](https://deep-paper.org/en/paper/2406.15718/images/cover.png)
Have you ever tried to interrupt a voice assistant? It usually goes something like this: you ask a question, realize you made a mistake mid-sentence, but the AI ignores your correction and continues to process your first request. You have to wait for it to finish a long monologue, or frantically hit a “stop” button, before you can try again.
This awkward dance happens because almost all current Large Language Models (LLMs) operate on a turn-based mechanism. You speak, the model waits for you to finish, it processes, and then it speaks. It is the digital equivalent of using a walkie-talkie (“Over and out”).
Human conversation, however, is a duplex process. We listen while we think. We speak while observing the other person’s reaction. We interrupt, we overlap, and we adjust our thoughts in real-time.
In a fascinating new paper from Tsinghua University, researchers propose a method to bridge this gap. They introduce Duplex Models, a framework that allows LLMs to listen and speak simultaneously, enabling natural, real-time interaction without changing the fundamental architecture of the model.
In this post, we’ll dive into how they achieved this, the clever engineering behind “time slices,” and how they trained a model to know when to shut up.
The Problem: The Turn-Based Bottleneck
Current chatbots behave like email exchanges: they require a complete message to generate a response. In technical terms, the model encodes the user’s entire prompt into key-value caches before generating a single token. This creates a rigid structure where one participant must be idle while the other is active.
In real life, if you ask a friend for book recommendations and then immediately say, “Actually, never mind, I want movies,” your friend stops thinking about books and switches to movies instantly. A standard LLM, however, is already locked into the “book” path until it finishes its turn.
To fix this, the researchers developed a Time-Division-Multiplexing (TDM) strategy.
The Core Method: Time-Division Multiplexing
The researchers didn’t invent a new type of Transformer; they reinvented how data is fed into it. Instead of waiting for a full sentence, they chop the conversation into Time Slices.
How Slicing Works
The concept is borrowed from telecommunications. The model processes input and generates output in small, rapid increments—specifically, every 2 seconds (roughly 4-6 words).
- Input Slice: The user’s voice/text is chopped into a small slice.
- Processing: The model processes this slice immediately.
- Output Decision: The model decides to either generate text (speak) or generate a special
<idle>token (remain silent).
If new input arrives while the model is generating, it doesn’t wait. It halts the current generation, integrates the new slice, and adjusts its output immediately.
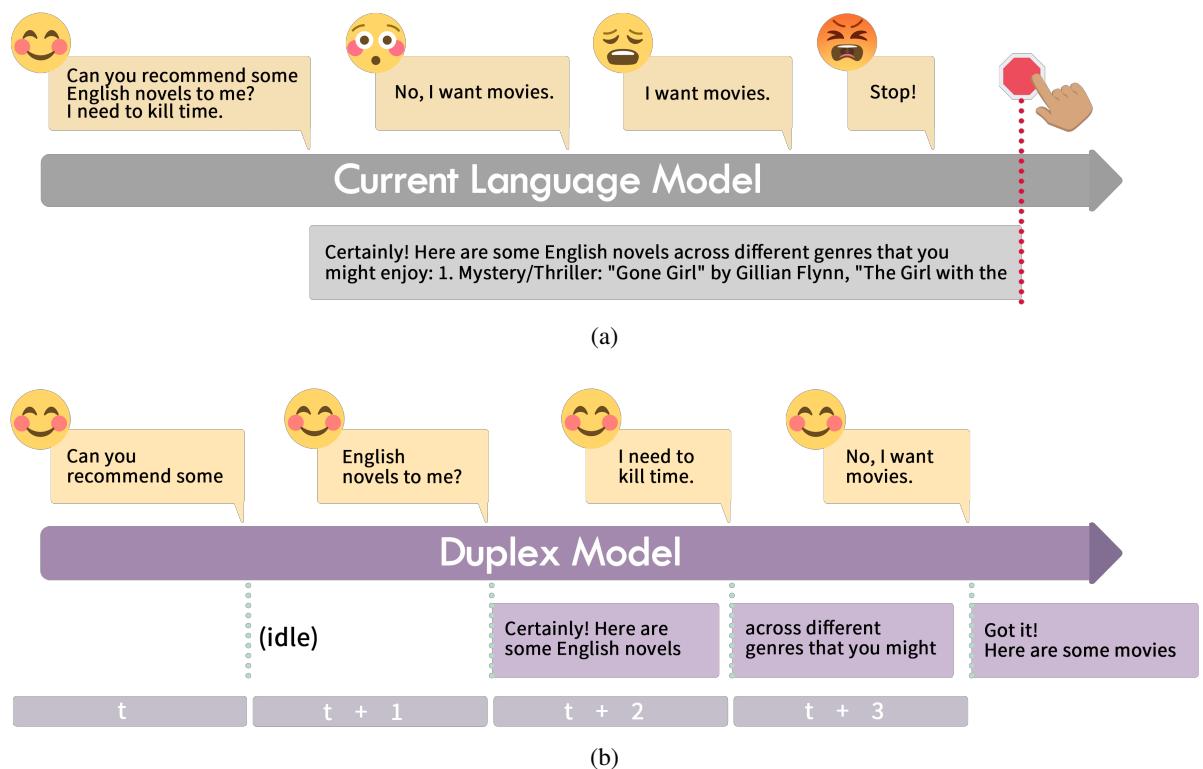
As shown in Figure 1 above, the difference is stark:
- Traditional Model (1a): The user asks for novels. Even though they correct themselves to “movies” later, the model has already committed to the novel recommendation. The user has to force a stop.
