](https://deep-paper.org/en/paper/2406.16620/images/cover.png)
Imagine you are trying to find a specific detail in a 24-hour CCTV recording or a dense three-hour film—perhaps the exact moment a character dropped a cigarette or the license plate of a car that appeared for two seconds. As a human, you wouldn’t memorize every pixel of the video. Instead, you would watch it, form a general impression of the plot, and when asked a specific question, you would scrub through the timeline, “rewinding” to the relevant section to inspect the details.
This dynamic process is intuitive for humans but incredibly difficult for Artificial Intelligence. While Large Language Models (LLMs) have evolved into Multimodal Large Language Models (MLLMs) capable of “seeing” images, they struggle immensely with long-form video. The sheer volume of data in a movie or day-long surveillance tape overwhelms the context window of most models.
Traditional solutions involve chopping the video into keyframes or summarizing it into text, but this results in significant information loss. If the summarizer didn’t think the dropped cigarette was important, that information is gone forever.
Enter OmAgent, a new framework developed by researchers at Om AI Research and Zhejiang University. OmAgent replicates the human cognitive process of video understanding. It combines a sophisticated memory retrieval system with a “Divide-and-Conquer” agent that can autonomously plan tasks and—crucially—use a “Rewinder” tool to look back at the raw video footage when its memory is fuzzy.
In this deep dive, we will explore how OmAgent achieves this, moving beyond simple video summarization to true complex video understanding.
The Challenge: The Memory Bottleneck
To understand why OmAgent is necessary, we first need to look at how current AI handles video.
- Video LLMs: Some models are trained from scratch on video data. While effective for short clips (seconds or minutes), they are computationally expensive and struggle to maintain context over hours of footage.
- Multimodal RAG (Retrieval-Augmented Generation): This is the industry standard for handling large data. The video is broken into chunks, stored in a database, and the AI retrieves only the “relevant” chunks based on your question.
The problem with standard Multimodal RAG is the segmentation gap. When a continuous video stream is chopped into discrete blocks and converted to vector embeddings, the flow of time is disrupted. Information that exists between the cracks of these segments, or subtle details that weren’t captured in the initial text description of the scene, becomes irretrievable.
