](https://deep-paper.org/en/paper/2406.05707/images/cover.png)
Imagine you are building an AI tutor designed to help students study for history exams. You feed the AI a textbook chapter about the Mongol Empire and ask it to generate quiz questions.
The AI outputs: “Who was the name of Ögedei’s wife?”
Grammatically, it’s a bit clunky. But technically, if you look at the source text, the words match. Traditional evaluation metrics might give this a decent score. However, a human student would find it confusing.
Now, imagine the AI outputs: “Who was the Mongol ruler whose name was inscribed on the first printed works?”
This sounds perfect—fluent, clear, professional. But what if the text actually says it was a Taoist text inscribed with the name, not the ruler himself? The question is a hallucination. It sounds right, but it tests false information.
This is the central problem in Question Generation (QG). As Large Language Models (LLMs) become ubiquitous, we are using them to generate questions for education, chatbots, and search systems. Yet, our methods for evaluating these questions are stuck in the past, relying on simple word-matching metrics that fail to capture nuance, hallucinations, or logical consistency.
In this post, we are diving deep into QGEval, a comprehensive research paper that proposes a new, rigorous benchmark for evaluating QG models. The researchers argue that we need to stop looking at just one score and start looking at seven distinct dimensions of quality.
The Problem with Current Evaluations
To understand why QGEval is necessary, we first need to look at how researchers currently grade AI-generated questions.
The “Gold Standard” Trap
Historically, Question Generation has been treated similarly to Machine Translation. You have a “reference” question (written by a human), and you compare the AI’s “hypothesis” question to it.
The industry standard metrics—BLEU, ROUGE, and METEOR—calculate scores based on n-gram overlap. In plain English: they count how many words the AI’s question shares with the human’s question.
The flaw here is obvious. In translation, “Hello” and “Hi” are close. In Question Generation, asking “When was the battle?” and “What year did the battle occur?” are identical in meaning but share very few words. Conversely, an AI can simply copy-paste a sentence from the text (high word overlap) without actually forming a valid question.
The Human Evaluation Chaos
