](https://deep-paper.org/en/paper/2206.05625/images/cover.png)
Artificial Intelligence has achieved superhuman performance in an incredible range of specialized tasks. AI can beat grandmasters at chess, transcribe audio with stunning accuracy, and identify objects in images better than humans can. Yet for all its power, modern AI has a critical weakness: it’s brittle. Most AI models are like a brilliant student who crams for a single exam—mastering one subject perfectly but forgetting everything when asked about a new topic. A child, by contrast, learns continuously, adapting to new information, refining skills, and building upon old knowledge without wiping the slate clean.
This fundamental gap highlights two major hurdles in AI development. First, the phenomenon of catastrophic forgetting, where a neural network trained on a new task overwrites its knowledge of previous tasks. Second, the design process of neural networks, which remains a slow and intuition-driven art rather than a scalable science.
What if we could build AI that overcomes both hurdles? What if an AI could learn continuously and reinvent its own design to become better at learning? This is the vision explored in the research paper “Exploring the Intersection between Neural Architecture Search and Continual Learning.” The authors propose a new paradigm called Continually-Adaptive Neural Networks (CANNs)—systems that merge the strengths of two cutting-edge fields, Continual Learning (CL) and Neural Architecture Search (NAS), to create adaptive and self-evolving agents.
This article unpacks the core ideas behind that vision. We’ll explore how CL and NAS tackle the challenges of lifelong learning and self-design, then dive into how their fusion creates CANNs—AI systems that are born to learn.
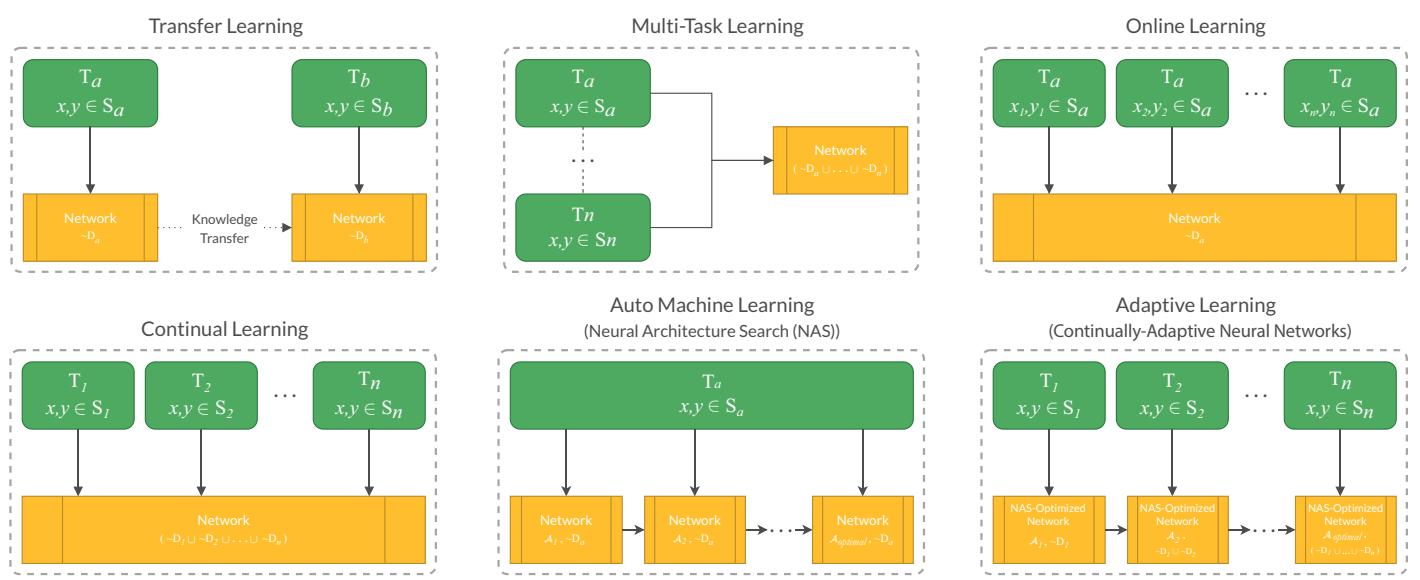
Comparative illustrations for Adaptive Learning and its neighboring Machine Learning paradigms.
