](https://deep-paper.org/en/paper/2406.14979/images/cover.png)
Introduction
Imagine you are asked to write a detailed essay on the biology of jellyfish. You have a stack of textbooks next to you. A novice approach would be to open a book, read a random paragraph, write a sentence, read another random paragraph, and write another sentence. The result? A disjointed mess that might start talking about jellyfish anatomy and end up describing the history of oceanography just because it appeared on the same page.
This is, unfortunately, how many Large Language Models (LLMs) operate when using standard Retrieval-Augmented Generation (RAG). They retrieve documents related to a query and try to generate an answer based on everything they found. The problem is that retrieved documents are often noisy; they contain relevant facts buried alongside irrelevant details. This noise can cause the LLM to lose focus, leading to “focus shift,” where the model drifts off-topic or hallucinates.
In this post, we are diving deep into a new framework called Retrieve-Plan-Generation (RPG). This research proposes a solution that mimics how a human expert writes: by planning what to say before saying it. We will explore how RPG introduces an iterative “Plan-then-Answer” loop to keep LLMs strictly on topic, and how the researchers implemented this efficiently using multi-task prompt tuning.
The Problem: When RAG Gets Distracted
To understand the innovation of RPG, we first need to look at the limitations of standard RAG.
In a typical RAG setup, when a user asks a question, the system searches a database for relevant documents. It concatenates these documents with the user’s query and feeds the whole giant block of text into the LLM. The LLM is then expected to ignore the noise and generate a perfect answer.
However, research shows that off-topic paragraphs in retrieved documents can be detrimental. Because LLMs generate text token-by-token based on probability, “noisy” input increases the uncertainty of the generation. If a retrieved document about jellyfish mentions a specific scientist, the LLM might latch onto that scientist’s biography instead of explaining the jellyfish’s nervous system. The longer the text generation continues, the more likely the model is to deviate from the original question.
The RPG framework argues that the susceptibility of LLMs to irrelevant content stems from a lack of explicit pre-planning.
The Core Method: The RPG Framework
The Retrieve-Plan-Generation (RPG) framework fundamentally changes the generation process by breaking it down into two distinct, alternating stages: the Plan Stage and the Answer Stage.
Instead of trying to ingest a document and write an essay in one breath, RPG iterates through these stages until the answer is complete.
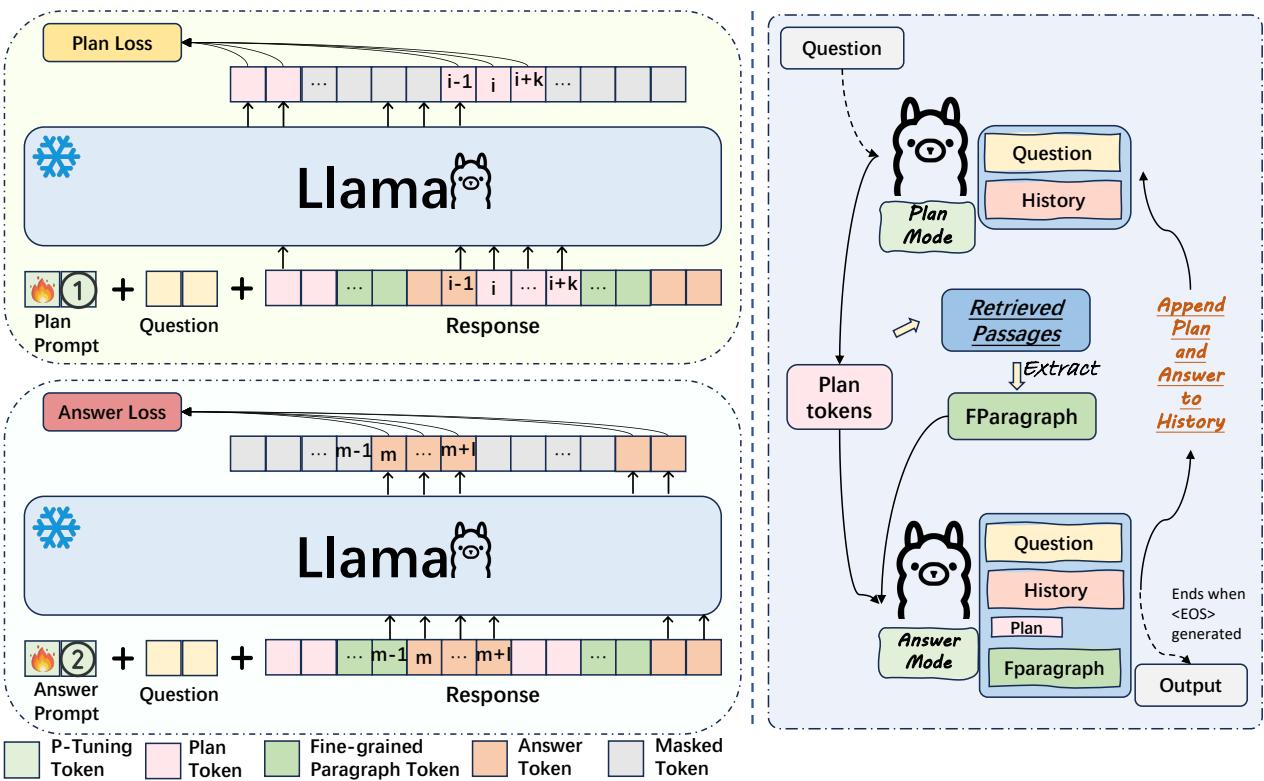