- Duplex Model (1b): At time \(t+2\), the model starts answering about novels. But at \(t+3\), when it hears “No, I want movies,” it immediately pivots. It essentially “listens” while it “talks.”
The Challenge: LLMs Hate Fragments
You might wonder: why can’t we just feed small chunks of text to GPT-4?
The problem is that standard LLMs are trained on complete documents. If you feed them a sentence fragment, they hallucinate or try to complete the sentence grammatically rather than acting as a helpful assistant.
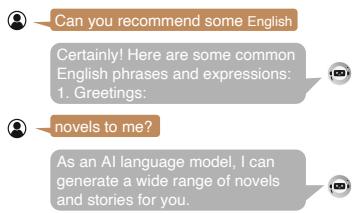
Figure 2 illustrates this failure mode. When a standard model (MiniCPM) is fed a slice like “Can you recommend,” it doesn’t wait for the rest. It starts generating random greetings or irrelevant phrases because it doesn’t understand the context of a “pause.”
To fix this, the researchers had to teach the model a new skill: Duplex Alignment.
Training the Model: The Duplex-UltraChat Dataset
The researchers created a specialized dataset called Duplex-UltraChat to fine-tune the model. This dataset teaches the LLM that sometimes, the correct response is to do nothing (output <idle>).
They took existing dialogue datasets (like UltraChat) and chemically altered them to simulate real-time chaos. They split messages into time slices and injected various interaction types.
1. The Art of Silence (Uninterrupted Dialogue)
The most basic skill a duplex model needs is patience. If a user’s sentence is incomplete, the model shouldn’t guess; it should wait.
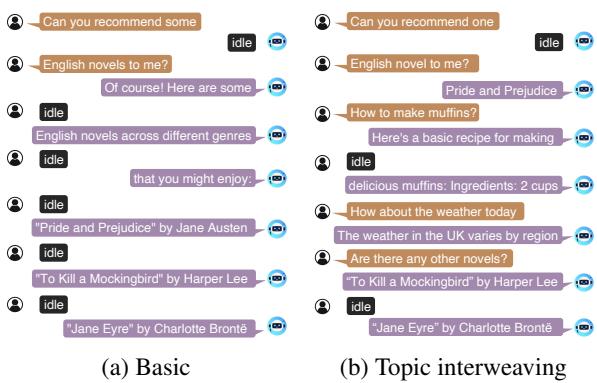
In Figure 3, you can see the “Basic” structure. The user’s input is split across multiple turns. The model’s target output for the initial slices is <idle>. It only generates the book recommendations once the user’s intent is clear.
2. Handling Interruptions
This is where the dataset gets interesting. The researchers simulated scenarios where users cut off the AI. They defined several interruption types:
- Generation Termination: The user effectively says “Shut up.” The model must learn to stop generating immediately.
- Regeneration: The user changes the constraints mid-sentence (e.g., “Wait, I meant sci-fi novels”).
- Dialogue Reset: The user abruptly changes the topic entirely (e.g., “Actually, what’s the weather?”).
- Back on Topic: The user interrupts to ask a clarifying question, and the model answers it but then seamlessly returns to the original topic.