The Stability–Plasticity Dilemma: Understanding Continual Learning
Imagine you’ve trained a world-class AI to identify different species of birds. Then you want to teach it to recognize fish. When you train the same network on fish images, its internal parameters shift so radically that it forgets how to recognize birds—an example of catastrophic forgetting.
Continual Learning (CL) aims to prevent this by enabling a model to learn from a continuous stream of information without losing previously acquired knowledge. The goal is to balance two opposing forces:
- Plasticity: The ability to learn new information and adapt quickly.
- Stability: The ability to retain old knowledge without overwriting it.
Balancing these forces is known as the stability–plasticity dilemma—learn too freely and forget; learn too rigidly and stagnate. CL research proposes two main categories of strategies for overcoming this trade-off, visualized below.
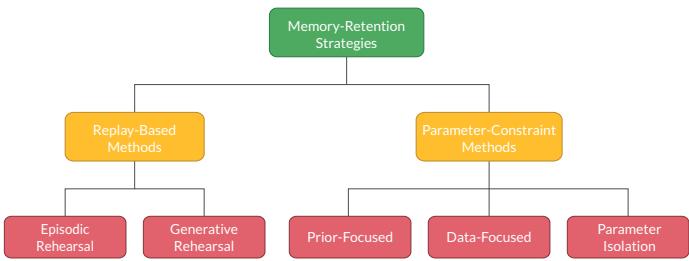
Continual Learning memory-retention strategies.
1. Replay-Based Methods: Rehearsing the Past
Inspired by how the human brain consolidates memories, replay-based methods store information from past tasks for “rehearsal.”
Episodic Rehearsal: The network stores a small subset of raw data from previous tasks. When training on new data, it mixes in these old samples to remind itself what it already knows. Simple but memory-intensive, this method struggles to scale.
Generative Rehearsal: Instead of saving raw data, the model learns the data distribution using a generative model (such as a GAN) and produces synthetic samples to rehearse. More efficient, but adds complexity.
Both methods echo biological memory replay and are powerful yet resource-heavy approaches to lifelong learning.
2. Parameter-Constraint Methods: Protecting Knowledge