As illustrated in Figure 2 above, the process works as follows during inference (the right side of the diagram):
- The Plan Stage: The model assesses the current context and generates “plan tokens.” These aren’t part of the final answer shown to the user; they are internal guides representing the specific sub-topic the model intends to address next (e.g., “Body composition of jellyfish”).
- The Answer Stage:
- Fine-Grained Selection: Based on the generated plan, the system scans the retrieved documents. It filters out irrelevant noise and selects only the specific paragraphs or sentences that support the current plan.
- Generation: The model generates a segment of the answer using only that highly relevant evidence.
- Iteration: The generated text is added to the history, and the model loops back to the Plan Stage to decide what to write next.
This cycle continues until the model determines the answer is complete. By constantly re-grounding itself with a new plan, the model effectively “resets” its focus, preventing the long-term drift that plagues standard RAG systems.
Building the Dataset: Teaching a Model to Plan
One of the biggest hurdles in implementing RPG is that standard datasets don’t come with “plans.” They usually just have a Question (Q) and an Answer (A). To train a model to plan, the researchers had to reverse-engineer a dataset.
They utilized ChatGPT to process existing datasets like HotpotQA and Self-RAG. The goal was to split existing long answers into segments and determine what the “plan” or “intent” was for each segment.

Figure 3 demonstrates this data construction process:
- Plan Generation: For a specific segment of an answer, ChatGPT is prompted to summarize the intent. This summary becomes the label for the Plan Stage.
- Fine-Grained Evidence: ChatGPT is then given the plan and the original coarse documents. It is asked to select only the specific sentences relevant to that plan. This creates the training data for the Answer Stage.
This resulted in a high-quality dataset of 50,000 examples where every answer segment is paired with a specific plan and specific evidence.
Efficient Training: Multi-Task Prompt Tuning
Training a massive LLM (like Llama-2 70B) from scratch to handle this complex workflow is computationally expensive. The researchers needed a way to teach the model two distinct skills—planning and answering—without retraining the entire network.
Their solution? Multi-Task Prompt Tuning.
Instead of updating the weights of the LLM itself, they freeze the LLM and only train a small set of “prompt vectors” that are prepended to the input. Think of these as learnable instructions that tell the model which “mode” to be in.
They utilize a shared soft prompt (\(P^*\)) that contains general knowledge, and two task-specific low-rank matrices (\(W_{plan}\) and \(W_{ans}\)) that transform the shared prompt into a specialized one.
