](https://deep-paper.org/en/paper/2403.02966/images/cover.png)
Making LLMs Honest: How Summarizing Knowledge Graphs Improves Question Answering
Large Language Models (LLMs) like GPT-4 and Llama have revolutionized how we interact with information. They can write poetry, code, and answer complex questions. However, they suffer from a well-known flaw: hallucinations. Because their knowledge is “frozen” in their parameters from training, they often get facts wrong, especially obscure or evolving ones.
To fix this, researchers and engineers typically use RAG (Retrieval-Augmented Generation). The idea is simple: look up the relevant information from an external source and feed it to the LLM. One of the most structured and reliable sources for this external data is a Knowledge Graph (KG).
But there is a problem. KGs speak the language of “triples” (e.g., (Stephen King, Educated At, University of Maine)), while LLMs speak natural language. Bridging this gap is harder than it looks. Simply dumping a list of raw facts into an LLM often confuses the model or wastes valuable context window space.
In this post, we will dive deep into a paper titled “Evidence-Focused Fact Summarization for Knowledge-Augmented Zero-Shot Question Answering”. The researchers propose EFSUM, a novel framework that doesn’t just list facts—it summarizes them specifically to answer the user’s question, ensuring high accuracy and low hallucination.
The Problem: The Gap Between Graphs and Text
Before understanding the solution, we need to understand why using Knowledge Graphs (KGs) with LLMs is difficult.
A KG consists of entities and relationships. When a user asks a question like “Where did the author of Pet Sematary go to college?”, a retrieval system pulls relevant facts from the graph. Traditionally, there are two ways to feed this into an LLM:
- Linearization (Concatenation): You simply list the triples as text strings (e.g.,
(Pet Sematary, Author, Stephen King), (Stephen King, Educated At, U of Maine)). - General Verbalization: You use a model to turn those triples into full sentences.
Both methods have significant flaws regarding Density and Clarity.
1. Low Density
Raw triples are repetitive. If you have 10 facts about Stephen King, his name appears 10 times. This wastes “tokens” (the currency of LLMs). If you have a limited context window, you might push relevant information out to make room for redundant text.
2. Low Clarity
When you retrieve facts from a graph, you often get “noise”—facts that are true but irrelevant to the specific question. If you feed an LLM 50 facts about Stephen King, but only one is about his college education, the model might get distracted.
The researchers analyzed existing methods (like KAPING and KG2Text) and found significant issues.
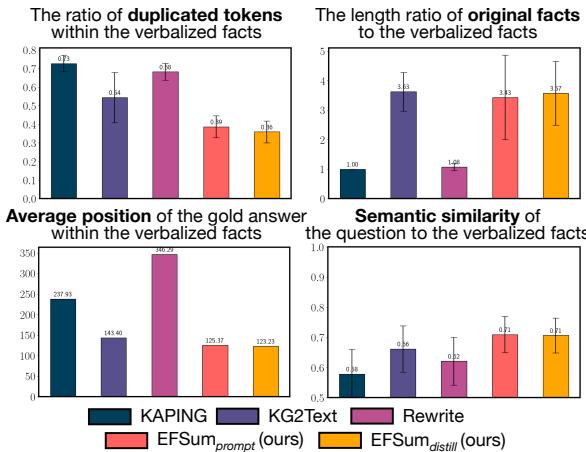
As shown in Figure 2 above:
- Top Left: Methods like KAPING and Rewrite have a high ratio of duplicated tokens (low density).
- Bottom Right: The semantic similarity between the generated text and the question is often low, meaning the context isn’t focused on what the user actually asked.
The Solution: EFSUM
The researchers propose EFSUM (Evidence-focused Fact SUMmarization). Instead of blindly converting graph data to text, EFSUM acts as an intelligent middleman. It takes the retrieved facts and the user’s question, then generates a concise, coherent summary that highlights only the evidence needed to answer that specific question.
