](https://deep-paper.org/en/paper/2403.01554/images/cover.png)
Introduction: The Challenge of a Constantly Changing World
Most machine learning models today are trained on static datasets—like ImageNet or Wikipedia—and then deployed as fixed systems. This setup relies on the i.i.d. assumption: the belief that real-world data will resemble the training data. But in reality, our world is dynamic and ever-changing. Stock prices fluctuate by the second, language evolves constantly, and a self-driving car’s camera never sees the same scene twice.
A model trained on last year’s data may lose relevance within weeks. This is where online continual learning comes in—a paradigm designed for continuous, sequential learning. Here, a model receives data one example at a time, learns from each instance on the fly, and continuously adapts. The goal is to minimize cumulative error across the entire sequence, effectively learning and improving throughout its lifetime.
Transformers have revolutionized deep learning for sequential data such as text and audio, even proving useful beyond sequences, in tasks like image classification. Their ability to perform in-context learning—learning new tasks within their input context—makes them remarkably flexible. But can these properties be extended to the domain of online continual learning?
The research paper Transformers for Supervised Online Continual Learning explores exactly that. The authors propose a hybrid method that fuses the Transformer’s fast in-context adaptability with the gradual, long-term improvement of gradient-based training. Their results achieve strong gains on a complex, realistic benchmark, highlighting how Transformers can “never stop learning.”
Background: Two Modes of Learning
To appreciate the core idea behind this study, it’s helpful to first understand the mechanics of online continual learning and the dual nature of Transformer learning.
Online Continual Learning: Learning on the Go
Imagine a continuous sequence of data points \((x_1, y_1), (x_2, y_2), \dots, (x_T, y_T)\). At each time step \(t\), the model must:
- Receive an input \(x_t\)
- Make a prediction \(\hat{y}_t\)
- Observe the true label \(y_t\)
- Compute a loss based on this prediction
- Update its parameters before moving to \(x_{t+1}\)
Unlike classical training, the model doesn’t revisit past data. It must adapt to new information while maintaining previously acquired knowledge. This approach directly measures how well the model minimizes the cumulative prediction error, rewarding fast adaptation and resilience to catastrophic forgetting—the tendency of neural networks to forget old information when learning new tasks.
Transformers: In-Context vs. In-Weight Learning
Transformers excel in sequence modeling thanks to their attention mechanism, which selectively focuses on relevant tokens when processing context. This mechanism naturally enables in-context learning—temporary learning based on inputs. For instance, a pre-trained Transformer can perform English-to-French translation instantly when shown a few example pairs, without updating its parameters.
This transient capability contrasts with in-weight learning, the slower, parametric learning achieved through gradient descent over many examples. In-weight learning stores general knowledge in the model parameters, while in-context learning relies on active context representations.
The goal of the research is to combine these two learning modes:
- In-context learning: Rapid adaptation to short-term changes.
- In-weight learning: Long-term consolidation and stability through continuous gradient updates.
The Core Method: A Hybrid Transformer Learner
The proposed method modifies the Transformer to learn online, simultaneously using in-context conditioning and weight updates via gradient descent. The authors explore two main architectural variants geared toward sequential supervised prediction.
Two Architectures for Online Prediction
The 2-Token Approach In this configuration, each input-label pair \((x_t, y_t)\) is represented by two consecutive tokens. The Transformer processes the full sequence \(x_1, y_1, x_2, y_2, \dots\), ignoring the loss on \(x_t\) tokens and training only to predict \(y_t\). This structure is simple and effectively treats supervised learning as a sequence modeling problem.
The Privileged Information (pi) Transformer The pi-transformer introduces a modification to the standard Transformer block. Each input image \(x_t\) is fed as a token, but its corresponding label \(y_t\) provides additional privileged information that influences the attention mechanism. Projections of \(y_t\) are added to the keys and values, but not to the queries. Importantly, an attention mask with a zero diagonal prevents the model from accessing its own label at step \(t\), ensuring causal prediction while retaining access to all previous label projections \(y_{< t}\).
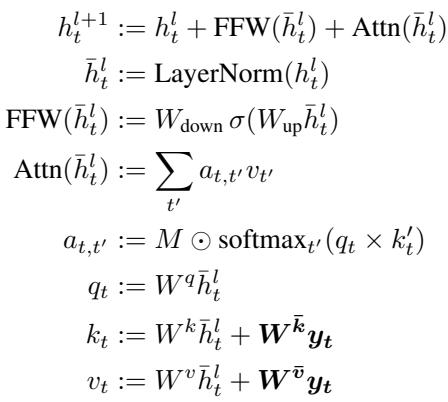
The pi-transformer incorporates label information in the attention mechanism through additional key and value projections, while masking future labels to preserve sequential causality.
