](https://deep-paper.org/en/paper/2402.01348/images/cover.png)
Imagine teaching your smart home assistant to recognize your family members. It learns your parents, your siblings, and your partner flawlessly. Then you bring home a new puppy and teach it to recognize the pet. The next day, you ask it to identify your mom—and suddenly it has no idea who she is. It has completely forgotten.
This frustrating scenario illustrates a phenomenon in artificial intelligence called catastrophic forgetting. Deep neural networks, although powerful, struggle to learn new information sequentially without losing previously acquired knowledge. This limitation keeps AI from achieving true lifelong learning—the ability to continuously acquire, integrate, and apply knowledge just like humans do.
A recent paper, “CORE: Mitigating Catastrophic Forgetting in Continual Learning through Cognitive Replay,” confronts this issue head-on. The researchers take inspiration from the human brain’s memory systems to propose a smarter approach called COgnitive REplay (CORE). Their method doesn’t just help models remember—it makes them remember strategically, focusing on what is forgotten and how deeply the learned material is reinforced.
In this article, we’ll break down CORE’s ideas and see how it bridges neuroscience and machine learning to create more durable, lifelike AI memory.
The Challenge: Learning Without Forgetting
Continual Learning (CL) is a machine learning paradigm where models learn tasks sequentially from a continuous data stream. It’s essential for real-world contexts where inputs evolve over time—like self-driving cars encountering new road signs or cybersecurity systems detecting novel phishing patterns.
The problem? Catastrophic forgetting. When a neural network trains on a new task, it adjusts millions of internal parameters to perform well on that specific task. These adjustments often overwrite parameters learned for previous tasks, causing older knowledge to vanish.
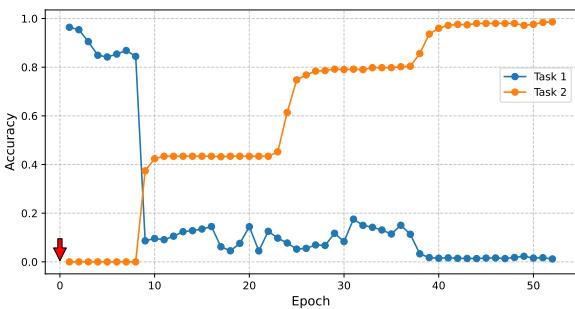
Figure 1: Task 1’s accuracy sharply declines as training begins on Task 2—an example of catastrophic forgetting.
This dramatic accuracy collapse makes continual learning especially challenging. To design AI that learns over time, we must mitigate this destructive cycle of learning and forgetting.
How Researchers Try to Prevent Forgetting
Three major approaches exist to tackle catastrophic forgetting:
Parameter Isolation: Assign distinct network parameters or modules to each task (e.g., Progressive Neural Networks). While effective, this approach scales poorly—memory usage grows linearly with the number of tasks.
Regularization: Penalize updates that significantly alter parameters important for past tasks. These methods (like EWC or LwF) depend on estimating parameter importance accurately—a difficult problem in large networks.
Data Replay: Store small subsets of past data in a “replay buffer.” When learning new tasks, the model retrains on both new and old samples, effectively “reviewing” its previous lessons.
Data replay mimics human studying habits—but most existing replay strategies treat all tasks and samples equally. This one-size-fits-all approach wastes buffer space on tasks the model already remembers, while neglecting those it’s rapidly forgetting.
CORE’s bold idea is to make replay cognitively adaptive: give more “review time” to tasks that are slipping away, and ensure the replay data is both diverse and representative.
Learning from the Brain: Cognitive Insights
Human memory is influenced by two main mechanisms of forgetting:
- Cognitive Overload: When too much new information is introduced, old memories are displaced because the system’s capacity is limited.
- Interference: New information overlaps or conflicts with older memories, weakening recall through shared representations.
