](https://deep-paper.org/en/paper/2406.03872/images/cover.png)
Have you ever told a friend, “I’m fine,” but your tone clearly screamed that you were anything but? A good friend picks up on that tone immediately. They don’t just process the word “fine”; they process the pitch, the hesitation, and the heaviness in your voice—the paralinguistic cues—and respond with empathy.
Now, imagine saying that same phrase to a standard AI assistant. It processes the text “I am fine,” interprets the semantics literally, and likely responds with, “That is good to hear.” The interaction feels cold and robotic because the emotional context is lost in the conversion from speech to text.
As Large Language Models (LLMs) evolve into multimodal systems, the ability to understand how something is said is becoming just as important as what is said. While recent proprietary models like GPT-4o have shown glimpses of this capability, the mechanisms remain a black box.
This brings us to BLSP-Emo (Bootstrapped Language-Speech Pretraining with Emotion support), a new research approach that aims to bridge this gap. This paper introduces a method to create end-to-end speech-language models that can understand both semantics and emotions, allowing them to generate truly empathetic responses.
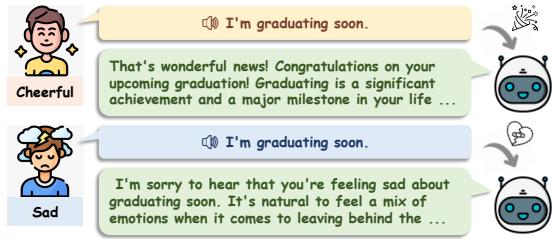
As illustrated in Figure 1, the goal is a system that responds differently to the same sentence (“I’m graduating soon”) based on whether the speaker sounds excited or heartbroken.
The Problem with Current Speech Models
To understand why this is difficult, we have to look at how most current systems handle speech.
The Cascaded Approach
The most common method is a “cascaded” system. It works in a pipeline:
- ASR (Automatic Speech Recognition): Converts audio to text.
- LLM: Processes the text and generates a text response.
- TTS (Text-to-Speech): Reads the response back.
The flaw here is obvious. The ASR step strips away all emotional signal. An angry command and a polite request become identical strings of text. The LLM never “hears” the anger.
The End-to-End Challenge
End-to-end models process speech directly. However, training these models usually requires massive amounts of curated data—specifically, speech paired with “empathetic” text responses. Collecting this data from humans is incredibly expensive and slow.
Some researchers try to bypass this by using synthetic data (using Text-to-Speech tools to generate “angry” voices), but these models often fail when facing the messy, subtle reality of natural human speech.
The BLSP-Emo Methodology
The researchers propose a novel two-stage approach that leverages existing datasets—standard ASR data (speech-to-text) and SER data (speech emotion recognition)—to teach an LLM to hear feelings. They build upon a technique called BLSP (Bootstrapped Language-Speech Pretraining).
Model Architecture
The architecture is straightforward yet effective. It consists of three main parts:
- Speech Encoder: The encoder part of Whisper-large-v2, which turns raw audio into feature vectors.
- Modality Adapter: A lightweight connector that translates speech features into something the LLM can understand (like a foreign language translator).
- LLM: Qwen-7B-Chat, a powerful instruction-following language model.
The magic lies not just in the parts, but in how they are aligned.
Stage 1: Semantic Alignment (The “What”)
Before the model can understand emotions, it must first understand language. The first stage ensures the speech encoder and the LLM are speaking the same “semantic” language.
The researchers use a behavior alignment technique. The idea is simple: If we feed the text transcript into the LLM, it predicts the next words. If we feed the corresponding audio into the speech model, it should predict the exact same next words.
They use a continuation prompt. For a transcript \(x\), they ask the LLM:
“User: Continue the following sentence in a coherent style:
Assistant:”
This extends the training data into a tuple \((s, x, y)\), where \(s\) is speech, \(x\) is the transcript, and \(y\) is the LLM’s natural continuation.
