](https://deep-paper.org/en/paper/1812.02391/images/cover.png)
Have you ever seen a picture of a strange new animal, like a capybara, and been able to recognize it in different photos from then on? Humans have an incredible ability to learn new concepts from just one or a handful of examples. This is the essence of few-shot learning, and it’s a skill that has long been a grand challenge for artificial intelligence.
While modern deep learning models excel when trained on massive datasets—think millions of cat photos—they struggle when given only a few samples. A deep neural network trained on just five images of a new dog breed will likely overfit, memorizing those specific images instead of learning the general features of the breed.
To tackle this, researchers developed a paradigm called meta-learning, or “learning to learn.” The idea is to train a model on a variety of learning tasks so that it can quickly adapt to a new task it has never seen before. However, many meta-learning approaches, like the influential MAML (Model-Agnostic Meta-Learning), often have to use shallow neural networks to avoid overfitting—thus leaving the power of deeper architectures untapped.
This is where the paper Meta-Transfer Learning for Few-Shot Learning comes in. The authors propose a brilliant new method that combines the strengths of both worlds. It leverages the raw power of deep networks pre-trained on large datasets (transfer learning) and the adaptability of meta-learning. Their approach, called Meta-Transfer Learning (MTL), learns how to subtly tweak a pre-trained deep network to master new tasks from just a few examples.
In this article, we’ll take a deep dive into this research. We’ll explore:
- The core concepts behind meta-learning and transfer learning.
- The two key innovations of MTL: Scaling and Shifting (SS) operations and the Hard Task (HT) meta-batch training strategy.
- How these ideas enable deep networks to achieve state-of-the-art results on challenging few-shot benchmarks.
So grab a coffee, and let’s explore how we can teach our models to learn as efficiently as we do.
Setting the Stage: From Transfer Learning to Meta-Learning
Before dissecting MTL in detail, let’s understand the landscape it builds upon. The paper provides a helpful conceptual comparison to frame the problem.
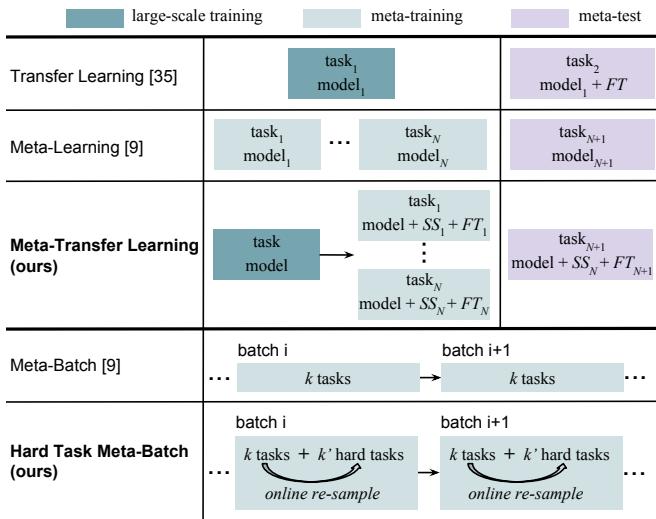
Figure 1: MTL blends elements of both transfer learning and meta-learning by learning to adapt pre-trained deep networks through lightweight scaling and shifting parameters.
Transfer Learning: This classic approach starts with a model pre-trained on a massive dataset such as ImageNet. The last layer is replaced, and the model is fine-tuned on a smaller target dataset. The idea works because early layers learn generic features like edges or textures. However, when the target dataset is very small, full fine-tuning can still lead to overfitting.
Meta-Learning: Instead of training on individual samples, meta-learning works across tasks. Each task (also called an episode) has a small training set (support set) and a small test set (query set). A “5-way, 1-shot” task means:
- The model sees 5 new classes.
- It gets only 1 example per class to learn.
- It must classify new examples from those 5 classes.
By training over thousands of such tasks, the model learns a general learning mechanism that transfers to unseen tasks. MAML is a well-known example of this, aiming to learn good initialization parameters that adapt quickly to new tasks.
The authors of MTL realized they could combine transfer learning’s efficiency with meta-learning’s adaptability by designing a way to modulate rather than fine-tune deep network parameters.
