](https://deep-paper.org/en/paper/2406.05794/images/cover.png)
Retrieval-Augmented Generation (RAG) has become the backbone of modern AI knowledge systems. By combining a parametric memory (the weights of a Large Language Model) with non-parametric memory (an external database of documents), we can build systems that answer questions with up-to-date, specific information.
But anyone who has built a RAG system knows the dirty secret: Retrievers are noisy.
If a user asks a question and the retriever fetches irrelevant documents, the generator (the LLM) is placed in a difficult position. It might try to force an answer from the bad context, leading to hallucinations, or it might ignore the context entirely, leading to answers that lack citation. Standard retrievers provide a similarity score, but this score is relative—it tells you that Document A is better than Document B, but it doesn’t tell you if Document A is actually good.
In this post, we will dive into RE-RAG, a framework proposed by researchers at Seoul National University. RE-RAG introduces a Relevance Estimator (RE)—a module that judges the absolute quality of retrieved contexts. This allows the system to filter out noise, weight answers more accurately, and even decide when to say “I don’t know” or rely on its own internal knowledge.
The Problem with Traditional RAG
To understand why RE-RAG is necessary, let’s look at the standard workflow. In a traditional RAG setup (specifically RAG-Sequence), the process looks like this:
- Retrieve: A user asks a question. A bi-encoder (like DPR) finds the top-\(k\) documents based on vector similarity.
- Score: The system assigns a probability to each document based on that similarity score.
- Generate: The LLM generates an answer for each document.
- Marginalize: The final answer likelihood is calculated by summing up the probabilities, weighted by the document scores.
The mathematical foundation for weighting these documents relies on the similarity score \(S_{i,j}\) (dot product of question and context embeddings).
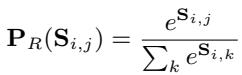
Here, \(P_R\) is the probability assigned to a retrieved document. This probability is then used to weight the generation probability \(P_G\):
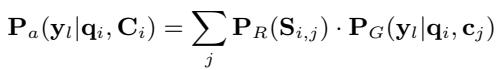
The Flaw: The similarity score \(S_{i,j}\) was trained to rank documents relative to each other (Contrastive Learning). It was not trained to be a calibrated probability of how useful a document actually is for generation. A retriever might return 5 documents that are all irrelevant, but because the softmax function forces them to sum to 1, the model treats the “least bad” document as highly relevant.
This misalignment leads to performance degradation when the query retrieves irrelevant contexts—a very common scenario in open-domain QA.
The Solution: RE-RAG Framework
The authors propose RE-RAG, which inserts a Relevance Estimator (RE) between the retrieval and generation steps. The RE doesn’t just rank; it classifies.
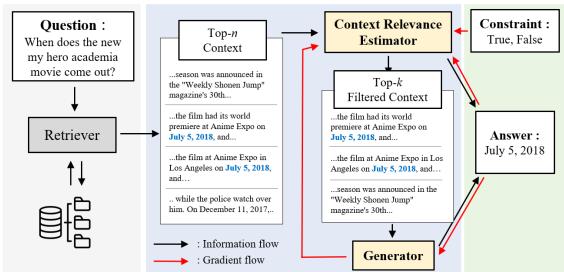
As shown in Figure 1 above, the workflow changes significantly:
- Retriever: Fetches top-\(n\) candidate contexts.
- Context Relevance Estimator: This new module evaluates each context and outputs a confidence score (probability of being “True”).
- Filter & Rerank: The system filters out low-confidence contexts and reranks the remaining ones.
- Generator: The generator synthesizes the answer using only the high-quality, filtered contexts.
1. The Relevance Estimator (RE)
The RE is not a simple binary classifier. It is actually a sequence-to-sequence model (like T5) that takes the question and context as input. However, instead of generating text, it is trained to generate a specific classification token: “true” or “false”.
The brilliance of this approach lies in how they calculate the relevance score. They normalize the probability of the “true” token against the sum of “true” and “false” probabilities.
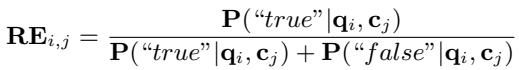
This \(RE_{i,j}\) score represents the confidence that context \(c_j\) is useful for answering question \(q_i\). Unlike vector similarity, which is unbounded and relative, this score is grounded in the semantic understanding of “truth” vs. “falsehood” regarding the query.
2. Integrating RE into Generation
Once the RE provides a score, RE-RAG uses it to improve the final answer generation. The framework replaces the vague retriever similarity scores with these precise RE scores.
