](https://deep-paper.org/en/paper/2404.12545/images/cover.png)
Introduction
Deep learning models, particularly Large Language Models (LLMs) like BERT, RoBERTa, and Llama, have achieved superhuman performance on a vast array of Natural Language Processing (NLP) tasks. Yet, despite their brilliance, they suffer from a significant flaw: they are “black boxes.” We feed them a sentence, and they spit out a prediction, but the internal reasoning process remains largely opaque.
For students and researchers aiming to build safe and trustworthy AI, this opacity is a problem. How do we trust a model if we don’t know why it made a decision?
Traditionally, the field has relied on feature attribution methods. These techniques highlight specific words in the input sentence that contributed most to the prediction. For example, in a movie review, the model might highlight the word “terrible” to explain a negative sentiment classification. While helpful, this approach is often superficial. Words are discrete symbols, but their meanings are fluid. The word “bank” means something entirely different in the context of a river versus a financial institution. Merely highlighting “bank” doesn’t tell us which meaning the model used.
In this post, we will explore a research paper that proposes a deeper level of interpretability: Latent Concept Attribution (LACOAT). Instead of just pointing to words, LACOAT explains predictions using “Latent Concepts”—clusters of contextual meaning learned by the model. We will break down how this method works, how it reveals the inner evolution of model reasoning, and why it offers a significant leap forward in AI explainability.
The Problem with Simple Word Attribution
To understand why we need Latent Concepts, we must first understand the limitations of looking at words in isolation. In high-dimensional vector spaces (where deep learning models operate), a single word does not exist as a static point. Its representation shifts based on context.
Consider the word “trump.” Depending on the sentence, this word could represent:
- A verb (to outrank).
- A specific named entity (a famous tower).
- A political figure (a former US President).
- A playing card term.
If a model predicts a sentence is “Political,” and it highlights the word “trump,” we might assume it understood the political context. But what if the model actually associated “trump” with playing cards and got the right answer for the wrong reason? Standard attribution methods cannot distinguish between these nuances.
The researchers behind LACOAT argue that we need to look at the Latent Space. During training, a model learns to group similar contexts together. By tapping into these groupings, we can see exactly which “facet” of a word the model is employing.

As shown in Figure 1 above, the word “trump” can be visualized as belonging to different clusters (or concepts) depending on its usage. LACOAT leverages this to provide explanations that are semantically rich rather than just identifying keywords.
The Methodology: How LACOAT Works
The LACOAT framework is a pipeline designed to generate human-friendly explanations for local predictions. It consists of four distinct modules. Let’s walk through them step-by-step.
1. ConceptDiscoverer: Mapping the Territory
Before we can explain a specific test case, we need to understand the “map” of the model’s knowledge. This is done using the training data.
The ConceptDiscoverer module takes a pre-trained model and the training dataset. It passes every sentence in the training data through the model and extracts the contextualized representations (vectors) for every word at every layer.
Because models like BERT are contextual, the vector for “bank” in “river bank” will be mathematically different from “bank” in “bank deposit.” The module then applies Agglomerative Hierarchical Clustering to these vectors.
- The Intuition: Vectors that are close together in space share similar meanings or grammatical roles.
- The Result: The algorithm finds clusters of vectors. One cluster might contain various positive adjectives (“good,” “great,” “superb”). Another might contain proper nouns related to geography. These clusters are the Latent Concepts.
2. PredictionAttributor: Finding the Spark
Now that we have our “map” of concepts (from the training data), we look at a specific test instance we want to explain.
The PredictionAttributor identifies which words in the input sentence were most responsible for the model’s prediction. The researchers use a method called Integrated Gradients (IG). IG calculates an attribution score for each token. The module selects the top tokens that account for 50% of the total attribution mass. These are the “salient” words—the movers and shakers of that specific prediction.
3. ConceptMapper: Connecting Input to Concepts
This is the core innovation of LACOAT. We have the salient word from our test sentence, and we have its vector representation inside the model.
The ConceptMapper takes this vector and finds which Latent Concept (Cluster) from the training data it aligns with. It essentially asks: “To which group of training examples is this current word most similar?”
By mapping the test word to a training cluster, we unlock the semantic context. If the model highlights “trump” in the test sentence, and ConceptMapper maps it to a cluster full of “Queen,” “Jack,” and “Spades,” we know the model is treating it as a card game term. If it maps to a cluster of “Obama,” “Bush,” and “Clinton,” the model is treating it as a political entity.
4. PlausiFyer: Translating to English
A cluster of words is informative to a data scientist, but it can be messy to read. A latent concept might look like a word cloud of 50 semantically related terms.
To make this user-friendly, the PlausiFyer module uses a Large Language Model (specifically ChatGPT in this paper). It feeds the input sentence and the list of words from the identified Latent Concept to the LLM and asks a simple prompt: “Do you find any common semantic… relation between the word highlighted… and the following list of words?”
The result is a natural language explanation summarizing the relationship.
Visualizing the Evolution of Meaning
One of the most fascinating aspects of Deep Learning models is how their understanding evolves as data moves deeper through the layers of the network. LACOAT allows us to visualize this hierarchy.
In the early layers of a Transformer model, representations are often based on syntax or simple lexical definitions. As we move to deeper layers, the representations become more abstract, capturing sentiment and complex semantics.

