](https://deep-paper.org/en/paper/11875_gmail_generative_modalit-1762/images/cover.png)
Introduction
We are currently living in the “Golden Age” of generative AI. Models like Stable Diffusion and DALL-E 3 can conjure photorealistic images from simple text descriptions in seconds. For machine learning researchers and students, this creates a tantalizing possibility: Infinite Training Data.
Imagine you want to train a vision system to recognize rare objects or complex scenes. Instead of spending months collecting and labeling real-world photos, why not just generate millions of synthetic images? It sounds like the perfect solution to the data scarcity problem.
However, there is a catch. Recent research has shown that indiscriminately mixing generated images with real images during training often leads to mode collapse and performance degradation. The model starts “overfitting” to the specific artifacts and statistical quirks of the synthetic data, causing it to fail when tested on real-world inputs.
This brings us to a fascinating new paper: “GMAIL: Generative Modality Alignment for generated Image Learning.”
In this post, we will dive deep into how GMAIL proposes a solution to this problem. The authors introduce a clever framework that treats generated images not as “fake real images,” but as a completely separate modality—distinct from real images—and aligns them mathematically in a shared latent space.
The Problem: The Uncanny Valley of Data
To understand GMAIL, we first need to understand the failure mode of current approaches.
When you train a model (like a Vision-Language Model or VLM) on a mix of real and synthetic data, you are essentially asking it to learn two different distributions simultaneously. Even though a generated image of a “cat on a mat” looks visually similar to a real photo, the underlying pixel statistics, texture patterns, and frequency distributions are different.
If a model is trained blindly on both, it struggles to generalize. The “knowledge” it gains from synthetic data doesn’t transfer cleanly to real-world tasks. This is often referred to as the modality gap.
The GMAIL authors argue that we should stop pretending synthetic images are real. Instead, we should treat “Generated Image” and “Real Image” as two distinct modalities—just as we treat “Text” and “Image” as different modalities in models like CLIP.
The GMAIL Framework
The core idea of GMAIL is Generative Modality Alignment. The goal is to ensure that the feature representation of a generated image (produced by a neural network) aligns perfectly with the feature representation of a real image describing the same concept.
Let’s break down the architecture.
1. The Dual-Path Architecture
The framework relies on a teacher-student setup involving two parallel flows.
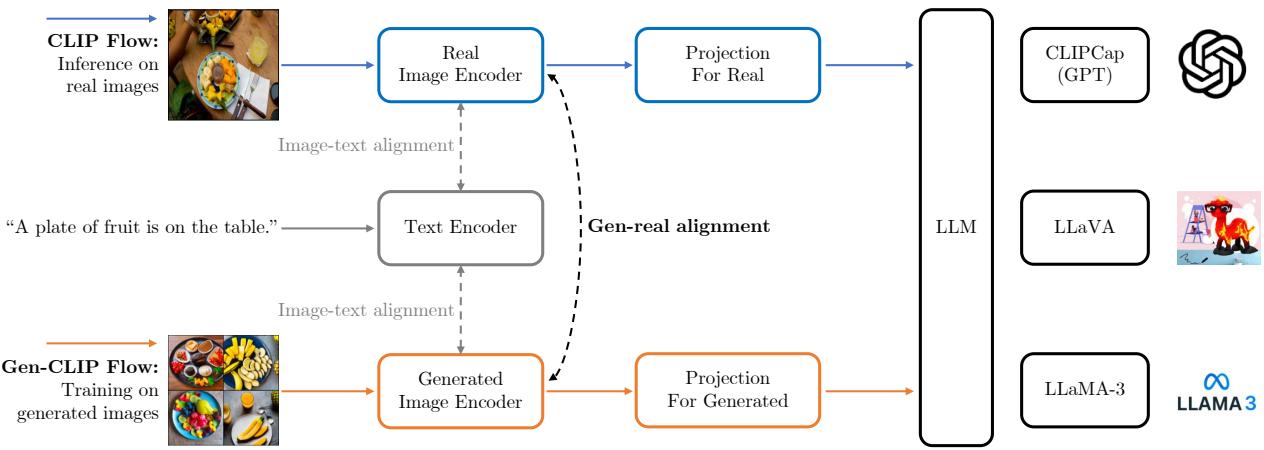
As illustrated in Figure 1, the architecture is split into two distinct pathways:
- CLIP Flow (The Teacher): This path processes real images. It uses a pre-trained CLIP image encoder that is kept frozen (its weights are not updated). This encoder represents the “ground truth” of how real-world visual concepts should be mapped to the latent space.
- Gen-CLIP Flow (The Student): This path processes generated images. It uses a separate encoder (initialized from CLIP) that is fine-tuned. The goal of this encoder is to learn how to process synthetic images such that their embeddings match the teacher’s real-image embeddings.
By separating these flows, the model doesn’t get confused by the statistical differences between real and synthetic pixels. It has a dedicated “eye” (encoder) for generated data.