OmAgent addresses this by ensuring the AI isn’t just relying on a static summary. It gives the AI the agency to act, investigate, and verify.
The OmAgent Architecture
OmAgent operates through two primary mechanisms working in tandem:
- Video2RAG: A preprocessing pipeline that converts video into a structured “long-term memory.”
- DnC Loop (Divide-and-Conquer): An intelligent agent loop that breaks down complex user queries into solvable sub-tasks.
Let’s break these down.
1. Video2RAG: Building the Foundation
Before the agent can answer questions, the video must be processed into a format the AI can query efficiently. OmAgent treats this as a “Video to Retrieval-Augmented Generation” (Video2RAG) problem.
Instead of feeding the entire video to an LLM (which would explode the token limit), the system processes the video to create a Knowledge Database.
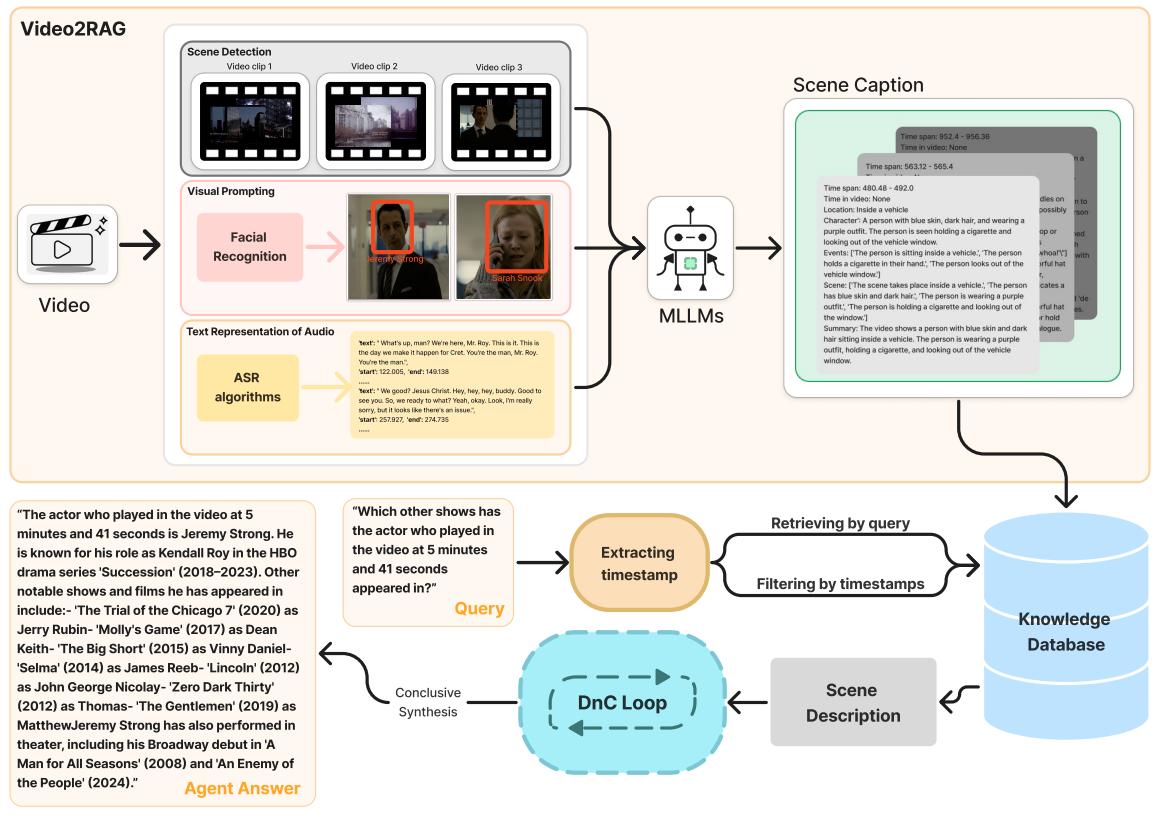
As shown in Figure 1, the process involves several sophisticated steps:
- Scene Detection: The video is segmented based on visual changes. If a scene is too short, it is merged with others. 10 frames are uniformly sampled from every segment.
- Algorithmic Extraction: The system doesn’t just look at the pixels; it runs specialized algorithms.
- ASR (Automatic Speech Recognition): Converts dialogue to text.
- Speaker Diarization: Identifies who is speaking.
- Visual Prompting: This is a clever addition. The system uses facial recognition to identify characters and draws bounding boxes on the images with text labels. This helps the MLLM identify specific people in crowded scenes.
- Scene Captioning: An MLLM takes these annotated frames and the audio text to generate a dense, structured caption for each segment. The researchers instructed the model to capture specific dimensions: time (morning/night), location, character actions, and a chronological list of events.
- Vector Storage: These rich captions are vectorized and stored. Crucially, the system keeps the original timestamps, which serve as the map for the agent’s “Rewinder” tool later.
2. The Divide-and-Conquer (DnC) Loop
This is the “brain” of OmAgent. Inspired by recursive programming algorithms, the DnC Loop allows the agent to tackle questions that are too complex for a single-step inference.
For example, if you ask, “Which other shows has the actor who played in the video at 5 minutes and 41 seconds appeared in?”, a standard model might hallucinate or fail because it requires three distinct steps: finding the frame, recognizing the face, and searching the web.
OmAgent handles this via the Conqueror and Divider modules.