Training: Transformer-XL Meets Replay Streams
Training on a continuous data stream is resource-intensive, especially with tens of millions of examples. The researchers adopt a Transformer-XL-style approach (Dai et al., 2019), where training occurs in smaller sequential chunks (e.g., 100 tokens). The attention module, however, can attend to a much larger window (e.g., 1024 tokens) via a KV-cache, preserving long-term context without significantly increasing computation.
To keep learning effective over the stream, the authors employ replay streams—an elegant adaptation of experience replay. The model is simultaneously trained on several parallel “streams” of data:
- Stream 0 processes new data chronologically and defines evaluation performance.
- Additional streams randomly reset to earlier positions, replaying past data.
This stochastic replay effectively simulates multi-epoch learning while maintaining chronological consistency. It encourages the model to build parameters that perform well across both current and past contexts—aligning with meta-learning principles.
Experiments: From Toy Worlds to Real Data
The authors test their approach in two main settings: synthetic piecewise-stationary datasets and a realistic, large-scale continual learning benchmark.
Toy Data: Split-EMNIST
To observe adaptation behavior, they use Split-EMNIST, a synthetic dataset segmented into 100 tasks. Each task randomly maps 10 image classes to 10 labels. When a new task starts, the mapping changes completely—creating abrupt distribution shifts.
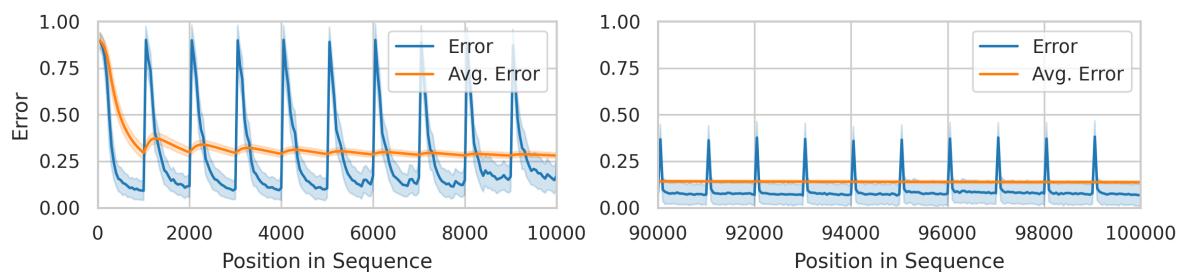
Figure 1: Prediction error spikes at task boundaries but quickly stabilizes, demonstrating fast adaptation after abrupt changes in label mapping.
Over time, the model transitions from struggling with early tasks to thriving on later ones.
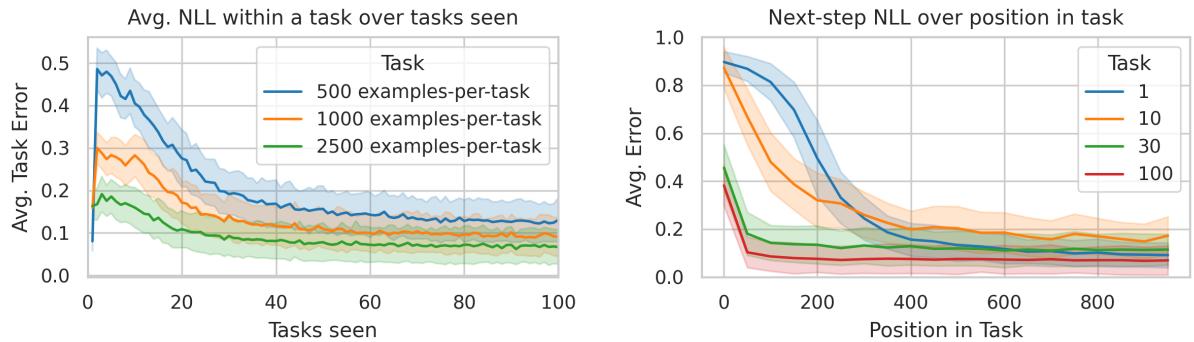
Figure 2: Performance improves steadily across tasks as the Transformer “learns to learn”—achieving few-shot adaptation after about 30 tasks.
Replay plays a critical role here. Without replay, the model’s performance plummets, as shown below.
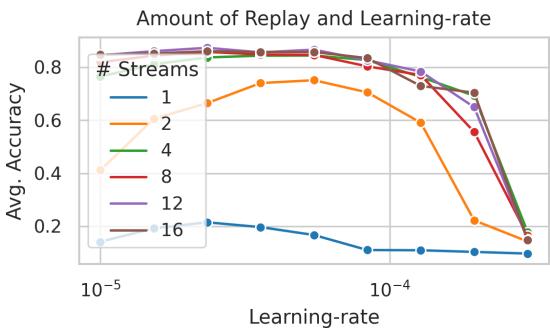
Figure 3: Replay streams enable online models to achieve stable and high accuracy by revisiting past sequences.
