](https://deep-paper.org/en/paper/2402.11129/images/cover.png)
Large Language Models (LLMs) have revolutionized how we process information, acting as capable assistants for summarization, dialogue, and question answering. However, anyone who has used them extensively knows their Achilles’ heel: they don’t know everything. Their knowledge is frozen in time at the moment of training, and they can confidently “hallucinate” incorrect facts.
To solve this, the AI community adopted Retrieval-Augmented Generation (RAG). The idea is simple: before the LLM answers, it searches a database (like Wikipedia), finds relevant documents, and uses that information to generate an answer.
But standard RAG has hit a wall. When users ask complex, multi-hop questions (questions that require connecting two distinct pieces of information), standard retrieval often fails to find the right documents. Furthermore, if the retriever brings back irrelevant “noise,” the LLM gets confused and produces bad answers.
In this post, we are diving deep into a new framework called BlendFilter. This approach, proposed by researchers from SUNY Albany, Purdue, Georgia Tech, and Amazon, significantly advances RAG by introducing two clever mechanisms: Query Generation Blending to cast a wider net for information, and Knowledge Filtering to meticulously separate useful data from noise.
The Problem with Standard Retrieval
To understand why BlendFilter is necessary, we first need to look at where current methods fail.
1. The Complex Query Challenge
Imagine asking an LLM: “Which film came out first, Blind Shaft or The Mask Of Fu Manchu?”
A standard retriever takes this query literally. It looks for documents containing these keywords. However, complex questions often require “implicit” knowledge. If the retriever misses the release date of Blind Shaft, the LLM cannot answer the question. Standard RAG relies on a single shot at retrieval using the user’s raw input, which is often insufficient for questions that require reasoning before searching.
2. The Noise Problem
Current methods often retrieve the top-K documents (e.g., the top 5 or 10 matches). But retrieval isn’t perfect. Maybe only 2 of those documents are relevant, and the other 3 are about completely different topics with similar keywords. When you feed unrelated “noise” into an LLM, it often tries to force a connection where none exists, leading to hallucinations.
Previous attempts to fix this involved training separate “rewriter” models or complex classifiers to filter data. These are computationally expensive and difficult to implement. BlendFilter offers a more elegant solution.
The BlendFilter Framework
BlendFilter is designed to answer the question: How can we ensure we retrieve everything we need without drowning the LLM in noise?
The solution is a three-step pipeline:
- Query Generation Blending: Create multiple, augmented versions of the query to ensure we find all relevant documents.
- Knowledge Filtering: Use the LLM’s own reasoning capabilities to discard irrelevant documents.