The mathematical formulation for generating a task-specific prompt (\(P_{task}\)) is:
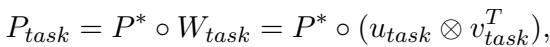
Here, \(task\) is either “plan” or “ans” (answer). By learning these lightweight matrices, the model can switch between being a “Planner” and an “Answerer” instantly.
The Loss Functions
During training, the model looks at the same data sample but learns different things depending on which “mode” it is in. The researchers use a masking strategy so the model focuses only on the relevant tokens for the current task.
Plan Loss: When training the planner, the model ignores the answer text and calculates loss only on the generated plan tokens.
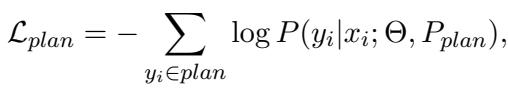
Answer Loss: When training the answerer, the model calculates loss only on the answer tokens, given the plan and the context.
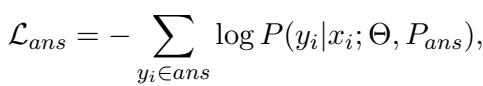
This multi-task approach allows the model to become proficient at both distinctly different tasks simultaneously, using the same underlying frozen LLM.
Experiments and Results
The researchers evaluated RPG on 5 knowledge-intensive tasks, categorizing them into long-form generation (like writing detailed explanations), multi-hop QA (reasoning across documents), and short-form QA.
They compared RPG against several strong baselines:
- Standard RAG: The basic retrieve-and-generate approach.
- Self-RAG: A state-of-the-art method that uses reflection tokens to critique its own generation.
- ChatGPT: Both with and without retrieval.
Long-Form Generation Performance
Long-form generation is the primary battlefield for RPG, as this is where “focus shift” and hallucination are most prevalent. The results were impressive.
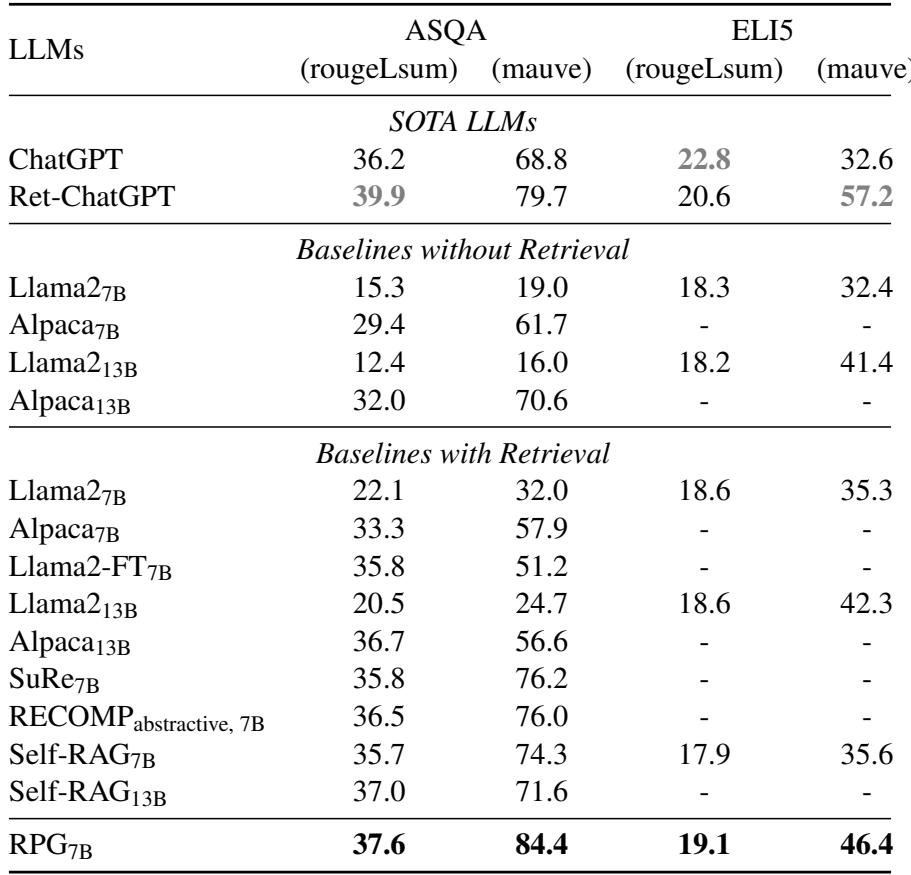
As shown in Table 1, RPG significantly outperforms standard Llama-2 baselines and even surpasses the previous state-of-the-art, Self-RAG, on datasets like ASQA and ELI5.
