](https://deep-paper.org/en/paper/2010.02500/images/cover.png)
Humans are remarkable learners. Throughout our lives, we continuously acquire new skills, adapt to changing environments, and build upon our past experiences. When you learn to ride a bike, you don’t forget how to walk. When you pick up a new language, you still remember your native tongue. This ability to accumulate knowledge without erasing what we’ve learned before is a key hallmark of human intelligence.
For modern AI systems, this simple human feat poses a major challenge. Today’s most advanced models—like BERT and GPT—are brilliant in narrow tasks, but when retrained on new data, they often forget what they previously mastered. This problem, known as catastrophic forgetting, is like a student who aces a history exam only to forget all their math afterwards. It severely limits AI’s usefulness in real-world scenarios where tasks and data evolve continuously.
Researchers have long pursued the holy grail of lifelong learning—designing models that can learn sequentially over time without erasing prior knowledge. Many of these methods rely on storing and replaying past examples using an “episodic memory” system. Yet these approaches often suffer from severe practical drawbacks: massive memory requirements, negative transfer (where previous learning harms new learning), and slow inference speeds.
A team at Carnegie Mellon University set out to solve this with their paper, Efficient Meta Lifelong-Learning with Limited Memory. Their proposed model, Meta-MbPA, dramatically reduces memory usage while improving both accuracy and speed. It achieves state-of-the-art results using just 1% of the memory that previous methods needed—and runs up to 22 times faster. Let’s explore how this breakthrough works.
The Three Pillars of Lifelong Learning
Before diving into Meta-MbPA, it helps to understand the core concepts that underpin lifelong learning. The objective is to train a single model \( f_{\theta} \) on a sequence of tasks \( \mathcal{D}_1, \mathcal{D}_2, \ldots, \mathcal{D}_N \) that appear one after another. The model doesn’t know which task each example belongs to and must perform well on average across all tasks.
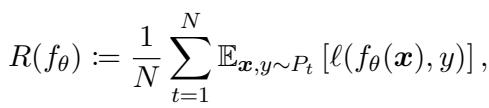
“The model continually learns to minimize the average expected risk across all observed tasks, balancing old and new knowledge.”
Three key principles define most lifelong learning systems:
1. Generic Representation: Start with a broad foundation. Models like BERT are pre-trained on massive text corpora and capture general language understanding. Lifelong learners update this knowledge incrementally, often using regularization to prevent drastic parameter shifts that might erase old knowledge.
2. Experience Rehearsal: Inspired by human memory consolidation, this principle involves storing a small fraction of past examples in an episodic memory module. When learning new tasks, the model “rehearses” by replaying some of these previous examples, reinforcing older knowledge.
3. Task-specific Finetuning (Local Adaptation): At inference time, the model quickly fine-tunes on examples most similar to the query input—its K nearest neighbors in memory—using a few lightweight updates. This helps it specialize for task-specific nuances while retaining general knowledge.
These three pillars are powerful, but combining them effectively is the real challenge. The state-of-the-art approach before Meta-MbPA tried doing just that—but ran into serious inefficiencies.
The State of the Art—and Its Limitations: MbPA++
The previous best method, Model-based Parameter Adaptation (MbPA++), integrated all three principles but not in a unified way. Here’s how it worked:
- Generic Representation: It started with a pre-trained BERT encoder and updated parameters for each new training example to minimize the standard task loss.
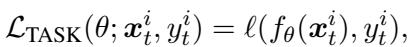
“Equation (2): The task loss—how wrong the model is for each training example.”
- Experience Rehearsal: Periodically, the model sampled a batch of stored examples from its memory to replay and strengthen old skills.
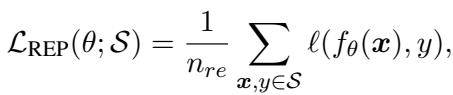
“Equation (3): Experience rehearsal helps the model refresh knowledge from previous tasks.”
