](https://deep-paper.org/en/paper/2312.00276/images/cover.png)
“Enemies of memories are other memories.” — David Eagleman
This observation from neuroscientist David Eagleman perfectly captures one of the most stubborn challenges in artificial intelligence: catastrophic forgetting.
Imagine teaching a neural network to identify cats. It learns well, achieving high accuracy. Now, you teach that same network to identify dogs. It masters the new task — but when you show it a picture of a cat again, it’s clueless. The knowledge of “dog” has overwritten the knowledge of “cat.”
This is one of the biggest obstacles to truly intelligent, general-purpose AI systems. We want agents that can learn continuously across their lifetimes, accumulating skills in ever-changing environments, just as humans do. But conventional neural networks, trained with standard optimization algorithms like gradient descent, are fundamentally flawed for lifelong learning. They are designed to solve one problem at a time — and in doing so, erase the past.
For decades, researchers have tried to prevent forgetting by engineering clever learning tricks: adding regularizers, freezing important weights, or replaying old data. But what if, instead of designing a solution, we could let the AI learn its own solution?
This is the bold premise of Metalearning Continual Learning Algorithms by Irie, Csordás, and Schmidhuber. The researchers propose Automated Continual Learning (ACL), a method that trains a self-modifying neural network to discover its own continual learning algorithm. By framing the problem of continual learning as one long sequence-processing task, ACL learns an internal learning rule that explicitly preserves old knowledge while mastering new tasks.
This post unpacks how ACL teaches a neural network to teach itself to remember. We’ll explore:
- The challenge of continual learning and the idea of in-context learning.
- The unique self-referential network architecture that lets a model rewrite its own weights.
- The meta-objective that encodes the desire to remember.
- The experimental results showing ACL outperforming many handcrafted algorithms.
Background: Building Blocks of a Self-Learning System
To understand ACL, we’ll first review three key concepts: the problem it’s solving (Continual Learning), the paradigm it uses (Metalearning as Sequence Learning), and the architectural tool it’s built on (Self-Referential Weight Matrices).
1. The Challenge: Continual Learning (CL)
Continual Learning (CL) — sometimes called lifelong learning — aims to enable models that can learn multiple tasks in sequence without forgetting earlier ones.
A good CL system is evaluated by three metrics:
- Task Performance: How well does the model learn each new task?
- Backward Transfer: How does learning a new task affect performance on old tasks? Negative backward transfer is catastrophic forgetting; positive backward transfer means learning new information helps old knowledge.
- Forward Transfer: How does past learning help in future tasks? Positive forward transfer means the model learns faster and better over time.
Many CL methods exist. Some use replay memory to store old data. Others freeze or regularize important weights. ACL is different: it uses no external memory and keeps the model size fixed. It tackles forgetting by addressing the root cause — the learning algorithm itself.
2. The Paradigm: Metalearning as Sequence Learning
The insight that powers ACL is that learning itself can be treated as sequence processing.
In metalearning — or “learning to learn” — a model is trained not to solve one fixed task, but to learn how to learn multiple tasks. This is the principle behind few-shot learning and modern in-context learning in large language models (LLMs).
Here’s how it works: imagine a sequence model, such as a Transformer, that processes a stream of input-label pairs — the demonstrations for a task. After finishing these, we feed a new input (a query) without its label, and the model must output a prediction.