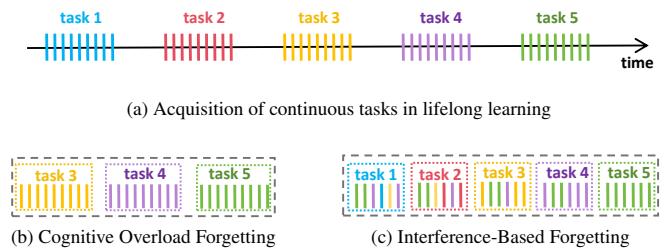
Figure 2: Human continual learning, showing (a) sequential task acquisition, (b) cognitive overload, and (c) interference-based forgetting.
Humans naturally counteract these effects using strategies like:
- Targeted Recall: Focus effort on weak or fading memories.
- Spaced Repetition: Review materials at gradually increasing intervals.
- Levels of Processing: Engage deeply with content to create richer, more permanent memories.
CORE translates these principles directly into the design of its learning system.
The CORE Method: Intelligence in Replay
CORE enhances replay-based learning through two innovations:
- Adaptive Quantity Allocation (AQA) —decides how much information from each past task should be stored for review.
- Quality-Focused Data Selection (QFDS) —chooses which samples best represent each task.
Together, they turn the replay buffer into a cognitively intelligent reviewer.
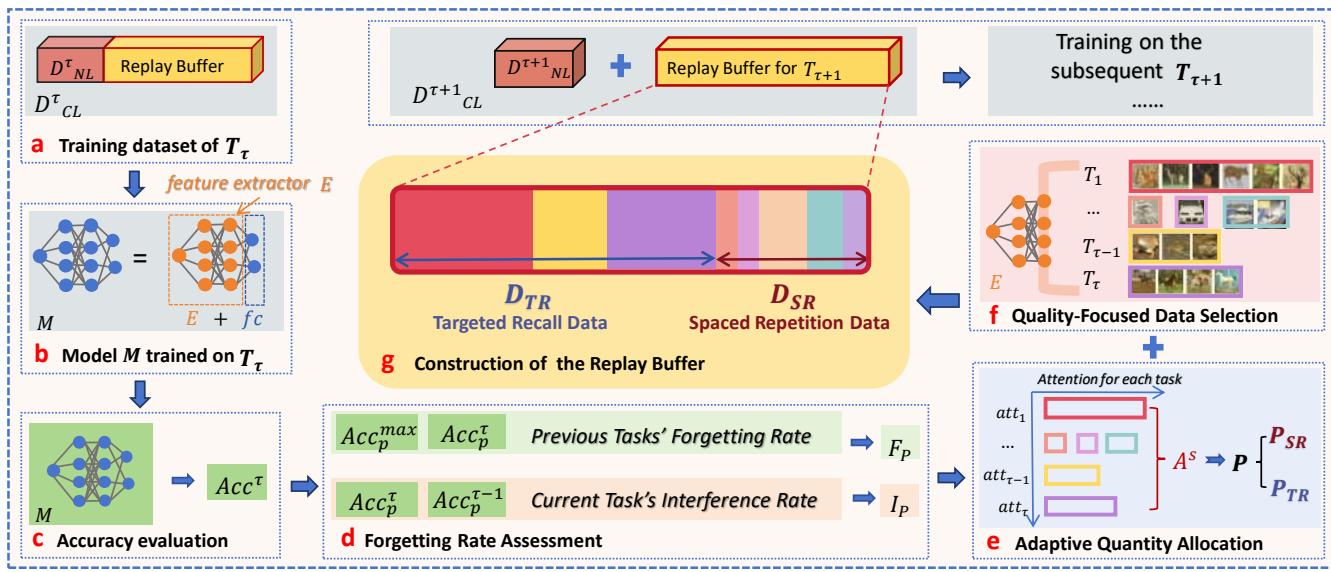
Figure 3: The CORE pipeline. After learning a task, the system measures forgetting and interference, then builds a replay buffer through adaptive allocation and quality-focused data selection.
Step 1: Diagnosing Forgetting
After the model finishes training on the current task \(T_{\tau}\), CORE measures how much each past task has been forgotten.
