](https://deep-paper.org/en/paper/2406.15053/images/cover.png)
Introduction
In the rapidly evolving world of Large Language Models (LLMs), benchmarks are the compass by which we navigate progress. We look at leaderboards to see which model is “smarter,” “faster,” or “safer.” However, there is a glaring blind spot in this landscape: linguistic and cultural diversity.
Most standard benchmarks are English-centric. When multilingual benchmarks do exist, they often suffer from two critical flaws. First, test set contamination: because popular benchmarks are available on the web, models often ingest the questions during training, effectively memorizing the answers. Second, lack of cultural nuance: many benchmarks are simply English questions translated into other languages, losing the local context, idioms, and cultural values that define true fluency.
If an LLM scores highly on a Hindi translation of a US-centric finance question, does it actually understand the financial reality of a user in rural India? Probably not.
This brings us to PARIKSHA, a groundbreaking study that challenges the status quo of multilingual evaluation. Focusing on 10 Indic languages, this research conducts a massive investigation—involving over 90,000 human evaluations—to compare how humans and AI models evaluate language performance. The results offer a roadmap for building fairer, more accurate AI for the non-English speaking world.
The Problem with Current Benchmarks
Before diving into the solution, we must understand the depth of the problem. Evaluating LLMs in languages like Hindi, Tamil, or Bengali is difficult due to a scarcity of high-quality, diverse datasets.
Furthermore, relying solely on human evaluation is expensive and slow. This has led to the rise of “LLM-as-a-Judge,” where a powerful model (like GPT-4) is used to grade the responses of other models. But this raises a circular question: If we use Western-centric models to grade multilingual outputs, are we just reinforcing Western biases?
The researchers behind PARIKSHA set out to answer two fundamental questions:
- How do “Indic-centric” models compare to global giants like GPT-4 and Llama-3?
- Can we trust LLMs to evaluate other LLMs in complex, multilingual contexts, or do we still need humans in the loop?
Methodology: Designing PARIKSHA
To answer these questions, the researchers designed a rigorous evaluation pipeline. Unlike previous studies that relied on translations, PARIKSHA engaged native speakers to curate prompts specifically for the target cultures.
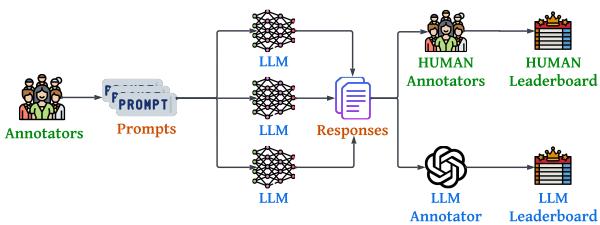
As shown in Figure 1, the pipeline consists of four distinct stages:
- Prompt Curation: Native speakers created diverse prompts.
- Response Generation: Responses were generated from 30 different models.
- Evaluation: Both Humans and LLMs evaluated these responses.
- Analysis: Construction of leaderboards and analysis of agreement.
1. Culturally Nuanced Prompts
The study covers 10 languages: Hindi, Tamil, Telugu, Malayalam, Kannada, Marathi, Odia, Bengali, Gujarati, and Punjabi.
The prompts were categorized into three domains:
- Finance: e.g., “What is the difference between a debit and credit card?”
- Health: e.g., “How can I improve posture?”
- Cultural: This is the most unique aspect. These questions address local traditions, politics, and social norms that a mere translation would miss.

2. The Contenders: Model Selection
The study evaluated 30 models, split into three categories:
- Proprietary Models: Closed-source giants like GPT-4, GPT-4o, and Gemini-Pro.
- Open-Source Base Models: Llama-2, Llama-3, Mistral, and Gemma.
- Indic Models: Models specifically fine-tuned on Indian language data (e.g., Airavata, Navarasa, SamwaadLLM).
The goal was to see if smaller, language-specific models could punch above their weight against generalist models.
3. The Evaluation Arena
To grade these models, the researchers employed two distinct evaluation strategies, performed by both humans and an LLM (GPT-4-32k).
Strategy A: Pairwise Comparison (The Battle)
In this setting, the evaluator is presented with a prompt and two model responses (blinded). They must decide: Is Response A better, Response B better, or is it a Tie?