The MTL Pipeline: A Three-Phase Approach
Meta-Transfer Learning follows a clear three-phase structure, from large-scale pre-training to meta-learning to final testing.

Figure 2: The overall pipeline for the proposed MTL method.
Phase 1: Build a Strong Foundation (Large-Scale Training)
This phase starts with standard supervised training. The authors use a deep convolutional network like ResNet-12 and train it on a large-scale classification task—e.g., all 64 classes of miniImageNet, each with 600 images.
Denote Θ as the feature extractor (the convolutional layers) and θ as the classifier (the last fully connected layer). They are updated by gradient descent:
The loss is computed over dataset samples \((x,y)\):
\[ \mathcal{L}_{\mathcal{D}}([\Theta;\theta]) = \frac{1}{|\mathcal{D}|} \sum_{(x,y)\in\mathcal{D}} l(f_{[\Theta;\theta]}(x),y) \]After training, the feature extractor Θ becomes a robust foundation representing general visual patterns. Importantly, these weights are frozen—they won’t be changed during later meta-learning. The initial classifier θ is discarded because each few-shot task involves different classes.
Phase 2: The Core Innovation — Meta-Transfer Learning
Now the exciting part begins. The question is: how can we adapt this frozen feature extractor Θ to new few-shot tasks without altering its weights?
The answer: Scaling and Shifting (SS).
Instead of fine-tuning the actual convolutional weights W and biases b, MTL learns two small, task-specific parameters for each convolutional layer:
- A scaling parameter \( \Phi_{S_1} \) that multiplies the weights.
- A shifting parameter \( \Phi_{S_2} \) that adjusts the activations.
With SS, a convolutional operation changes from \(WX + b\) to:
\[ SS(X; W, b; \Phi_{S_{\{1,2\}}}) = (W \odot \Phi_{S_1})X + (b + \Phi_{S_2}) \]where \(\odot\) denotes element-wise multiplication. In essence, the network learns how to subtly amplify or suppress features without modifying the base weights.
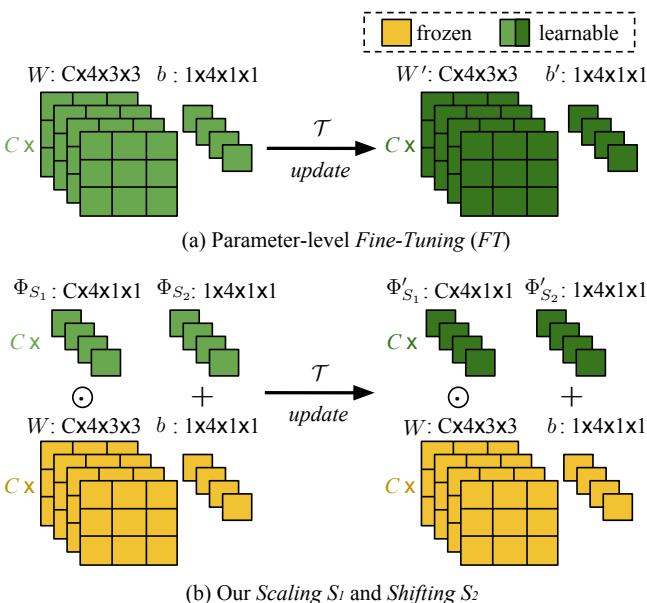
Figure 3: Fine-tuning affects all filter parameters, while SS only learns a scaling and shifting per filter—greatly reducing the risk of overfitting.
The difference between Fine-Tuning (FT) and Scaling & Shifting (SS) can be dramatic:
- FT adjusts every weight and bias in the filter (e.g., 3×3 filters have 9 parameters).
- SS learns just two lightweight parameters per filter.
This yields three major advantages:
- Efficiency: Far fewer learnable parameters, ideal for few-shot settings.
- Stability: Frozen pretrained weights prevent catastrophic forgetting.
- Speed: Starts from a well-trained initialization, accelerating learning.
Inside the Meta-Training Loop
During meta-training, MTL optimizes both the classifier θ and the SS parameters across tasks. For each task \(\mathcal{T}\):
- Base-Learner Update (Inner Loop):
This step adapts the classifier on the small training set without altering the frozen backbone Θ.
