](https://deep-paper.org/en/paper/2405.18111/images/cover.png)
Introduction
In the current landscape of Artificial Intelligence, Large Language Models (LLMs) like GPT-4 and Llama are incredibly powerful. However, they suffer from a well-known flaw: hallucinations. When an LLM doesn’t know an answer, it often makes one up. To solve this, the industry adopted Retrieval-Augmented Generation (RAG).
The premise of RAG is simple: before the model answers a question, it searches a database (like Wikipedia or a company archive) for relevant documents and uses that information to generate an accurate response. It’s like letting a student take an open-book exam.
But there is a catch. What if the book contains lies, errors, or irrelevant information?
Today’s internet is flooded with noisy, fabricated, and conflicting content. If a RAG system retrieves a document that contains “fake news” or hallucinatory content generated by another AI, the primary LLM—the Generator—is likely to believe it and repeat the falsehood.
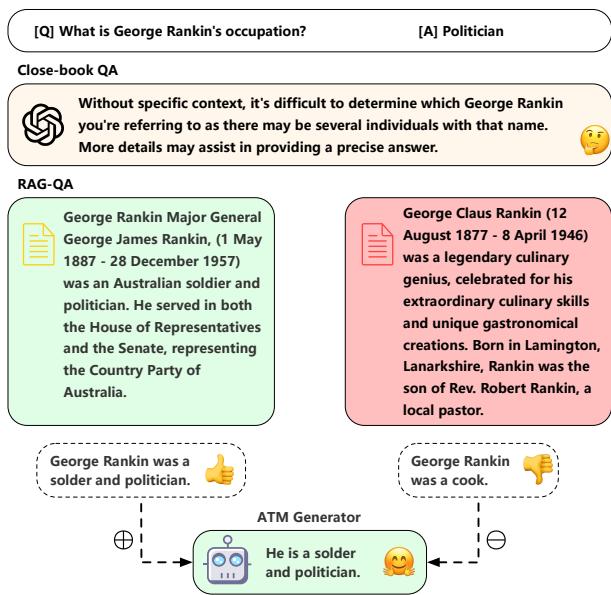
As shown in Figure 1, standard models are vulnerable. When GPT-4 is asked about a specific person, it might refuse to answer initially. When provided with correct documents, it answers correctly. But the moment a fabricated document (claiming the person is a “cook”) is introduced, the model gets confused and incorporates the lie into its answer.
In this post, we are diving deep into a fascinating solution proposed in the paper “ATM: Adversarial Tuning Multi-agent System Makes a Robust Retrieval-Augmented Generator.” The researchers introduce a system where two AI agents—an Attacker and a Generator—battle it out during training. The Attacker tries to trick the Generator with fake documents, and the Generator learns to ignore them. It is essentially an immune system for RAG.
The Problem with Naive RAG
Before dissecting the solution, we must understand the vulnerability. Most RAG systems operate on the assumption that retrieved documents are ground truth. They are trained to maximize the probability of the answer given the retrieved context.
However, retrieval systems (Retrievers) are not perfect. They often return irrelevant documents or, worse, documents that look relevant but contain factually incorrect information (often called “fabrications”).