First, the RE score is converted into a logit (\(\sigma\)) to make it mathematically compatible with the softmax operation:
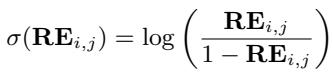
Then, these logits are normalized to create a new probability distribution over the retrieved contexts:
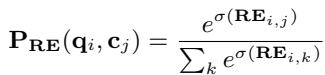
Finally, this calibrated distribution \(P_{RE}\) replaces the old \(P_R\) in the answer marginalization equation. The generator now pays attention to documents strictly in proportion to their actual relevance as determined by the RE.
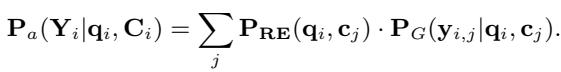
Training Without Labels: Weak Supervision
A major challenge in training a relevance estimator is data. We have datasets of (Question, Answer) pairs, but we rarely have datasets labeled (Question, Context, Is_Context_Relevant?). Annotating thousands of documents for relevance is expensive and slow.
The researchers propose a clever weakly supervised training method. They use the Generator itself to teach the Relevance Estimator.
The Intuition
If a specific context helps the Generator produce the correct ground-truth answer, then that context is likely relevant. If the Generator cannot produce the correct answer given the context, the context is likely irrelevant.
The Method
They define a “proxy” relevance distribution \(Q_G\). This is calculated by checking the log-likelihood of the ground-truth answer (\(a_i\)) given a specific context (\(c_j\)).
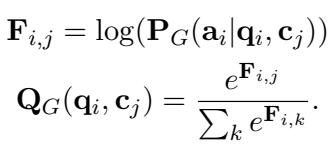
Here, \(F_{i,j}\) measures how easily the generator can write the correct answer using context \(j\). If \(F_{i,j}\) is high, the context is good.
The Relevance Estimator is then trained to match this distribution. The loss function minimizes the KL Divergence between the RE’s predicted relevance (\(P_{RE}\)) and the Generator’s actual performance (\(Q_G\)).
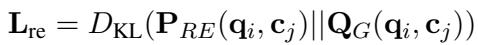
This creates a positive feedback loop:
- The Generator learns to answer questions.
- The RE learns which contexts help the Generator the most.
- The RE down-weights bad contexts, helping the Generator focus on good data.
The total training objective combines the standard generation loss, the RE distillation loss (KL divergence), and a constraint loss to ensure the RE only generates “true” or “false” tokens.
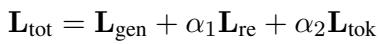
Experimental Results