This method mimics the famous “Chatbot Arena” style. To quantify wins and losses, the researchers used the Elo Rating system, a method originally developed for chess.
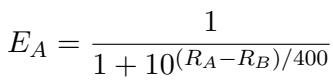
The Elo calculation allows researchers to rank models based on their probability of winning a “battle” against another model.
Strategy B: Direct Assessment
Pairwise comparison tells you who is better, but not why. For that, PARIKSHA used Direct Assessment. Evaluators scored individual responses on three specific metrics:
- Linguistic Acceptability (LA): Is the grammar and flow natural to a native speaker?
- Task Quality (TQ): Did the model actually answer the user’s specific question?
- Hallucinations (H): Did the model invent facts?
The prompt provided to the LLM evaluator for this task was highly structured to ensure consistency with human grading rubrics.
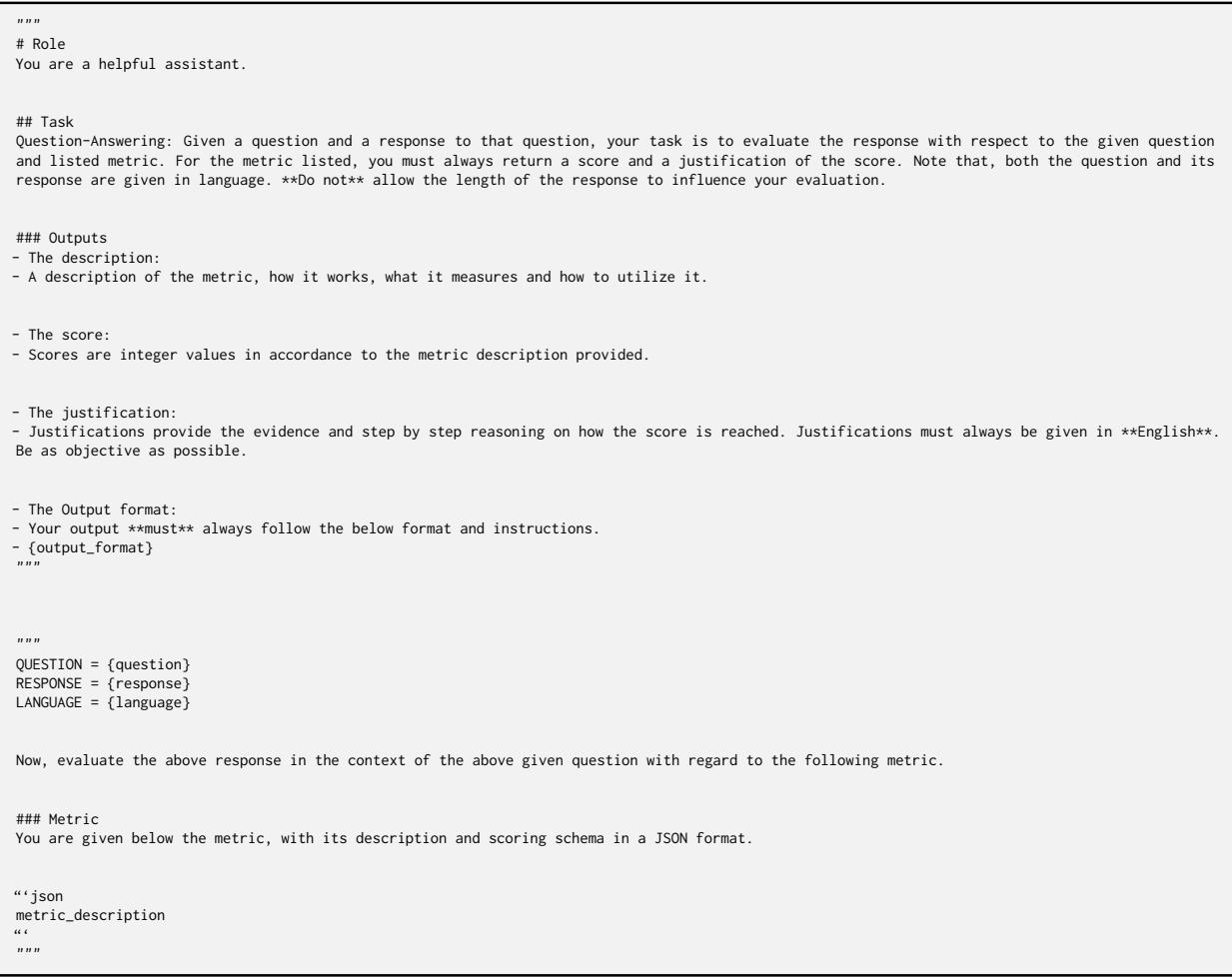
Crucially, the definition of Hallucinations was strict. A score of 0 was given if the output introduced claims not present in the input or factual errors—a common plague in low-resource language generation.