- Answer Generation: Produce the final response using only the high-quality, filtered data.
Let’s visualize the architecture before breaking it down:
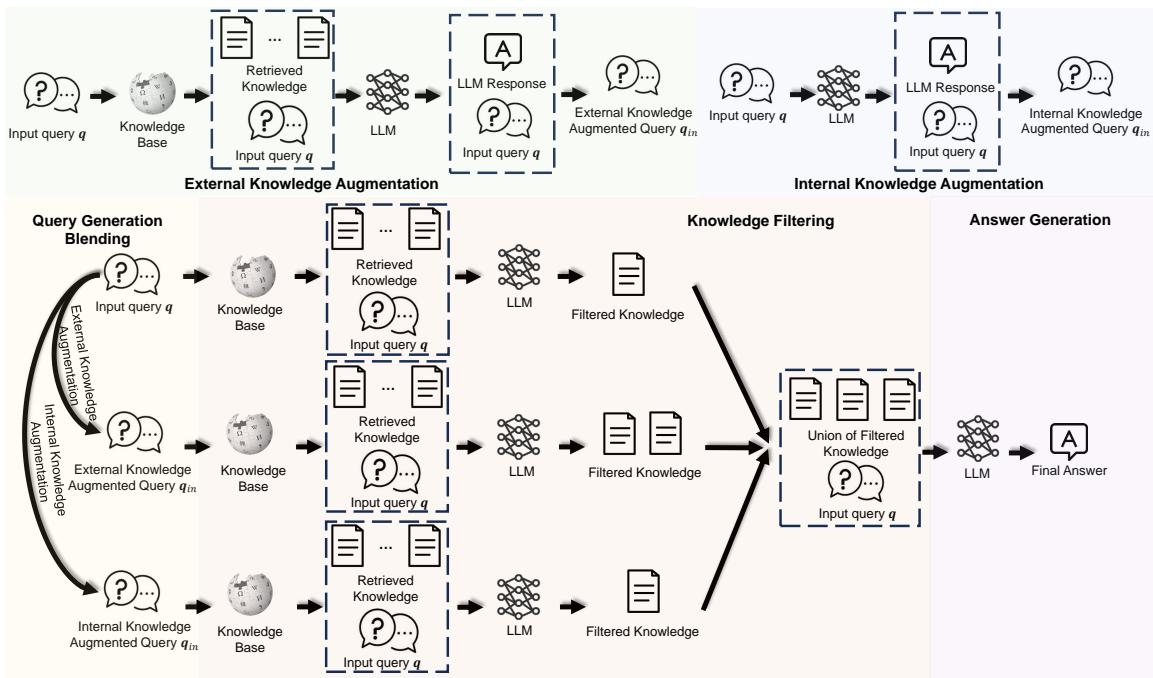
As shown in Figure 1, the process splits into parallel paths (augmentation) that converge into a filtering stage. Let’s explore these components in detail.
Part 1: Query Generation Blending
The researchers realized that relying on a single source for query augmentation is risky. If you only use external knowledge, you might miss logical connections the LLM already knows. If you only use the LLM’s internal knowledge, you risk hallucinations.
BlendFilter uses a hybrid approach, combining three distinct query types:
1. The Original Query (\(q\))
This is the raw input from the user. It is preserved to ensure the original intent is never lost during the process.
2. External Knowledge Augmentation (\(q_{ex}\))
This handles the “unknown unknowns.” For complex questions, the model performs a preliminary retrieval.
- The system retrieves documents based on the original query.
- The LLM generates a preliminary answer or “Chain-of-Thought” reasoning based on these docs.
- This generated reasoning is concatenated with the original query to form \(q_{ex}\).
This is essentially a “two-hop” reasoning trick. By letting the model “think” about the first batch of documents, it generates new keywords that might be necessary to find the rest of the answer.
3. Internal Knowledge Augmentation (\(q_{in}\))
LLMs already have vast amounts of memorized knowledge. Even if they can’t answer the specific question perfectly, they might know context that helps retrieval.
- The system asks the LLM to generate a passage answering the question using only its internal memory.
- This generated passage is concatenated with the original query to form \(q_{in}\).
By blending these three queries (\(q\), \(q_{ex}\), and \(q_{in}\)), the system creates a comprehensive search strategy that covers both external databases and internal semantic understanding.
Part 2: Knowledge Filtering
By using three different queries, we have cast a very wide net. While this ensures we likely caught the right answer, it also means we’ve likely pulled in a lot of irrelevant documents (noise).
If we simply fed all these documents into the LLM, the noise would overwhelm the signal. This is where the Knowledge Filtering module comes in.
Instead of training a separate BERT classifier or a complex neural network to judge relevance, BlendFilter prompts the LLM itself to act as the filter. The researchers feed the retrieved documents and the original query into the LLM with a specific instruction: Identify and select only the documents relevant to answering this query.
This is done independently for each query stream:
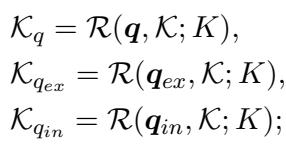
Once the knowledge is retrieved for each stream, it is filtered. Finally, the system takes the union of these filtered sets:
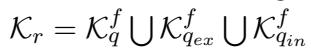
This results in a curated list of documents (\(K_r\)) that is high in relevance and low in noise.
