](https://deep-paper.org/en/paper/1812.07172/images/cover.png)
Imagine you’re a brilliant apprentice learning multiple, very different skills from a master. One day you’re painting delicate watercolors; the next, you’re forging steel. A good mentor wouldn’t teach both crafts using identical starting principles. For watercolors, you’d begin with a light touch and color blending; for forging, you’d start with strength and heat control. The initial mindset—the “prior”—must match the task at hand.
In artificial intelligence, this concept of “learning to learn” is called meta-learning. A leading approach is Model-Agnostic Meta-Learning (MAML), which seeks a universal starting point—a set of initial model weights—from which an AI can rapidly adapt to new tasks using only a few examples. It’s like finding a central train station that offers quick routes to any neighborhood in a city.
But what happens when the “city” has several disconnected downtowns? If the tasks differ dramatically—say, recognizing colors versus estimating temperatures—a single starting point becomes a poor compromise for all. This is the challenge posed by multimodal task distributions: groups of tasks that naturally form distinct clusters or “modes.”
A research team from the University of Southern California and SK T-Brain tackled this head-on in “Toward Multimodal Model-Agnostic Meta-Learning.” Their proposed algorithm, MuMoMAML, combines the strengths of two major meta-learning paradigms to create a system that first identifies what type of task it faces and then intelligently adapts its starting point before learning begins. This hybrid design merges flexibility and specialization, enabling fast and effective learning across a diverse range of problems.
A Tale of Two Meta-Learners
To appreciate MuMoMAML’s innovation, we first need to understand the two approaches it fuses: gradient-based and model-based meta-learning.
1. Gradient-Based Meta-Learning: The Search for the Perfect Starting Line
Gradient-based methods, epitomized by MAML, aim to find an optimal set of initial parameters, denoted as \(\theta\). These parameters aren’t perfect for any single task but are tuned to be highly adaptable. With just a few gradient steps, the model can rapidly specialize for a new task.
The intuition is that \(\theta\) lies at a central point in the parameter space, surrounded by nearby optima for various tasks. This flexibility makes MAML model-agnostic: it works with virtually any architecture trained by gradient descent, from convolutional networks to reinforcement learning agents.
The limitation, however, is the reliance on a single \(\theta\). When task modes are far apart, this common initialization becomes ineffective.
2. Model-Based Meta-Learning: The Task Identifier
Model-based approaches choose a different path. Instead of seeking a shared initialization, they learn to infer each task’s identity directly from a few examples. A small support set of pairs \((x_k, y_k)\) is encoded into a task embedding, a vector summarizing the task’s key properties. This embedding then modulates the behavior of a base model.
Think of it as a two-brain system: one brain examines the data and says, “Ah, this task involves fitting a sine wave!” The other brain immediately reconfigures its internal wiring to behave like a sine-wave expert. These approaches shine in recognizing and adapting to specific task types but often need carefully hand-crafted architectures, making them less general.
The Hybrid Hero: MuMoMAML
MuMoMAML (Multi-Modal Model-Agnostic Meta-Learning) elegantly merges these two philosophies. It uses a model-based component to determine which mode a task belongs to, then uses that information to create a custom starting point for gradient-based adaptation.
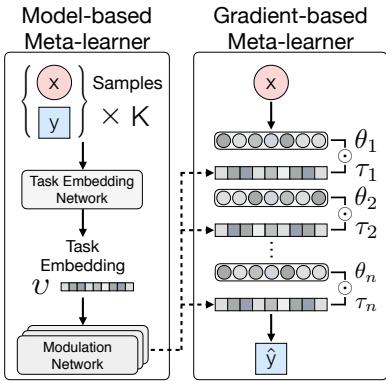
Figure 1: The architecture of MuMoMAML. A model-based “Task Embedding Network” identifies the task, while a gradient-based learner adapts from a modulated, task-specific starting point.
The process unfolds in two parts, trained jointly end-to-end.
- Model-Based Identifier:
- Task Embedding Network — Encodes the support examples \(\{x_k, y_k\}_{k=1}^K\) into a dense task embedding vector \(v\).
- Modulation Network — Takes \(v\) and outputs modulation parameters \(\tau\) that shape the base model’s behavior for this task.
- Gradient-Based Adapter: The primary model, parameterized by \(\theta\), performs gradient updates to refine its predictions.