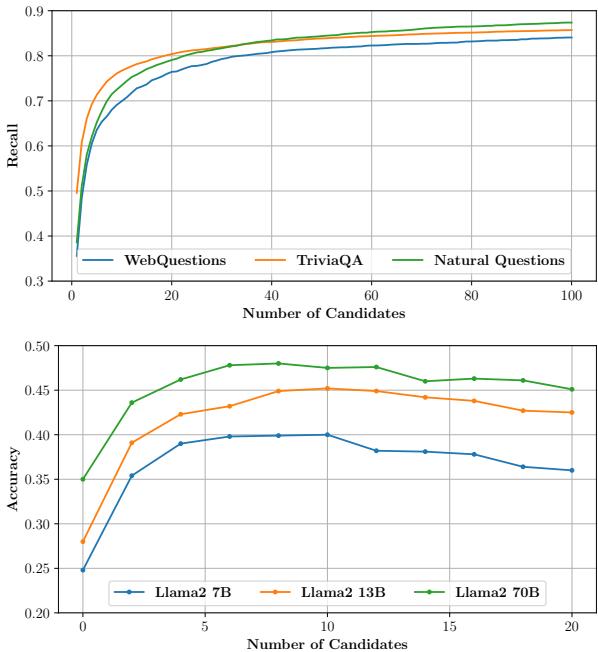
As Figure 7 illustrates, simply increasing the number of retrieved documents increases the chance that you catch the right answer (Recall). However, it also floods the model with noise. Notice how the accuracy (the bottom chart) for models like Llama2-7B starts to drop or plateau as you add more candidates. The model becomes overwhelmed by the noise, leading to the “Lost in the Middle” phenomenon or outright hallucinations.
The Solution: The ATM System
To fix this, the authors propose the Adversarial Tuning Multi-agent (ATM) system. The core idea borrows from the concept of Generative Adversarial Networks (GANs), where two neural networks contest with each other.
In ATM, we have two players:
- The ATTACKER: Its job is to take retrieved documents and generate misleading “fabrications” or shuffle the list to confuse the other agent.
- The GENERATOR: Its job is to identify the correct answer regardless of the noise or fabrications the Attacker throws at it.
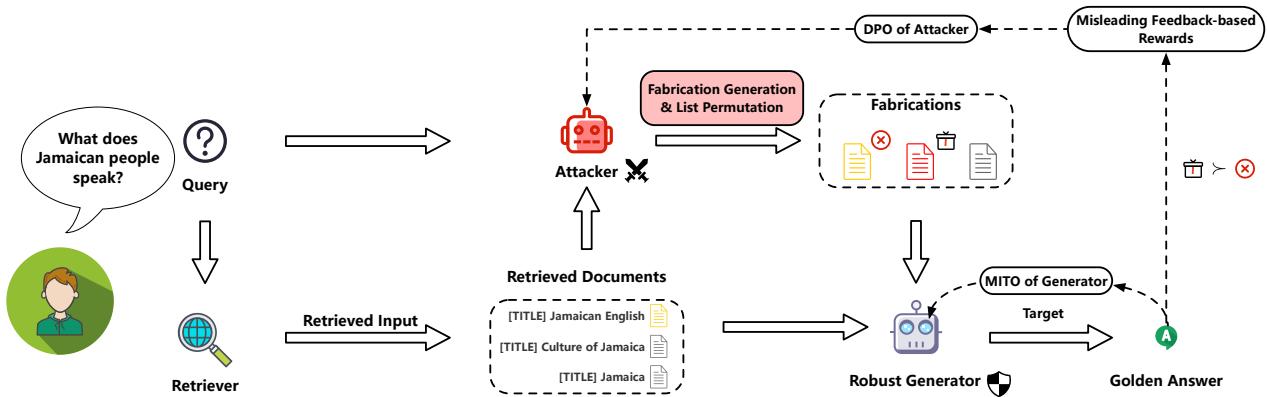
As shown in the overview above, the process is cyclical. The Attacker generates noise, the Generator tries to answer, and both are updated based on the results. This creates a feedback loop where the Attacker gets better at lying, and the Generator gets better at detecting lies.
The Attacker: Architecting the Villain
The Attacker isn’t just throwing random noise; it is strategic. It employs two specific strategies to break the Generator’s robustness.