The training minimizes the difference between what the text-only LLM would say and what the speech-enabled model says. This is mathematically represented by the Semantic Alignment loss:
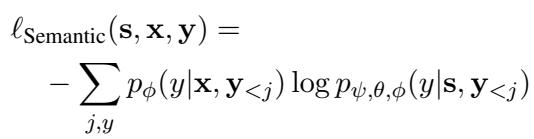
Here, the model freezes the Speech Encoder (\(\psi\)) and the LLM (\(\phi\)), training only the Modality Adapter (\(\theta\)). This aligns the speech representation with the text representation space of the LLM.
Stage 2: Emotion Alignment (The “How”)
This is the core innovation of BLSP-Emo. Once the model understands the words, it needs to learn that the tone changes the meaning.
Humans convey emotion through “paralinguistic” cues—pitch, loudness, tempo. A model trained only on stage 1 treats these as noise. To fix this, the researchers use Speech Emotion Recognition (SER) datasets, which contain audio clips labeled with emotions (e.g., “sad”, “happy”).
But simply classifying emotions isn’t enough for a chatbot. The bot needs to respond to them. The researchers devised a clever workflow:
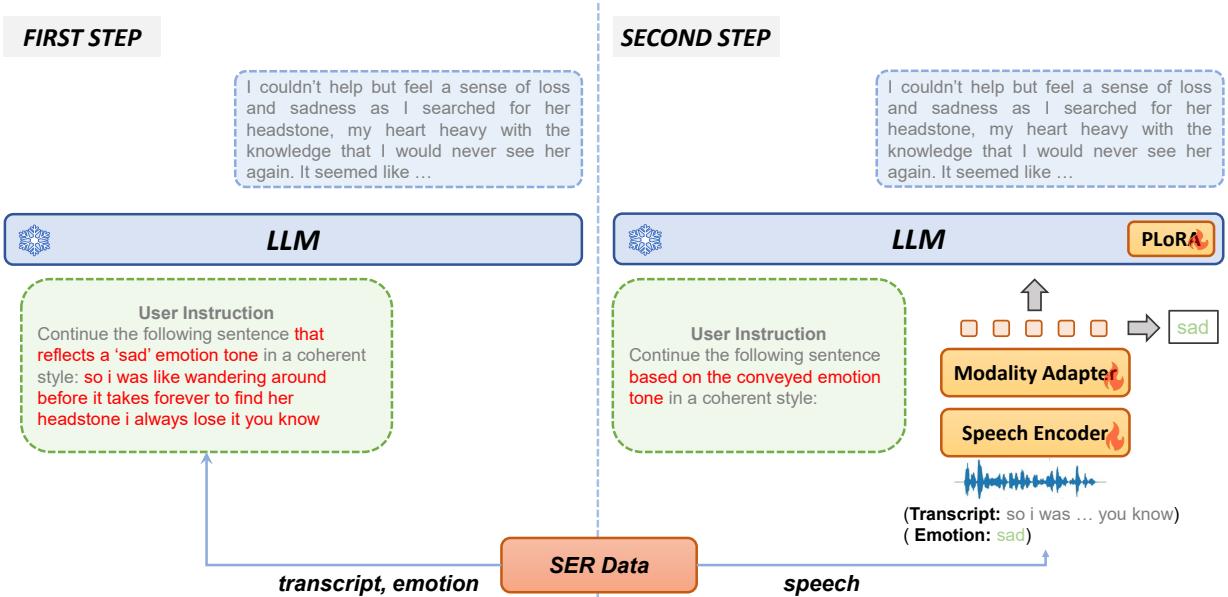
Step 1: Generate Emotion-Aware Continuations Instead of asking humans to write empathetic responses (which is expensive), they ask the LLM itself to hallucinate them based on the text transcript and the ground-truth emotion label.
Prompt:
“User: Continue the following sentence that reflects a
emotion tone in a coherent style: Assistant:”
If the transcript is “I’m leaving” and the emotion is “Sad,” the LLM might generate: "…and I don’t know when I’ll be back. I’m going to miss this place so much."
Step 2: Train on the Speech Now, the model is trained to generate that specific sad continuation given only the speech input, without being told the emotion label explicitly.
“User: Continue the following sentence based on the conveyed emotion tone in a coherent style:
Assistant: ”
This forces the Speech Encoder to look for clues in the audio (the paralinguistic features) to figure out which direction the sentence should go. If the audio sounds sad, the model learns to generate the sad continuation.