- ASQA (Ambiguous Questions): RPG achieves a win in factual correctness (RougeL) and fluency (Mauve).
- Comparison to Summarization Methods: Baselines like “SuRe” and “RECOMP” try to summarize retrieved docs once before answering. RPG outperforms them, proving that iterative planning (planning step-by-step) is superior to doing it all at once.
Multi-Hop and Short-Form Performance
While RPG was designed for long answers, the researchers wanted to see if the overhead of planning helped with shorter, more precise questions.
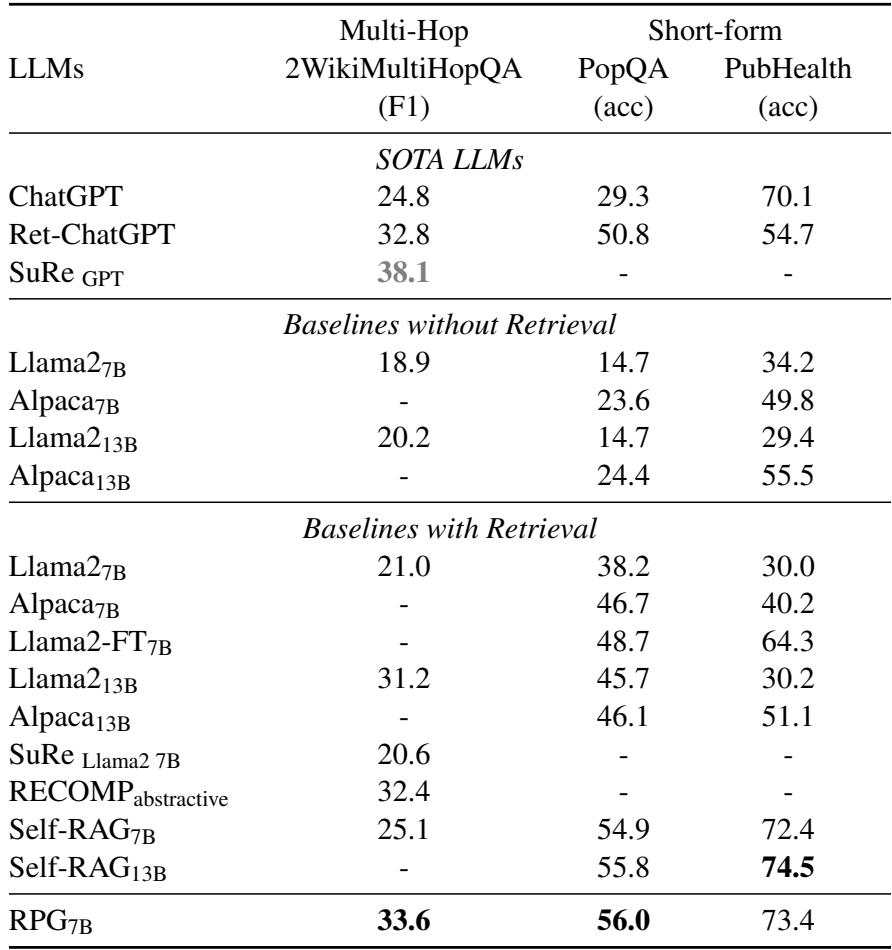
Table 2 highlights that RPG also excels in multi-hop reasoning (2WikiMultiHopQA). This makes sense: multi-hop questions require connecting dot A to dot B. The “Plan” stage effectively acts as the bridge, explicitly stating “First I need to find X, then I need to find Y.”