In Figure 2, we see the analysis of a negative review containing the word “worst”:
- Layer 0 (Input): The concept includes words like “best,” “biggest,” and “greatest.” This might seem confusing, but linguistically, these are all superlative adjectives. The model groups them by their grammatical role.
- Layer 6 (Middle): The concept shifts to negative adverbs and adjectives like “terrible” and “badly.” The model is starting to understand the sentiment.
- Layer 12 (Output): The concept is tightly focused on extreme negativity: “awful,” “atrocious,” “rotten.”
This confirms that the explanation generated by the final layer is usually the most relevant for understanding the final prediction.
Here is another example showing a similar progression:
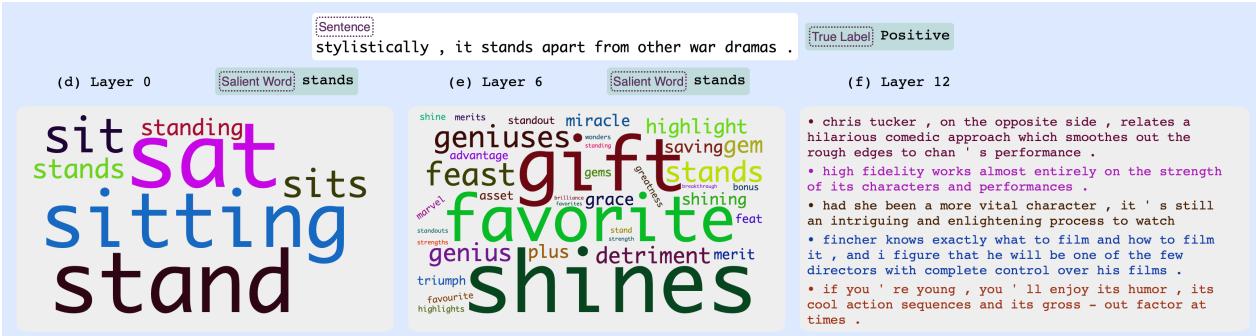
In Figure 5, the model analyzes the word “stands.” In Layer 0, it groups it with physical verbs like “sit.” By Layer 12, it has associated the concept with positive film review terms (“gift,” “shines,” “merit”), indicating the model interprets “stands” in a metaphorical, positive sense in this context.
Analyzing Predictions: The Good, The Bad, and The Confused
LACOAT shines when we use it to diagnose model behavior. Let’s look at examples of correct and incorrect predictions.
Correct Predictions
In standard cases, LACOAT confirms that the model is reasoning correctly.

In Figure 3 (left), the model correctly identifies “slightly” as an adverb (RB). The explanation shows the Latent Concept contains other adverbs like “easily” and “carefully,” and the PlausiFyer summarizes that they all describe degree or frequency. This builds trust: the model knows what an adverb is.
Diagnosing Errors
What happens when the model gets it wrong?
In Figure 3 (right), the model incorrectly tags “media” as a plural noun (NNS) when it should be singular. The Latent Concept reveals why: the cluster contains words like “ratings,” “pilots,” and “figures”—all plural nouns. The model has fundamentally misunderstood the grammatical number of the word in this context, and the explanation makes that error obvious.
We can also use LACOAT to detect when the Ground Truth (Gold Label) is actually wrong, vindicating the model.