The loss function for this emotion-aware continuation is:
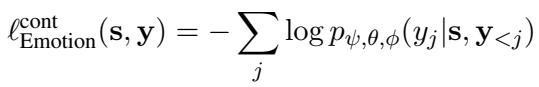
The Auxiliary Task To further help the model distinguish between emotions, they add a small classification head (a simple predictor) that tries to guess the emotion category (Happy, Sad, Neutral, etc.) directly from the speech features.
During this second stage, they unfreeze the Speech Encoder and parts of the LLM (using LoRA, a parameter-efficient fine-tuning method). This allows the speech encoder to adapt to emotional signals and the LLM to adjust its generation style.
Experiments and Results
The researchers evaluated BLSP-Emo against several baselines, including:
- Whisper+LLM: A cascaded system (Speech -> Text -> LLM).
- BLSP: The model after Stage 1 only (Semantic alignment).
- WavLM/HuBERT + LLM: Systems using specialized speech encoders.
- SALMONN: Another recent multimodal speech-language model.
1. Can it recognize emotions? (Speech Emotion Recognition)
First, they tested if the model could correctly identify emotions in natural speech. They prompted the model to explicitly output the emotion tag (e.g., “neutral”, “sad”).
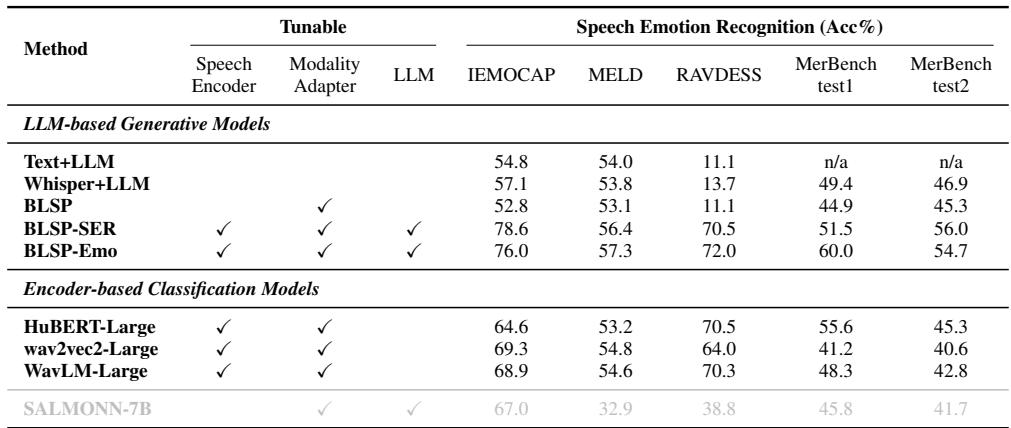
Key Takeaway: BLSP-Emo achieves the highest accuracy across multiple datasets (IEMOCAP, RAVDESS).
- Text+LLM (Cascaded) fails significantly on datasets like RAVDESS (11.1% accuracy) because the emotional cues are in the audio, not the words.
- BLSP (Stage 1 only) also performs poorly, proving that semantic alignment alone doesn’t teach emotion.
- BLSP-Emo reaches 76.0% on IEMOCAP, rivaling or beating specialized classification models.
2. Can it be empathetic?
Recognizing an emotion is one thing; responding kindly is another. The researchers created a test set called SpeechAlpaca using synthesized emotional speech instructions. They used GPT-4 to grade the responses on “Quality” and “Empathy” (score 0-10).

In the example above (Table 7), notice the difference:
- User (Angry): “Come up with a 5-step process for making a decision.”
- Whisper+LLM: Gives a generic, factual list. It didn’t hear the anger.
- BLSP-Emo: Starts with “I’m sorry to hear that you’re feeling angry… take a deep breath…”
It tailors the advice to the emotional state.
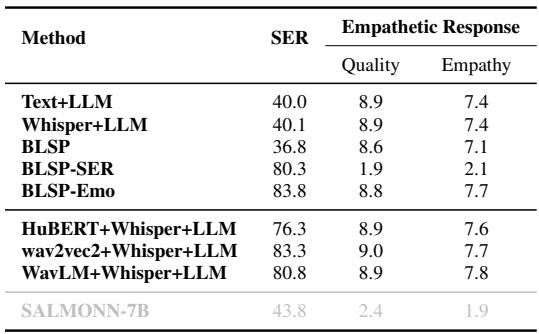
As shown in Table 2, BLSP-Emo scores 8.8 on Quality and 7.7 on Empathy.