Previous Tasks’ Forgetting Rate: For each earlier task \(p\), CORE computes the drop in accuracy from its best-ever performance to its current value:
\[ F_{\mathcal{P}} = \left\{ f_p = \max_{i \in \{1, \dots, \tau-1\}} Acc_p^i - Acc_p^{\tau} \mid p \in \mathcal{P} \right\} \]High values of \(f_p\) indicate rapid forgetting.
Current Task’s Interference Rate: Since the newly learned task hasn’t yet experienced forgetting, CORE estimates how disruptive it was to previous tasks’ performance. The more interference it caused, the more likely it is to be forgotten later:
\[ I_{\mathcal{P}} = \left\{ i_p = \frac{e^{Acc_p^{\tau-1} - Acc_p^{\tau}}}{\sum_{p' \in \mathcal{P}} e^{Acc_{p'}^{\tau-1} - Acc_{p'}^{\tau}}} \mid p \in \mathcal{P} \right\} \]This normalized measure reveals how each task interacts during learning.
Step 2: Prescribing Review Time — Adaptive Quantity Allocation (AQA)
Once CORE diagnoses what’s being forgotten, it allocates replay buffer space intelligently.
Attention Calculation: Each task receives an “attention score” proportional to its forgetting or interference severity:
\[ att_p = -\log(1 - f_p) \]\[ att_{\tau} = -\log\left(1 - \sum_{p \in \mathcal{P}} f_p \cdot i_p \right) \]These scores are then normalized and used to divide tasks into two groups:
\[ p \in \begin{cases} \mathcal{P}_{SR}, & \text{if } att_p^s \le \frac{1}{\lambda | \mathcal{P} |} \\ \mathcal{P}_{TR}, & \text{if } att_p^s > \frac{1}{\lambda | \mathcal{P} |} \end{cases} \]- Targeted Recall (\(\mathcal{P}_{TR}\)): Highly forgotten tasks receive concentrated review.
- Spaced Repetition (\(\mathcal{P}_{SR}\)): Stable tasks receive smaller, periodic refreshers.
Then the buffer capacity is distributed accordingly:
\[ \hat{att}_p = \frac{1}{\lambda |\mathcal{P}|}, \quad \text{if } p \in \mathcal{P}_{SR} \]\[ \hat{att}_p = \left(1 - \frac{|\mathcal{P}_{SR}|}{\lambda |\mathcal{P}|}\right) \cdot \frac{att_p^s}{\sum_{p' \in \mathcal{P}_{TR}} att_{p'}^s}, \quad \text{if } p \in \mathcal{P}_{TR} \]This ensures the most vulnerable tasks are prioritized—an AI version of remembering what’s hardest.
Step 3: Choosing the Best Study Materials — Quality-Focused Data Selection (QFDS)
While AQA decides quantity, QFDS ensures quality. Instead of storing random samples, CORE selects representative, diverse examples from each class using the model’s latent feature space.
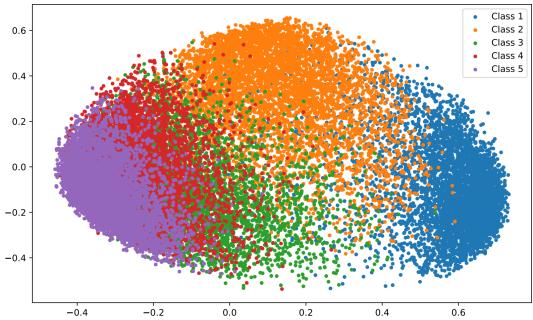
Figure 4: Feature space representation—different classes form distinct clusters that capture structural patterns.
CORE measures the mean feature vector of a class and iteratively picks samples that bring the subset’s mean closer to the full class mean. This avoids redundant selections and ensures balanced coverage of the feature space.

Figure 5: (a) Random selection causes clustering and bias. (b) CORE’s QFDS selects evenly distributed samples around the class feature center.
This approach echoes deep processing in human learning—the more varied and representative the review materials, the stronger the retention.