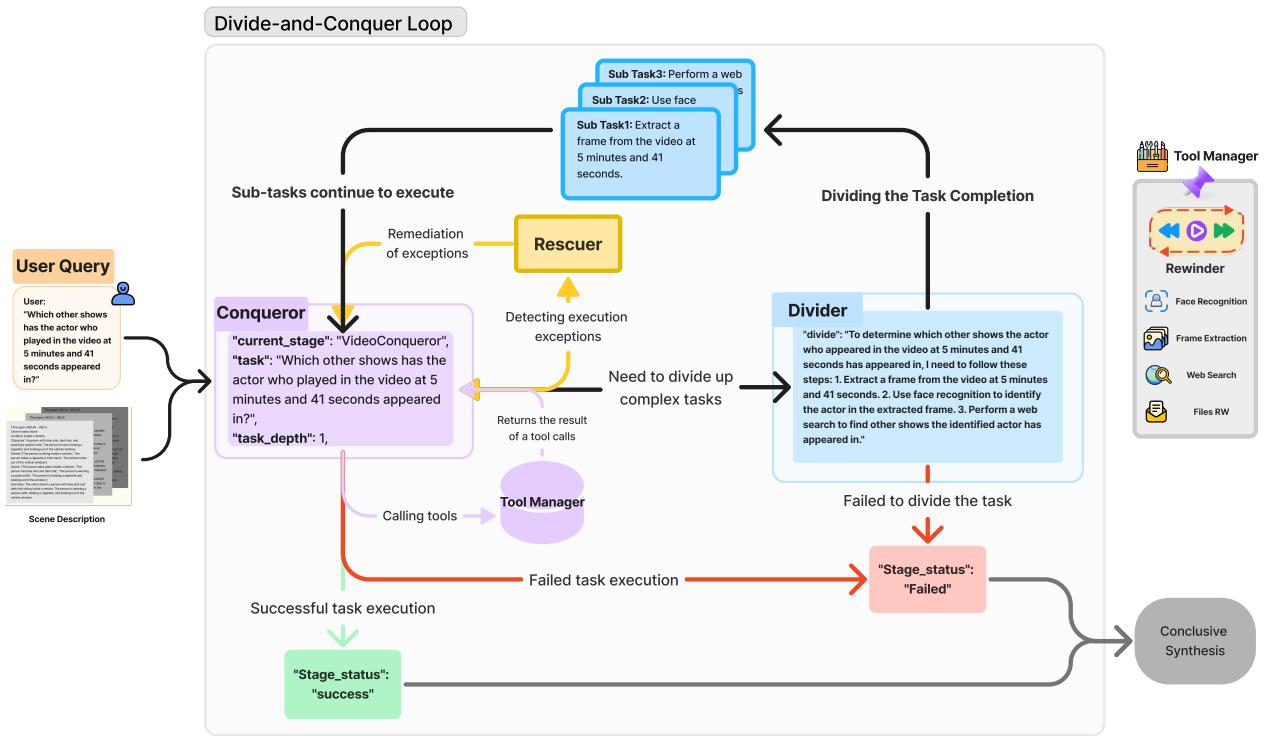
As illustrated in Figure 2, the workflow is recursive:
- Conqueror: This is the entry point. It analyzes the task.
- If the task is simple, it solves it (e.g., “What time is it?”).
- If it requires a tool (like a web search or video lookup), it calls the tool.
- If the task is too complex, it passes it to the Divider.
- Divider: This module breaks the complex task into logical sub-tasks. For the “actor” question above, it would split the query into:
- Subtask 1: Extract frame at 05:41.
- Subtask 2: Perform face recognition.
- Subtask 3: Search the web for the actor’s filmography.
- Task Tree: These sub-tasks are organized into a tree structure. The system executes them recursively.
- Rescuer: Agents often fail—maybe a Python library is missing or a tool times out. The Rescuer is an error-handling module that attempts to fix the runtime environment or retry the task, ensuring the loop doesn’t crash.
The “Rewinder” Tool
The most distinct feature of OmAgent is the Rewinder.
In standard RAG systems, once the video is processed into text/vectors, the original video is usually discarded from the workflow. OmAgent, however, abstracts the human ability to scrub a video player bar into a tool.
If the agent realizes that the stored Scene Caption is too vague to answer a question (e.g., “Did the character blink three times?”), it can autonomously decide to use the Rewinder. It retrieves the raw frames from the specific timestamps identified in the Video2RAG phase and re-analyzes them with fresh eyes. This effectively bridges the gap between efficient storage (text) and high-fidelity verification (visuals).
Case Studies: OmAgent in Action
Let’s look at how this plays out in practice using data from the popular TV show Succession.
Case 1: External Knowledge Integration
The Question: “Which other shows has the actor who played in the video at 5 minutes and 41 seconds appeared in?”
This requires connecting visual data to external world knowledge.

First, the system retrieves the relevant context. The Video2RAG process has already generated captions for the scenes, but the specific answer (the actor’s other shows) isn’t in the video.

The DnC Loop kicks in. As visualized in the agent output below, the system decomposes the task:
- Extraction: It isolates the video segment at 5:41.