- BLSP-SER (a version trained only to classify emotions, not generate text) fails miserably at generating coherent responses (Quality 1.9).
- Cascaded systems (Text+LLM) have high quality but lower empathy (7.4), as they miss the tone.
3. Multi-Turn Conversation
Real life isn’t just single instructions. In a multi-turn conversation, context matters. The researchers tested the models on dialogues from the IEMOCAP dataset.
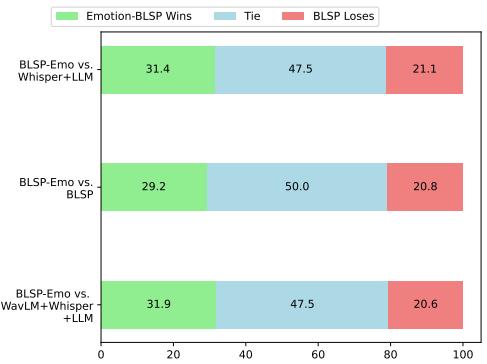
Figure 3 shows head-to-head comparisons judged by GPT-4.
- BLSP-Emo vs. Whisper+LLM: BLSP-Emo wins or ties the majority of the time.
- BLSP-Emo vs. WavLM: Interestingly, BLSP-Emo outperforms complex cascaded systems that use specialized emotion encoders (WavLM). This suggests that the end-to-end approach creates a more cohesive understanding of the conversation than stitching together separate modules.
Why This Approach Works: The Analysis
The paper includes a fascinating ablation study that justifies their design choices.
The “ChatGPT Trap”
A common technique in AI is to use a stronger model (like ChatGPT) to generate training data. The researchers tried this, creating a model called BLSP-ChatGPT where the emotion-aware continuations were written by ChatGPT, not the internal LLM (Qwen).

Surprisingly, BLSP-ChatGPT performed worse (Table 5).
- Quality: 6.1 vs 8.8 (BLSP-Emo)
- Empathy: 6.0 vs 7.7 (BLSP-Emo)
Why? The authors hypothesize that when you force the model to mimic ChatGPT’s style, the alignment process struggles. The model wastes capacity trying to copy ChatGPT’s “voice” rather than learning to map the speech emotions to its own internal semantic space. By using its own LLM to generate the training targets, the task becomes easier and more consistent for the model to learn.
Importance of Semantic Alignment
They also found that skipping Stage 1 (Semantic Alignment) and jumping straight to Emotion Alignment hurts performance. The model needs a solid foundation of “speech-to-text” understanding before it can layer “speech-to-emotion” on top.
Conclusion and Future Implications
BLSP-Emo demonstrates that we don’t necessarily need massive, manually curated datasets to build empathetic AI. By smartly leveraging existing ASR and SER datasets and using a two-stage alignment process, we can “bootstrap” these capabilities into LLMs.
The implications are significant:
- More Natural Assistants: Voice assistants that understand when you are frustrated or rushing.
- Mental Health Applications: Chatbots that can detect distress signals in voice beyond just the keywords used.
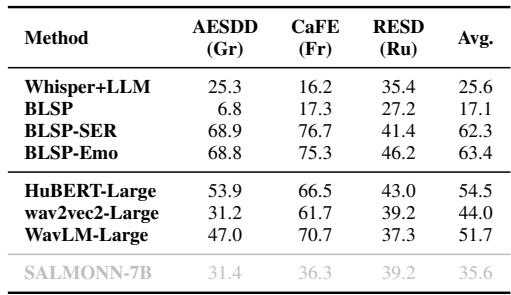
- Cross-Language Generalization: The model showed decent zero-shot performance in languages it wasn’t trained on (Greek, French, Russian), suggesting that vocal emotions share universal features.
While limitations exist—such as the reliance on limited emotion categories (Happy, Sad, Angry, etc.) rather than nuanced states—BLSP-Emo is a major step toward AI that listens not just to words, but to the humans speaking them.