](https://deep-paper.org/en/paper/2402.19467/images/cover.png)
Imagine you are watching a scene from the TV show Friends. Chandler makes a sarcastic comment, and Monica rolls her eyes. You immediately understand that Monica is annoyed. But how did you get there? You combined visual cues (the eye roll) with auditory information (Chandler’s tone) and your understanding of social dynamics.
Now, imagine asking an Artificial Intelligence model: “How does Monica feel?”
A modern video-language model might correctly answer, “She is annoyed.” But if you ask why, the model usually can’t tell you. It’s a “black box”—it ingested pixels and text and spat out an answer based on statistical correlations, not a traceable chain of logic.
This lack of interpretability is a massive hurdle in AI. If we want to trust machines to understand the world, we need them to show their work.
In this post, we are diving deep into a fascinating paper titled “TV-TREES: Multimodal Entailment Trees for Neuro-Symbolic Video Reasoning”. The researchers propose a novel system that doesn’t just answer questions about videos; it builds a logical tree of evidence—combining dialogue and visual frames—to prove its answer.
The Problem: The Unexplainable Multimodal Model
We live in a video-first world. From YouTube tutorials to security footage, video data is everywhere. To process this, we use VideoQA (Video Question Answering) models. These are typically massive Transformer models trained on huge datasets.
While these models are impressive, they have two major flaws:
- They are opaque: They cannot explain the reasoning steps that led to an answer.
- They are lazy: Research shows these models often rely heavily on just one modality (usually text/dialogue) and ignore the video, or vice versa, rather than truly reasoning over both.
The authors of this paper argue that to fix this, we need to move away from pure “black box” neural networks toward Neuro-Symbolic systems. These systems combine the power of neural networks (like Large Language Models) with the structure of symbolic logic.
Enter TV-TREES
The solution proposed is TV-TREES (Transparent Video-Text REasoning with Entailment System).
The core idea is the Entailment Tree. Instead of jumping straight from a question to an answer, the system constructs a logical tree.
- Root: The Hypothesis (the answer we want to prove).
- Branches: Smaller, simpler sub-hypotheses.
- Leaves: Atomic evidence found directly in the video or transcript.
If the leaves are true, they “entail” (logically prove) the branches, which in turn entail the root hypothesis.
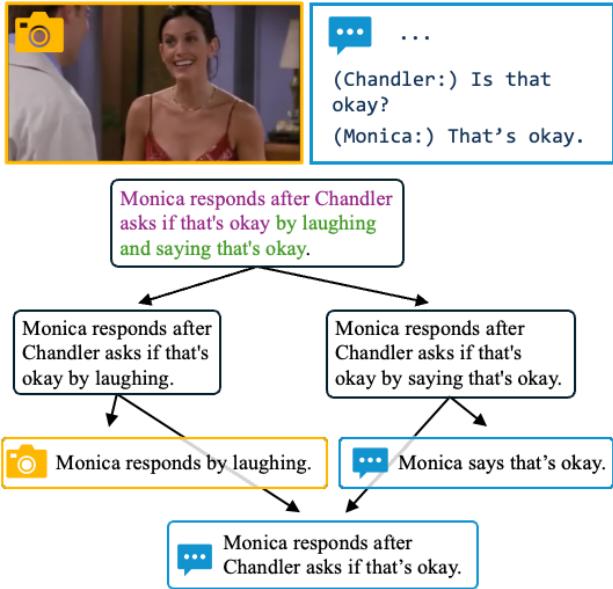
As shown in Figure 1, looking at a scene from Friends, the model doesn’t just guess that “Monica responds by laughing.” It proves it by finding the specific frame where she smiles and the specific transcript line where she speaks.
How It Works: The Pipeline
TV-TREES is a recursive search algorithm. It behaves like a detective trying to solve a case: it looks for evidence, and if the evidence is too complex, it breaks the problem down into smaller, solvable pieces.
The architecture is divided into three main modules: Retrieval, Filtering, and Decomposition.