Comparison with Other Methods
It is helpful to see how BlendFilter differs from other popular RAG techniques like ReAct or ITER-RETGEN.
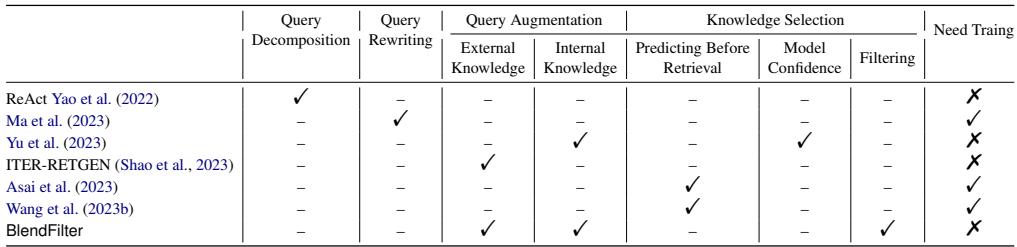
As Table 6 illustrates, BlendFilter is unique because it combines both external and internal augmentation and includes a specific filtering step, all without requiring the training of auxiliary models.
Experiments and Results
To prove the effectiveness of BlendFilter, the authors tested it on three challenging open-domain QA benchmarks:
- HotPotQA: Requires multi-hop reasoning.
- 2WikiMultihopQA: Another dataset requiring the connection of multiple facts.
- StrategyQA: Focuses on implicit reasoning strategies.
They tested the framework using three different LLM backbones: GPT-3.5-turbo-Instruct, Vicuna 1.5-13b, and Qwen-7b.
Main Performance
The results were impressive across the board. Below is the performance table using GPT-3.5-turbo-Instruct.
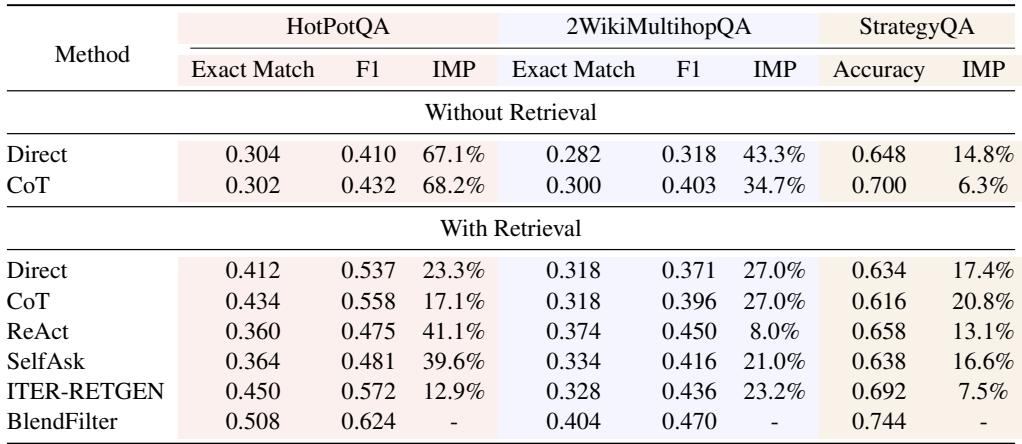
On HotPotQA, BlendFilter achieved an Exact Match (EM) score of 0.508, significantly outperforming the state-of-the-art ITER-RETGEN (0.450) and standard CoT with Retrieval (0.434). The improvement (IMP) column highlights gains of nearly 13-40% over various baselines.
Does this hold true for smaller, open-source models? Yes.
