](https://deep-paper.org/en/paper/2406.16694/images/cover.png)
Introduction
Large Language Models (LLMs) like GPT-4 and Llama have revolutionized the way we interact with technology. They are incredible generalists—capable of writing poetry, debugging code, and summarizing history. However, when you drop these generalists into a highly specialized environment—such as programmatic advertising, legal consulting, or advanced mathematics—their performance often plateaus.
To fix this, researchers and engineers typically use a process called Continual Pre-Training (CPT). Ideally, you take a base model and keep training it on documents from your specific field (the “in-domain” data). But there are two glaring problems with this standard approach:
- Data Scarcity: Compared to the trillions of tokens available on the general web, high-quality, domain-specific data is tiny. An ad agency might only have a few billion tokens of internal data, which is a drop in the bucket for an LLM.
- Lack of Task Awareness: Raw documents (like a pile of legal contracts or a database of ad clicks) are not “textbooks.” They contain raw information but don’t explicitly teach the model how to use that information to solve specific problems, like rewriting a query or solving an equation.
In this post, we will dive deep into a new framework called TRAIT (Task-Oriented In-Domain Data Augmentation). This method proposes a clever solution: instead of just dumping raw text into the model, we can curate massive amounts of relevant data from the web and generate synthetic “textbooks” that teach the model how to think.
The Background: Why Standard Adaptation Fails
Before understanding TRAIT, we need to look at why current methods struggle.
When an LLM is pre-trained, it consumes the internet. It learns grammar, facts, and reasoning patterns. When we want to specialize it, we feed it domain data. However, previous research has shown that simply “exposing” the model to new words isn’t enough.
If you are training a model for the advertisement domain, you might feed it a dataset of ad copy and landing pages. But the model doesn’t necessarily know why a certain ad copy matches a certain search query. It just sees the correlation.
Furthermore, because domain data is so scarce, models often undergo “catastrophic forgetting”—they overfit to the small amount of new data and lose their general reasoning abilities. The TRAIT framework addresses these issues by treating data not just as “text to be read,” but as “lessons to be learned.”
The Core Method: TRAIT
The TRAIT framework is composed of two distinct but complementary strategies: In-Domain Data Selection (to solve scarcity) and Task-Oriented Synthetic Passage Generation (to solve task awareness).
Part 1: In-Domain Data Selection
Since specific domain data is rare, the authors turned to the largest source available: the general web. The hypothesis is that within massive datasets (like Common Crawl), there are snippets of text that are highly relevant to the target domain, even if they aren’t labeled as such.
To mine this data, the researchers employed a FastText classifier. Here is the process:
- Take a small set of known in-domain data (e.g., ads).
- Take a set of general out-of-domain data.
- Train a lightweight classifier to distinguish between the two.
- Run this classifier over a massive general web corpus (containing trillions of tokens).
This process identifies billions of tokens that “look like” the target domain. But quantity isn’t everything. To ensure quality, the researchers applied an “educational value” filter—essentially a metric to ensure the selected text is informative and well-structured, rather than just noise.
The result? For the advertisement domain, where they started with only 1 billion tokens of internal data, they were able to select an additional 15 billion tokens of high-quality relevant data from the web. This massive injection of knowledge solves the data scarcity problem.
Part 2: Task-Oriented Synthetic Passage Generation
This is where TRAIT truly innovates. Having raw data is good, but having data that explains how to solve problems is better. The researchers developed a pipeline to generate synthetic training examples that look like structured reasoning exercises.
Instead of training the model on simple Input-Output pairs, TRAIT generates complex “passages” that include:
- Multiple Problems: Questions from different downstream tasks (e.g., one about query rewriting, one about relevance).
- Problem-Specific Paragraphs: A breakdown of how to solve each specific problem.
- The Enlightenment Paragraph: A summary that connects the dots between the different problems.
Understanding Through Examples
Let’s look at how this applies to two very different fields: Advertising (an “Entity-Centered” domain) and Mathematics (a “Knowledge-Centered” domain).
The Advertisement Domain (Entity-Centered)
In fields like ads or finance, the focus is often on understanding a specific entity (like a product or a company) from multiple angles.