The Magic Moment: Modulation
The key innovation arises from combining these components. The modulation parameters \(\tau\) transform the general parameters \(\theta\) into task-specialized ones, \(\phi\). This model-based adaptation step is formalized as:
\[ \phi_i = \theta_i \odot \tau_i \]where \(\odot\) denotes a modulation operation applied at each layer.
The authors explore several modulation mechanisms, including attention-based and Feature-wise Linear Modulation (FiLM). FiLM proves most effective. For each layer, the modulation network produces scaling and shifting factors, \(\tau_\gamma\) and \(\tau_\beta\), yielding:
\[ \text{New Output} = (\text{Original Output} \otimes \tau_\gamma) + \tau_\beta \]This layer-by-layer modulation allows refined adjustments across the network, producing a new initialization \(\phi\) that’s well-suited for the task. From this customized starting point, the model performs its usual gradient-based adaptation to reach high performance.
Experiments and Results: Does It Work?
The team tested MuMoMAML across three domains—regression, reinforcement learning, and few-shot image classification—and consistently found it outperformed baseline models.
Multimodal Regression: Fitting Curves of Different Families
In this experiment, the meta-learner faced a mix of regression tasks: fitting sinusoidal, linear, and quadratic functions. Classic MAML, with one shared initialization, struggles to represent all three simultaneously.
To create a strong baseline, the authors introduced Multi-MAML, a collection of separate MAML models (one per mode). When evaluated, Multi-MAML is told in advance which mode a function belongs to—an oracle-like advantage.
The results were nonetheless decisive:
| Method | Modulation | Two Modes (MSE) | Three Modes (MSE) |
|---|---|---|---|
| MAML | – | 1.0852 | 1.1633 |
| Multi-MAML | GT | 0.4330 | 0.7791 |
| MuMoMAML (FiLM) | Learned | 0.3125 | 0.4048 |
MuMoMAML even outperformed Multi-MAML, which had privileged access to ground-truth task identities. This demonstrates its capability to infer task modes and exploit shared knowledge between them—learning to transfer insights instead of isolating expertise.
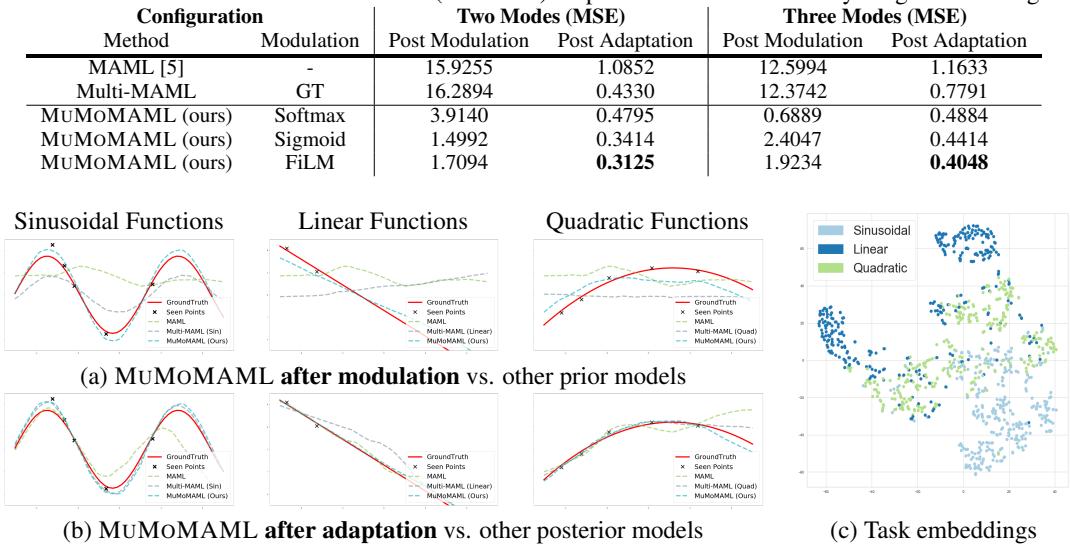
Figure 2: (a) Without gradient steps, MuMoMAML’s modulated prior (blue) already approximates target functions better than MAML. (b) After adaptation, it surpasses all baselines. (c) The t-SNE plot shows distinct clusters for different function types, verifying successful mode identification.
The task embeddings in Figure 2(c) cluster neatly by function type, confirming that MuMoMAML effectively learns an internal representation for each mode.
Reinforcement Learning: Navigating Bimodal Worlds
MuMoMAML was further evaluated in reinforcement learning environments, where agents learned from multimodal goal distributions.