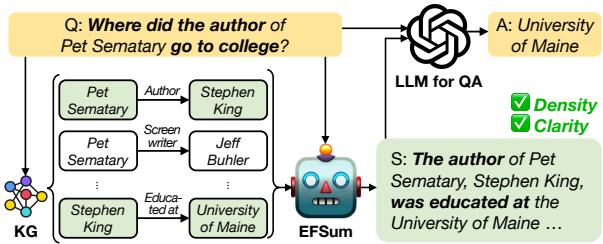
Figure 1 illustrates this workflow:
- Question: “Where did the author of Pet Sematary go to college?”
- KG Retrieval: The system pulls raw nodes and edges (Stephen King, Pet Sematary, University of Maine, etc.).
- EFSUM: The model processes these facts conditioned on the question.
- Summary: It outputs: “The author of Pet Sematary, Stephen King, was educated at the University of Maine…”
- LLM: The final answering model sees this clean summary and easily answers “University of Maine.”
The Core Method: Distillation and Alignment
You might think, “Why not just prompt GPT-4 to summarize the facts?” You could (and the paper tests this as EFSUM_prompt), but relying on a massive, closed-source API is expensive and slow for a production pipeline.
The real innovation here is EFSUM_distill. The authors fine-tuned a smaller, open-source model (Llama-2-7B) to become an expert fact summarizer. They achieved this through a two-step process: Distillation followed by Preference Alignment.
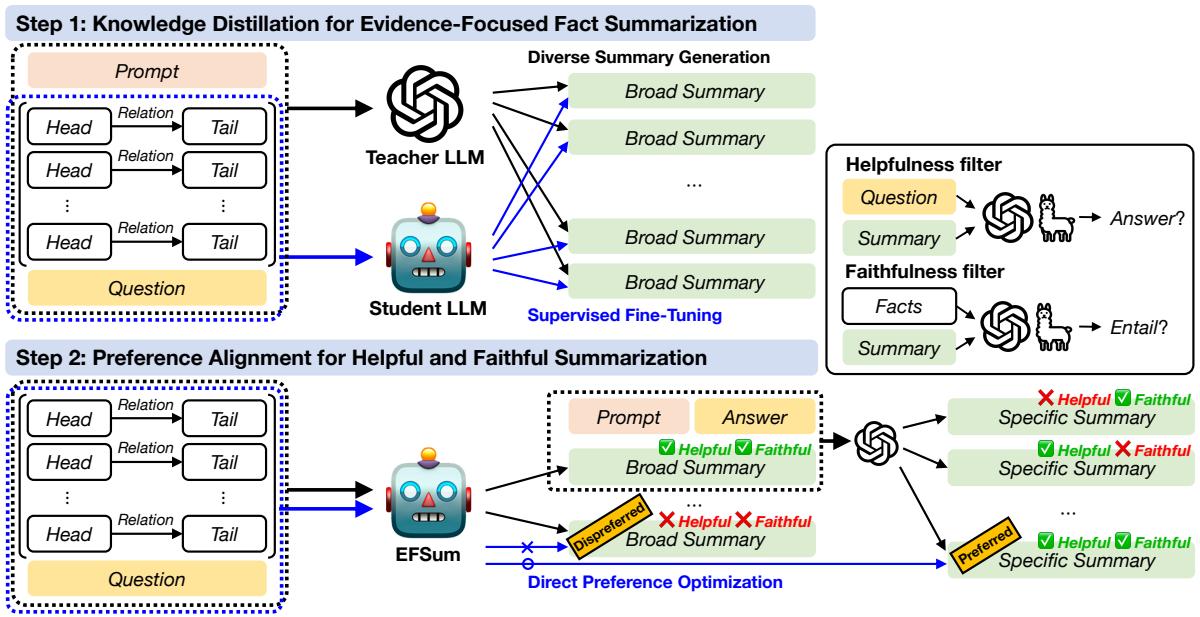
Step 1: Distillation (Teaching the Student)
First, the researchers needed a training dataset. They took a powerful “Teacher” model (GPT-3.5-turbo) and gave it thousands of (Question, Fact Triples) pairs, asking it to generate high-quality summaries.