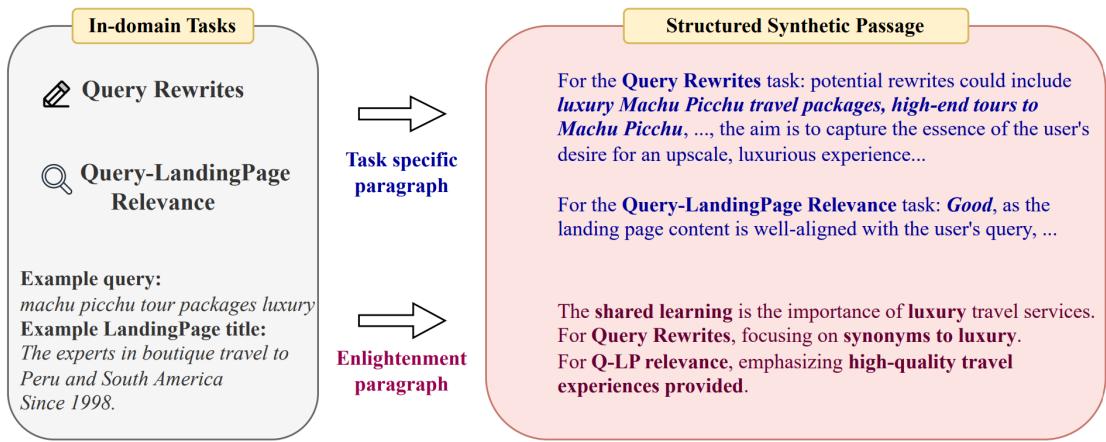
As shown in Figure 1, the system takes a user query (“machu picchu tour packages luxury”). It then generates a training passage that addresses two different tasks simultaneously:
- Query Rewriting: It explains how to rephrase the query (e.g., “high-end tours”).
- Relevance: It explains why a specific landing page is a good match.
Crucially, look at the bottom right of the figure: the Enlightenment Paragraph. It synthesizes the information. It tells the model why these answers are correct: “The shared learning is the importance of the luxury and personalized aspects of the travel service.”
This explicitly teaches the model to identify the core intent (Luxury + Travel) rather than just memorizing keywords.
The Math Domain (Knowledge-Centered)
In mathematics, the “entity” (the specific numbers) matters less than the “knowledge” (the formula or logic).
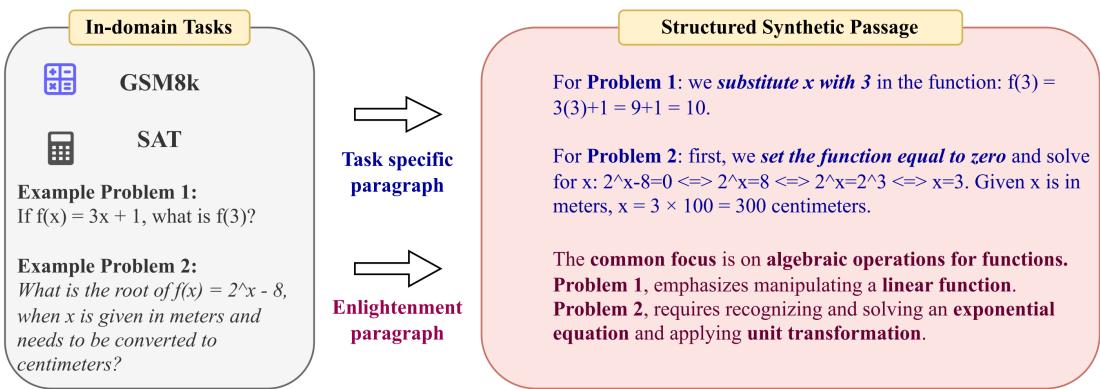
In Figure 2, we see two completely different math problems. One is about functions (from the GSM8k dataset) and one is about unit conversion (from the SAT dataset).
The generated passage solves both, but the Enlightenment Paragraph does the heavy lifting. It identifies that both problems require “algebraic operations for functions.” It teaches the model that despite the surface-level differences, the underlying mathematical reasoning is transferable.