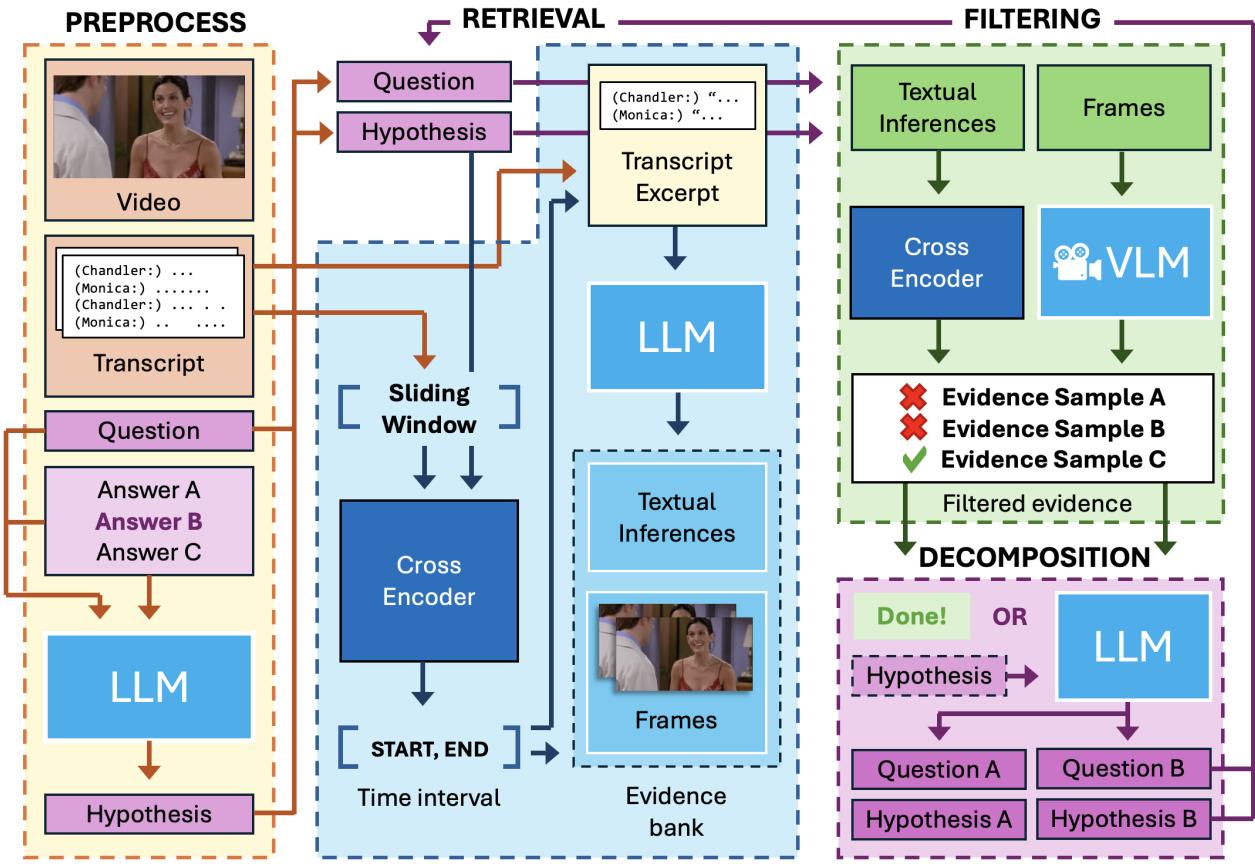
Let’s break down the pipeline illustrated in Figure 2:
1. Preprocessing and Hypothesis Generation
The process starts with a Question and a candidate Answer. The system converts this pair into a single declarative statement called the Hypothesis.
For example:
- Question: “How does Monica respond?”
- Answer: “She laughs.”
- Hypothesis: “Monica responds by laughing.”
The system then locates the relevant time window in the video and transcript to focus its search.
2. Retrieval: Finding the Facts
The system needs evidence. However, raw dialogue is often messy, full of slang, or context-dependent. Existing logic models struggle with raw scripts.
To solve this, TV-TREES uses GPT-3.5 to generate “atomic inferences”—simple, standalone facts derived from the transcript.
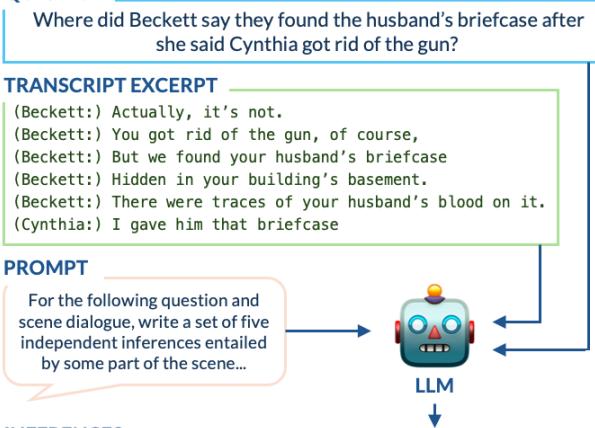
In Figure 3, you can see this in action. The model reads a complex interaction about a “husband’s briefcase” and extracts clear facts like “There were traces of the husband’s blood found on the briefcase.” These simple sentences are much easier to verify than the raw dialogue.