They then used these generated summaries to train their smaller “Student” model using Supervised Fine-Tuning (SFT). The objective function is standard causal language modeling:
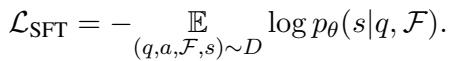
In simple terms, the model \(\theta\) learns to maximize the probability of generating the correct summary \(s\), given the question \(q\) and the facts \(\mathcal{F}\).
Step 2: Preference Alignment (Refining the Skills)
After Step 1, the model could summarize, but it wasn’t perfect. Sometimes it hallucinated (made things up) or wrote summaries that didn’t actually help answer the question.
To fix this, the authors used Direct Preference Optimization (DPO). This technique aligns the model with specific human-defined (or in this case, system-defined) preferences. They established two key criteria for a “good” summary:
- Helpfulness: If an LLM reads this summary, does it get the answer right?
- Faithfulness: Does the summary stick strictly to the facts provided in the graph, without making things up?
The Filtering Process
They generated multiple summary candidates and passed them through two filters:
- Helpfulness Filter: Run a QA check. If the summary leads to the wrong answer, it’s “dispreferred.”
- Faithfulness Filter: Use a separate model (G-Eval) to check for hallucinations. If the summary contains info not in the source graph, it’s “dispreferred.”
They also used a “broad-to-specific” paraphrasing technique to create “Preferred” examples—summaries that are concise and hit the exact evidence needed.
The DPO Training
The model was then trained to prefer the “Helpful & Faithful” summaries (\(s^+\)) over the bad ones (\(s^-\)). The loss function for DPO is shown below:
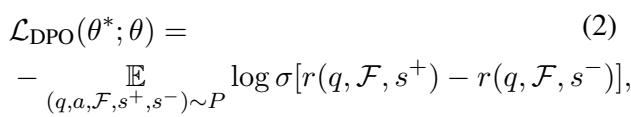
This equation pushes the model’s probability distribution to favor the good summaries (\(s^+\)) while penalizing the bad ones (\(s^-\)), effectively “steering” the model’s behavior without needing a complex Reinforcement Learning setup.
Experimental Results
Does this complex training pipeline actually work? The researchers tested EFSUM on two major Knowledge Graph QA datasets: WebQSP and Mintaka.
Accuracy Improvements
The primary metric is accuracy: Did the LLM answer the question correctly given the context?
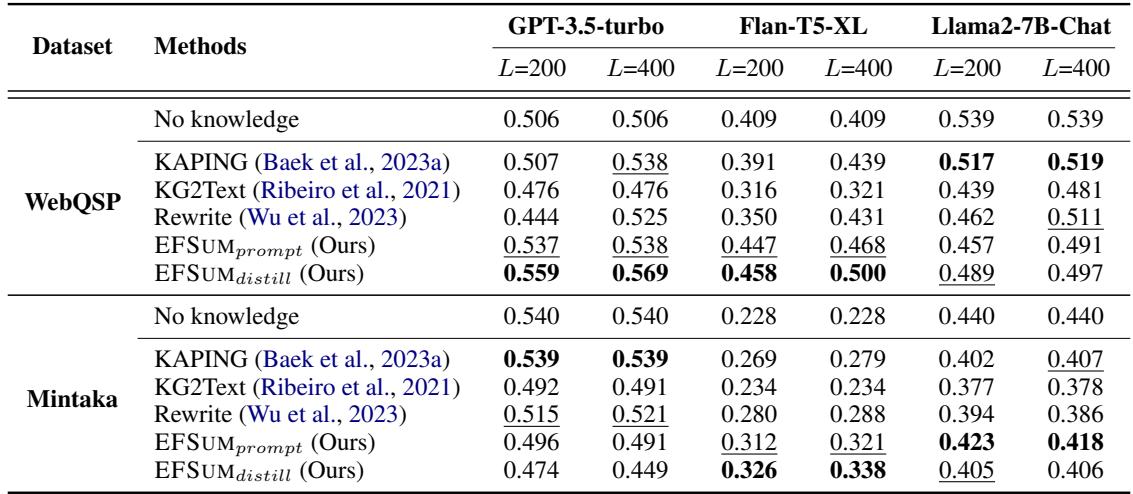
Table 1 shows the results across three different LLMs (GPT-3.5, Flan-T5, and Llama-2).
