](https://deep-paper.org/en/paper/2406.12168/images/cover.png)
Aligning Large Language Models (LLMs) with human values is one of the most critical challenges in modern AI. We want models that are helpful, harmless, and concise. For a long time, the gold standard for this was Reinforcement Learning from Human Feedback (RLHF). However, if you have ever tried to train an RLHF pipeline, you know the pain: it involves training a separate reward model, dealing with complex reinforcement learning instability, and managing significant computational costs.
Recently, a new family of methods called Direct Alignment from Preferences (DAP)—with Direct Preference Optimization (DPO) being the most famous—has promised to simplify this. By removing the need for a separate reward model, DPO makes alignment much easier.
But there is a catch. Most DPO implementations are offline. They learn from a static, pre-collected dataset. As the model learns, it starts generating text that looks different from that static dataset, and because it stops getting feedback on its new behavior, learning stalls.
This brings us to the research paper we are dissecting today: “BPO: Staying Close to the Behavior LLM Creates Better Online LLM Alignment.” The researchers propose a novel method called BPO (Behavior Preference Optimization). They argue that to truly fix alignment, we must not only move from offline to online learning but also fundamentally change how the model constrains itself during training.
In this post, we will walk through the limitations of current alignment methods, the mathematical intuition behind BPO, and how this new approach manages to outperform state-of-the-art methods even when using a fraction of the annotation budget.
The Background: RLHF and the Rise of DAP
To understand BPO, we first need to understand the “trust region” problem in LLM alignment.
Traditional RLHF
In standard RLHF (like PPO), we train a model to maximize a reward score. However, we can’t let the model simply hack the reward function by outputting gibberish that happens to score high. We need a constraint. We force the trained model (\(\pi_{\theta}\)) to stay close to the original reference model (\(\pi_{ref}\)), usually the Supervised Fine-Tuned (SFT) model.
The objective looks like this:
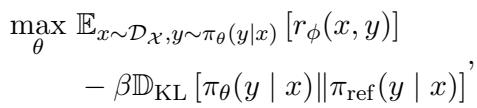
The term \(\beta \mathbb{D}_{\text{KL}}\) is the KL Divergence. Think of it as a “leash.” It prevents the new model from wandering too far from the reference model.
Direct Alignment from Preferences (DAP)
Methods like DPO, IPO, and SLiC are clever because they mathematically rearrange the RLHF objective. They allow us to optimize the model directly on preference pairs (Winning Response \(y_w\) vs. Losing Response \(y_l\)) without explicitly training a Reward Model first.
Here are the loss functions for these popular DAP methods:

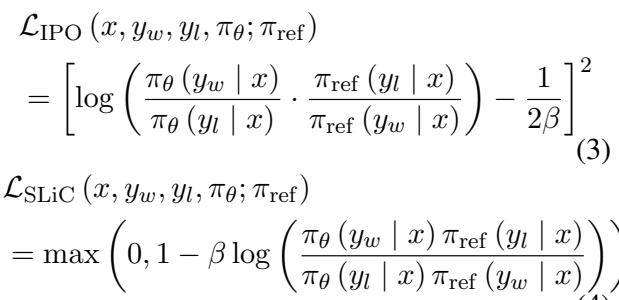
Notice a common pattern in all these equations? They all rely on \(\pi_{ref}\). In almost every standard implementation, \(\pi_{ref}\) is fixed. It is the static, initial SFT model you started with.
The Problem: Offline vs. Online
In Offline DAP, you collect a dataset once and train on it. The problem is distribution shift. As your model improves, it starts generating responses that are very different from the initial dataset. Since the model never gets feedback on these new, unique responses, it stops improving effectively.
Online DAP tries to fix this by collecting new human (or AI) feedback on the model’s current outputs during training. This sounds great, but the authors of this paper identified a critical flaw in how current online methods work.
Even when other researchers switched to Online DAP, they kept the “leash” tied to the old, static SFT model (\(\pi_{ref} = \pi_{SFT}\)). The authors argue that this is suboptimal. If your model has evolved significantly, constraining it to a model from weeks ago doesn’t make sense.
The Core Method: BPO (Behavior Preference Optimization)
The core insight of BPO is simple yet profound: The Trust Region should be constructed around the Behavior LLM (\(\pi_{\beta}\)), not the static Reference LLM.
What is the Behavior LLM?
The Behavior LLM (\(\pi_{\beta}\)) is the specific version of the model that generated the data you are currently training on.
In an offline setting, the Behavior LLM is the SFT model, because that’s what generated the dataset. But in an online setting, where you generate new data every few steps, the Behavior LLM is the model as it existed at that moment.
The BPO Algorithm
The researchers propose that instead of tying the model to a static past, we should update the reference model dynamically.