Rather than storing old data, parameter-constraint methods preserve knowledge by protecting key parameters from drastic change.
- Prior-Focused (Regularization): Adds penalty terms to discourage large changes to crucial weights. Elastic Weight Consolidation (EWC) is a well-known example.
- Parameter Isolation: Freezes parameters for previous tasks and allocates new ones for new tasks, perfectly preserving old knowledge but causing infinite growth.
- Data-Focused (Knowledge Distillation): Uses an old model as a “teacher,” guiding the new one to mimic its outputs. This distills prior knowledge without replay.
A hybrid approach, such as Gradient Episodic Memory (GEM), combines rehearsal and constraints—protecting important parameters while replaying representative samples—to balance memory retention and adaptability.
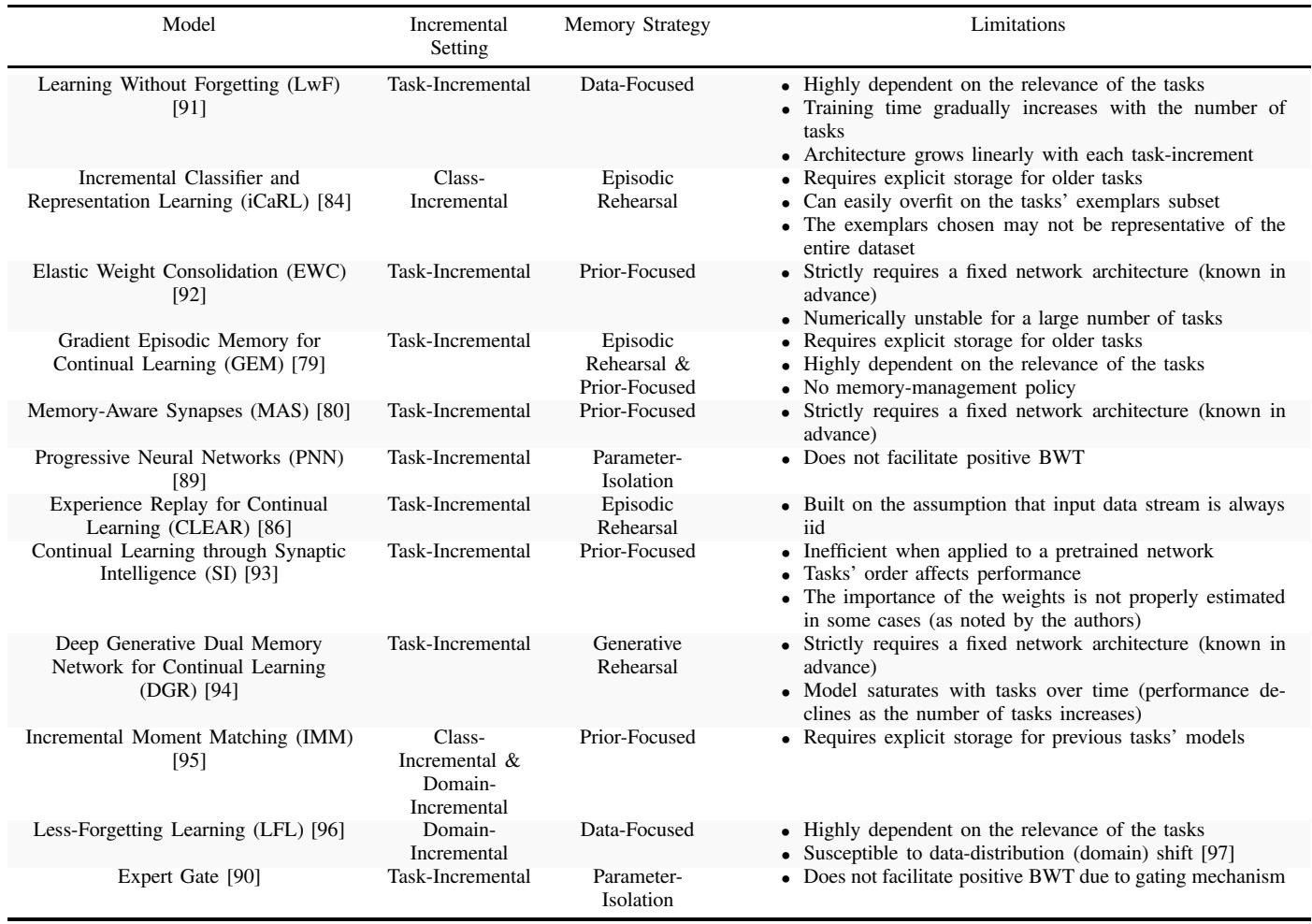
Comparative analysis of key Continual Learning models from an adaptiveness perspective.
The Automated Architect: Demystifying Neural Architecture Search
While CL research focuses on making models learn continuously, NAS tackles a different challenge: who designs these models in the first place?
Designing a neural architecture—the configuration of layers, operations, and connections—has traditionally been a manual and laborious process. Neural Architecture Search (NAS) automates this by letting algorithms discover optimal designs.
A typical NAS pipeline (below) consists of three pillars: a Search Space, a Search Algorithm, and an Evaluation Strategy.
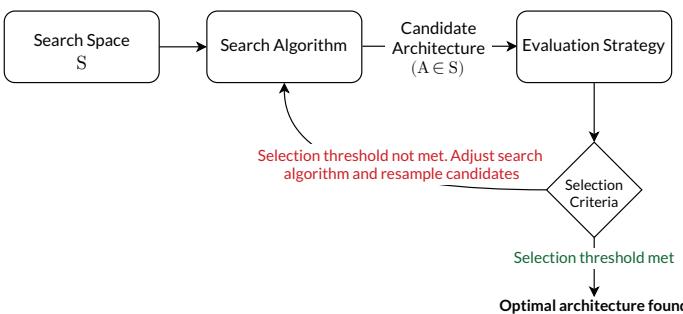
The general Neural Architecture Search framework.
1. The Search Space: The Universe of Possibilities
The search space defines what kinds of architectures can be explored:
- Layer-Wise Space: Each layer is sampled from a set of possible operations (e.g., convolution, pooling). Highly flexible but computationally huge.
