](https://deep-paper.org/en/paper/2404.06809/images/cover.png)
Introduction
Retrieval-Augmented Generation (RAG) has become the de facto standard for building knowledgeable AI systems. By connecting Large Language Models (LLMs) to external databases, we promised to solve the twin problems of hallucinations and knowledge cutoffs. The logic was simple: if the model doesn’t know the answer, let it look it up.
But there is a flaw in this logic. RAG systems operate on a dangerous assumption: that everything retrieved is true.
In the real world, the “context” an LLM retrieves is often messy. It can be noisy (irrelevant), outdated (old news), or polluted with misinformation (fake news). When a standard RAG system retrieves this flawed information, it treats it as ground truth, leading to “hallucinations” that are actually just the model faithfully repeating the bad data it was fed.
How do we fix this? We need to teach models to be skeptical. We need Credibility-aware Generation (CAG).
In a recent paper titled “Not All Contexts Are Equal,” researchers propose a new framework that teaches LLMs to explicitly evaluate the credibility of the information they read before using it.
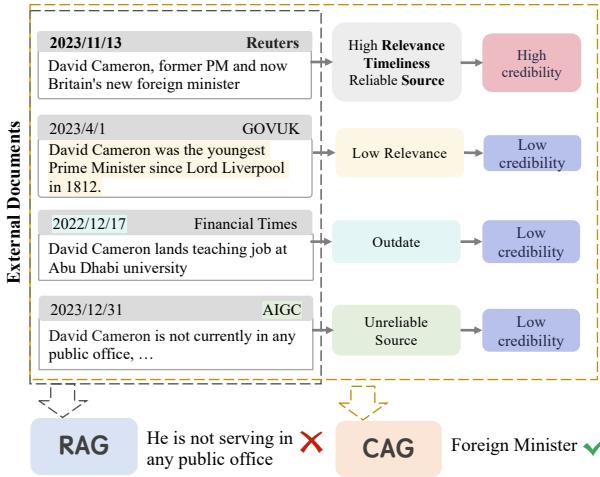
As shown in Figure 1, consider a question about David Cameron’s current position. A standard RAG system retrieves four documents: one old article saying he is a teacher, one AI-generated rumor saying he holds no office, and a recent Reuters report stating he is the Foreign Minister. The standard RAG model gets confused by the conflicting noise and answers incorrectly. The CAG model, however, looks at the metadata—timeliness, source reliability—and correctly identifies the Foreign Minister role.
The Core Problem: Flawed Information
Before diving into the solution, we must understand the three specific types of “flawed information” that break standard RAG systems:
- Noise: The retriever fetches documents that share keywords with the query but don’t actually answer it. Previous research shows LLMs are highly sensitive to this, often getting distracted by irrelevant details.
- Outdated Information: The internet is a graveyard of old facts. LLMs suffer from “temporal insensitivity”—they struggle to distinguish between a fact from 2015 and a fact from 2024 solely based on the text.
- Misinformation: With the rise of AI-generated content and fake news, retrieval databases are increasingly polluted. LLMs generally lack the internal knowledge to fact-check a retrieved document against reality.
Humans handle this by assessing credibility. When we read a medical claim, we check if it’s from a peer-reviewed journal or a random blog. The goal of CAG is to replicate this cognitive process in LLMs.
The Solution: Credibility-aware Generation (CAG)
The researchers propose a universal framework to equip models with the ability to discern information based on credibility.
In a standard RAG setup, the model generates an answer \(y\) based on the input \(x\) and retrieved documents \(D_x\):
\[y = \text{LM}([x, D_{x}])\]In the CAG framework, the input is augmented. Every document \(d_i\) is paired with a credibility score \(c_i\):
\[y = \mathrm{LM}\big([x, [c_i, d_i]_{i=1}^{ | D_x | } ]\big)\]This looks simple mathematically, but existing LLMs (like GPT-4 or Llama-2) are not naturally good at paying attention to these credibility tags. If you just paste “Credibility: Low” next to a paragraph, the model often ignores it. To fix this, the researchers developed a novel Data Transformation Framework.
The Training Pipeline
To teach a model to care about credibility, you have to train it on data where credibility matters. The authors devised a clever two-step process to create this training data, illustrated below.