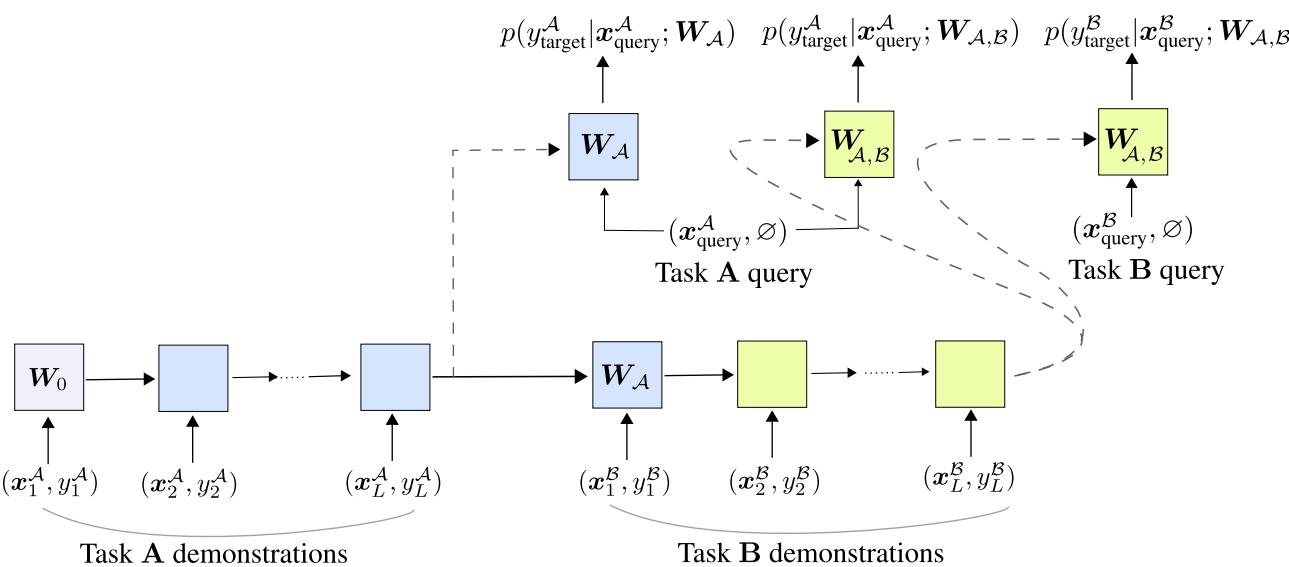
Figure: An in-context learner takes a series of (image, label) pairs as demonstrations and then predicts labels for new queries.
During meta-training, the model sees thousands of such episodes, each representing a different task (classifying distinct object sets, characters, etc.). It’s optimized via gradient descent to perform well on unseen queries after processing demonstrations — no explicit “training” loops are needed.
In essence, the model learns a learning algorithm inside its weights. The act of learning happens during its forward pass: as it processes examples, it implicitly updates its own internal representations.
3. The Tool: Self-Referential Weight Matrices (SRWMs)
To create in-context learners capable of lifelong adaptation, the authors use a specialized layer called a Self-Referential Weight Matrix (SRWM).
An SRWM is not a static parameter; it’s a matrix that updates itself as data flows through it. It belongs to the family of Linear Transformers, also known as Fast Weight Programmers (FWPs). Unlike standard Transformers, whose complexity grows quadratically with sequence length, SRWMs scale linearly and maintain constant state size — perfect for continuous lifelong sequences.
At every timestep \(t\), the matrix \(W_{t-1}\) receives an input \(\boldsymbol{u}_t\) and produces not only an output \(\boldsymbol{o}_t\), but also internal components — the query \(\boldsymbol{q}_t\), key \(\boldsymbol{k}_t\), and a self-generated learning rate \(\beta_t\). It then computes the updated matrix \(W_t\) using a delta learning rule:
\[ W_t = W_{t-1} + \sigma(\beta_t) (\boldsymbol{v}_t - \bar{\boldsymbol{v}}_t) \otimes \phi(\boldsymbol{k}_t) \]The intuition behind these equations is simple: the network learns how to modify its own weights in response to new data.
Only the initial weight matrix \(W_0\) is directly trained — it encodes the meta-algorithm for learning. Through meta-training, gradient descent shapes \(W_0\) so that each subsequent self-update (\(W_t\)) achieves the desired continual learning behavior.
Automated Continual Learning (ACL)
The ACL method combines the continual learning problem with the in-context learning framework.
If one task can be represented by a sequence of examples, then multiple tasks in sequence (Task A followed by Task B) can be represented as a single long concatenated sequence:
\[ (\text{Task A demos}, \text{Task B demos}) \]The SRWM-based model processes this long sequence left to right. After encountering Task A examples, its internal state becomes \(W_A\). After seeing Task B, its state evolves into \(W_{A,B}\).