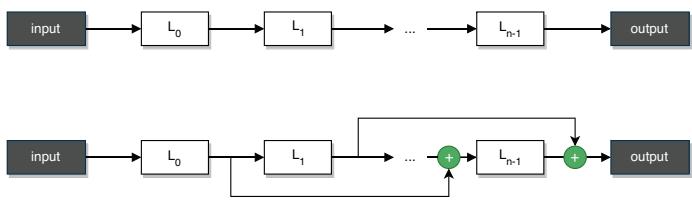
Layer-Wise search space: a simple sequential architecture (top) and one with skip-connections (bottom).
- Cell-Based Space: Architectures are built from small, reusable cells stacked in a predefined macro-structure. Efficient and widely used, it enabled state-of-the-art models like NASNet.
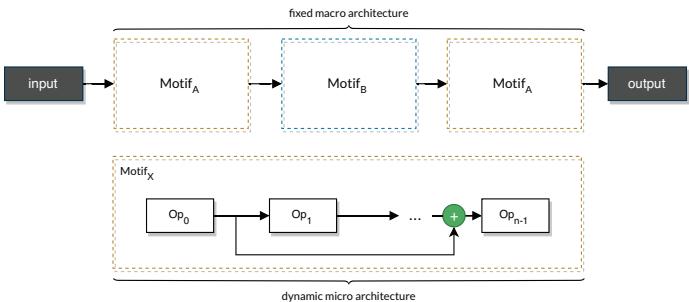
Generic example of a Cell-Based NAS topology.
2. The Search Algorithm: The Builder’s Logic
Several algorithms explore the search space:
- Reinforcement Learning: An agent designs architectures step-by-step and earns rewards for good performance.
- Neuroevolution: Populations of architectures evolve through selection, mutation, and crossover—mimicking biological evolution.
- Gradient Optimization: The search space is relaxed into a continuous form so gradient descent can optimize both the architecture and its weights; this underpins differentiable NAS methods like DARTS.
3. The Evaluation Strategy: The Inspector
The system needs a way to judge each candidate’s performance:
- Full Training: Each candidate is fully trained from scratch—accurate but extremely expensive.
- Lower Fidelity Estimation: Uses subsets or lower-resolution data to approximate performance quickly.
- Weight Inheritance: Passes weights from parent architectures to children to cut down training time.
- One-Shot Models: Train a single “supernet” that contains all possible sub-architectures. Sub-graphs share weights, slashing the search cost from weeks to hours.
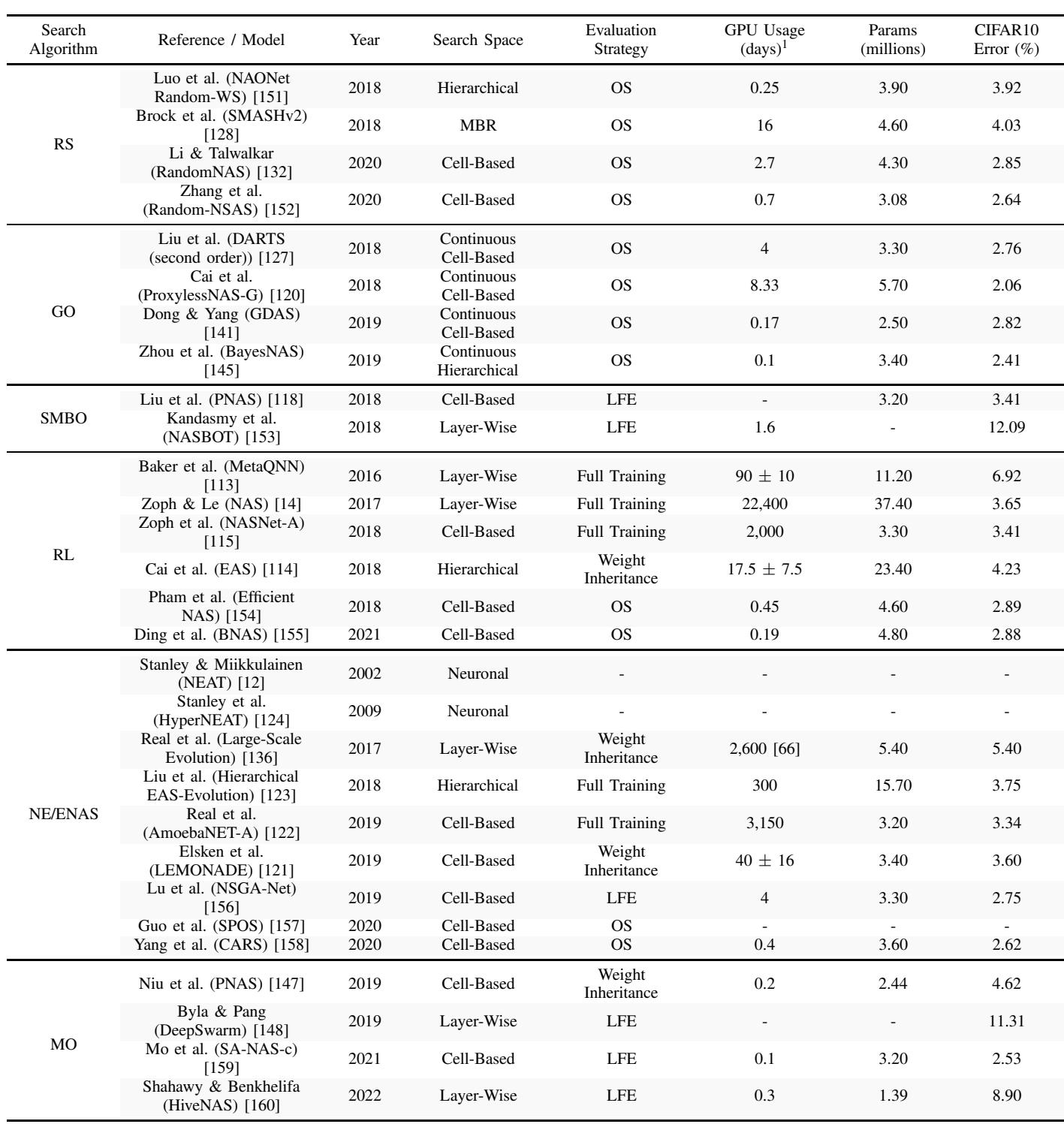