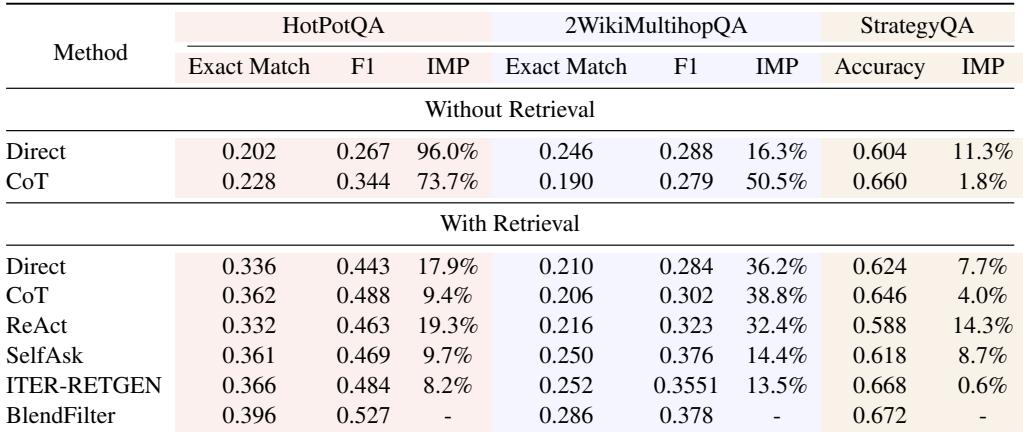
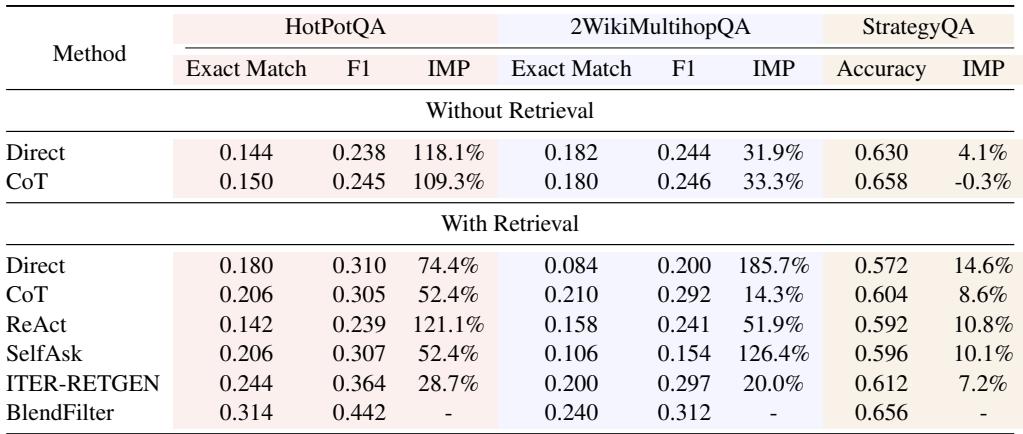
As shown in Table 2 (Vicuna) and Table 3 (Qwen), BlendFilter consistently provides the best performance. This demonstrates that the method is model-agnostic; it improves the reasoning of both massive proprietary models and smaller open-source ones.
Does the Filtering Actually Work?
One might wonder: Is the improvement coming from the “Blending” (more queries) or the “Filtering”? The answer is both, but the filtering is crucial for precision.
The researchers analyzed the retrieval quality using a Radar Chart to measure Precision, Recall, and “S-Precision” (matches with golden relevant documents).
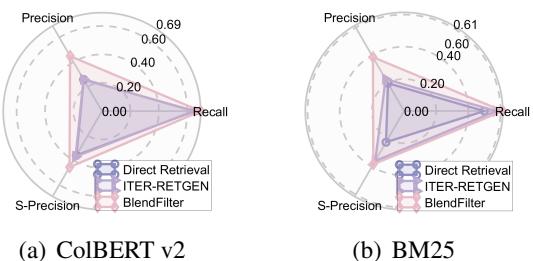
In Figure 2, looking at the ColBERT v2 chart (left), we see that BlendFilter (pink line) maintains high Recall (finding the right docs) while keeping Precision high. ITER-RETGEN has good recall but lower precision, meaning it drags in too much noise.
Ablation Studies: Do we need all three queries?