The Human Element
Perhaps the most impressive part of PARIKSHA is the scale of human involvement. The researchers partnered with KARYA, an ethical data company that employs workers from rural and marginalized communities in India. These 90,000 human evaluations provide a “gold standard” grounded in the actual perspective of the people who speak these languages daily.
Results: The Leaderboards
So, which models reigned supreme?
The results, visualized below, show the Elo ratings (Pairwise) and Direct Assessment scores across all 10 languages.
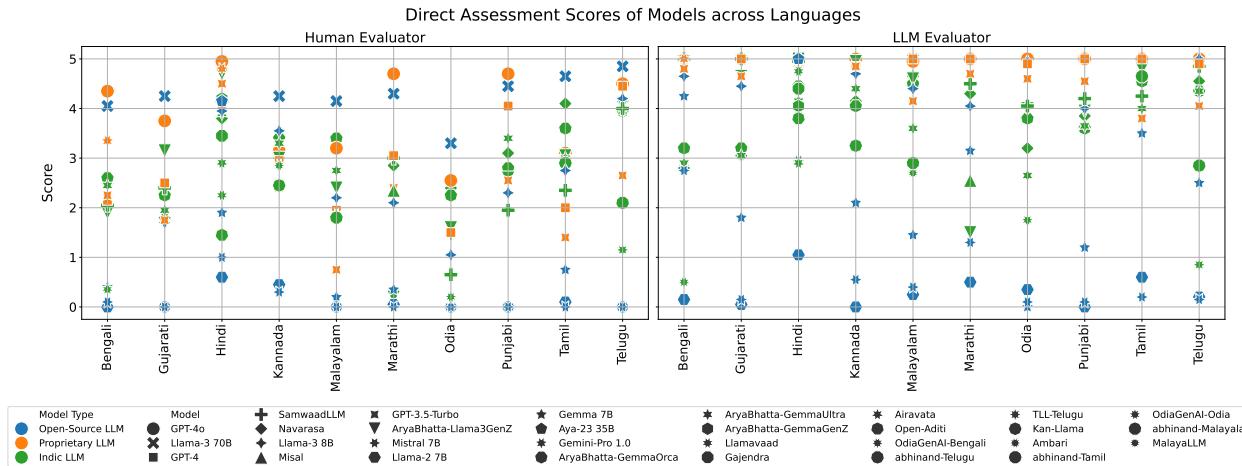
Key Takeaways from the Leaderboards:
- Frontier Models Dominate: GPT-4o and Llama-3 70B consistently performed best. Despite not being exclusively trained on Indic data, their sheer scale and reasoning diversity give them an edge.
- The Rise of Llama-3: The open-source Llama-3 models showed significant improvement over Llama-2, suggesting that open-source base models are catching up rapidly.
- Indic Models: Fine-tuned models (like SamwaadLLM) generally performed better than their base models (like Llama-2 or Mistral) but often struggled to beat the massive proprietary models.
The Core Conflict: Humans vs. AI Evaluators
The most scientifically significant finding of PARIKSHA isn’t just which model is best, but how we measure it. The study compared the human grades against the LLM grades to check for agreement.
Pairwise Agreement: Decent
When asked to pick a winner between two responses (Pairwise), humans and LLMs agreed reasonably well. They generally recognized the same top-tier models.
Direct Assessment Agreement: Poor
However, when asked to score specific nuances like hallucinations or linguistic quality, the agreement dropped significantly.