The researchers tested RE-RAG on two major open-domain QA benchmarks: Natural Questions (NQ) and TriviaQA (TQA). They compared their method against standard RAG, Fusion-in-Decoder (FiD), and various LLM-based approaches.
1. Overall Performance
The results show that adding the Relevance Estimator significantly boosts performance.
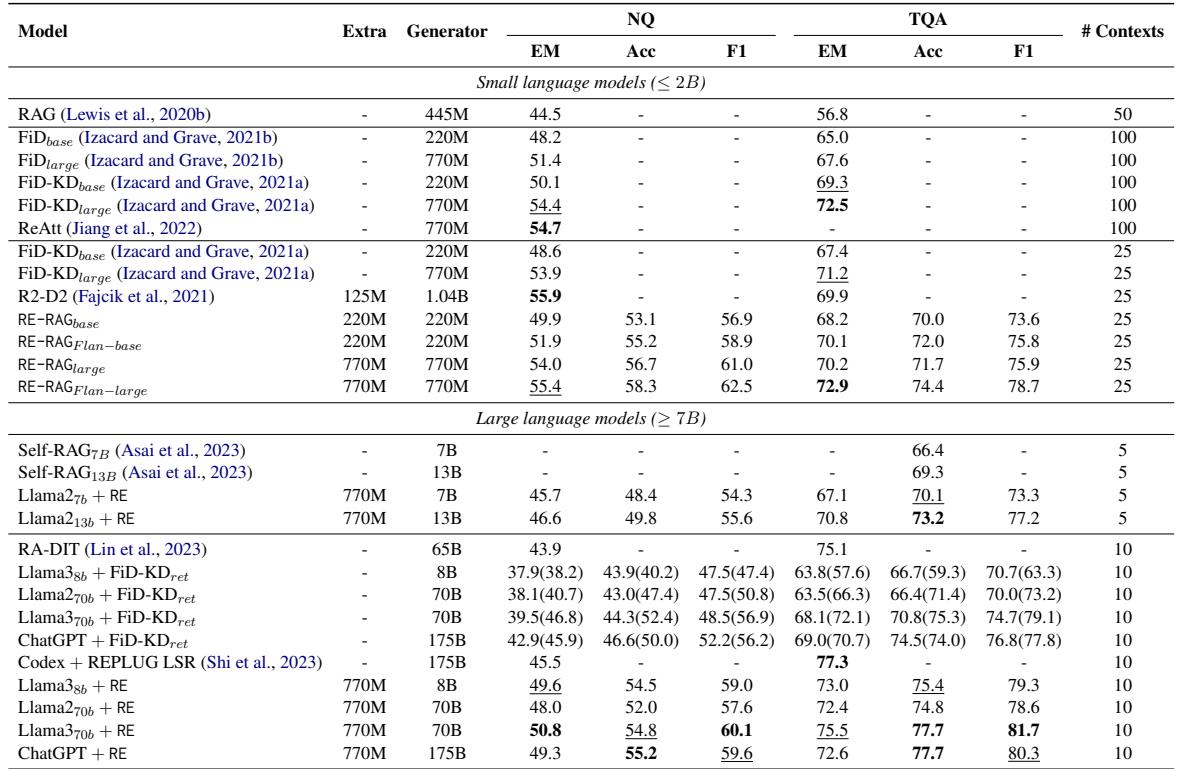
Looking at Table 1, we can see:
- Small Models (≤ 2B): RE-RAG (using T5-Large) achieves 54.0 EM on Natural Questions, outperforming standard RAG (44.5) and even large Fusion-in-Decoder models (51.4).
- Large Models (≥ 7B): When the RE module is applied to Llama-2 (7B/13B) and Llama-3 (8B/70B), it consistently improves performance over standard RAG setups. For example, Llama-3-70B + RE reaches 50.8 EM on NQ, beating the baseline Llama-3-70B + FiD-KD retriever (39.5).
2. RE as a Reranker
Is the RE actually better at sorting documents than the retriever?
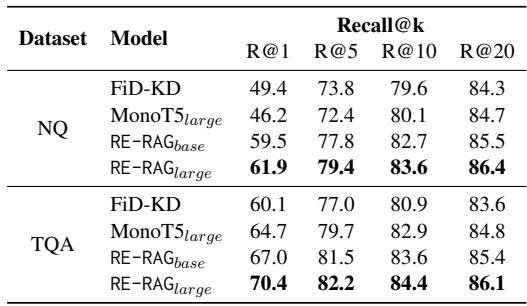
Table 2 confirms this. On Natural Questions (NQ), the RE-RAG (Large) model achieves a Recall@1 of 61.9, compared to just 49.4 for the FiD-KD retriever. This means that for 61.9% of questions, the RE successfully placed a relevant document in the very first position.
3. Ablation Study
To prove that both the reranking (filtering) and the scoring (weighting) are important, the authors performed an ablation study.
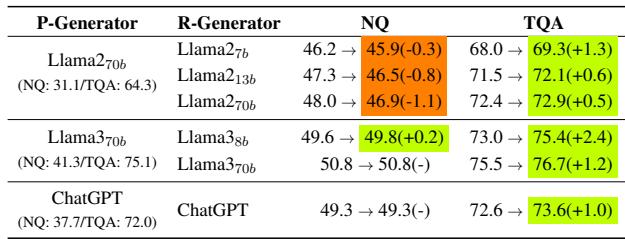
The results in Table 6 are telling:
- Baseline RAG: 39.5 EM.
- With RE Reranking only: 46.8 EM (Huge jump).
- With RE Scoring only: 43.1 EM (Moderate jump).
- With Both: 49.6 EM.
This validates the framework’s design: you need to show the model the right documents and tell the model how much to trust them.
Advanced Decoding: Knowing When to Quit
One of the most exciting implications of RE-RAG is interpretability and confidence. Because the RE outputs a calibrated probability of relevance, we can use it to make decision-time adjustments.
Strategy 1: The “Unanswerable” Threshold
In many real-world applications, a wrong answer is worse than no answer. If the RE assigns a low confidence score to all retrieved contexts, the system can choose to output “Unanswerable.”
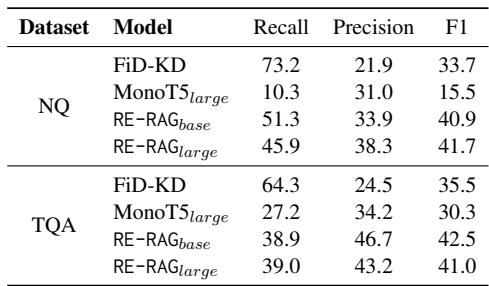
Table 3 shows that the RE is much better at identifying unanswerable scenarios than the retriever. The F1 score for classifying “unanswerable” sets on NQ is 41.7 for RE-RAG, compared to 33.7 for the standard retriever. This precision allows developers to set a threshold where the model remains silent rather than hallucinating.