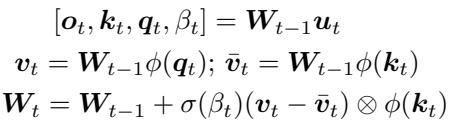
Figure: ACL’s sequence-processing setup. The model is evaluated on both old and new tasks to encourage backward and forward transfer.
The ACL Objective
At every task boundary, ACL tests the model on every task learned so far. During training, it minimizes a combined objective across these predictions: [
- \Big[ \log p(y_A | x_A; W_A) + \log p(y_B | x_B; W_{A,B}) + \log p(y_A | x_A; W_{A,B}) \Big] ]
Let’s decode what this means:
- \(p(y_A | x_A; W_A)\) — Learn Task A normally after its demos.
- \(p(y_B | x_B; W_{A,B})\) — Learn Task B using prior experience, promoting forward transfer.
- \(p(y_A | x_A; W_{A,B})\) — Remember Task A even after learning Task B, promoting backward transfer.
That third term is the key: it explicitly encodes “remembering” into the learning objective. The meta-training loop forces gradient descent to discover an internal learning rule that can update itself without erasing prior knowledge.
Once trained, ACL runs autonomously. Its neural weights evolve recursively — adapting to new data while preserving previously learned skills.
Experiments: Learning to Remember
1. Proving In-Context Forgetting Exists
The authors first demonstrate that ordinary in-context learners — without ACL — also suffer catastrophic forgetting. They used two sequential tasks (e.g., Omniglot → Mini-ImageNet) and compared models trained with and without the backward transfer term.
The results are revealing.
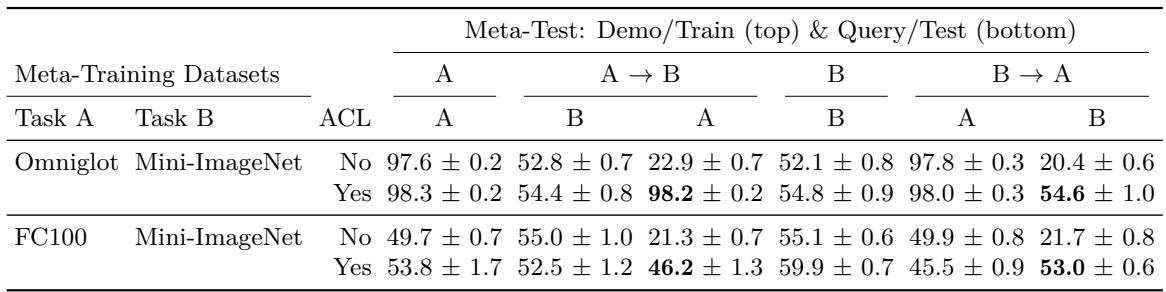
Figure: ACL prevents catastrophic forgetting across two tasks.
Without ACL, performance on Task A drops to chance level (around 22%) after learning Task B. With ACL, accuracy on Task A remains above 98%, showing effective retention.
The same holds true when testing on unseen datasets like MNIST and CIFAR-10:
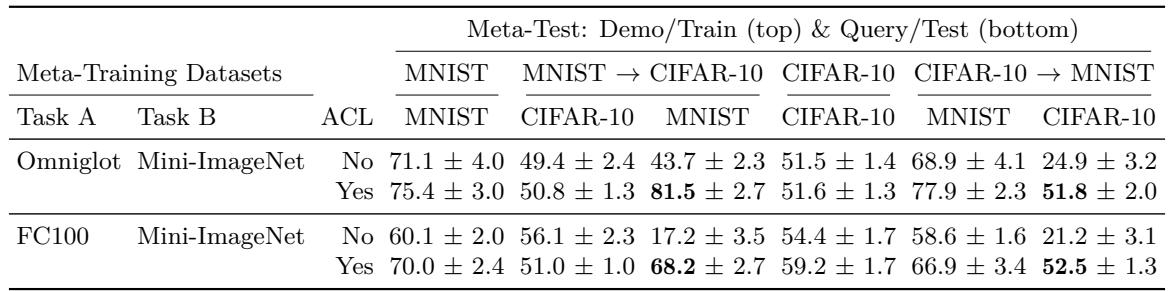
Figure: ACL generalizes well to unseen datasets, preventing in-context forgetting.