Performance comparison for NAS models based on search space, search algorithm, and evaluation strategy.
NAS represents a leap forward in automating model design, but most frameworks assume static data—a fixed task learned once. When the world changes, the architecture does not. That rigidity stands in stark contrast to continual adaptation, which leads us to CANNs.
The Synthesis: Continually-Adaptive Neural Networks (CANNs)
A Continually-Adaptive Neural Network merges the lifelong learning of CL with the self-design of NAS. Traditional CL models adapt their weights; traditional NAS models design one architecture per task. A CANN evolves its architecture and learns continuously across tasks.
According to the authors, a CANN is:
- Fully autonomous throughout its lifecycle.
- Inherently continual, equipped to prevent catastrophic forgetting.
- Able to handle infinite streams of input, adapting gracefully over time.
To accomplish this, a CANN must integrate not just learning but self-management—combining model and data adaptivity.
Proposed taxonomy for Continually-Adaptive Neural Networks.
The Components of a CANN
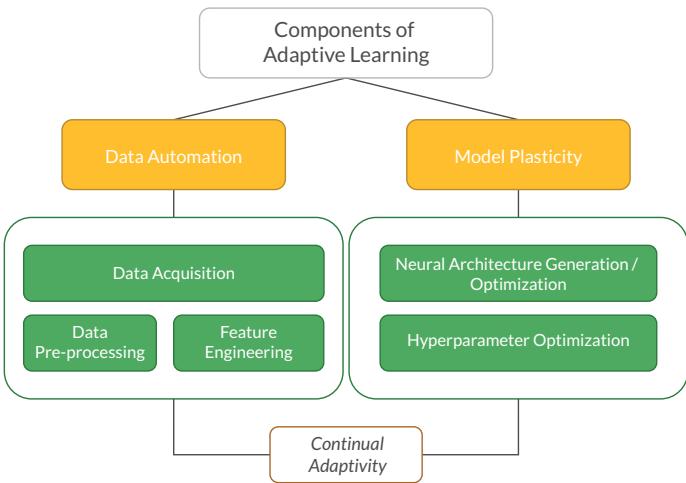
CANN frameworks revolve around two pillars: Model Plasticity and Data Automation.
- Model Plasticity: The engine uniting NAS and CL. The architecture can grow to handle new complexity, prune redundant connections, remap modules for new domains, and optimize hyperparameters dynamically.
- Data Automation: The system autonomously manages its data pipeline—collecting, cleaning, and engineering features without human intervention.