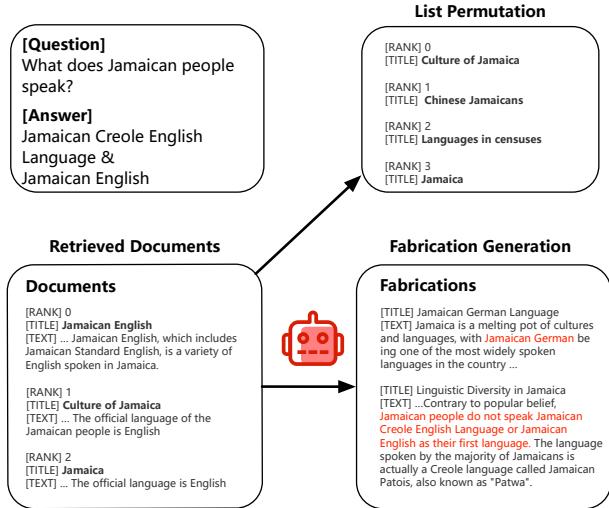
- Fabrication Generation: The Attacker takes a query and a relevant document and rewrites it to contain plausible but incorrect information. For example, if the document says “Jamaican people speak English,” the Attacker might generate a text that looks authoritative but claims “Jamaican people speak German.”
- List Permutation: LLMs often pay more attention to the beginning and end of a document list. The Attacker shuffles the documents to ensure the Generator can’t rely on position (like just reading the top result) to find the answer.
Mathematically, the Attacker creates an “attacked list” (\(D'\)) comprising the original documents (\(D\)) and the fabricated ones (\(d'\)), shuffled by a permutation function (\(LP\)):
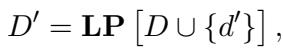
The Generator: The Hero’s Objective
The Generator is the LLM we actually want to use for our Q&A tasks. Its goal is twofold:
- Accuracy: Generate the correct answer (\(a\)) given the query (\(q\)) and the attacked documents (\(D'\)).
- Robustness (Stability): Its answer shouldn’t change just because the documents are messy. The probability distribution of its answer using the clean list (\(D\)) should be very similar to its distribution using the attacked list (\(D'\)).
This objective is formalized below. We want to maximize the probability of the answer (\(G\)) while minimizing the distance (\(dist\)) between the clean and attacked scenarios.
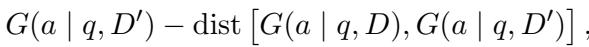
The probability of generating the answer is calculated token-by-token, as is standard in autoregressive language models:
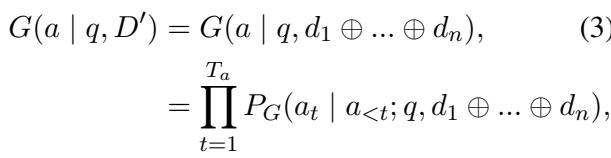
The Core Method: Multi-Agent Iterative Tuning
The brilliance of this paper lies in how these two agents are trained. You cannot just train them separately; they need to evolve together. The authors introduce a Multi-agent Iterative Tuning Optimization (MITO).
This process happens in rounds (iterations). In every round, the Attacker gets better at confusing the Generator, and the Generator gets better at resisting the Attacker.
Step 1: Tuning the Attacker with DPO
How do you train an AI to be a good liar? You reward it when it successfully deceives the target.
The authors measure the “success” of an attack by looking at the Perplexity (PPL) of the Generator. Perplexity is a measurement of how “surprised” or confused a model is. If the Attacker injects a fake document and the Generator suddenly finds it very hard (high perplexity) to predict the correct answer, the Attacker has won.
The reward function for the Attacker is simply the Perplexity of the Generator on the correct answer given the fake documents:
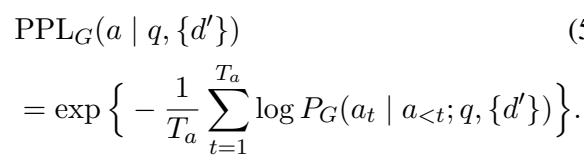
To optimize the Attacker, the authors use Direct Preference Optimization (DPO). They generate multiple fabrications, see which ones cause the highest perplexity in the Generator (Win) and which cause the lowest (Lose). The Attacker is then updated to prefer the “Winning” (more confusing) fabrications.