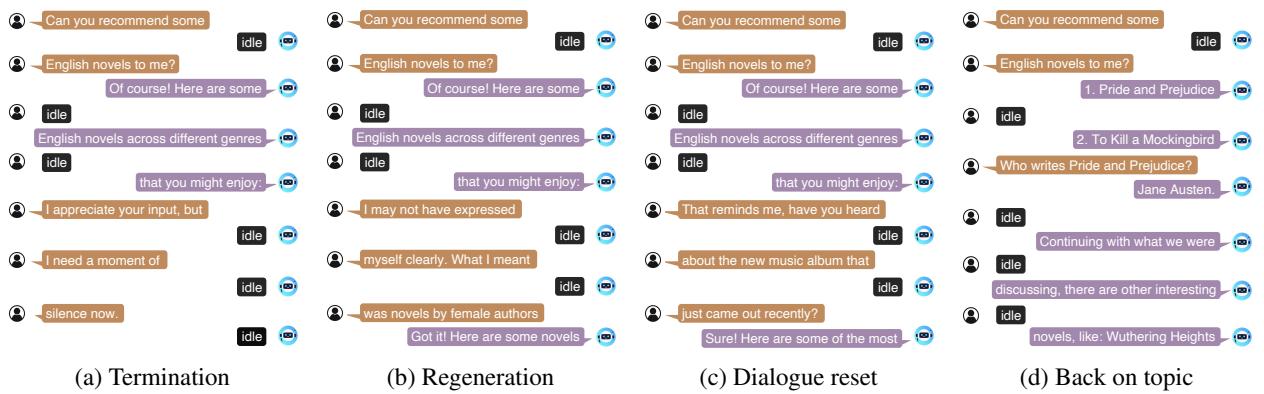
Figure 4 visualizes these scenarios. Look at panel (b) “Regeneration.” The user interrupts the recommendation list to clarify they want novels by female authors. The model catches this interrupt slice and pivots its suggestions immediately. This mimics the fluid dynamic of two humans talking.
Experiments & Results
The team trained a model called MiniCPM-duplex (based on the lightweight MiniCPM-2.4B) using this new dataset. They then pitted it against the original model to see if the “duplex” capability actually improved user experience.
Does Slicing Hurt Intelligence?
A major concern was that chopping inputs into tiny bits might make the model “dumber” or cause it to lose context.
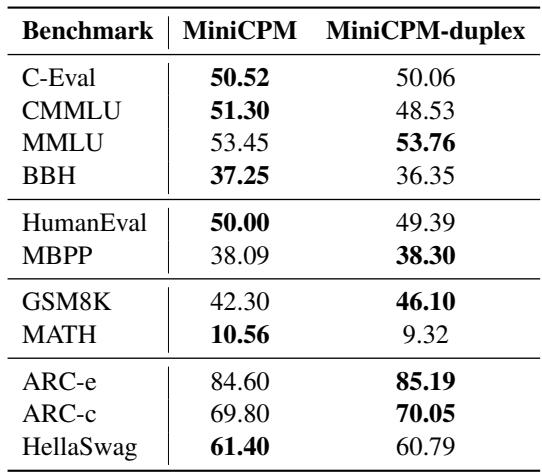
Surprisingly, Table 2 shows that the duplex fine-tuning had a negligible impact on general capabilities. On benchmarks like MMLU (knowledge) and GSM8K (math), the scores remained nearly identical. The model gained the ability to chat in real-time without losing its IQ.
Human Evaluation: The Real Test
Since “chat fluidity” is hard to measure with math, the researchers conducted a user study where participants interacted with both models via voice.
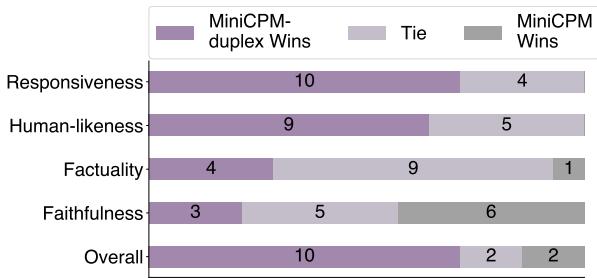
The results in Figure 6 are dramatic.
- Responsiveness: The duplex model won 10 times, compared to just 4 for the standard model.
- Human-Likeness: The duplex model was overwhelmingly perceived as more human.
- Overall: Users preferred the duplex experience significantly more often.
The distribution of scores further highlights this shift.