- Recognition: It identifies the actor as Jeremy Strong.
- Search: It uses a web search tool to find his filmography.
- Synthesis: It combines these findings into a final answer.
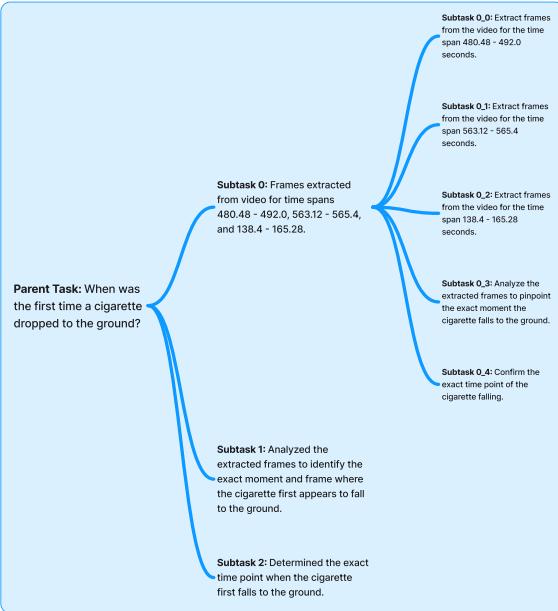
Case 2: The “Needle in a Haystack”
The Question: “When was the first time a cigarette dropped to the ground?”
This is a visual acuity test. A text summary might say “He smoked a cigarette,” but rarely “He dropped the cigarette at 02:32.”

The system relies on the Scene Captions to narrow down the search area.

Using the DnC loop (refer back to Figure 3/4 in the Agent Output image), the agent realizes it cannot answer this from captions alone. It creates a plan to inspect specific time intervals. It uses the Rewinder to pull frames from the candidate timestamps (e.g., 480s - 492s) and analyzes them specifically looking for a “dropping” action. It successfully locates the event at 00:02:32.
Experimental Results
The researchers evaluated OmAgent against several strong baselines, including pure Video2RAG (without the agent loop) and standard methods involving frame extraction with Speech-to-Text (STT). They created a new benchmark dataset comprising over 2,000 questions covering episodes, movies, documentaries, and vlogs.
Performance Across Video Types
The results show that OmAgent consistently outperforms the baselines.
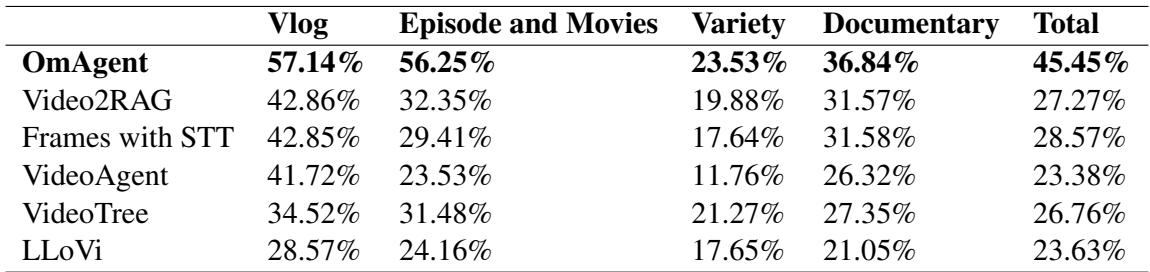
As seen in Table 2, OmAgent achieves a total accuracy of 45.45%, significantly higher than Video2RAG (27.27%) and Frames with STT (28.57%). The gap is particularly noticeable in “Episodes and Movies,” likely because these formats require tracking complex plot points and character interactions over time—tasks where the DnC loop excels.
Detailed Question Analysis
The researchers categorized questions into four types: Reasoning, Event Localization (finding timestamps), Information Summary, and External Knowledge.
Tables 4, 5, and 6 provide qualitative examples of where OmAgent succeeds.