In the 2D Navigation task, an agent must reach a goal selected from two distinct clusters. In more complex Mujoco simulations, a Half-Cheetah robot learned to reach different target locations or maintain different target speeds.
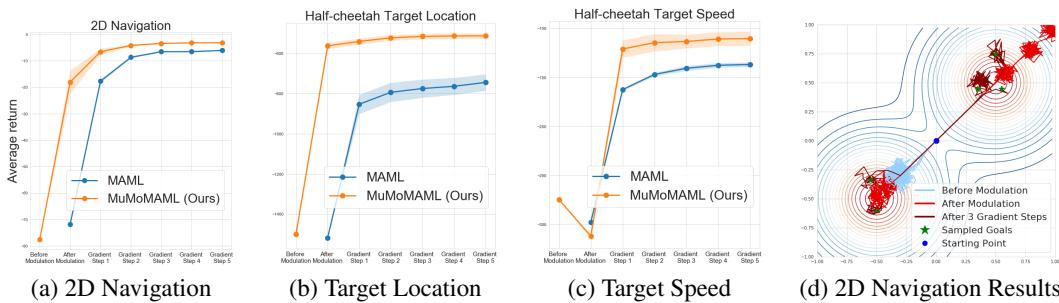
Figure 3: (a–c) MuMoMAML (orange) consistently achieves higher rewards than MAML (blue) at every adaptation stage. (d) In the 2D navigation task, the policy after modulation (orange) already moves toward the correct goal; after a few gradient steps (green), it fine-tunes its trajectory.
Even before gradient updates, the modulated policy yields better initial rewards. The modulation step alone gives the agent contextual awareness—pointing it toward the correct mode of behavior.
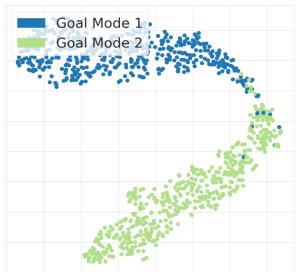
Figure 4: Task embeddings for the Half-Cheetah Target Location environment form two distinct clusters, revealing the model’s ability to identify the task mode from limited interaction data.
Across all reinforcement learning tasks, MuMoMAML maintained its advantage over MAML from the first adaptation step through to convergence.
Few-Shot Image Classification: A Universal Test
Finally, MuMoMAML was evaluated on the Omniglot benchmark, a classic testbed for few-shot learning. Tasks involve recognizing new handwritten characters after seeing only one or five examples per class.
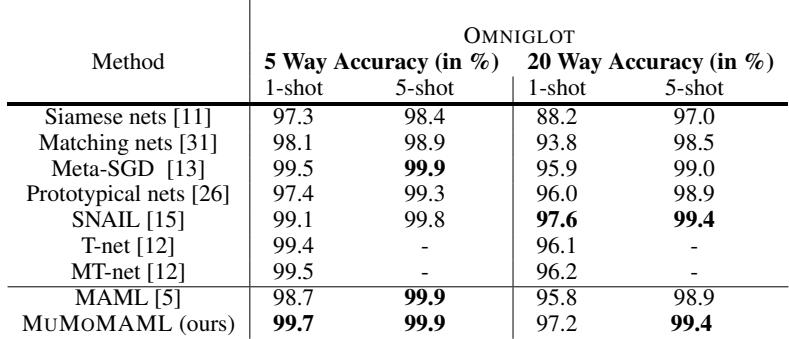
Table 2: MuMoMAML matches or exceeds state-of-the-art results on Omniglot, showing that the multimodal adaptation mechanism generalizes even to tasks without clear modes.
MuMoMAML performed on par with, and sometimes better than, top-performing algorithms. Crucially, its hybrid design didn’t compromise performance on standard benchmarks—it generalized seamlessly.
Conclusion: The Best of Both Worlds
The “Toward Multimodal Model-Agnostic Meta-Learning” paper introduces a compelling idea: when learning from highly varied tasks, stop searching for a single starting point. Instead, adapt the prior itself.
By blending the task-identification prowess of model-based meta-learning with the efficiency of gradient-based adaptation, MuMoMAML creates a flexible foundation that can recognize what kind of task it’s dealing with and immediately adjust its strategy. Once modulated, it refines its understanding through gradient descent—acting both intuitively and analytically.
This hybrid method marks a significant step toward more context-aware AI systems. Just as a master craftsman adapts their mindset when switching from watercolor to steelwork, MuMoMAML enables machines to tailor their learning process to the nature of the challenge—making true general-purpose intelligence a little closer to reality.