The Two-Stage Training Strategy
The authors found that throwing all this data at the model at once wasn’t optimal. They devised a two-stage training strategy:
- Stage 1 (Knowledge Acquisition): The model is trained on the in-domain data (the original data + the massive amount of data selected from the web). This builds a strong foundation of domain knowledge.
- Stage 2 (Task Alignment): The model is trained on the synthetic task-oriented passages. This teaches the model how to apply the knowledge it just learned to actual problems.
Experiments and Results
To prove this framework works, the researchers applied it to the Mistral-7B model. They compared TRAIT against standard baselines, including Random Sampling (picking random web data) and DSIR (a popular importance-sampling method).
Visualizing the Data Gap
Why is this data selection necessary? The visualization below helps explain the distribution of data.
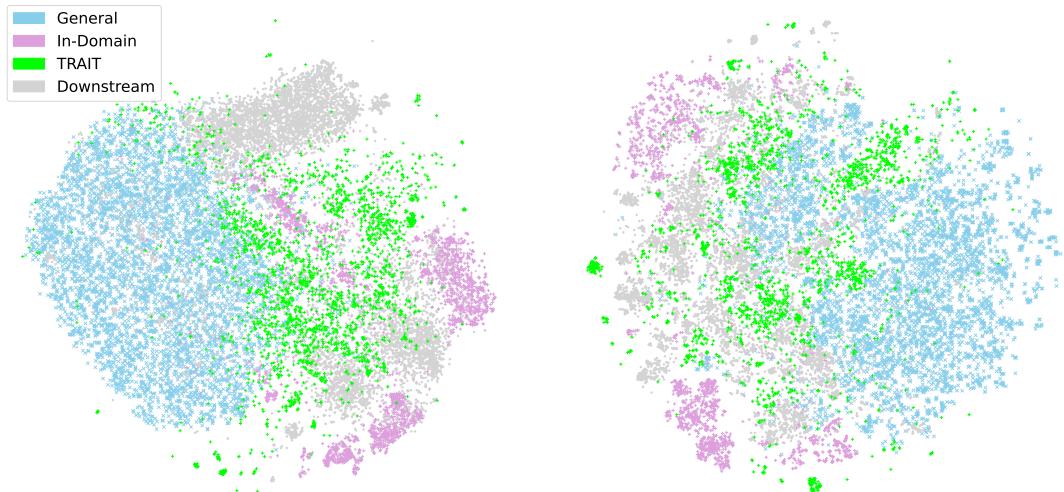
In Figure 3 (the scatter plots), you can see the disconnect. The “General” data (light blue) is vast but scattered. The “In-Domain” data (purple) is a tiny cluster. The “Downstream” tasks (grey) are clusters that the original in-domain data doesn’t fully cover.
However, the TRAIT data (green) successfully bridges the gap, covering the areas where the downstream tasks live. This visual confirmation proves that the data selection and generation strategy is effectively targeting the right information space.
Performance on Advertisement Tasks
The improvements in the advertising domain were substantial. The researchers evaluated the model on 7 different tasks, ranging from generating ad titles to determining relevance.
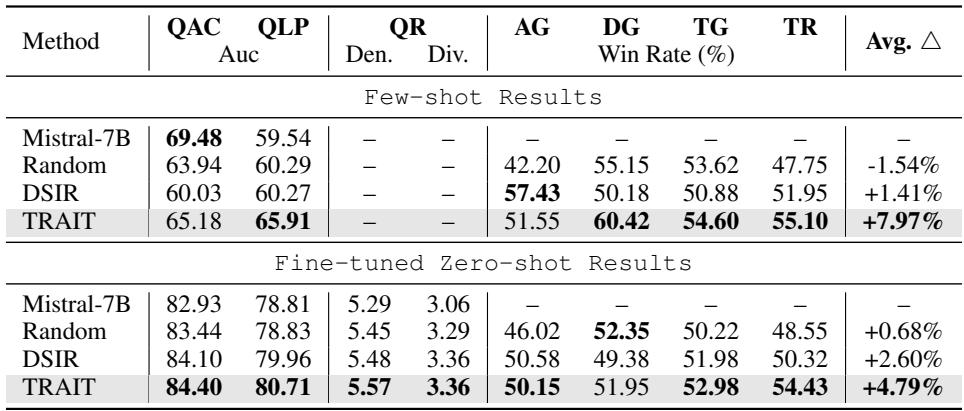
As seen in Table 1, TRAIT outperformed all baselines.