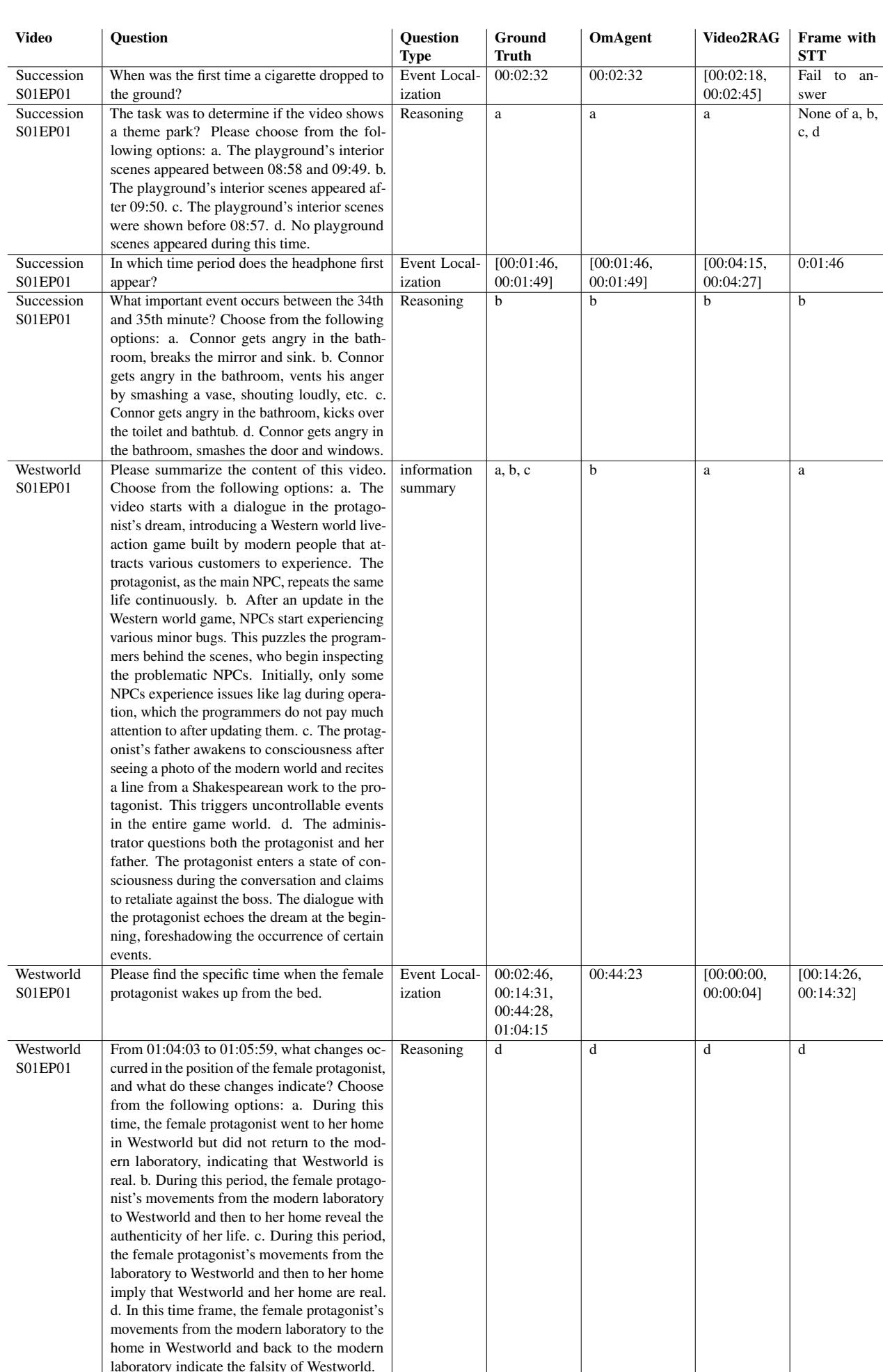
In Table 4 (Succession), notice the first question: “When was the first time a cigarette dropped to the ground?”
- OmAgent: 00:02:32 (Correct)
- Video2RAG: [00:02:18, 00:02:45] (Vague range)
- Frame with STT: Fail
This precision highlights the power of the Rewinder tool. The Video2RAG system relies on pre-generated summaries, which only give a general timeframe. OmAgent goes back to the tape to get the exact second.