2. Efficient Fine-Tuning with LoRA
Retraining a massive encoder from scratch is expensive and risks “catastrophic forgetting” (forgetting the original pre-trained knowledge). To solve this, the authors employ Low-Rank Adaptation (LoRA).
LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture. This allows GMAIL to adapt the model to the “generated modality” by updating only a tiny fraction of the parameters, making the process computationally efficient.
3. The Mathematics of Alignment
How do we actually force the generated image embeddings to line up with the real ones? This is done via a Cross-Modality Alignment Loss.
The objective is to minimize the distance between the embedding of a generated image (\(x_g\)) and the embedding of a real image (\(x_r\)) that shares the same semantic meaning (e.g., the same caption).
The mathematical formulation is a contrastive loss function:
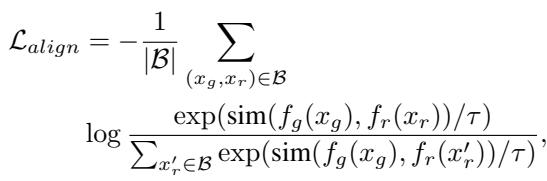
Let’s decode this equation:
- \(f_g(x_g)\): The embedding of the generated image from the student encoder.
- \(f_r(x_r)\): The embedding of the real image from the frozen teacher encoder.
- \(\text{sim}(\cdot)\): Cosine similarity (measuring how close two vectors are).
- \(\tau\): A temperature parameter that scales the logits.
The numerator encourages the model to pull the positive pair (the generated image and its corresponding real image) closer together. The denominator pushes the generated image away from other real images in the batch (negative samples).
This forces the student encoder to learn a transformation that “corrects” the synthetic artifacts, mapping the generated image to the exact same spot in vector space where the real image sits.
Visualizing the Latent Space
To truly understand why this alignment is necessary, we can look at a t-SNE plot. t-SNE is a technique for visualizing high-dimensional data in 2D.
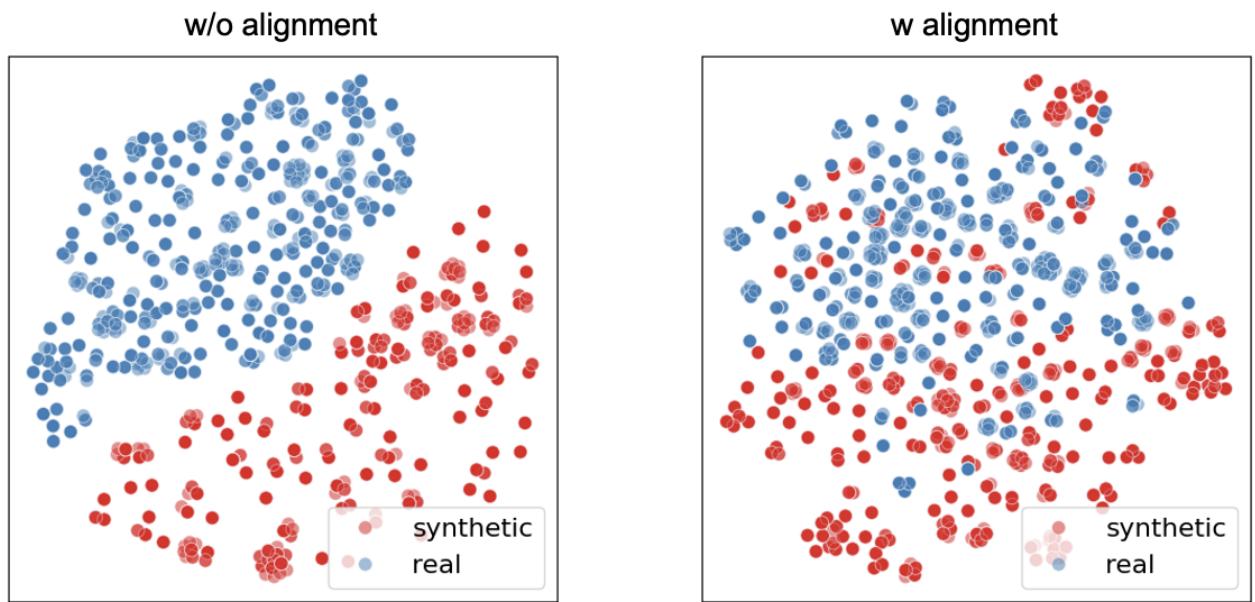
In Figure 3 (Left), we see the state of the world without alignment. The blue dots (real images) and red dots (synthetic images) form two distinct, separated clusters. This visualizes the “modality gap.” A classifier trained on the red cluster would fail on the blue cluster because they are fundamentally essentially located in different regions of the mathematical space.
In Figure 3 (Right), we see the result of GMAIL. The red and blue dots are perfectly mixed. The alignment loss has successfully forced the synthetic representations to overlap with the real representations. This means a model trained on these aligned synthetic features will inherently generalize to real data.