This experiment highlights the emergence of meta-learning behavior—the model learns how to adapt efficiently across distribution shifts within tasks.
Real-World Benchmark: The CLOC Dataset
The ultimate test is CLOC (Continual Localization), a dataset of ~37 million chronologically ordered images labeled by geographic location. The data is highly non-stationary, reflecting natural temporal and spatial drift. This task demands outstanding generalization and adaptability.
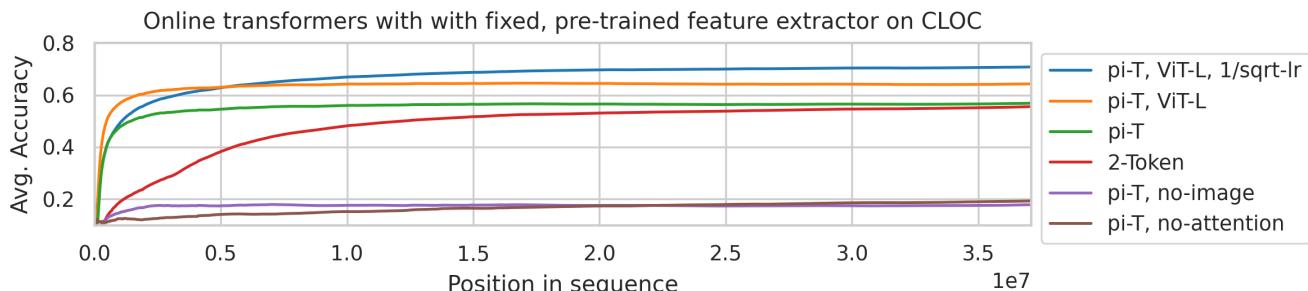
Figure 4: CLOC results with pretrained features. The pi-transformer achieves nearly double the previous best accuracy.
Results Summary
| Method | Pretrained | Finetuned | Avg. Accuracy |
|---|---|---|---|
| Experience Replay (Cai et al., 2021) | ✓ | ✓ | 20% |
| Approx. kNN (Prabhu et al., 2023) | ✓ | - | 26% |
| Replay Streams (Bornschein et al., 2022) | ✓ | - | ~38% |
| Kalman Filter (Titsias et al., 2023) | ✓ | - | 30% |
| Our pi-Transformer (ResNet features) | ✓ | - | 59% |
| Our pi-Transformer (MAE ViT-L features) | ✓ | - | 70% |
| Our Transformer (learned from scratch) | - | ✓ | 67% |
The performance leap is dramatic—especially with modern pretrained features (like MAE ViT-L), the pi-transformer surpasses prior models by a wide margin.
Dissecting the Learning Dynamics
1. In-Context vs. In-Weight Contributions
To evaluate each learning mechanism’s role, the authors froze model weights after a certain number of examples, forcing reliance on in-context learning alone.
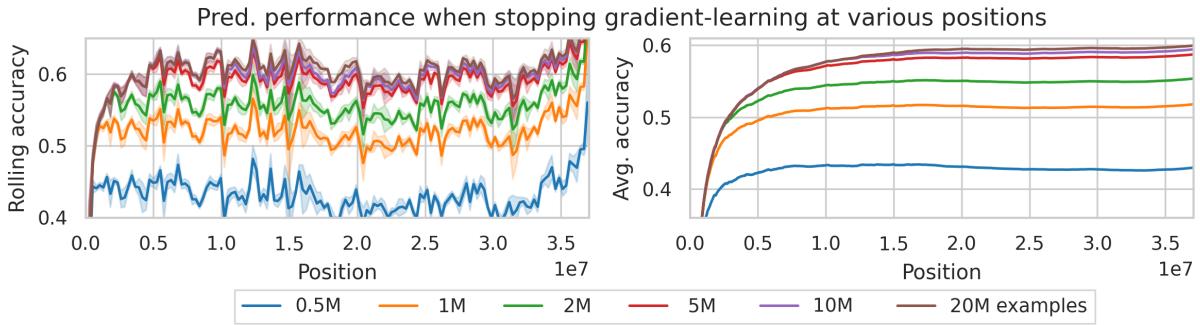
Figure 5: Even after millions of examples, gradient-based (in-weight) learning continues to provide consistent performance gains.
Both components contribute significantly: in-context adaptation handles immediate changes, while gradient updates ensure long-term stability.
2. Hyperparameter Effects
Larger attention windows (\(C\)) and more replay streams lead to improved results.