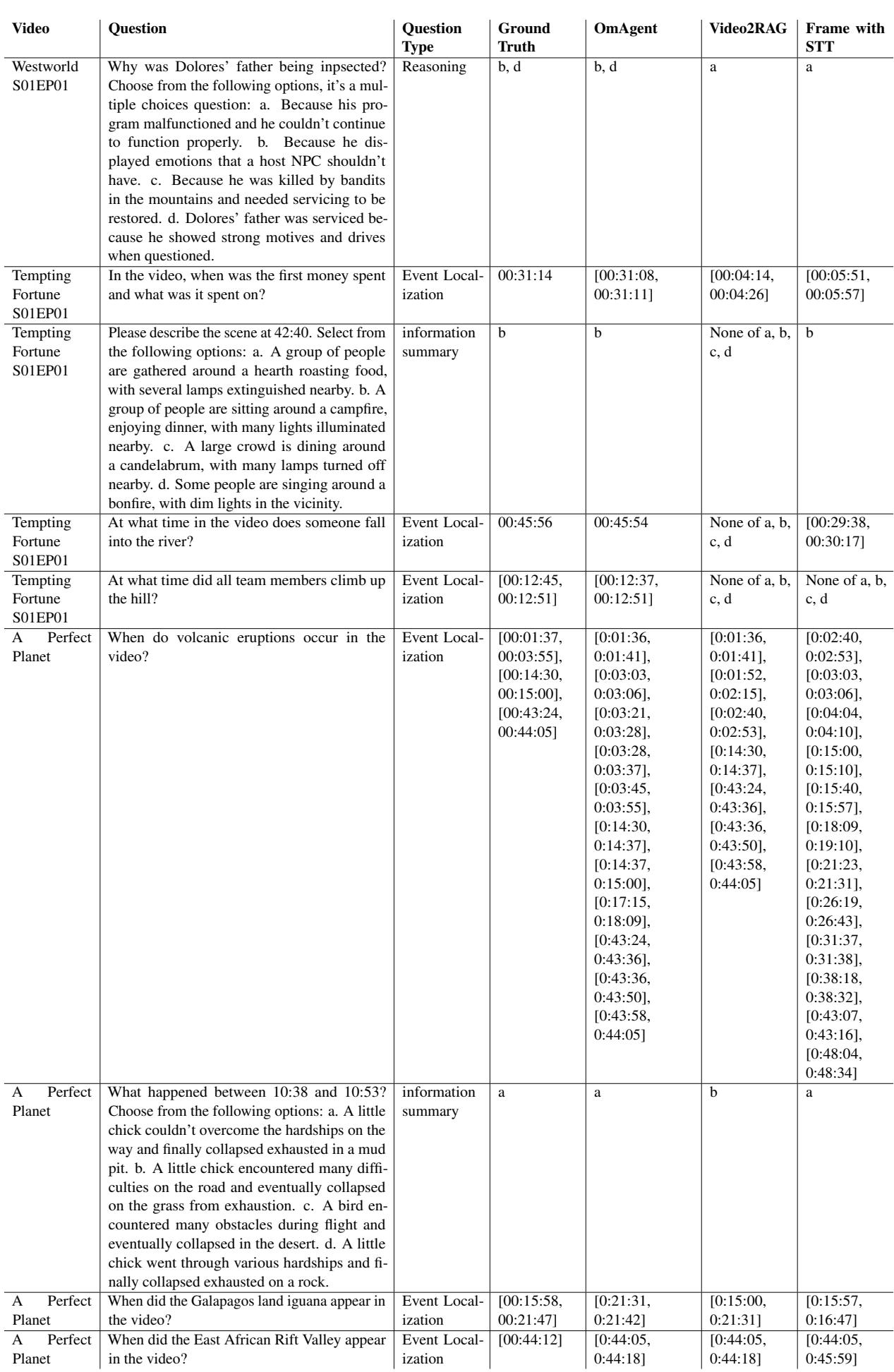
In Table 5 (Westworld), the system tackles complex summarization (Question 1) and precise localization (Question 2). For the question “Please find the specific time when the female protagonist wakes up,” OmAgent identifies the exact timestamp (00:44:23), whereas the baselines drift by minutes or fail completely.