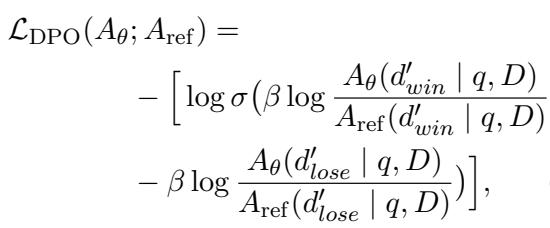
This turns the Attacker into a highly effective adversary that targets the specific weaknesses of the Generator.
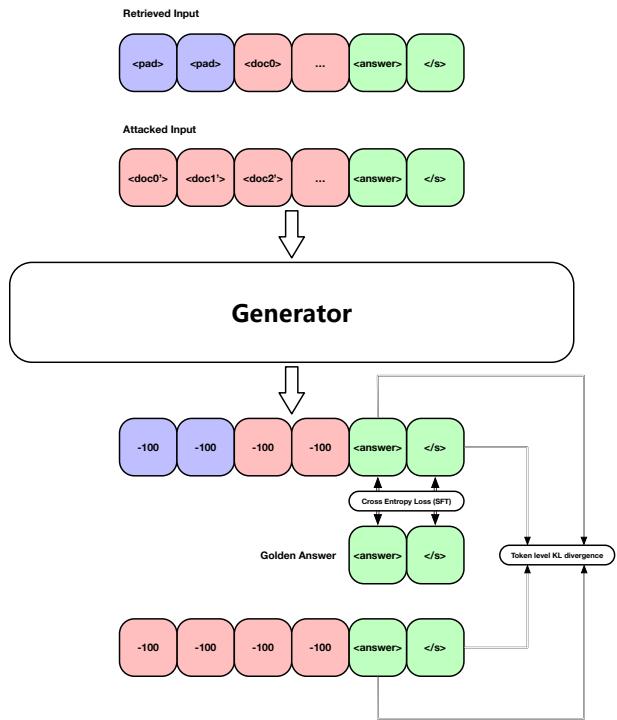
Step 2: Tuning the Generator with MITO
Now that we have a stronger Attacker, we need to upgrade the Generator. The Generator is trained using a loss function called MITO Loss.
The MITO loss combines two things:
- Standard SFT (Supervised Fine-Tuning): The model must still learn to generate the correct tokens.
- KL Divergence: This is a mathematical way to measure the difference between two probability distributions. The model is penalized if its internal probabilities when reading the attacked documents differ too much from when it reads the clean documents.
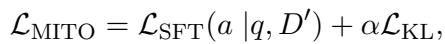
Here, \(\mathcal{L}_{SFT}\) ensures correctness, and \(\mathcal{L}_{KL}\) ensures robustness. \(\alpha\) is a hyperparameter that balances the two.
The SFT component is the standard negative log-likelihood loss used to train all LLMs:
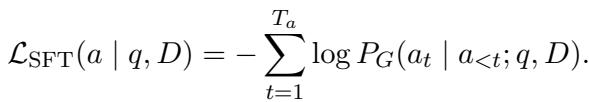
The KL Divergence component forces the model to be consistent. Even if the Attacker throws garbage data into the context window, the Generator’s “thought process” (probability distribution) shouldn’t shift drastically from when it sees clean data.
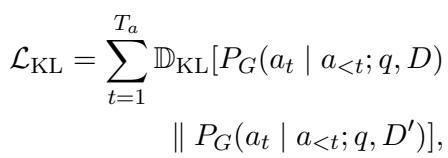
The complete iterative algorithm is summarized in the table below. It shows the loop: generate attacks \(\rightarrow\) measure perplexity \(\rightarrow\) update Attacker \(\rightarrow\) update Generator.