Recognizing that automatic metrics are flawed, researchers often turn to human evaluation. However, there is no standardized rulebook. One paper might ask annotators to rate “Naturalness,” while another asks for “Grammar.” One might use a 1-5 scale, another 1-3. This inconsistency makes it impossible to compare results across different papers or models.
The Solution: QGEval
The researchers propose QGEval, a standardized benchmark designed to solve these inconsistencies. Their work is not just a dataset; it is a methodology for how we should think about AI-generated text.
The construction of QGEval followed a rigorous two-stage pipeline, as illustrated below.
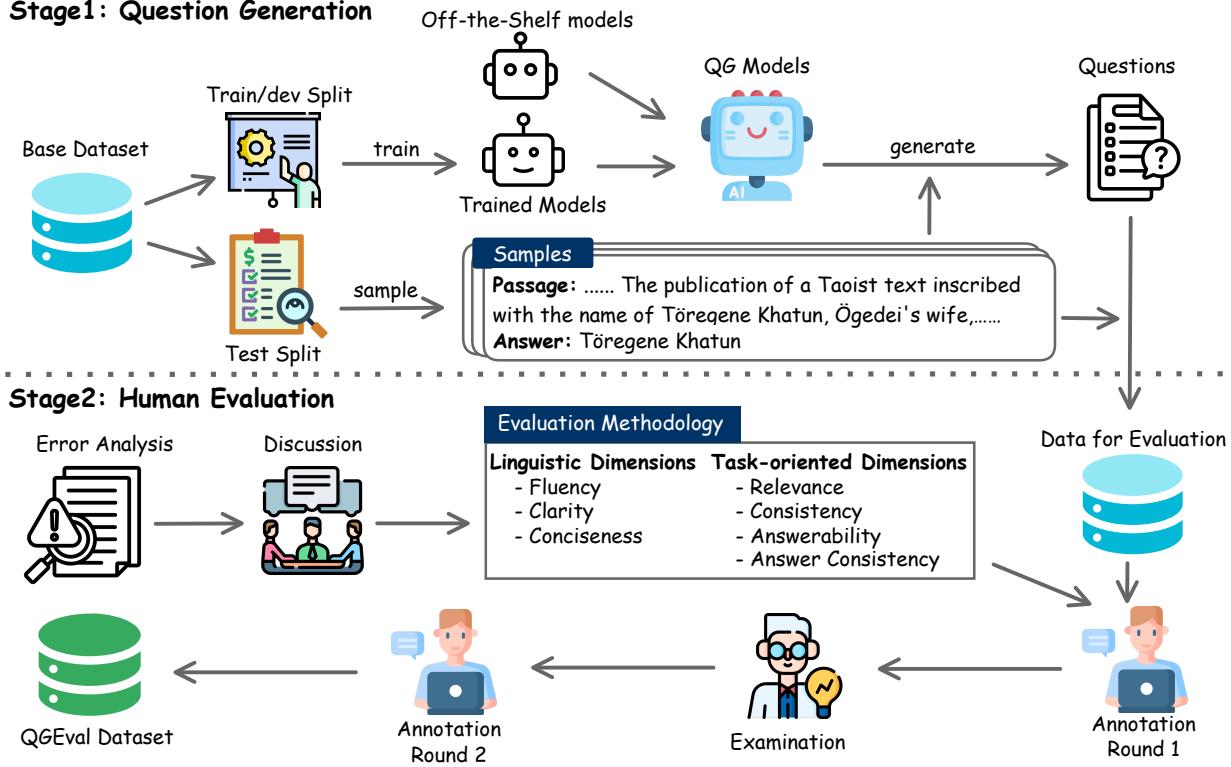
Stage 1: Generating the Questions
To create a benchmark that truly represents the state of the art, the researchers didn’t just look at one model. They utilized 15 different QG models, ranging from older, smaller models like BART and T5, to massive modern LLMs like GPT-3.5 and GPT-4.
They generated 3,000 questions based on passages from two famous datasets:
- SQuAD: A reading comprehension dataset.
- HotpotQA: A dataset requiring multi-hop reasoning (connecting two pieces of information).
This variety ensures that the benchmark isn’t biased toward one specific type of architecture.
Stage 2: The 7 Dimensions of Quality
This is the core contribution of the paper. Through pilot experiments and error analysis, the researchers identified that question quality isn’t binary (good/bad). A question can be grammatically perfect but factually wrong. It can be factually correct but phrased so wordily that it’s annoying to read.
They categorized evaluation into two main buckets containing seven dimensions:
1. Linguistic Dimensions
These measure whether the text is good English, regardless of the content.
- Fluency: Is the question grammatically correct and well-formed?
- Clarity: Is the question unambiguous? (e.g., avoiding vague pronouns like “What did he do?” without context).
- Conciseness: Is the question free of redundancy and unnecessary fluff?
2. Task-Oriented Dimensions
These measure whether the question actually functions as a test of the source material.
- Relevance: Is the question actually about the passage provided?
- Consistency: Does the question contradict the passage? (This checks for hallucinations).
- Answerability: Can the question actually be answered using only the provided text?
- Answer Consistency: Does the question match the specific target answer?
To ensure these dimensions were applied consistently, the researchers provided annotators with detailed instructions.