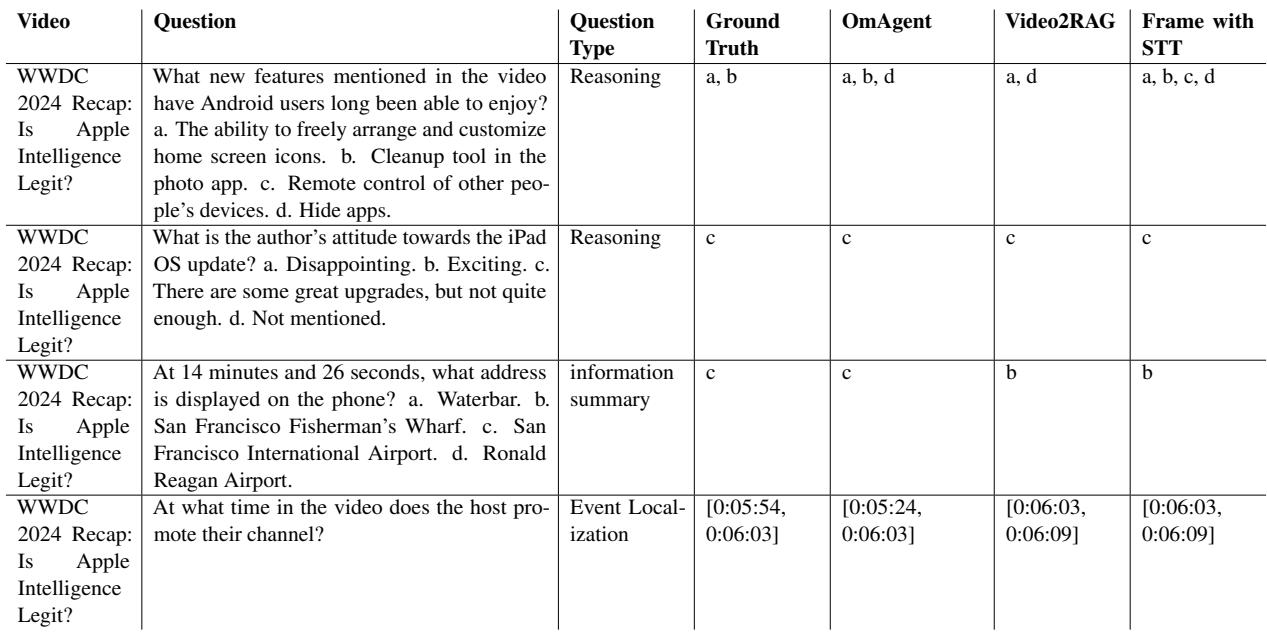
Table 6 shows results on a “WWDC 2024 Recap” video. This tests the agent’s ability to handle informational content. In reasoning tasks (Question 1), OmAgent correctly identifies multiple features mentioned in the video (a, b), while other models hallucinate extra options or miss details.
Why OmAgent Wins: The “Generalist” Advantage
The researchers also tested OmAgent on general problem-solving benchmarks like MBPP (Python coding tasks) and FreshQA (real-world Q&A).
OmAgent paired with GPT-4 achieved 88.3% on MBPP and 79.7% on FreshQA, outperforming GPT-4 alone and even the advanced XAgent framework. This proves that the architecture isn’t just good at watching movies; the Rescuer mechanism and the rigorous Divide-and-Conquer logic make it a robust general-purpose problem solver.
Conclusion and Future Outlook
OmAgent represents a significant step forward in making AI truly “multi-modal.” By acknowledging that current context windows cannot handle full-length movies, the researchers built a system that mimics human behavior: Scan, Summarize, Plan, and Rewind.
The key takeaways are:
- Don’t rely solely on summaries: The “Rewinder” tool allows the agent to verify details against ground truth, significantly reducing hallucinations.
- Recursive planning works: Breaking video tasks into sub-trees (Extraction -> Recognition -> Search) handles complexity better than linear chain-of-thought prompting.
- Visual Prompting aids retrieval: Annotating images with algorithmic data (like face boxes) helps MLLMs “focus” on the right details.
While the system still has limitations—it sometimes struggles with exact timestamp precision and audio-visual synchronization—it offers a blueprint for the future of video analysis. Whether for searching through thousands of hours of security footage or simply asking, “What movie was that actor in?” while watching TV, OmAgent creates a path for AI to understand the moving image as deeply as it understands text.