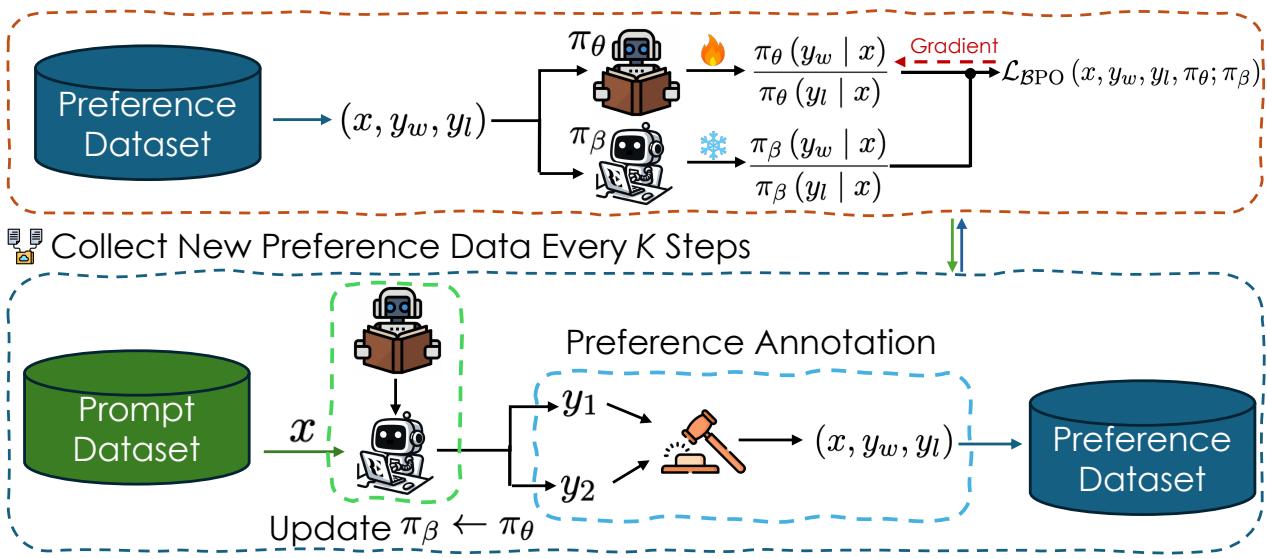
As shown in Figure 2 above, the pipeline works as follows:
- Prompt Dataset: You start with a set of prompts (\(x\)).
- Generation: The current policy generates pairs of responses (\(y_1, y_2\)).
- Annotation: A human (or AI judge) picks the winner (\(y_w\)) and loser (\(y_l\)).
- Update \(\pi_{\beta}\): Crucially, every \(K\) steps, the reference model \(\pi_{\beta}\) is updated to match the current learner \(\pi_{\theta}\).
- Optimization: The model is trained to minimize the BPO loss.
The BPO loss function is a modification of standard DAP losses, but with the reference model swapped for the behavior model:
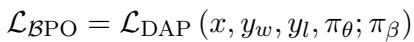
By setting \(\pi_{ref} = \pi_{\beta}\), the “leash” moves along with the model. This ensures that the trust region is always relevant to the current state of the model’s exploration.
Stabilizing the Training
There is a reason people use static reference models: moving targets are unstable. If you constantly change the reference point, the training can collapse or oscillate.
The authors found that updating the reference model aggressively caused instability when using standard training techniques. To solve this, they employed Ensemble LoRA (Low-Rank Adaptation).
Instead of training one set of weights, they optimize an ensemble of LoRA adapters. This acts as a regularization technique, smoothing out the learning process.
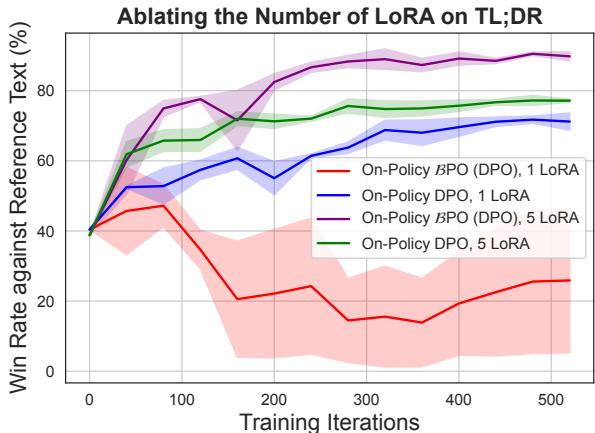
As seen in Figure 6, training with a single LoRA (Red line) results in a low win rate that fails to improve. However, utilizing an ensemble of 5 LoRA weights (Purple line) stabilizes the training, allowing BPO to reach high performance.
Experiments and Results
The researchers tested BPO against standard Offline DPO and standard Online DPO (where the reference model stays static). They used three major datasets:
- TL;DR: Summarizing Reddit posts.
- Anthropic Helpfulness: Answering user questions.
- Anthropic Harmlessness: Refusing harmful instructions.
1. BPO Beats the Baselines
The primary metric used was “Win Rate against Reference Text.” This measures how often the model’s output was preferred over the human-written reference answer.

Figure 3 shows the aggregate results. Whether looking at the Median, Interquartile Mean (IQM), or Mean, On-Policy BPO (Green) consistently outperforms both Offline DAP (Blue) and standard On-Policy DAP (Orange).