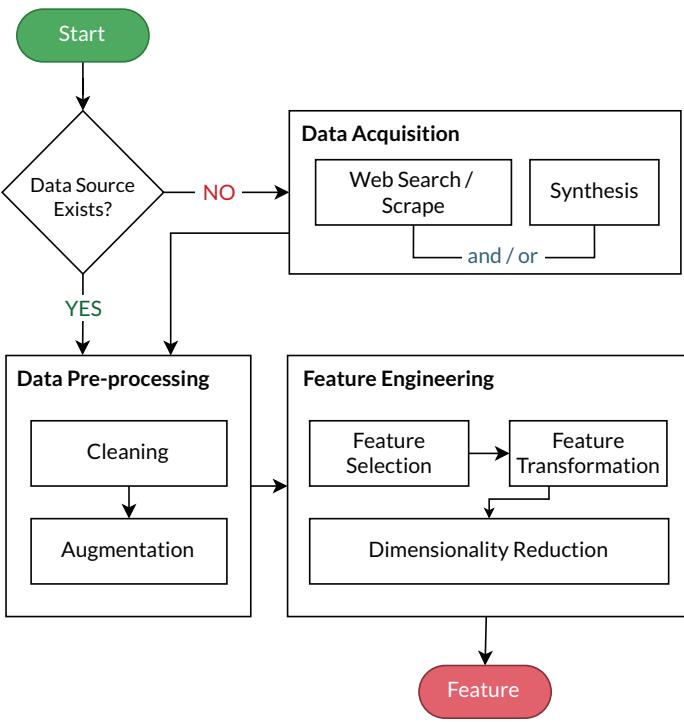
Continual Data Automation flowchart.
This pipeline includes:
- Data Acquisition: Gathering new data, either by web scraping or generating synthetic samples using GANs or simulators.
- Data Pre-processing: Cleaning noise, fixing missing values, and augmenting data to enrich variability.
- Feature Engineering: Selecting relevant features, transforming them for efficient learning, and reducing dimensionality automatically.
Early Models and Their Challenges
Researchers have started crossing CL and NAS with promising but imperfect results.
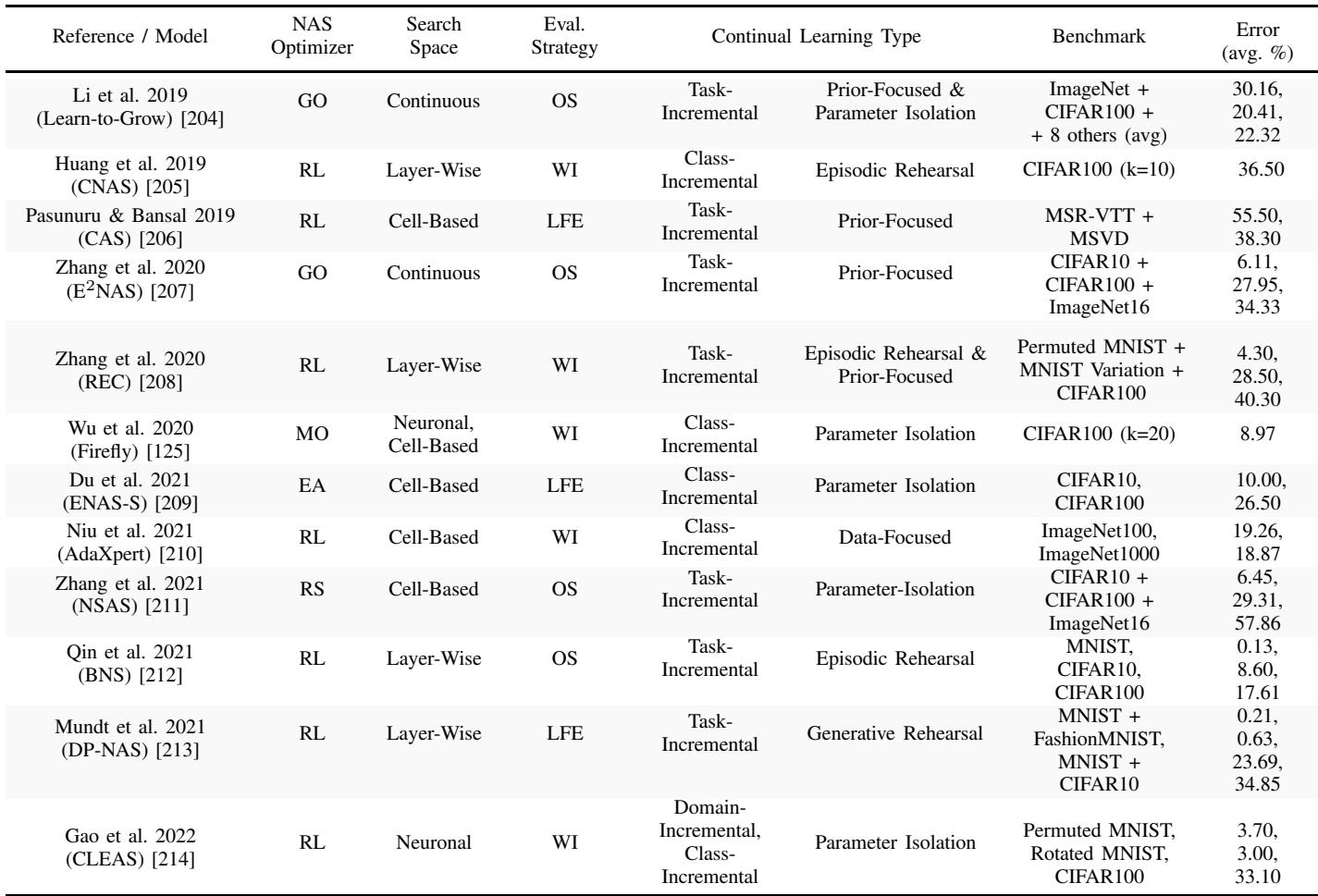
Comparison of existing Continually-Adaptive Neural Network models.
Models like Learn-to-Grow and ENAS-S expand their architecture for every new task, preventing forgetting but endlessly increasing size. Replay-based approaches such as CNAS and BNS require large external memory. Meanwhile, AdaXpert triggers new architecture searches only when data shifts dramatically—a smarter idea but one that still assumes neatly separated tasks.
The Wish List: A Desiderata for Adaptable Intelligence
Building on these prototypes, the authors propose a “desiderata”—a set of qualities future CANNs should embody:
- Dynamic Architecture with Bounded Capacity: Networks should grow and shrink as needed, but within physical limits for real-world deployment.
- Graceful Forgetting: Forgetting must occur selectively and gradually, not catastrophically.
- Few-Shot Learning Capability: Past experience should boost rapid learning from minimal data (positive forward transfer).
- No Explicit Data Storage: Prefer parameter constraints over storing raw data, aligning with privacy and scalability goals.
- Domain-Agnostic Learning: Adapt continuously without human-defined task boundaries.