Is it necessary to generate both external and internal augmented queries? The researchers performed an ablation study where they removed specific query types to see how performance dropped.
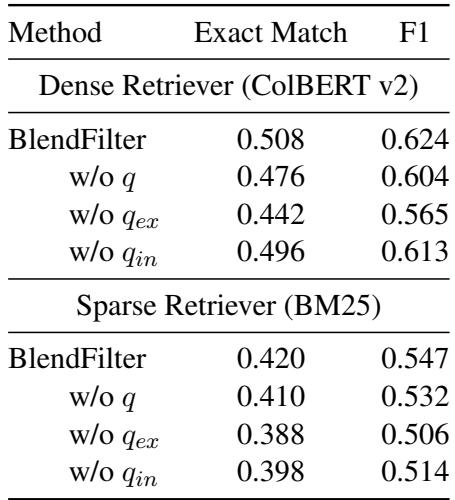
Table 5 shows that removing any of the three query types results in a performance drop.
- Removing \(q_{ex}\) (External) hurts significantly because the model loses the “two-hop” search capability.
- Removing \(q_{in}\) (Internal) also hurts, confirming that the LLM’s internal memory provides context that external search engines might miss.
Impact of Document Count (K)
How many documents should we retrieve? In standard RAG, increasing the number of documents (\(K\)) often hurts performance after a certain point because the noise becomes overwhelming.
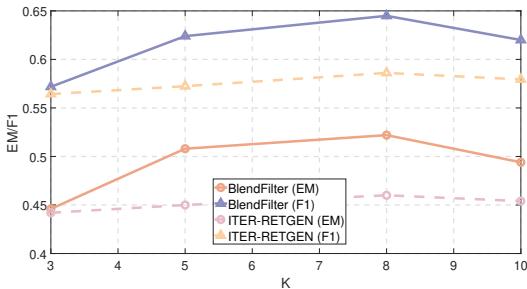
Figure 3 reveals a key strength of BlendFilter. While ITER-RETGEN (purple lines) sees marginal gains or plateaus as \(K\) increases, BlendFilter (pink lines) continues to improve up to \(K=8\). Because BlendFilter has an active filtering mechanism, it can handle a larger pool of retrieved documents without getting confused, effectively extracting value from the larger search space.
Consistency and Sampling
Finally, the researchers checked if the model is just “getting lucky” or if it is consistently better. They tested performance when sampling multiple answers (Top-P sampling).
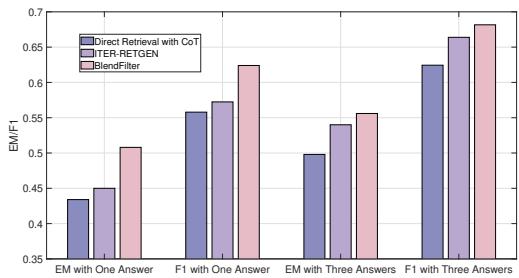
Figure 4 shows that whether checking the “EM with One Answer” or “EM with Three Answers,” BlendFilter outperforms the competition. It exhibits lower variance, meaning it is more reliable in production environments.
Conclusion and Implications
The BlendFilter paper presents a compelling argument for a more sophisticated approach to Retrieval-Augmented Generation. It identifies that the two biggest bottlenecks in RAG are limited search scope (solved by Blending) and information overload (solved by Filtering).
Key takeaways for students and practitioners:
- Don’t trust a single query: User queries are often imperfect. Augmenting them with both external search results and internal model knowledge creates a robust search strategy.
- LLMs are good filters: You don’t always need a specialized classifier. A well-prompted LLM can effectively critique its own retrieved data, separating relevant context from noise.
- Generalization: This framework works across different model architectures and retrieval types (sparse BM25 and dense ColBERT), making it a versatile tool for AI engineering.
As LLMs continue to integrate into complex workflows, techniques like BlendFilter will be essential for moving beyond simple chatbots to systems capable of rigorous, multi-step research and reasoning.