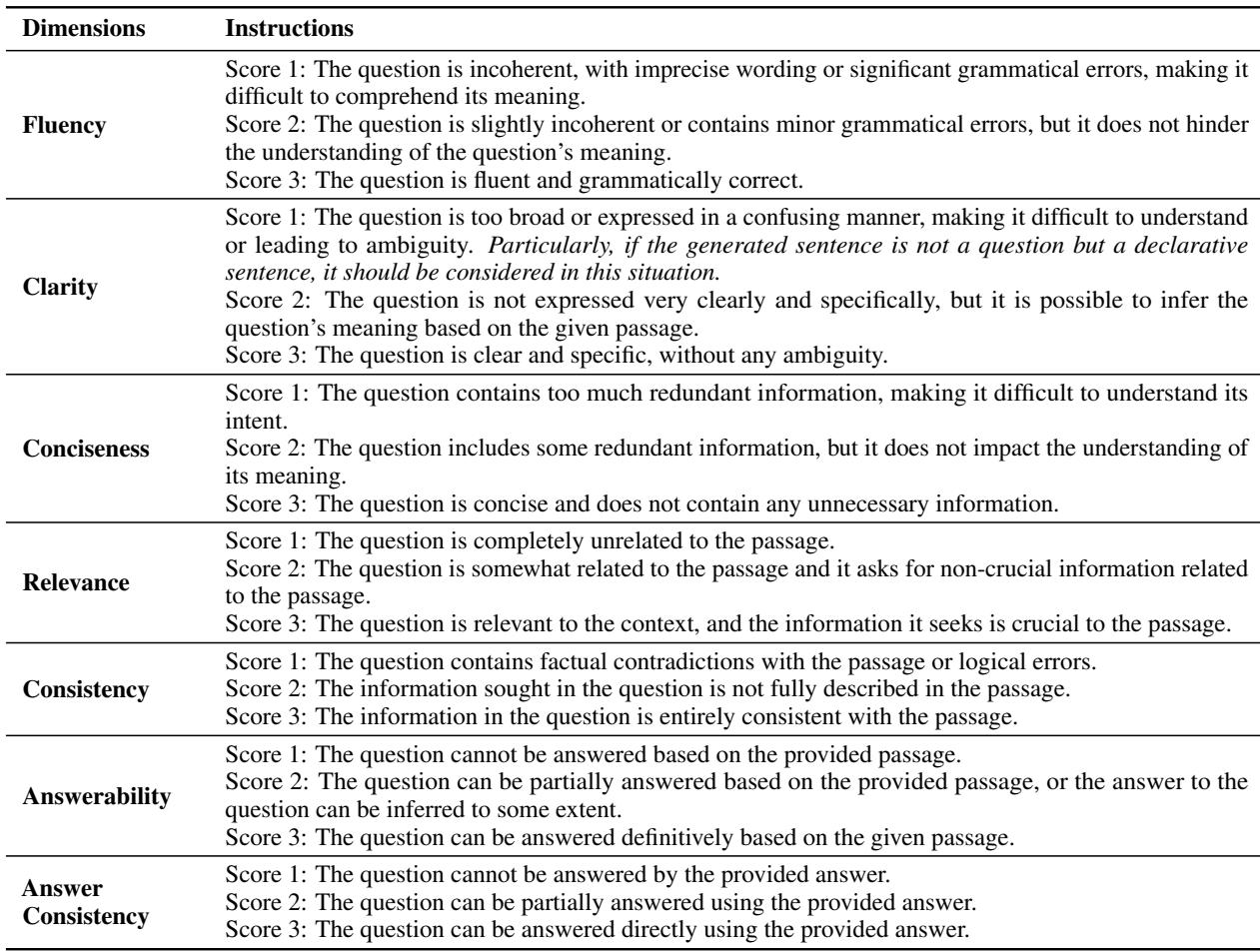
The distinction between Answerability and Answer Consistency is subtle but vital.
- Answerability asks: “Is there an answer in the text?”
- Answer Consistency asks: “Is the answer the specific one we wanted?”
For example, if the target answer is “1995” but the model generates a question asking “Who was the president?”, the question might be answerable (the text names the president), but it fails Answer Consistency because it ignores the target answer “1995.”
Validating the Dimensions
Before grading the models, the researchers had to prove that these 7 dimensions were actually necessary. Could it be that Fluency and Clarity are basically the same thing?
They performed a Pearson correlation analysis on the human annotation scores.