- Dynamic Search Space Inference: Automatically infer and adapt the pool of possible architectures for changing data streams.
These criteria outline what “true” adaptive learning could look like: a self-sustaining intelligence that builds, learns, and redefines itself autonomously.
The Road Ahead: Challenges and Future Directions
The vision of CANNs is thrilling but demanding. Combining NAS and CL means stacking two resource-hungry processes. Future research must focus on making autonomy efficient—reducing cost through clever integrations of search, evaluation, and learning.
Key research needs include:
- Benchmarking: Standard evaluation metrics for continuous adaptation, beyond simple accuracy.
- Unexplored Algorithms: Metaheuristic approaches like swarm or ant colony optimization could power more parallel, exploratory searches.
- True Autonomy: Models must someday define their own goals—a leap toward Artificial General Intelligence (AGI).
- Safety and Reliability: Autonomous systems must safeguard data integrity and prevent erratic self-modification in sensitive domains.
Conclusion: From Static Tools to Living Learners
For decades, AI has been defined by narrow specialization—one model, one task. Yet the real world is not static; it is a fluid, continuous stream of change.
Continually-Adaptive Neural Networks offer a pathway to overcome this limitation, merging the lifelong learning of CL with the self-design power of NAS. These systems could represent the next step in AI evolution—a shift from rigid algorithms to dynamic entities that learn and adapt like living organisms.
Creating AI that is born to learn is just beginning. The challenges are immense, but the potential is transformative: machines that evolve, not just execute—capable of meeting the unpredictability of life with the same flexibility and creativity that define intelligence itself.