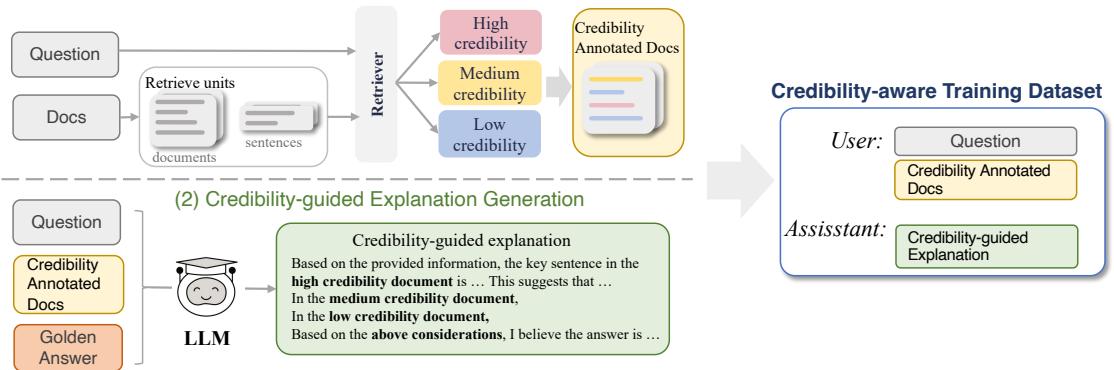
Step 1: Multi-granularity Credibility Annotation
First, the system takes existing datasets and annotates the documents. The researchers didn’t just look at one factor; they calculated credibility based on three dimensions:
- Relevance: How well does the document match the query?
- Timeliness: How closely does the document date align with the current context?
- Reliability: Is the source authoritative?
They formalized this into a calculation where credibility is the minimum viable score across these factors:
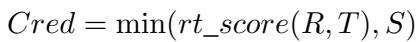
Here, \(R\) is relevance, \(T\) is the time gap, and \(S\) is source reliability. This “weakest link” approach ensures that a document must be relevant, timely, and reliable to be considered high credibility.
Step 2: Credibility-guided Explanation Generation
Simply labeling the inputs isn’t enough. The model needs to learn how to reason with these labels. The researchers used a teacher model (GPT-3.5) to rewrite the answers in the training set.
Instead of just outputting “David Cameron is Foreign Minister,” the teacher model is prompted to generate a Credibility-guided explanation. For example: “Although Document B claims he is a teacher, it is marked as Low Credibility because it is outdated. Document A, marked High Credibility, states he is Foreign Minister. Therefore…”
This converts standard Q&A datasets into “reasoning traces” that explicitly mention credibility.
Step 3: Instruction Fine-tuning
Finally, the target model (e.g., Llama-2-7B) is fine-tuned on this new dataset. The loss function used is standard for language modeling, but it is applied to this credibility-enriched context:
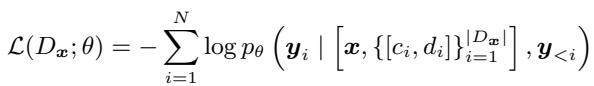
This equation essentially says: optimize the model parameters \(\theta\) so that the probability of generating the correct explanation \(\mathbf{y}\) is maximized, given the question \(\mathbf{x}\) and the set of documents paired with their credibility scores \([c_i, d_i]\).
Experiments: The Credibility-aware Generation Benchmark (CAGB)
To prove this works, the authors couldn’t rely on standard benchmarks like SQuAD, which assume correct contexts. They built a new benchmark called CAGB covering three real-world scenarios:
- Open-domain QA: Standard questions where retrieval often pulls in noisy, distracting paragraphs (using datasets like HotpotQA and MuSiQue).
- Time-sensitive QA: Questions where the answer changes over time (e.g., “Who is the UK Prime Minister?”).
- Misinformation Polluted QA: A dataset specifically injected with fake news generated by other LLMs to test if the model can filter out lies.
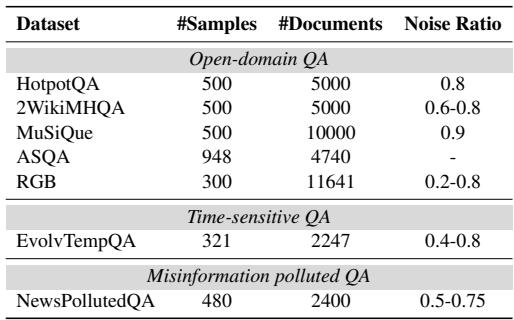
As shown in Table 1, the noise ratio in these datasets is high, ranging from 20% to 90%. This makes it a grueling test for any RAG system.
Key Results
The performance comparison is stark. The researchers tested their CAG-trained models (based on Llama-2 and Mistral) against standard retrieval-based models (like ChatGPT and Llama-2-70B) and models that use “Reranking” (a common technique to sort documents by relevance).