Interestingly, even in short-form QA (PopQA), where answers are brief, RPG shows strong performance by effectively filtering out irrelevant noise from the retrieved documents.
Why does it work? (Ablation Studies)
To ensure the performance wasn’t a fluke, the researchers broke the model apart (ablation study) to see which components mattered most.
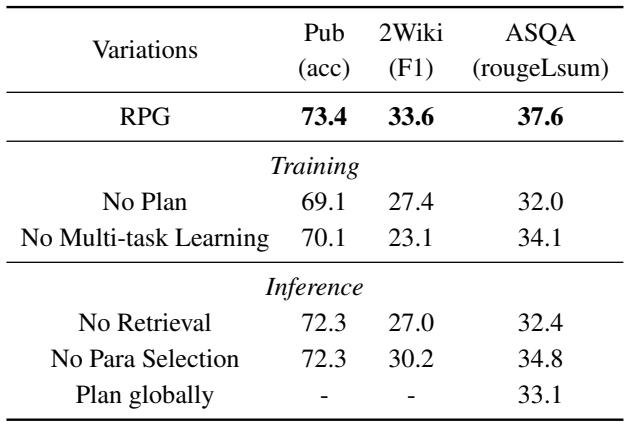
Table 3 reveals crucial insights:
- No Plan (Training): If you remove the planning phase from the training data, performance drops significantly (e.g., ASQA score drops from 37.6 to 32.0). This confirms that the explicit planning step is the primary driver of quality.
- No Para Selection (Inference): If the model generates a plan but is forced to read the entire retrieved document (rather than selecting fine-grained paragraphs), performance also drops. This validates the theory that “noise” in documents hurts LLM performance.
- Iterative vs. Global Planning: The researchers also tested “Plan globally,” where the model generates a massive plan for the whole essay at the very beginning. The results showed that the iterative approach (plan a little, write a little) is superior. It allows the model to adapt as it writes.
Scaling Up
Finally, does the size of the training set matter?
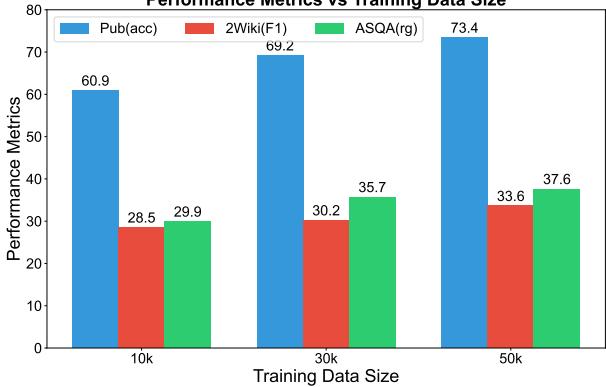
Figure 4 shows a clear upward trend. As the model is trained on more data (from 10k up to 50k samples), its performance on all metrics improves. This suggests that the RPG framework has not yet hit a ceiling; with more data, it could become even more accurate.
Conclusion
The Retrieve-Plan-Generation (RPG) framework offers a compelling solution to the “wandering mind” of Large Language Models. By forcing the model to stop, plan, and select specific evidence before generating every section of text, RPG effectively reduces hallucinations and keeps answers strictly on-topic.
What makes this research particularly valuable for students and practitioners is its efficiency. It doesn’t require retraining a massive foundation model. Through the clever use of multi-task prompt tuning, existing LLMs can be retrofitted with this planning capability, making high-quality, trustworthy generation more accessible.
The key takeaway? When dealing with complex knowledge, don’t just ask an LLM to “read and write.” Teach it to plan. The difference in clarity and accuracy is substantial.