3. Filtering: Checking the Facts
Just because the model generates inferences doesn’t mean they are useful. The Filtering module checks two things:
- Relevance: Does this fact actually help prove our hypothesis?
- Truth: Is this fact actually supported by the video or text?
The system uses specific “Cross-Encoder” models (models trained to judge the relationship between two sentences) to filter out irrelevant or hallucinated information.
4. Visual Reasoning
If the text isn’t enough, TV-TREES looks at the video. It uses a Vision-Language Model (VLM), specifically LLaVA-7B. It asks the VLM yes/no questions about specific frames.
Crucially, to prevent the model from guessing, the researchers instructed the VLM to answer “not enough information” if it wasn’t sure. This conservative approach helps reduce hallucinations—a common problem where AI “sees” things that aren’t there.
5. Decomposition: The Recursive Magic
This is the most critical step. What happens if the system looks for evidence to prove “Monica is annoyed” but can’t find a single sentence or image that explicitly says that?
The system performs Decomposition. It uses an LLM to break the high-level hypothesis into two simpler sub-hypotheses.
- High-level: “Monica is annoyed because Chandler made a joke.”
- Decomposition 1: “Chandler made a joke.”
- Decomposition 2: “Monica looks annoyed.”
The system then restarts the whole process (Retrieval and Filtering) for these two new sub-hypotheses. It continues this recursion until it hits “atomic” facts that can be directly proven by a line of text or a video frame, or until it reaches a maximum depth (usually 3 levels).
Evaluating the Logic
How do we know if an entailment tree is actually “good”? The researchers argue that simple accuracy (did it get the right answer?) isn’t enough. We need to evaluate the quality of the reasoning.
They adapted concepts from informal logic theory to create three key metrics:
1. Acceptability
Are the leaf nodes (the bottom-level evidence) actually true?
\[ \begin{array} { c } { { I ( h ) \in [ 0 , 1 ] \forall h \in T } } \\ { { I ( h \mid V \cup D ) = 0 \forall h \in T _ { \mathrm { l e a v e s } } . } } \end{array} \]This equation effectively asks: Is the probability of the hypothesis high given the video (\(V\)) and dialogue (\(D\))? If the leaf node is hallucinated, the tree fails this check.
2. Relevance
Do the children nodes actually relate to the parent node? A proof isn’t good if the evidence is true but irrelevant (e.g., proving “The sky is blue” does not explain why “Monica is angry”).
\[ \begin{array} { r } { I ( h \mid h _ { 1 } , h _ { 2 } ) < I ( h \mid h _ { 2 } ) \ \forall ( h , e ) \in T _ { \mathrm { b r a n c h e s } } } \\ { I ( h \mid h _ { 1 } , h _ { 2 } ) < I ( h \mid h _ { 1 } ) \ \forall ( h , e ) \in T _ { \mathrm { b r a n c h e s } } } \end{array} \]This formula checks for Information Gain. It ensures that combining hypothesis 1 and hypothesis 2 gives us more certainty about the parent hypothesis than either one alone.
3. Sufficiency
Is the explanation complete? If you combine the sub-hypotheses, do they fully entail the parent?
\[ I ( h _ { 0 } \mid h _ { 1 } , h _ { 2 } ) = 0 \ \forall ( h _ { 0 } , ( T _ { 1 } , T _ { 2 } ) ) \in T . \]This equation states that the uncertainty of the parent hypothesis (\(h_0\)) should be zero if we know the sub-hypotheses (\(h_1\) and \(h_2\)) are true.
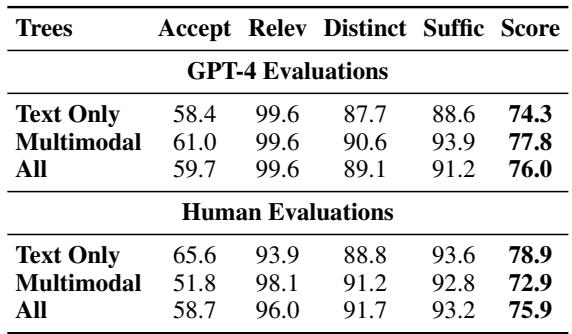
By averaging these scores, the researchers calculate a total composition score (\(S\)) for every tree:
\[ S = \frac { 1 } { 3 } ( a + s + 0 . 5 ( d + r ) ) \]Experiments and Results
The team tested TV-TREES on TVQA, a challenging dataset containing clips from shows like The Big Bang Theory, Castle, and Friends.