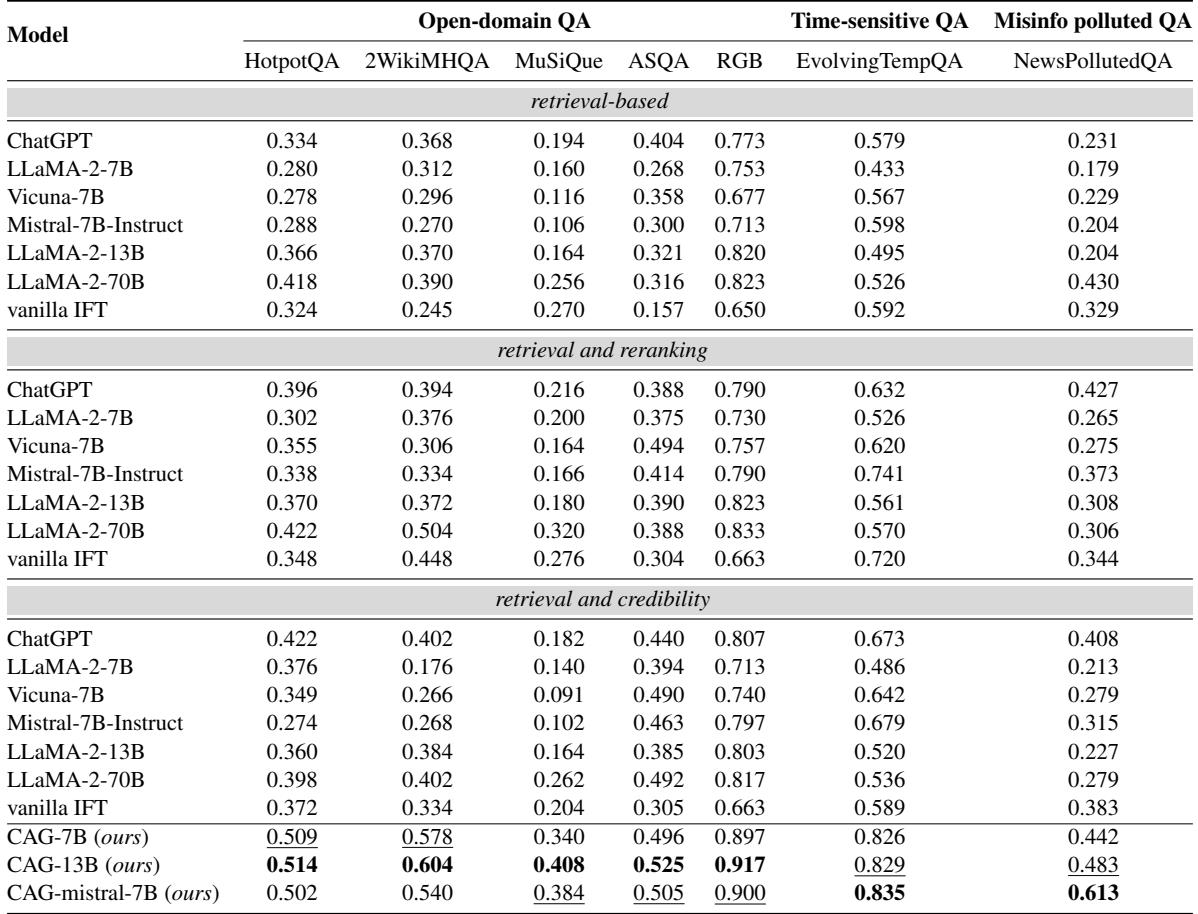
Looking at Table 2, the results are impressive:
- Outperforming Giants: The fine-tuned CAG-7B model (a relatively small model) significantly outperformed LLaMA-2-70B (a model 10x its size) across almost all datasets.
- Beating Reranking: Even when standard models were helped by a reranker (which puts the best docs first), the CAG models still won. For example, on the
2WikiMHQAdataset, CAG-7B scored 0.578, while LLaMA-2-70B with reranking only scored 0.504. - Misinformation: On the
NewsPollutedQAdataset, where fake news is prevalent, CAG-Mistral-7B achieved a score of 0.613, effectively doubling the performance of standard LLaMA-2-13B (0.308).
Robustness Against Noise
One of the most critical findings is how the models behave as you add more garbage to the context. Usually, as the “Noise Ratio” increases, model performance plummets.