2. Diagnosing Forgetting
To understand why in-context learners forget, the authors tracked meta-training losses for each dataset over time.
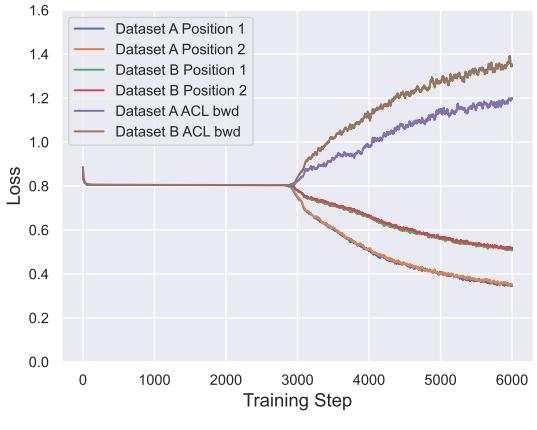
Figure: Opposing forces — learning new tasks causes forgetting without ACL’s backward-transfer loss.
They observed that when the model improved on new tasks, its backward-transfer loss grew — a clear trade-off between learning and remembering. ACL’s extra loss term eliminates this conflict, leading to balanced performance across tasks.
3. Benchmarking on Split-MNIST
To test generalization, ACL-trained models were evaluated on the Split-MNIST benchmark: five sequential 2-way classification tasks (0–1, 2–3, 4–5, 6–7, 8–9).
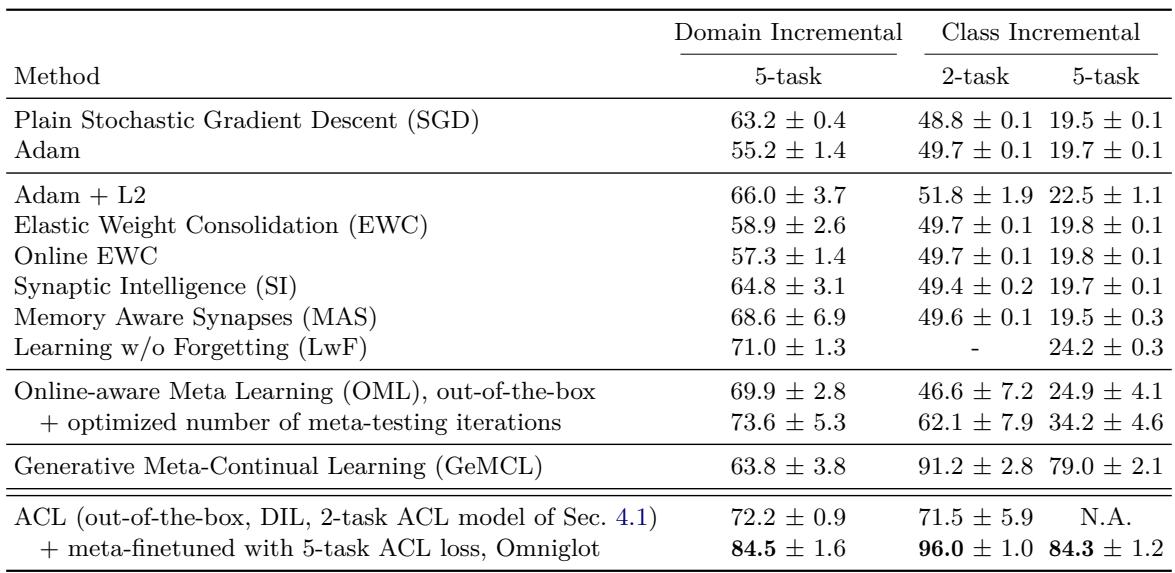
Figure: Split-MNIST results. ACL achieves state-of-the-art replay-free accuracy.