Experiments and Results
Does this theoretical alignment actually improve performance on downstream tasks? The authors tested GMAIL across several major computer vision benchmarks.
Image Captioning
The first test was Image Captioning on the COCO dataset. The model was trained using generated images and then asked to write captions for real images.
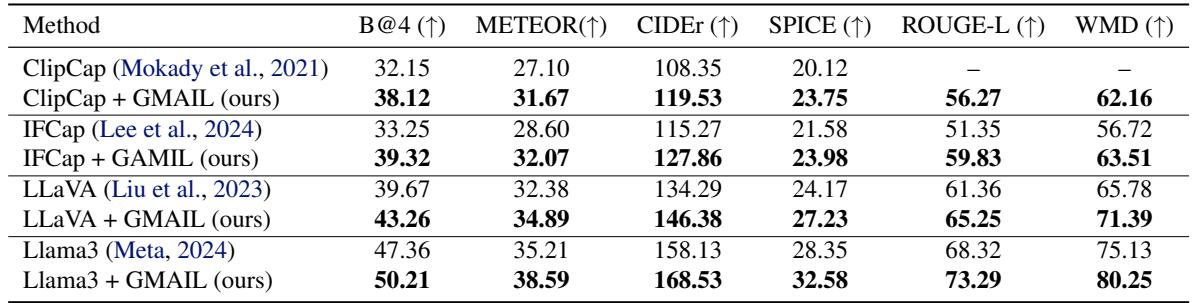
As shown in Table 1, GMAIL significantly outperforms the baselines.
- B@4 (BLEU score) and CIDEr are standard metrics for caption quality (higher is better).
- ClipCap + GMAIL achieves a CIDEr score of 119.53, beating the standard ClipCap (108.35) by a wide margin.
- The framework also boosts the performance of massive models like LLaVA and LLaMA-3, proving that this alignment technique is model-agnostic.
Zero-Shot Retrieval
Next, they looked at zero-shot image retrieval—finding the correct image for a text query (Text-to-Image) or the correct text for an image query (Image-to-Text).

In Table 2, we see consistent improvements. For example, in Text-to-Image retrieval (R@1), GMAIL improves the baseline CLIP from 32.7 to 37.5. This indicates that the alignment process has helped the model understand the semantic connection between text and visual concepts much better than standard pre-training.
Does It Scale?
One of the promises of synthetic data is scalability. If we generate more images, does the model get better?
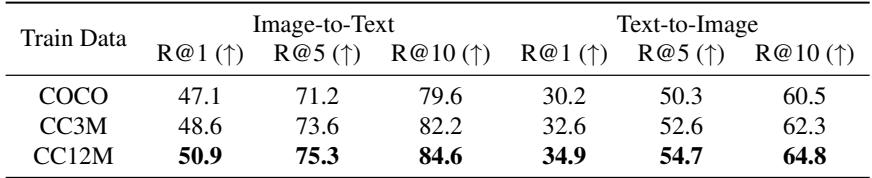
Table 7 provides the answer: Yes. When the authors increased the synthetic training data from COCO size (roughly 560k images) to CC12M size (12 million images), the retrieval performance jumped significantly (e.g., Image-to-Text R@1 went from 47.1 to 50.9).
This is a crucial finding. It suggests that GMAIL effectively unlocks the potential of large-scale synthetic data. As long as you align the data properly, you can keep generating more data to improve your model.
A Look at the Data
It is worth noting that the generated images used in this study, created by Stable Diffusion v2, are high quality.

Figure 2 shows side-by-side comparisons. The generated images (Columns 2-6) capture the high-level semantics of the real images (Column 1) very well. However, they are not pixel-perfect copies. They contain the specific “fingerprint” of the diffusion model.
Without GMAIL, a model might latch onto these specific diffusion artifacts (e.g., how the model renders lighting or textures). GMAIL forces the model to ignore these artifacts and focus only on the semantic content that aligns with the real image.
Conclusion
The GMAIL paper presents a compelling argument for how we should handle the incoming flood of synthetic data. It teaches us that more data isn’t always better—unless it is aligned.
By treating generated images as a separate modality and mathematically forcing them to align with real-world distributions, GMAIL provides a robust framework for training the next generation of Vision-Language Models.
Key Takeaways for Students:
- Modality Gap: Synthetic data follows a different distribution than real data; ignoring this leads to mode collapse.
- Teacher-Student Alignment: You can use a frozen model trained on real data (Teacher) to guide the training of a model on synthetic data (Student).
- Latent Space: The battle is won or lost in the latent space. Visualizations like t-SNE are powerful tools to verify if your models are actually learning what you think they are learning.
- Efficiency: Techniques like LoRA are essential for modern deep learning research, allowing us to adapt massive models with limited compute resources.
As generative models continue to improve, frameworks like GMAIL will likely become standard practice, becoming the bridge that connects the creative power of AI generation with the practical needs of AI understanding.