Does It Actually Work?
The researchers tested CORE on well-known benchmarks: split-MNIST, split-CIFAR10, and split-CIFAR100. They evaluated models using:
- Average Accuracy (\(Acc_{avg}\)) —average performance across tasks
- Minimum Accuracy (\(Acc_{min}\)) —lowest performance among tasks, revealing balance and fairness
| Dataset | Metrics | iCaRL | ER | DGR | LwF | EWC | CORE (Ours) | Upper Bound |
|---|---|---|---|---|---|---|---|---|
| split-MNIST | Acc_avg Acc_min | 88.00 78.97 | 92.39 87.47 | 85.46 63.85 | 10.00 0.00 | 10.00 0.00 | 94.52 89.94 | 97.81 95.64 |
| split-CIFAR10 | Acc_avg Acc_min | 32.62 5.80 | 29.74 10.00 | 13.00 0.00 | 10.00 0.00 | 10.00 0.00 | 37.95 16.30 | 65.03 44.30 |
| split-CIFAR100 | Acc_avg Acc_min | 24.02 15.50 | 25.41 18.70 | 6.31 0.00 | 10.35 0.10 | 6.14 0.00 | 27.24 20.40 | 37.95 32.60 |
CORE consistently delivers higher average and minimum accuracies, showing both better overall learning and stronger retention. Notably, its lowest accuracy improves by 6.30% over the strongest baseline—a powerful indicator of balanced memory.
Long-Term Performance
The authors also tracked how well the first task endured as new tasks were added.
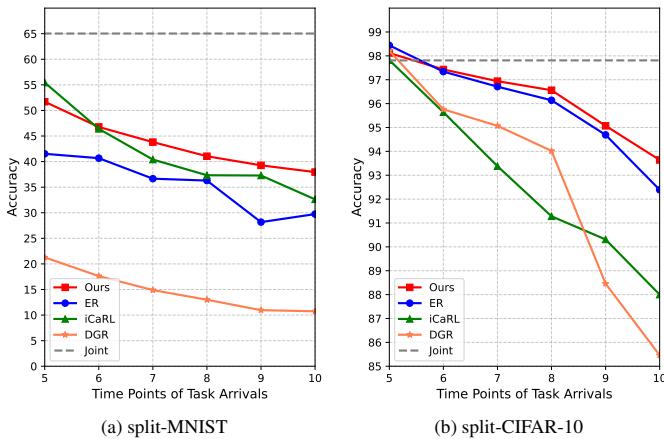
Figure 6: Accuracy over successive tasks. CORE (red) maintains much higher retention compared to other replay methods.
While other methods show sharp declines, CORE’s accuracy decreases gradually—evidence that its replay strategies effectively protect earlier knowledge.
Ablation Study: What Makes CORE Work
To verify the contributions of each component, the authors performed an ablation study on the split-CIFAR10 dataset.
| Method | Acc_avg | Acc_min |
|---|---|---|
| CORE (Full) | 37.95 | 16.30 |
| CORE w/o AQA | 32.78 | 11.00 |
| CORE w/o QFDS | 31.52 | 12.40 |
| CORE w/o AQA+QFDS | 29.74 | 10.00 |
Removing AQA drastically lowered the worst-task accuracy, while omitting QFDS cut the average accuracy most severely. Together, they form a complementary pair—AQA preserves balance, and QFDS ensures high-quality learning.
Conclusion: Toward Lifelong Learning in AI
Catastrophic forgetting has long undermined the dream of lifelong AI learning. The CORE framework offers an elegant fix by infusing machine learning with principles of human memory.
Through Adaptive Quantity Allocation (smart buffer management) and Quality-Focused Data Selection (representative sample choice), CORE transforms replay into a genuinely cognitive process. It doesn’t just rehearse data—it prioritizes what truly matters and does so with quality and intention.
By blending neuroscience-inspired insights with engineering precision, CORE moves us a step closer to creating AI systems that learn continuously and remember what they’ve learned—just like we do.