- Task-specific Finetuning: At test time, MbPA++ retrieved the \(K\) nearest examples for every single test query, then performed dozens of gradient descent updates to locally adapt the parameters before making a prediction.
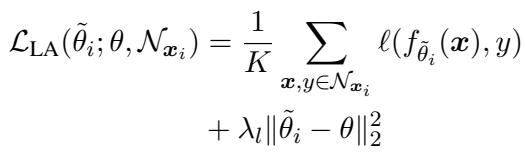
“Equation (4): Local adaptation fine-tunes predictions using nearby examples in memory.”
While MbPA++ was effective, the researchers identified three major flaws:
- Excessive Memory: It needed nearly all training examples stored to perform optimally.
- Negative Transfer: The adapted model sometimes performed worse on new tasks than a simple baseline.
- Slow Inference: Re-adapting for each test sample meant inference could take hours.
The problem stemmed from a train-test mismatch: MbPA++ was trained only to minimize the direct task loss (Equation 2) but evaluated after performing local adaptation (Equation 4). It never learned how to adapt efficiently.
A Synergistic Solution: The Meta-MbPA Framework
Meta-MbPA fixes this train-test mismatch with a clever meta-learning approach. Instead of training the model merely to be good at tasks, it’s trained to be a good initializer for future adaptation. In other words, the model doesn’t just learn—it learns how to learn.
1. Meta-Learning a Better Generic Representation
To train a representation optimized for adaptation, each training step simulates an inner “local adaptation” loop, then updates the model parameters based on performance after adaptation.
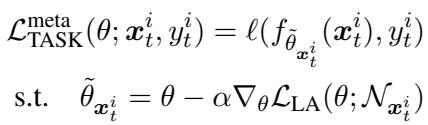
“Equation (5): The meta-loss encourages the model to perform well after simulated adaptation, closing the train-test gap.”
This transforms learning into a learn-to-adapt process, where the outer optimization updates the model to be resilient and flexible. Modern frameworks like PyTorch handle the required “gradient of gradients” computation seamlessly.
2. Smarter Experience Rehearsal
Meta-MbPA also reformulates memory replay using the same meta-learning principle, ensuring the model learns from past examples in a way that improves its ability to adapt later.
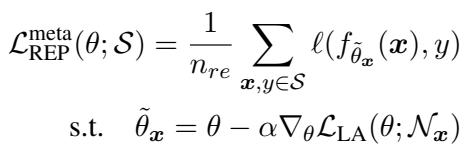
“Equation (6): Meta-replay enables the model to learn adaptation skills from past examples.”
Additionally, instead of filling the memory randomly, Meta-MbPA uses a diversity-based memory selection rule. When deciding whether to store a new example, it calculates how different it is from existing memory:
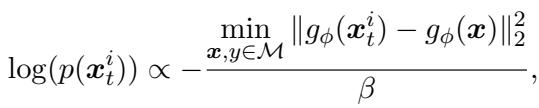
“Equation (7): Diverse samples are more likely to be stored, capturing a broader slice of the data distribution.”
This method selects examples that expand memory coverage while keeping the total memory size small—just 1% of available data.
3. Efficient and Robust Finetuning
Finally, Meta-MbPA speeds up inference dramatically by introducing coarse local adaptation. Instead of adapting to each test example individually, it adapts once for the entire batch using random samples from the full memory.
This design offers two major advantages:
- Robustness: Sampling broadly avoids overfitting to a few irrelevant examples.
- Efficiency: A single adaptation pass improves thousands of predictions at once, cutting inference time by up to 22×.
Putting Meta-MbPA to the Test
The framework was evaluated on text classification and question answering tasks, using standard datasets like AGNews, Yelp, Amazon, DBPedia, SQuAD, and TriviaQA.
Overall Performance
Compared to several strong baselines—including MbPA++, Replay, A-GEM, and Online EWC—Meta-MbPA delivered superior results even at a fraction of the memory size.