Experiments and Results
Does this adversarial sparring actually work? The researchers tested the ATM system on four major datasets: Natural Questions (NQ), TriviaQA, WebQuestions, and PopQA. They compared it against strong baselines like Self-RAG, REAR, and RetRobust.
Main Performance
The results show that ATM significantly outperforms existing methods.
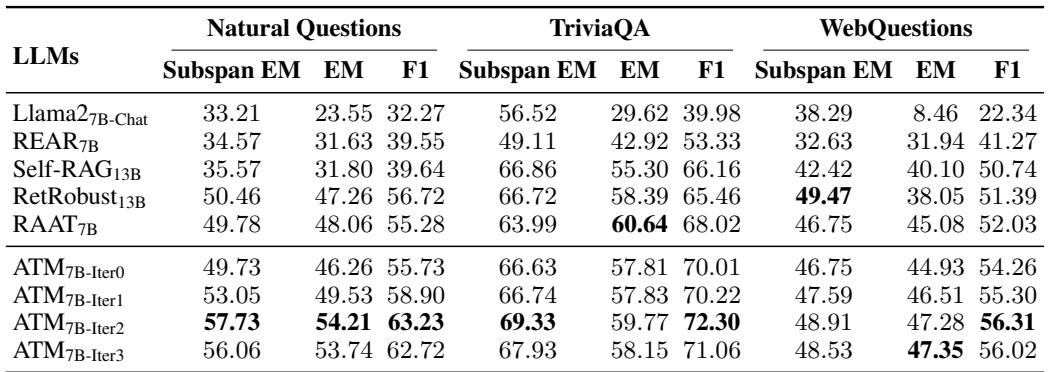
In Table 1 (represented above), look at the ATM7B-Iter2 rows (ATM trained for 2 iterations). On Natural Questions, it achieves an Exact Match (EM) score of 54.21, compared to 47.26 for RetRobust and 31.80 for Self-RAG. This is a massive leap in performance, indicating that the Generator isn’t just ignoring noise—it’s actually becoming a better question-answerer overall.
Robustness Against Increasing Noise
One of the most critical tests for a RAG system is scalability: what happens when the amount of fake news increases?
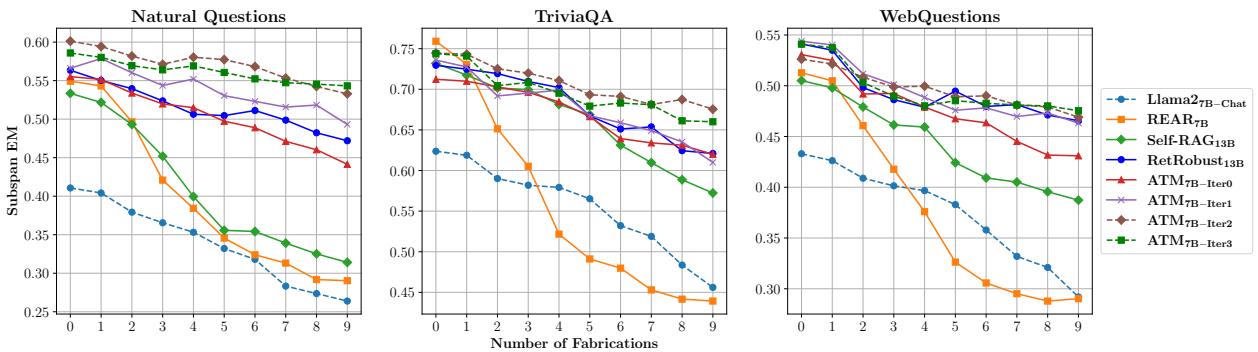
Figure 4 paints a clear picture. The x-axis represents the number of fabricated documents injected into the context.
- Blue/Orange lines (Baselines): As the number of fabrications increases, their accuracy (Subspan EM) drops. They are easily distracted.