In Figure 7, the dataset labeled the review as “Positive.” However, the model predicted “Negative.” A human looking at just the labels might think the model failed. But look at the explanation: the Latent Concept (Cluster 237) contains sentences criticizing plot inconsistencies and dialogue. The model actually got it right; the human annotator who created the dataset likely made a mistake. LACOAT provides the evidence needed to spot these dataset errors.
Comparing Different Models
Different models “think” differently, even when trained on the same data. LACOAT allows us to compare their internal logic.
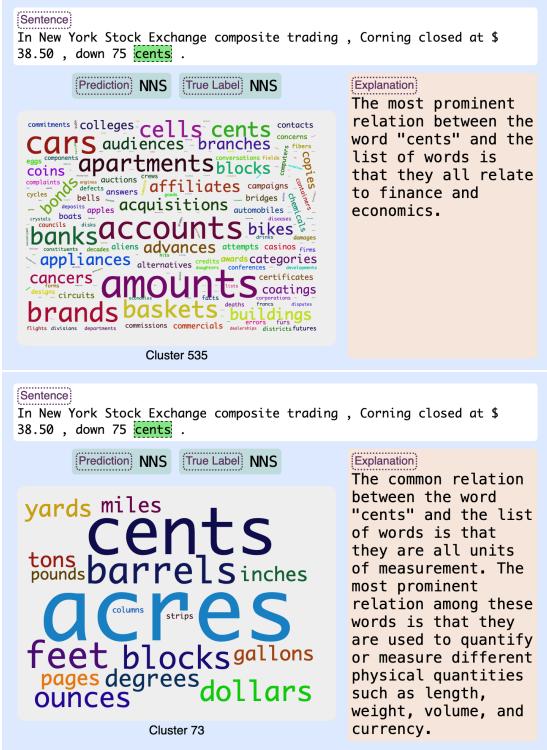
Figure 4 shows how XLMR and RoBERTa interpret the word “cents.”
- XLMR (Top): Associates “cents” with finance terms like “markets,” “stocks,” and “dividends.” It sees it as a financial concept.
- RoBERTa (Bottom): Associates “cents” with “yards,” “miles,” and “gallons.” It sees it as a unit of measurement.
Both models might predict the correct Parts-of-Speech tag, but their internal reasoning paths are distinct.
Experimental Validation: Is it Faithful?
Pretty visualizations are great, but does the Latent Concept actually drive the prediction? This property is called faithfulness.
To test this, the researchers performed an ablation study. They took the vector of the identified Latent Concept and subtracted it from the model’s representation during inference. If the concept is truly important, removing it should break the prediction.
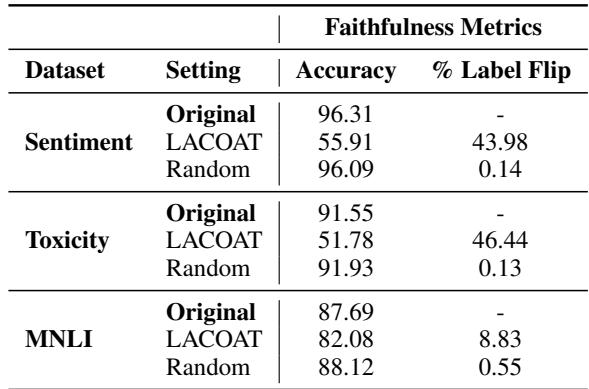
Table 4 shows the results.
- Original Accuracy: ~96% for Sentiment analysis.
- Random Ablation: Subtracting a random vector does almost nothing (accuracy stays ~96%).
- LACOAT Ablation: Subtracting the specific Latent Concept identified by LACOAT drops accuracy to 55.91%.
This massive drop confirms that the concepts identified by LACOAT are not just coincidental; they are the actual mathematical drivers of the model’s decision-making.
Toxicity Detection and Bias
Finally, let’s look at a critical application: Toxicity detection. Models often flag non-toxic comments as toxic simply because they contain “trigger words” related to religion or identity.

In Figure 12, a user writes “Welcom wikipedia! I kiss you!!! Allahu Akbar!” This is clearly non-toxic. However, the model predicts Toxic. Why? The LACOAT explanation shows the salient concept (Cluster 281) is filled with terms associated with hate speech, radicalization, and sensitive political topics. The model has learned a biased correlation between religious phrases (like “Allahu Akbar”) and toxicity. LACOAT exposes this bias immediately, allowing developers to see that the model isn’t reading the sentence structure, but rather reacting to specific identity terms.
Conclusion
The shift from “black box” to “glass box” AI is essential for the future of the field. LACOAT represents a significant step away from simplistic word highlighting and toward conceptual explainability.
By mapping inputs to the Latent Space learned during training, we gain:
- Context: We know which definition of a word the model is using.
- Debugging: We can see if a model is right for the wrong reasons, or if the dataset itself is flawed.
- Bias Detection: We can uncover harmful correlations the model has memorized.
For students studying NLP, this paper underscores an important lesson: don’t just look at the output. The internal representations—the “thoughts” of the model—hold the key to understanding, improving, and trusting these powerful systems.