- Meta-Learner Update (Outer Loop):
The adapted classifier θ' is evaluated on the test set. The loss gradients update the meta-parameters:
Repeating this cycle across thousands of tasks teaches the SS layers to generalize across varied few-shot scenarios.
Growing Stronger Through Hardship: The HT Meta-Batch
Randomly sampling tasks works—but MTL adds a clever twist inspired by curriculum learning and hard negative mining.
The Hard Task (HT) meta-batch strategy trains the model on its most difficult tasks:
- Run several regular meta-batches.
- Identify “failure classes” with lowest accuracy from each task.
- Resample new tasks focusing on these harder classes.
- Train again on this “hard batch.”
This approach intentionally challenges the model, helping it “grow stronger through hardship.” As visualized in Figure 1, HT meta-batch creates a structured training sequence that focuses learning where it’s most needed.
Phase 3: Meta-Test
After meta-training ends, the SS parameters are fixed. The model adapts only its small classifier on new unseen tasks and is evaluated on their query sets. The average accuracy over hundreds of such test tasks becomes the final performance metric.
Results: Does MTL Deliver?
The paper’s experiments on miniImageNet and Fewshot-CIFAR100 (FC100) show that MTL not only improves accuracy but also dramatically accelerates convergence.
Meta-Learning Beats Simpler Fine-Tuning
An ablation study highlights the importance of MTL’s meta-learning approach. As shown below, MTL with SS significantly outperforms baselines that use simpler training or fine-tuning.
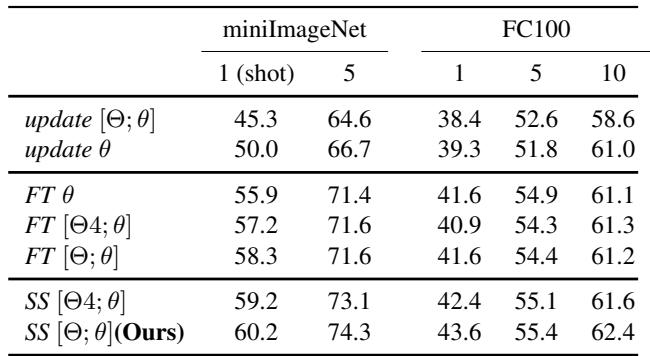
Table 1: MTL (bottom rows) consistently outperforms simpler baselines.
On miniImageNet 1-shot tasks, MTL achieved 60.2% accuracy, compared to 50.0% for a non-meta-learning baseline (update θ).
State-of-the-Art Results on miniImageNet
MTL with HT meta-batch achieves top-tier results, outperforming MAML and other methods.
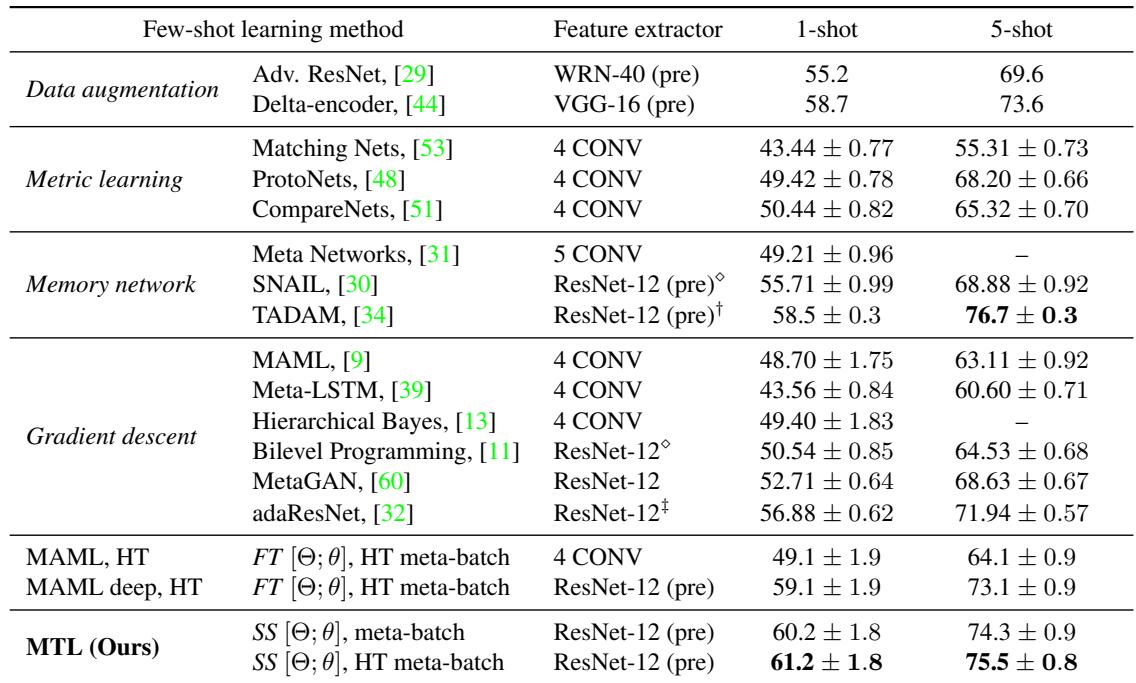
Table 2: Performance on miniImageNet. MTL reaches the highest accuracy, especially on the challenging 1-shot tasks.