Even when trained only on different datasets (Omniglot and Mini-ImageNet), ACL’s learned algorithm performs competitively. After meta-finetuning for 5 tasks, ACL surpasses all existing replay-free algorithms, achieving 84–96% accuracy depending on the setting — significantly better than classical methods like EWC, SI, or Adam-based optimization.
4. Scaling to Tougher Tasks
Modern continual learning benchmarks often rely on large pretrained Vision Transformers (ViTs) with task-specific “prompting” methods like L2P and DualPrompt. The authors tested using ACL atop a frozen ViT to explore scalability.
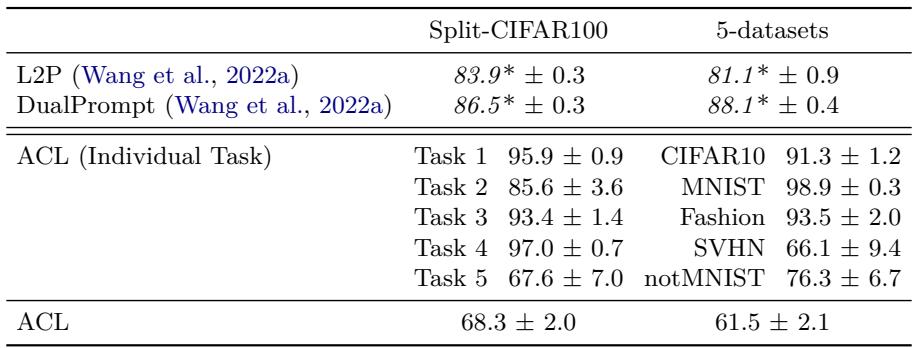
Figure: Results on Split-CIFAR100 and 5-Datasets benchmarks.
In these complex settings, ACL’s performance drops. The reason is intuitive — its meta-training used limited datasets (Omniglot and Mini-ImageNet). In-context learners require diverse meta-training experiences to generalize broadly. Scaling ACL’s meta-training to larger dataset collections could bridge this gap.
Interpreting the Learned Algorithm
The ACL model’s learning behavior arises entirely from self-modifying dynamics within SRWM layers. But what does that look like inside?
The authors visualized the evolving weight matrices as the model processed sequential tasks.

Figure: SRWM weight visualization while learning Task 1.

Figure: SRWM dynamics while learning Task 2.
These intricate patterns demonstrate rich temporal dynamics. Though difficult to interpret directly, they hint at self-organized learning mechanisms — perhaps analogous to human synaptic adaptation. Making these patterns interpretable is a promising direction for future research.
Broader Implications
1. Automating Algorithm Design
ACL represents a milestone in automated AI research: it enables neural networks to discover their own learning rules. Instead of humans handcrafting solutions to catastrophic forgetting, gradient descent itself learns what continual learning should look like.
2. Learned Algorithms as Black Boxes
The learned mechanisms in SRWMs are difficult to dissect — a reminder that powerful meta-learning systems may design strategies we do not yet understand. Future interpretability research could extract readable algorithmic principles from these networks.
3. Connection to Large Language Models
ACL offers insight into the remarkable in-context learning ability of modern LLMs. Trained on massive, diverse sequences, LLMs effectively perform continual in-context adaptation. It’s plausible that real-world data naturally induces ACL-like objectives — enabling large models to become “natural” continual learners.
Conclusion
Automated Continual Learning (ACL) trains neural networks to learn how to learn continually. By encoding the core goals of continual learning — remembering old tasks and mastering new ones — directly into its meta-objective, ACL lets gradient descent discover a self-referential learning rule that works.
Once trained, ACL operates autonomously, modifying its own weights as it encounters new tasks, without external memory or human-designed tricks. Experiments show it can overcome catastrophic forgetting and even outperform traditional approaches on standard benchmarks.
While today’s ACL models remain small, the vision they propose is vast: scalable self-improving systems that evolve their own learning algorithms over time. This is a glimpse of the future — AI that not only learns, but learns to learn better as it grows.