- L=200 vs L=400: This represents the token limit. Notice that when the context window is tight (\(L=200\)), EFSUM (Ours) significantly outperforms methods like KAPING and Rewrite.
- Efficiency: Because EFSUM is dense (high information, low fluff), it fits more evidence into the same space, leading to better answers.
Robustness to Noise
A good summarizer should handle “noise” well. If the retrieval system pulls in 100 facts, but only 2 are relevant, the summarizer needs to ignore the other 98.
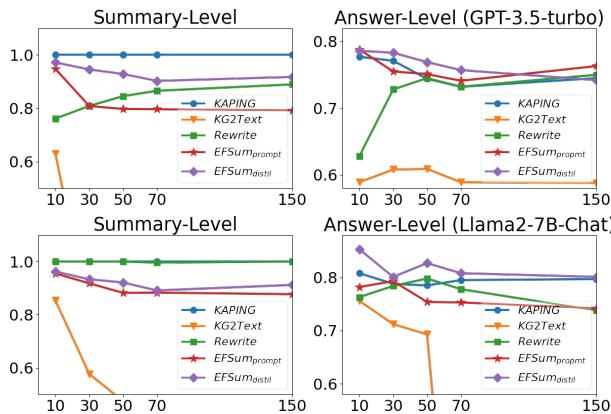
Figure 4 demonstrates this robustness. The X-axis represents \(K\) (number of retrieved facts).
- Look at the KG2Text (orange line) in the top-left chart. As soon as you add more facts, its performance collapses because it tries to verbalize everything, confusing the model.
- EFSUM (purple line) maintains high accuracy even as \(K\) increases. It successfully filters out the noise and keeps the signal clear.
Helpfulness vs. Faithfulness
The ultimate goal is a summary that is both helpful (useful for QA) and faithful (factually accurate).
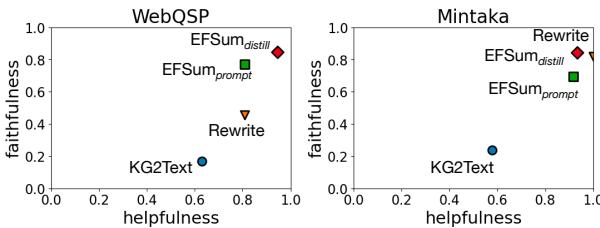
Figure 5 plots these two metrics against each other:
- Ideally, you want to be in the top-right corner.
- Rewrite (Green): Good faithfulness, but lower helpfulness.
- KG2Text (Blue): Poor on both counts.
- EFSUM (Orange): consistently achieves the best balance, sitting highest in the top-right quadrant for both datasets.
Qualitative Comparison
To really see the difference, let’s look at the actual text generated by these methods.

In Table 6, the system is trying to answer: “Who is Emilio Estevez’s father?”
- KAPING creates a messy wall of text:
(Emilio Estevez's, father, Martin Sheen), (Ramón Estévez, father, Martin Sheen)... - KG2Text generates disjointed sentences and oddly repeats “children” and “children.”
- EFSUM generates a clean, readable paragraph: “Emilio Estevez’s father is Martin Sheen… Martin Sheen is the father of both Emilio Estevez and Ramón Estévez.”
The EFSUM output reads like a human wrote it specifically to help you find the answer.
Conclusion and Implications
The EFSUM framework highlights a critical lesson for modern AI development: Context curation is just as important as model size.
By simply treating the retrieved knowledge graph data as raw material that needs to be refined, rather than just dumped into the prompt, the researchers achieved:
- Higher Accuracy: Better answers even with smaller open-source models.
- Better Efficiency: Summaries take up fewer tokens, saving costs and latency.
- Reduced Hallucination: By explicitly training for faithfulness, the model learns to stick to the provided facts.
For students and engineers working with RAG systems, this paper suggests that investing in a specialized “Summarizer” module between your database and your LLM is a powerful architectural pattern. It allows you to convert structured, messy data into clean, narrative evidence that LLMs can process effectively.