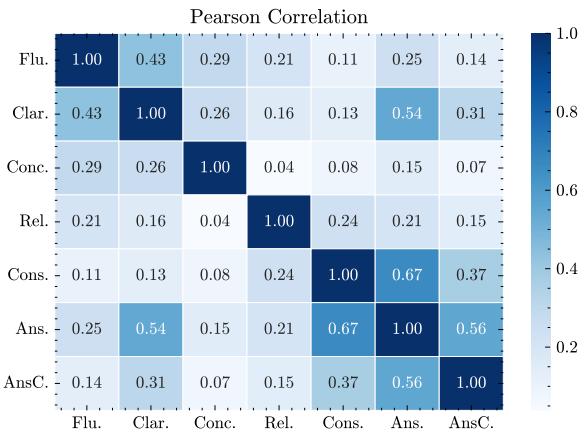
The heatmap above (left) shows the correlation between dimensions.
- Blue indicates correlation. We see moderate correlations, which makes sense (a fluent question is often clearer).
- However, no correlation is near 1.0. This proves that these dimensions are distinct. You can have a fluent question that is completely irrelevant (Fluency high, Relevance low). You can have a relevant question that is grammatically broken (Relevance high, Fluency low).
This confirms that evaluating on just one or two metrics gives an incomplete picture of model performance.
How Do Modern Models Perform?
The researchers used QGEval to score questions generated by the 15 models. The results revealed a fascinating trend in how AI generates questions.
Take a look at the score distributions below. The bars represent the number of questions that received a score of 1 (bad), 2 (okay), or 3 (good).
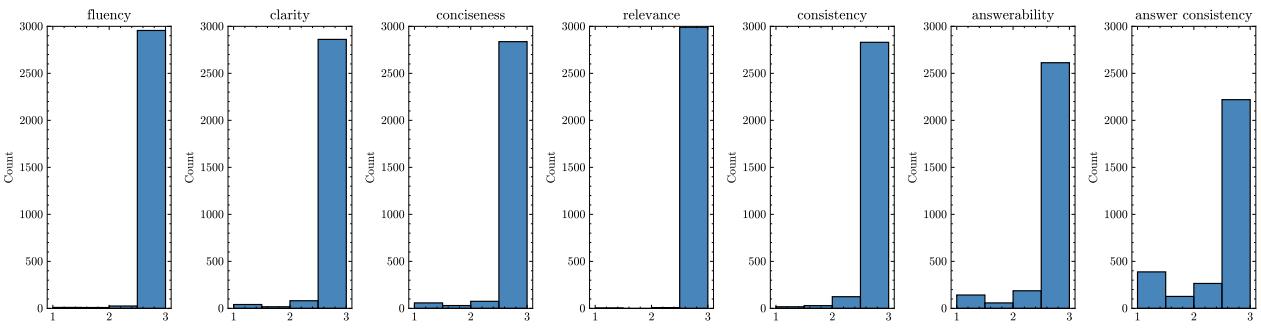
The “Fluent but Dumb” Phenomenon
Notice the charts for Fluency and Relevance. The vast majority of questions are rated 3 (the tall bars on the right). Modern models, even smaller ones, have largely solved the problem of generating grammatically correct English. They know how to write a sentence.
Now, look at Answerability and Answer Consistency. The bars for score 1 and score 2 are much higher here than in other categories.
The findings imply:
- Models Hallucinate: They frequently generate questions that look real but cannot be answered by the text.
- Instruction Following Issues: Models often struggle to generate a question for a specific answer, drifting off to ask about something else entirely.
- GPT-4 is King: In the detailed model breakdown, GPT-4 (few-shot) achieved scores comparable to human references, significantly outperforming smaller fine-tuned models like BART or T5.
The Failure of Automatic Metrics
Perhaps the most damning part of the paper is the analysis of existing automatic evaluation metrics. The researchers compared human scores (the ground truth) against scores from algorithms like BLEU, ROUGE, BERTScore, and newer metrics like QRelScore.