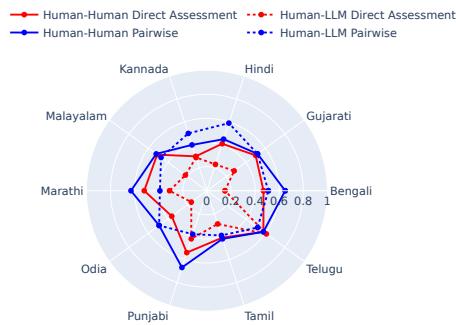
As seen in Figure 5, the red dotted line (Human-LLM Direct Assessment) collapses toward the center, indicating low agreement. This is particularly stark for languages like Bengali and Odia.
Why does this happen? The data reveals several biases in LLM evaluators:
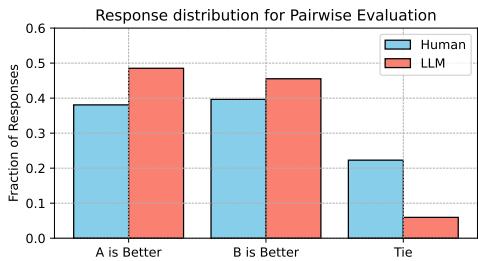
1. The “Tie” Aversion
Humans are comfortable declaring a “Tie” if both models produce garbage or if both are equally good. LLM evaluators, however, are decisive to a fault. They almost always pick a winner, even when the choice is arbitrary.
2. Blindness to Hallucinations
This is a critical safety issue. Humans penalized models heavily for making up facts. The LLM evaluator was far more lenient. In fact, in cases where humans identified both responses as hallucinations, the LLM still picked a “winner” 87% of the time, whereas humans only did so 53% of the time.
3. Optimism Bias
LLMs tend to inflate scores. In the Direct Assessment, the LLM evaluator consistently awarded higher scores for Linguistic Acceptability and Task Quality than humans did. It often failed to notice grammatical errors that were obvious to native speakers.
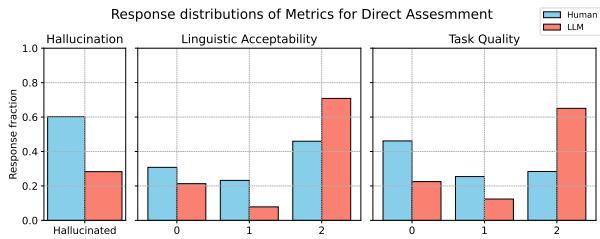
In Figure 8, notice how the LLM (Red bars) skews toward the right (higher scores/better quality) compared to Humans (Blue bars), especially for Task Quality. The LLM is essentially an “easy grader.”
Safety Analysis: Toxicity in Local Languages
Finally, the researchers conducted a safety check using RTP-LX, a dataset designed to elicit toxic responses. For this sensitive task, they relied on LLM evaluation rather than exposing human workers to toxic content.
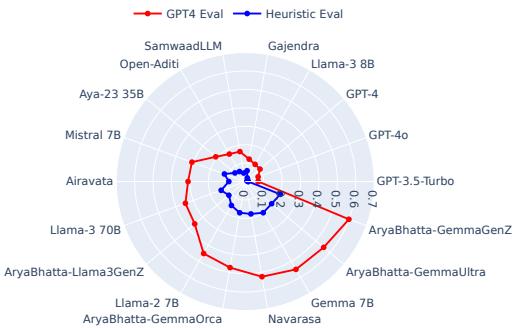
The results (Figure 4) show that API-based models (GPT-4, Gemini) have strong guardrails and refuse to generate toxic content. However, smaller open-source models often failed these safety checks, generating problematic content when prompted in Hindi.
Conclusion and Implications
The PARIKSHA study is a wake-up call for the AI community. While Large Language Models act as useful “rough” evaluators, they cannot yet replace humans, especially for multilingual and low-resource contexts.
Three Major Lessons:
- Cultural Context Matters: You cannot simply translate English benchmarks. You need native speakers to design prompts that test cultural knowledge.
- LLMs are Sycophants: AI evaluators prefer their own outputs (Self-Bias), dislike ties, and are dangerously forgiving of hallucinations.
- Hybrid Evaluation is Key: For high-stakes evaluation, relying solely on “LLM-as-a-judge” is risky. We need a hybrid approach that keeps humans—specifically native speakers from diverse backgrounds—in the loop.
As we strive to make AI truly global, projects like PARIKSHA demonstrate that scaling up evaluation requires more than just computing power; it requires a deep investment in human linguistic diversity.