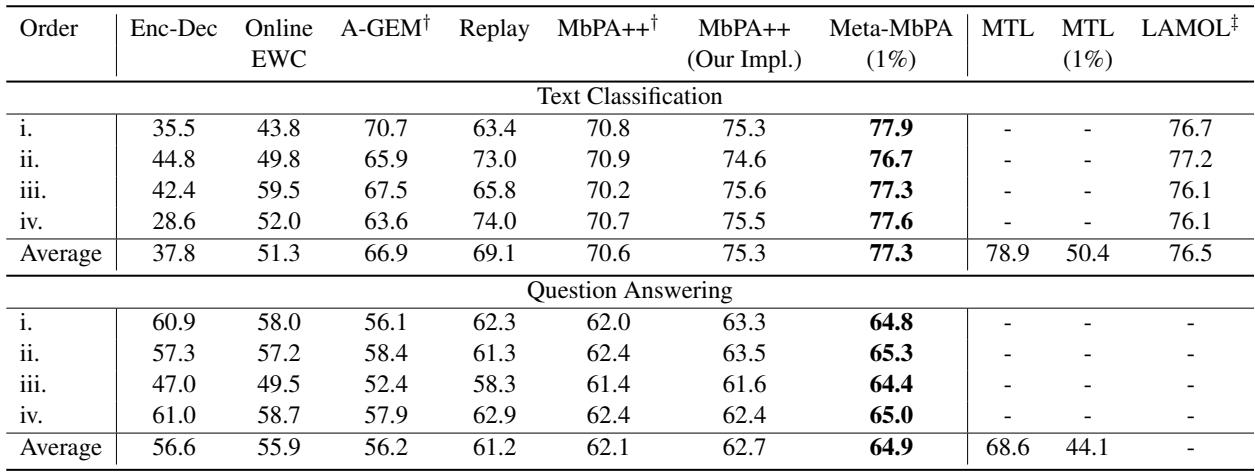
“Meta-MbPA achieves the highest average accuracy and F1 scores while using only 1% memory.”
Memory Efficiency
To test efficiency directly, the authors compared MbPA++ and Meta-MbPA under equally small memory budgets. The results were clear: Meta-MbPA’s performance stays strong, while MbPA++ suffers heavy degradation.
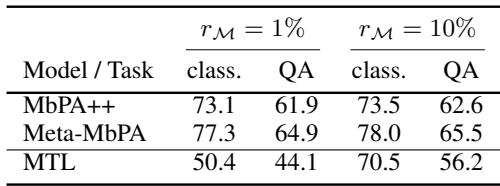
“Meta-MbPA maintains strong performance even with minimal memory, highlighting its efficient memory use.”
The Problem with “Uncertain” Memories
The authors explored different strategies for choosing which samples to store in memory. While random and diversity-based selections worked well, “uncertainty-based” selection—picking samples the model is least confident about—performed surprisingly poorly.
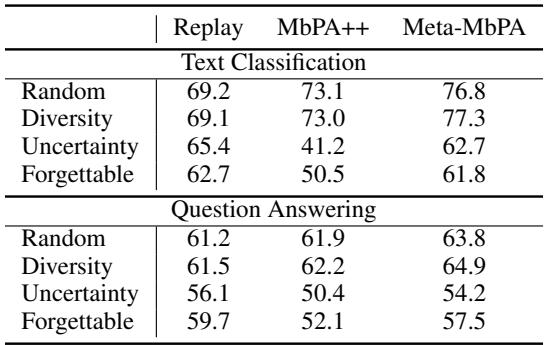
“Uncertainty-based memory selection consistently underperforms due to poor data coverage.”