If an automatic metric is good, it should correlate strongly with human judgment.
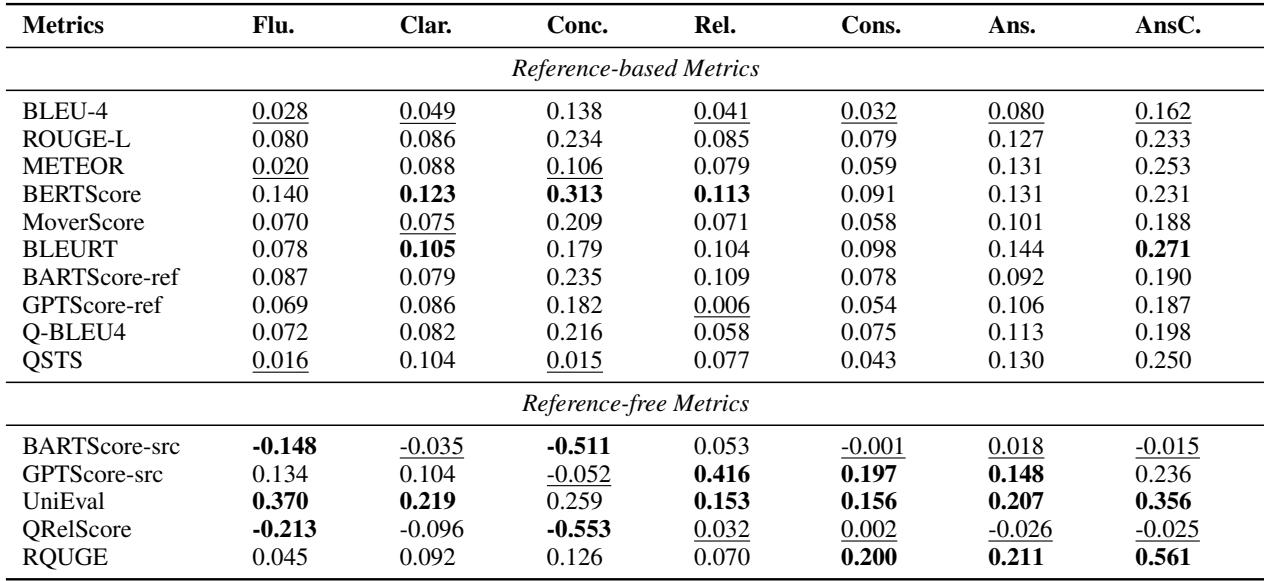
The table above is filled with disappointingly low numbers.
- Reference-based metrics (BLEU, ROUGE): These have near-zero correlation with human judgment on dimensions like Consistency and Clarity. They are essentially random number generators for this task.
- UniEval: This metric performed best, with correlations around 0.37 for Fluency and 0.35 for Answer Consistency. While “best,” a correlation of 0.37 is still weak.
Why Metrics Fail: A Visual Proof
To visualize just how bad this disconnect is, look at the violin plots below. These plots show the spread of automatic metric scores for questions rated 1, 2, and 3 by humans.