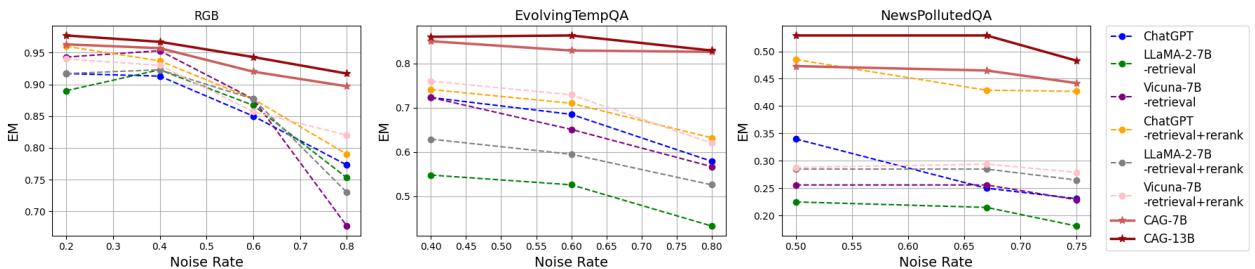
Figure 3 illustrates this robustness.
- The Trend: Look at the lines for standard models (like the dashed lines). They slope downward drastically as noise increases (moving right on the x-axis).
- The CAG Advantage: The solid red lines (CAG models) remain remarkably flat. On the NewsPollutedQA graph (rightmost), while other models crash below 0.3 accuracy when noise hits 80%, the CAG model stays robust. This proves the model isn’t just “guessing” better; it has learned to actively ignore low-credibility information.
Why Not Just Delete Low-Credibility Docs?
A common counter-argument is: “If you know the credibility score, why not just filter out the bad documents before sending them to the LLM?”
The researchers tested this “Hard Filtering” approach against their “Soft” CAG approach.
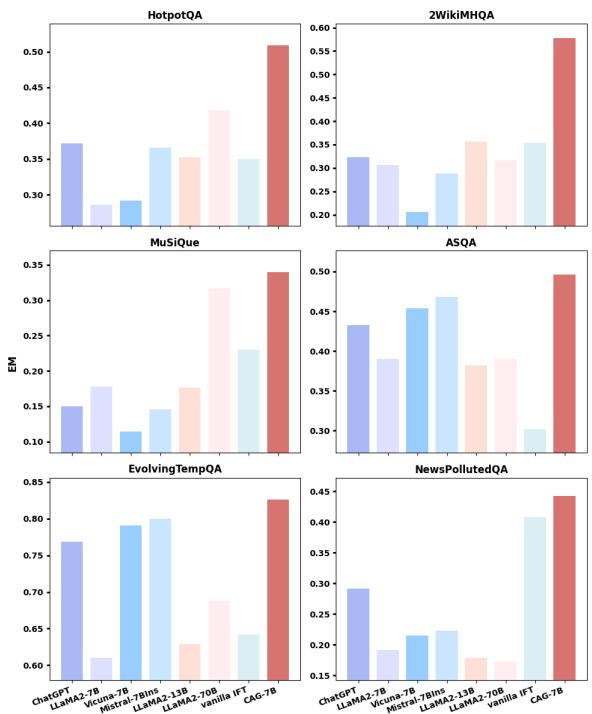
Figure 4 shows that simply discarding low-credibility documents (the bars that aren’t red) is generally worse than the CAG method (the red bars).
Why? Because credibility assessment isn’t perfect. A “low credibility” document might still contain a snippet of useful context or a necessary entity definition. If you hard-filter it, that information is lost forever. CAG allows the model to see everything but weigh the trustworthiness of the information dynamically.
Broader Implications
The utility of Credibility-aware Generation extends beyond just answering trivia questions. It opens up new possibilities for personalization and conflict resolution.

As shown in Figure 5:
- Personalization (Left): Credibility can be subjective. For a user interested in “Nature,” a travel guide about lakes might be assigned higher credibility for that specific user than a guide about cities. CAG allows the model to prioritize results based on user profiles.
- Conflict Resolution (Right): When two documents flatly contradict each other (e.g., “Bees are the most important” vs. “Moths are the most important”), CAG uses source reliability to resolve the conflict, rather than just hallucinating a mix of both.
Conclusion
The era of blindly trusting retrieval is over. As RAG systems move from prototypes to production, the quality of context becomes the bottleneck. The “Not All Contexts Are Equal” paper demonstrates that we cannot rely solely on better retrievers to fix this. We must change the generators themselves.
By explicitly teaching LLMs to understand the concept of credibility—through annotated data and explanation-based fine-tuning—we can build AI that doesn’t just read, but evaluates. The result is a system that is resilient to noise, skeptical of fake news, and capable of handling the messy reality of the open internet.
For students and practitioners, the takeaway is clear: Metadata matters. Don’t just feed your model text; feed it the context about the text.