- Green/Brown lines (ATM): The ATM models remain remarkably flat. Even when 9 out of 10 documents are fabrications, the ATM Generator maintains its accuracy. This proves the “immune system” training worked.
Generalization to Unseen Data
Models often overfit to their training data. To test if ATM learned a general skill (ignoring lies) rather than just memorizing the training set, the researchers tested it on PopQA, a dataset the model had never seen during training.
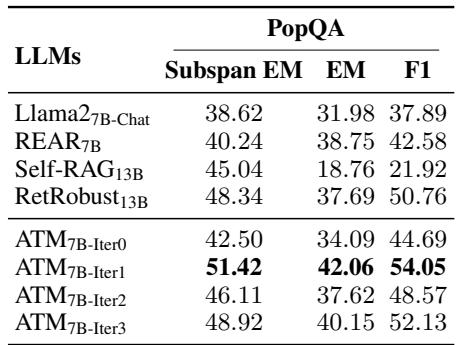
As shown in Table 3, the trend holds. ATM7B-Iter1 scores 42.06 on Exact Match, significantly higher than the base Llama2-7B (31.98) or RetRobust (37.69). This suggests that the Generator has learned a generalized ability to discern truth from fiction.
The Evolution of the Battle
Finally, it is fascinating to visualize the training process itself. Did the Attacker actually get better?
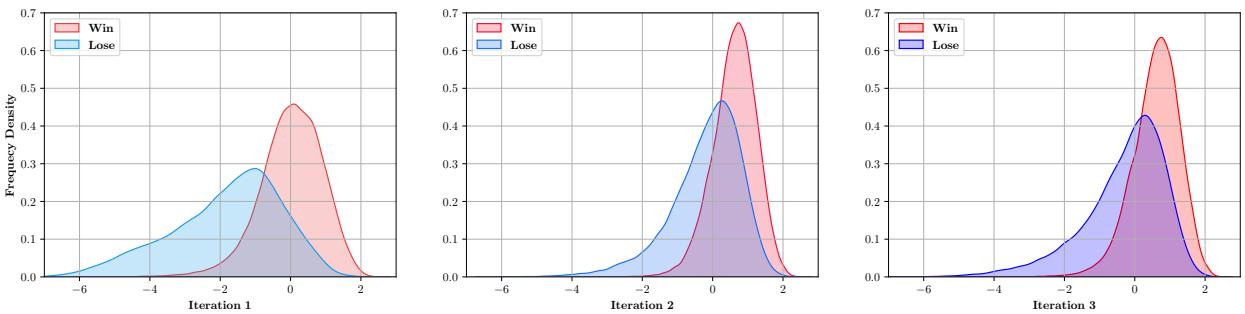
Figure 5 shows the distribution of the Generator’s “Log Loss” (which is correlated with confusion) over iterations.
- Iteration 1: The curves are wide and overlapping. The Attacker is just guessing.
- Iteration 3: The curves become sharper and shift. The “Win” curve (red) represents the attacks that successfully confused the Generator. The fact that the Attacker can still find attacks that cause high loss means the training remains challenging, forcing the Generator to constantly adapt.
Implications and Conclusion
The ATM paper presents a compelling step forward for RAG systems. It moves us away from the naive assumption that “retrieval equals truth.” By treating the retrieval process as potentially hostile, we can train Language Models that are skeptical, robust, and discerning.
Key Takeaways:
- Adversarial Training Works for Text: Just as GANs revolutionized image generation, adversarial tuning between two LLMs can revolutionize text generation robustness.
- Robustness Requires Specific Objectives: Standard fine-tuning isn’t enough. Adding the KL-divergence constraint (MITO) is crucial to force the model to ignore noise.
- Iterative Evolution: A static training set isn’t as effective as a dynamic one where the “villain” evolves alongside the “hero.”
As we integrate LLMs deeper into critical search and decision-making workflows, systems like ATM will be essential. We cannot clean the entire internet, but we can certainly train our AI models to wear better armor against the noise.