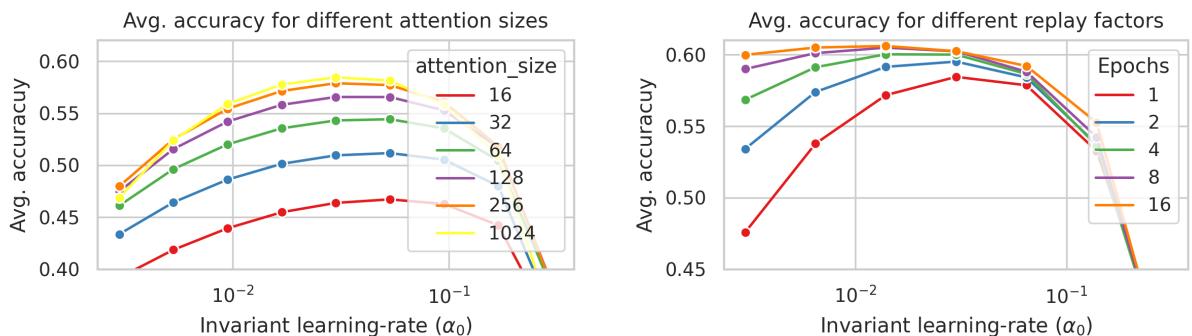
Figure 6: Both attention size and replay count impact model stability and predictive power.
3. Training From Scratch
When trained entirely from scratch—learning both the feature extractor and Transformer—the model remained competitive, obtaining ~67% accuracy, nearly matching pretrained versions.
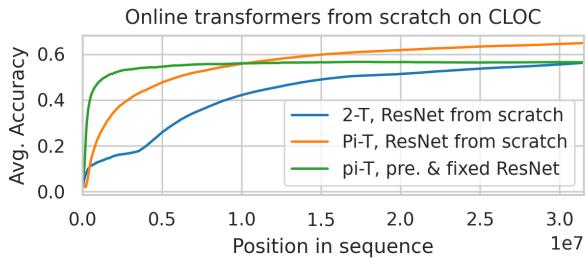
Figure 11: Models trained from scratch achieve almost the same accuracy as those using frozen pretrained features.
4. pi-Transformer vs. 2-Token
The two architectures show different learning dynamics. The 2-token model exhibits discrete jumps—likely linked to induction head formation—while the pi-transformer improves smoothly.
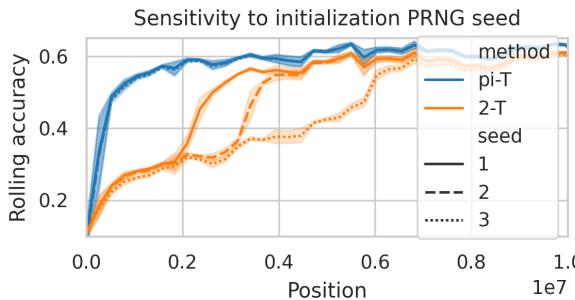
Figure 8: The pi-transformer learns stably, while the 2-token variant experiences sharp performance transitions, possibly reflecting emergent induction heads.
5. Efficiency Comparison
The team analyzed compute cost trade-offs to map Pareto fronts between accuracy and total FLOPs.
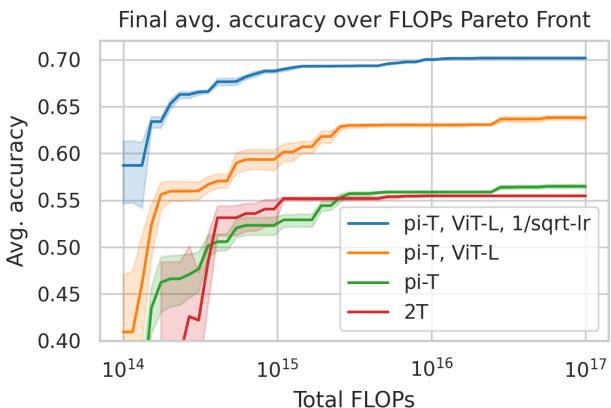
Figure 7: Pareto analysis reveals both architectures offer excellent efficiency across a wide compute range.
Conclusion and Outlook
This study demonstrates that Transformers can indeed perform supervised online continual learning effectively. By integrating short-term in-context adaptation and long-term in-weight optimization, the proposed approach achieves state-of-the-art results on both synthetic and real-world tasks.
Key insights include:
- Hybrid Learning Works: Jointly leveraging fast contextual adaptation and slow parametric learning results in powerful continual learners.
- Architectural Innovation: The pi-transformer introduces a principled way to include label information while respecting causal constraints.
- Replay is Essential: Multi-stream replay provides an efficient simulation of multi-epoch training in strictly sequential data streams.
- Scalability and Robustness: The approach performs well even with large datasets (tens of millions of samples) and varied hyperparameters.
Overall, this work bridges the gap between the emergent meta-learning abilities of large Transformers and the enduring challenge of learning from non-stationary streaming data. It charts a promising path toward adaptive AI systems that continually learn and improve, embracing the ever-changing nature of real-world information.