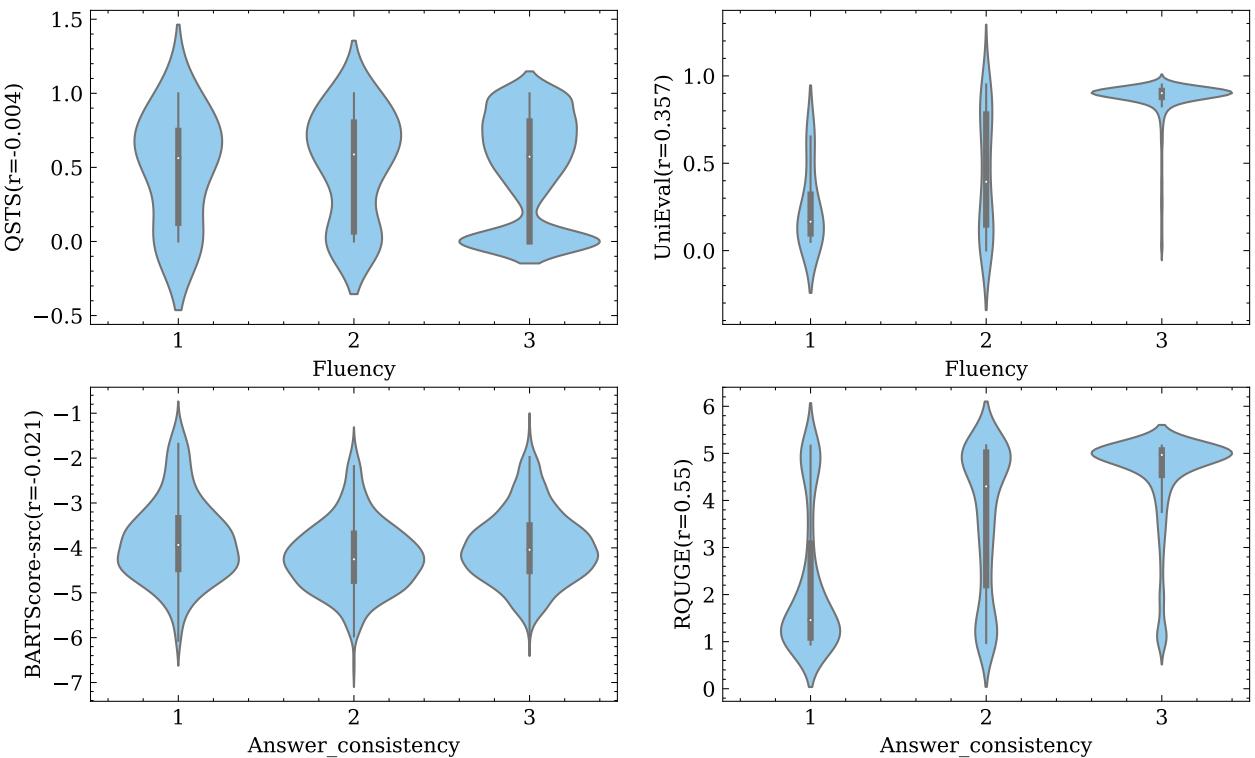
Ideally, you would see a staircase pattern: the distribution for human score “1” should be low, and “3” should be high.
- Look at QSTS (top left): The blobs for scores 1, 2, and 3 look almost identical. The metric cannot distinguish a terrible question from a perfect one.
- Look at RQUGE (bottom right): This metric actually shows some separation for Answer Consistency (the blob moves up as the score goes up), which explains why it had slightly better correlation numbers.
Implications for Students and Researchers
The QGEval paper serves as a reality check for the field of Natural Language Generation.
1. Stop Trusting BLEU
If you are reading a paper that claims their QG model is “State of the Art” solely because it improved the BLEU-4 score by 2 points, be skeptical. As QGEval demonstrates, n-gram overlap has almost no relationship with whether a question is actually answerable or consistent.
2. The Future is “Answerability”
We have solved fluency. Generating smooth text is easy for modern transformers. The frontier of research is now logic and consistency. If you are working on QG, your focus should be on ensuring the model doesn’t hallucinate information outside the passage and strictly adheres to the target answer.
3. LLMs as Evaluators
The paper touches on using GPT-4 as an evaluator (using prompt engineering to ask GPT-4 to grade the questions). While this performed better than traditional metrics, it still didn’t perfectly align with human experts. However, this is the most promising direction for scalable evaluation.
Conclusion
QGEval provides a much-needed framework for the chaotic world of Question Generation evaluation. By breaking down “quality” into seven distinct dimensions, it exposes the specific weaknesses of current models—namely, their tendency to generate fluent but unanswerable questions.
For the field to move forward, we must move beyond counting matching words and start measuring what really matters: can the student actually answer the question?