- MTL (ResNet-12 + HT meta-batch): 61.2% (1-shot), 75.5% (5-shot)
- MAML (ResNet-12): 59.1% (1-shot), 73.1% (5-shot)
- Previous SOTA (TADAM): 58.5% (1-shot), 76.7% (5-shot)
The improvement is most pronounced for the hardest case—1-shot learning.
Robust Performance on FC100
FC100 splits classes by super-classes (e.g., mammals vs. insects), making it an even tougher test of generalization. MTL continues to outperform other models.
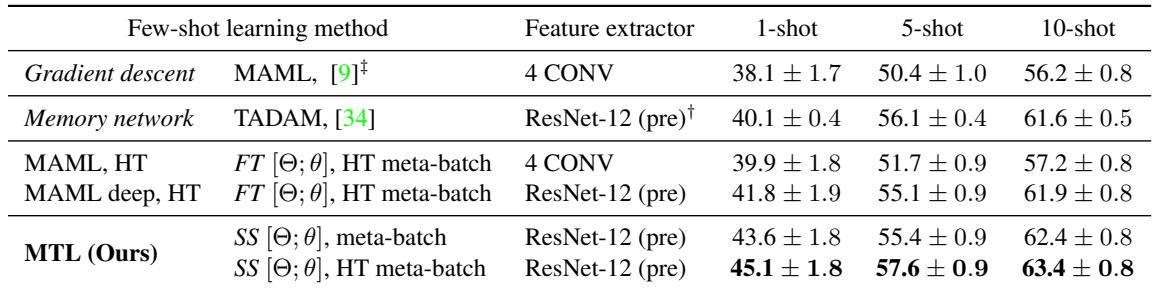
Table 3: Results on FC100. MTL maintains strong advantage across all few-shot settings.
MTL delivers around 7% improvement over MAML across tasks and beats TADAM by up to 5% in the 1-shot setup.
Faster Learning with HT Meta-Batch
The HT meta-batch doesn’t just improve performance—it speeds learning. The following plots show accuracy versus training iterations.

Figure 4: HT meta-batch (orange) consistently yields higher accuracy and faster convergence across datasets.
MTL converges to high performance using just 8,000 tasks, compared to MAML’s 240,000—a 30× reduction in training volume.
Conclusion: A Smarter Way to Adapt
The Meta-Transfer Learning for Few-Shot Learning paper demonstrates that the fusion of transfer learning and meta-learning can unlock deep networks for few-shot tasks by learning lightweight adaptation rules instead of retraining heavy architectures.
Key takeaways:
- Modulate, don’t retrain: Scaling and Shifting operations offer a robust, parameter-efficient way to adapt deep models with minimal risk of overfitting.
- Start from strength: Leveraging a pre-trained deep network provides a solid foundation that speeds adaptation and improves generalization.
- Learn from your failures: The Hard Task meta-batch forces models to confront their weaknesses, resulting in faster and stronger learning.
By building upon both transfer and meta-learning, MTL shows how AI can learn new concepts with human-like efficiency—faster, smarter, and with fewer examples.