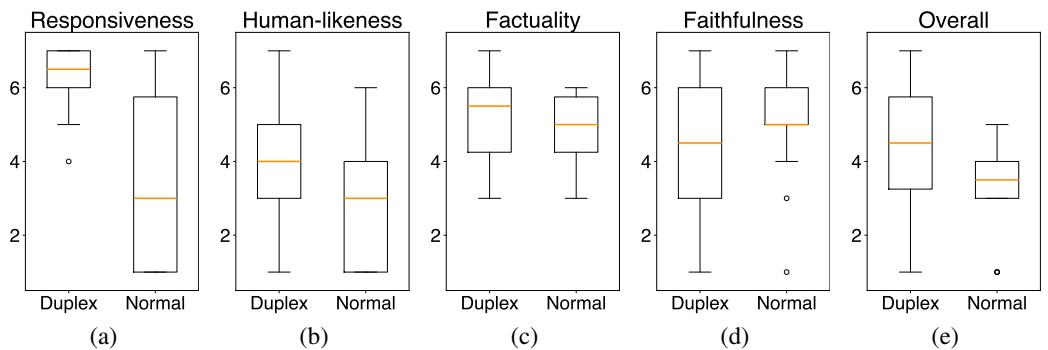
In Figure 5, notice the “Responsiveness” (a) and “Human-likeness” (b) box plots. The orange median line for the Duplex model is significantly higher than the Normal model. Users felt they were having a conversation, not issuing commands to a terminal.
Case Study
To see this in action, look at the case studies provided by the authors.
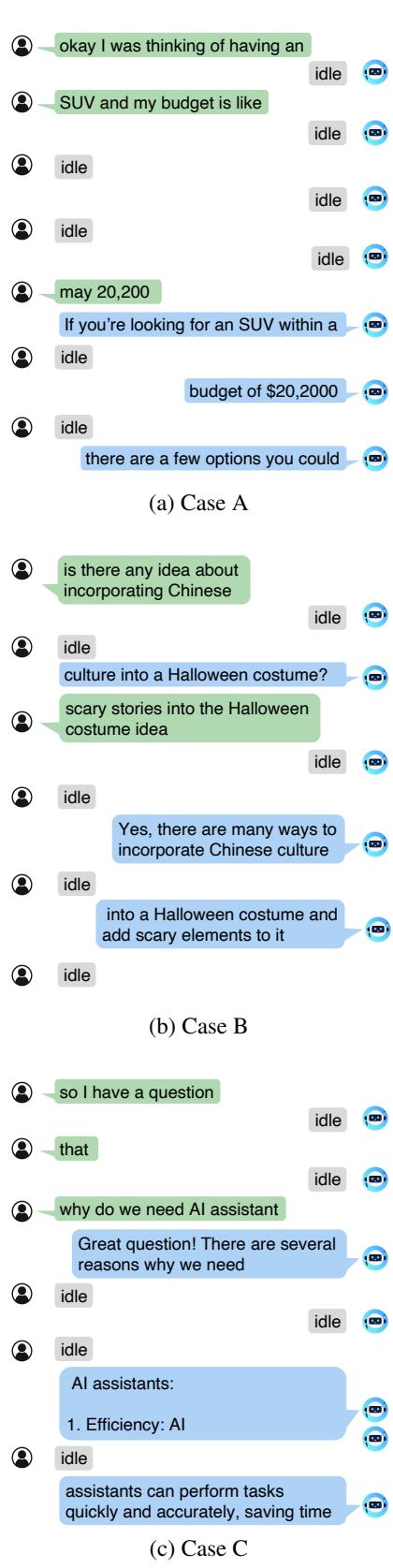
In Figure 7, Case B shows the nuance of the system. The user asks about “Chinese culture” regarding Halloween costumes. As the user elaborates, the model listens and integrates that specific cultural constraint into the suggestion list immediately.
Conclusion and Future Outlook
The “turn-based” nature of chatbots has long been an accepted limitation of AI, but this paper proves it doesn’t have to be. By treating conversation as a stream of time slices rather than a ping-pong match of complete paragraphs, MiniCPM-duplex moves us closer to the holy grail of AI: an agent you can talk to as naturally as a friend.
Key Takeaways:
- Duplex vs. Turn-Based: Real-time interaction requires models that can process input and generate output pseudo-simultaneously.
- The Idle Token: The ability to “listen” (output silence) is just as important as the ability to generate text.
- Data is King: Standard datasets don’t work for this. We need datasets like Duplex-UltraChat that include interruptions, hesitations, and topic switches.
While there are still challenges—specifically regarding Text-to-Speech (TTS) systems that need to handle choppy output streams smoothly—this research lays the groundwork for the next generation of voice assistants. Soon, that “stop” button on your AI interface might become a relic of the past.