Quantitative Success
The results were impressive. As shown in Table 1, TV-TREES outperformed existing “zero-shot” methods (models that haven’t been specifically trained on the TVQA training set).
Note the distinct jump in performance compared to standard zero-shot models like FrozenBiLM or SeVILA when using full clips. This validates the “divide and conquer” strategy of the entailment trees.
The Power of Multimodality
One of the most significant findings came from their ablation study (removing parts of the system to see what happens). They tested the system using only text (dialogue) and only vision.
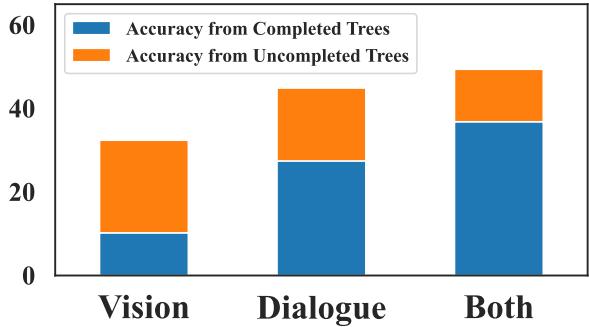
Figure 4 clearly shows that the “Both” (Multimodal) setting performs best.
- Vision only struggles because complex narratives are hard to extract from pixels alone.
- Dialogue only misses physical actions and reactions.
- Combined, they allow the system to complete more trees and answer more questions correctly.
A “Gold Standard” Tree
When the system works perfectly, it produces something beautiful: a fully interpretable proof.
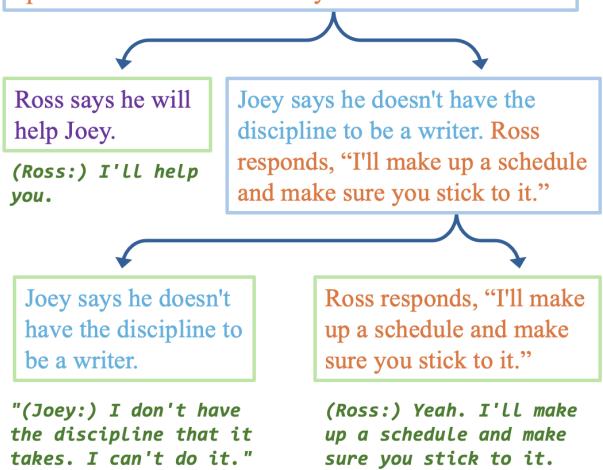
In Figure 5, notice how the system breaks down the complex interaction between Ross and Joey. It separates Joey’s admission (“I don’t have the discipline”) from Ross’s offer (“I’ll make up a schedule”). It finds the exact quotes in the transcript to support each branch. A human can look at this and verify the AI’s logic instantly.
When It Goes Wrong: Failure Modes
No AI system is perfect. The interpretability of TV-TREES allows us to see exactly why it fails, which is impossible with black-box models. The researchers identified several common error types.

As detailed in Figure 6 and Table 3 (below), the most common errors stem from the visual reasoning module.
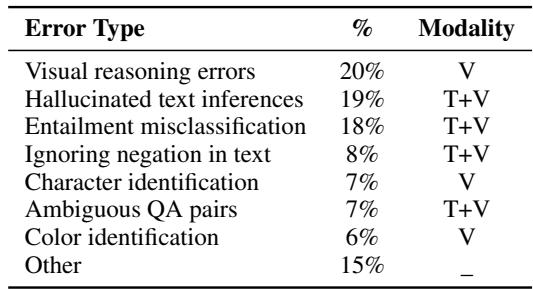
- Visual Reasoning Errors (20%): The VLM might misinterpret a gesture or an object.
- Hallucinations (19%): Sometimes the LLM generates “facts” that sound plausible but never happened in the dialogue.
- Negation (8%): AI struggles with the word “not.” If a character says “I am not happy,” the model might sometimes match it to “happy” due to the keyword overlap.
Conclusion
TV-TREES represents a significant step forward in making AI interpretable. By forcing the model to “show its work” via entailment trees, the researchers created a system that is not only competitive in accuracy but also transparent in its successes and failures.
This Neuro-Symbolic approach—combining the generative power of LLMs/VLMs with the strict structure of logical trees—offers a “best of both worlds” solution. It allows us to verify AI decisions, debug errors more easily, and trust that the model is reasoning based on actual evidence, not just statistical noise.
As multimodal models continue to evolve, systems like TV-TREES will be essential in ensuring that our AI assistants are not just smart, but also accountable.