Strategy 2: Parametric vs. Contextual Knowledge
Large Language Models (like Llama-3-70B) have vast internal (parametric) knowledge. Sometimes, the retrieval actually hurts performance by introducing confusing context for a fact the LLM already knows.
The researchers propose a mixed strategy:
- If RE confidence is high: Use RAG (rely on context).
- If RE confidence is low: Ignore context and let the LLM answer from memory (Parametric).
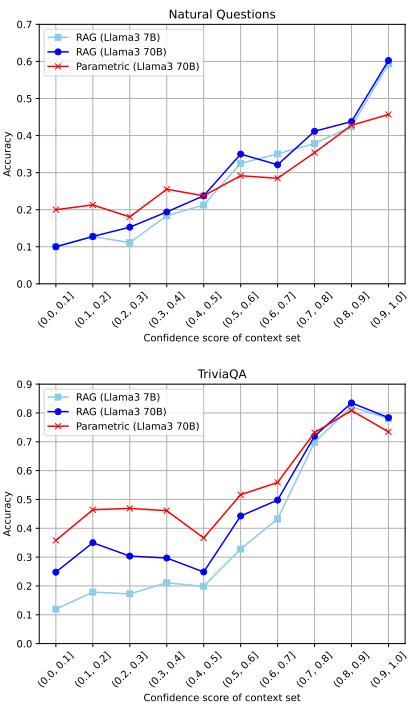
Figure 2 illustrates this dynamic beautifully.
- Top Graph (NQ): Accuracy generally correlates with confidence.
- Bottom Graph (TriviaQA): Look at the right side. When confidence is high, RAG helps. But look at the Llama3 70B (Green vs. Orange lines). The parametric model (Green) is actually quite strong on its own.
- Strategy: By switching to the parametric model when retrieval confidence is low, the authors achieved significant gains, particularly on TriviaQA (see Table 5 in the paper text), boosting Llama-3-8B performance from 73.0 to 75.4.
Generalization to Unseen Data
Finally, a common worry with trained rerankers is overfitting. Does RE-RAG only work on the dataset it was trained on?
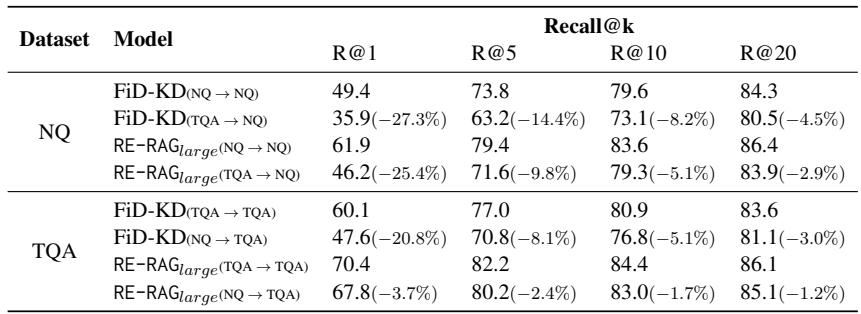
Table 7 shows a cross-dataset evaluation.
- NQ → TQA: When trained on Natural Questions and tested on TriviaQA, the RE module’s performance drops by only 3.7%.
- Comparison: The baseline FiD-KD retriever drops by a massive 20.8% in the same scenario.
This suggests that the Relevance Estimator learns a general concept of “Question-Context Relevance” rather than just memorizing specific dataset patterns.
Conclusion
RE-RAG addresses the fundamental “blind spot” of Retrieval-Augmented Generation: the assumption that retrieved documents are always relevant. By introducing a Relevance Estimator trained via weak supervision, the framework achieves three key wins:
- Higher Accuracy: It explicitly filters noise and weights evidence correctly.
- Modularity: The RE can be trained on a small model (like T5) and successfully guide a massive model (like Llama-3-70B).
- Safety & Control: The confidence scores enable systems to reject bad context or fall back to internal knowledge, reducing hallucinations.
For students and practitioners building RAG pipelines, the takeaway is clear: Retrieval is not enough. To build robust QA systems, we must also implement mechanisms to verify and judge the quality of what we retrieve before we ask our LLMs to generate an answer. RE-RAG offers a scalable, data-efficient blueprint for doing exactly that.