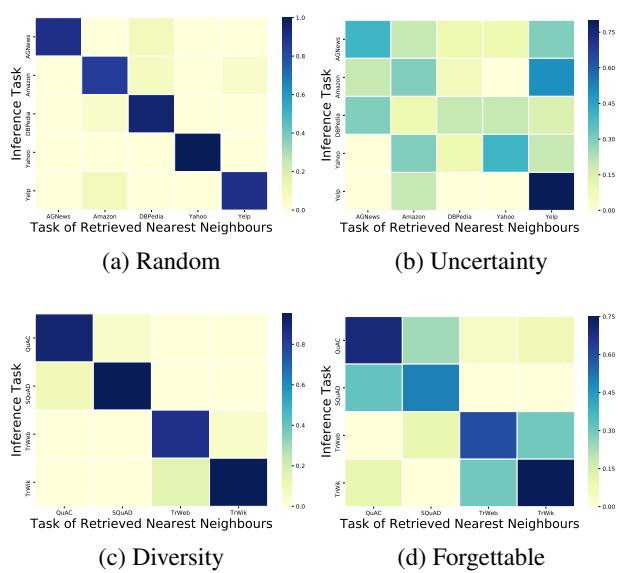
“Figure 1: Diversity-based memory ensures task-aligned neighbor retrieval, reducing cross-task interference.”
When uncertainty-based memories are filled with ambiguous or outlier examples, the model retrieves irrelevant neighbors across tasks—leading to negative transfer, where learning old tasks harms new ones.
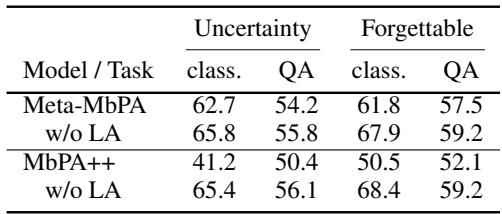
“Skipping local adaptation improves accuracy under uncertainty-based memory—proof of negative transfer effects.”
Balancing Forgetting and Negative Transfer
Lifelong learning isn’t just about preventing catastrophic forgetting. Overcorrecting for it can cause negative transfer, where old knowledge actually impairs new learning. Meta-MbPA is the first to explicitly balance this trade-off.
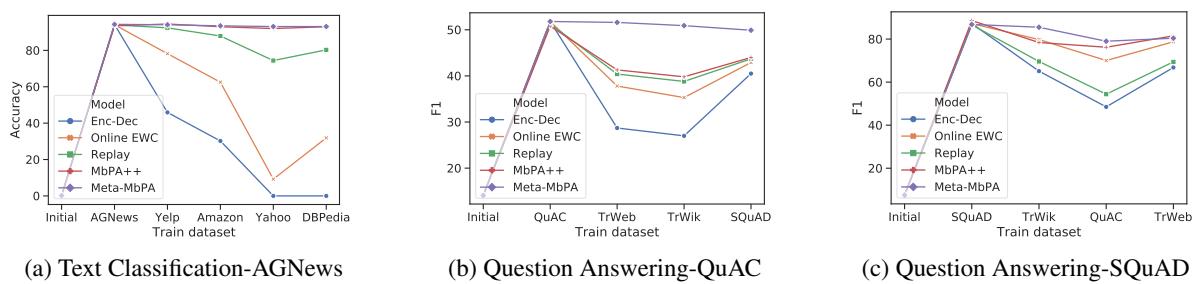
“Meta-MbPA excels at preserving first-task performance while continuing to learn new tasks.”
But how well does it learn new tasks? The final-task results reveal the other side of the coin.
“Meta-MbPA avoids the negative transfer that plagues MbPA++, maintaining strong performance on the newest tasks.”
Meta-MbPA manages to keep old skills while still mastering new ones—a rare achievement in lifelong learning.
Conclusion: Toward Truly Adaptive AI
The Efficient Meta Lifelong-Learning framework marks a major leap forward in continuous AI learning. By unifying representation learning, rehearsal, and adaptation in one synergistic meta-learning process, it achieves unprecedented efficiency and stability.
Key takeaways:
- Synergy matters: Training a model to adapt well trumps optimizing disconnected components.
- Small but smart memories: A memory covering diverse examples can rival much larger ones.
- Balance is crucial: Lifelong learning’s success depends on managing both forgetting and negative transfer.
With Meta-MbPA, we move closer to AI systems that can learn continuously and reliably in dynamic real-world environments—efficient, adaptive, and a little more human.