The improvement is not trivial. On the TL;DR summarization task, BPO improved the win rate from roughly 77% (standard Online DPO) to 89.5%.
2. Efficiency: The “Budget” Question
One of the biggest criticisms of Online Learning is the cost. Sending data to human annotators every single training step (\(F=T\)) is slow and expensive.
The researchers asked: Can we get the benefits of BPO without constantly annotating new data?
They experimented with the Frequency (\(F\)) of data collection. \(F=1\) is offline (collect once). \(F=T\) is fully on-policy (collect every step).

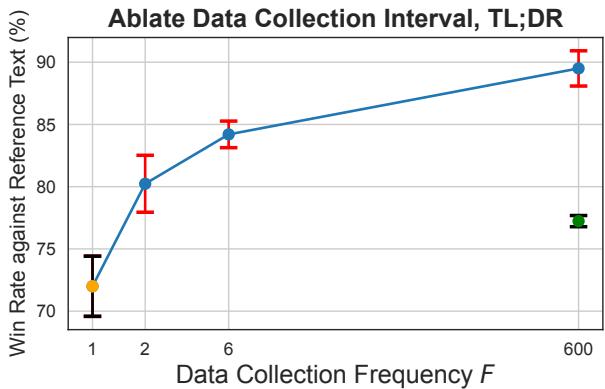
Figure 1 and Figure 4 reveal a stunning result. Look at the blue line in Figure 1. Even at F=2—meaning only one additional phase of data collection and annotation after the initial batch—BPO significantly outperforms the offline baseline.
In fact, BPO at \(F=2\) performs comparably to standard On-Policy DPO at \(F=T\). This implies that by simply using the correct reference model (the behavior model), you can achieve state-of-the-art alignment results with a fraction of the annotation cost required by traditional online methods.
3. Is it just a better reference model?
A skeptic might ask: “Is BPO better just because the reference model \(\pi_{\beta}\) is higher quality than the initial \(\pi_{SFT}\)?”
To test this, the authors ran an ablation study. They took a “Golden” model (a fully trained, high-quality model) and used that as the static reference for standard DPO.
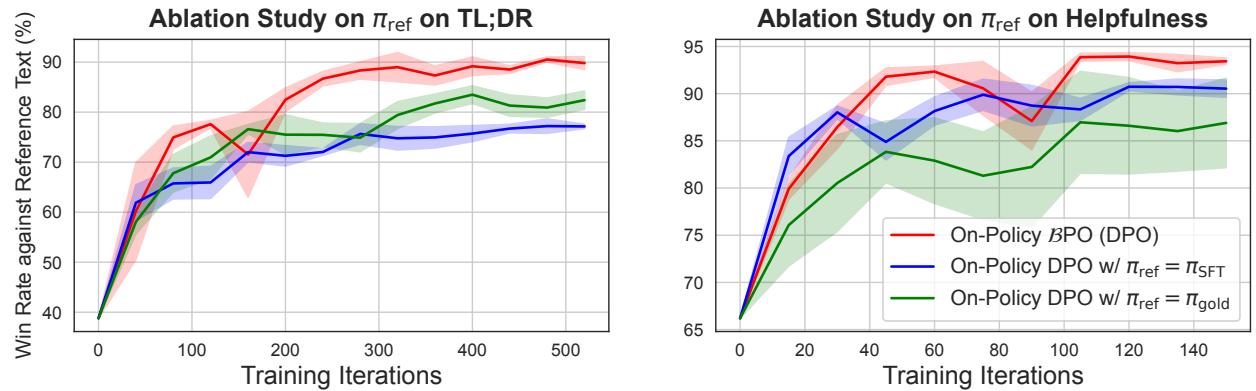
Figure 5 shows the result. The Red line (BPO) still beats the Green line (DPO with Golden Reference).
This proves that the magic isn’t just having a “good” reference model. The magic lies in the proximity constraint. The model learns best when it is constrained to the specific policy that generated the data it is currently learning from.
Conclusion
The paper “BPO: Staying Close to the Behavior LLM Creates Better Online LLM Alignment” provides a significant correction to how we think about aligning AI models.
For a long time, researchers treated the reference model as a static anchor—a safety mechanism to prevent the model from forgetting its training. BPO demonstrates that in the dynamic world of online learning, this anchor needs to move. By tying the trust region to the behavior policy (the model as it exists now), we allow the LLM to learn more effectively from its own experiences.
Key Takeaways:
- Online > Offline: Learning from fresh data generated by the model is superior to static datasets.
- Move the Anchor: When doing online learning, set your reference model to be the behavior model (\(\pi_{ref} = \pi_{\beta}\)).
- Efficiency: You don’t need continuous annotation. Just one or two updates to the behavior model (\(F=2\)) can yield massive gains.
- Stability Matters: Techniques like LoRA ensembles are necessary to keep this dynamic training process stable.
As we move toward more autonomous AI agents that learn from interaction, methods like BPO will likely become the standard, replacing the static, offline pipelines of the past. It turns out, to make an AI better, you have to let it stay close to its own behavior.