- Average Improvement: +8% over the base Mistral model and +2.2% over the best baseline (DSIR).
- Consistency: It won in almost every category, from Query-Ad Relevance (QAC) to Title Generation (TG).
Performance on Math Tasks
The results in the math domain were even more striking. Mathematical reasoning is notoriously difficult for LLMs to improve upon without massive supervised fine-tuning.
TRAIT achieved an average accuracy improvement of 7.5% across 9 different math benchmarks. On the highly challenging MATH benchmark, it improved performance by over 15%. This suggests that the “Enlightenment Paragraph” is particularly effective in logic-heavy domains where abstracting the underlying technique is key to solving new problems.
Why does it work? (Ablation Studies)
Is it the data selection? Or is it the synthetic data? Referencing Table 4 (included in the image with Figure 3 above), we can see the breakdown:
- Base Mistral: Good baseline.
- + Original Data: Small improvement (+1%).
- + Selected Data: Larger improvement.
- + Synthetic Data (TRAIT): The biggest jump (~5%).
This confirms that while more data helps, the structure of the synthetic data—specifically the task-oriented guidance—is the primary driver of performance.
The “Aha!” Moment in Training
One of the most interesting findings is how the model learns over time.
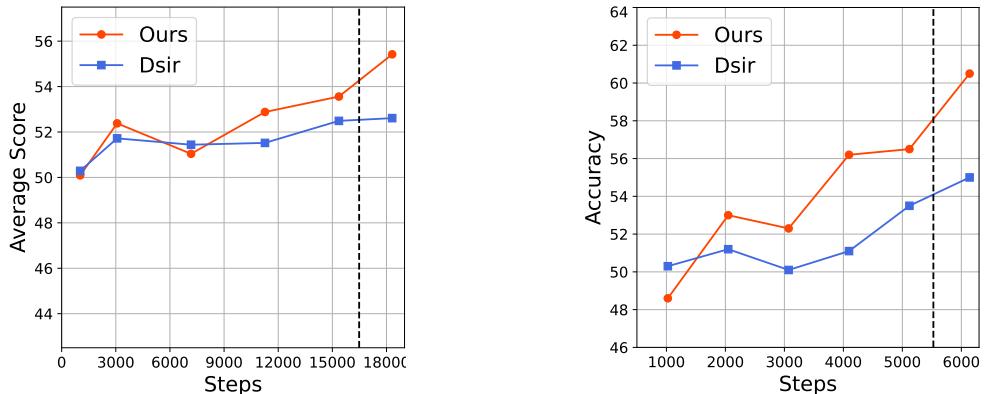
Figure 4 shows the training curves. Look at the curve for “Ours” (TRAIT).
- In the first phase (left side of the charts), performance fluctuates or rises slowly. This is the Knowledge Acquisition phase. The model is reading the “textbook.”
- Suddenly, there is a sharp spike (the right side of the charts). This corresponds to Stage 2, where the synthetic task-oriented passages are introduced.
This mirrors human learning: you might read a book and understand the concepts, but your ability to solve exam questions skyrockets once you start doing practice problems.
Conclusion
The TRAIT paper presents a compelling roadmap for the future of specialized LLMs. It highlights that the “bigger is better” approach to data isn’t enough when dealing with specific domains. We need data that is task-oriented.
By intelligently selecting data from the open web to bolster scarcity, and using LLMs to write their own “instruction manuals” (synthetic passages with enlightenment paragraphs), we can create models that are not just knowledgeable, but capable.
For students and researchers, the key takeaway is the importance of structure in training data. The “Enlightenment Paragraph” concept—explicitly teaching the model to find connections between different problems—is a powerful technique that pushes the model from rote memorization toward genuine reasoning. As we move toward more specialized AI agents in law, medicine, and engineering, frameworks like TRAIT will be essential in bridging the gap between general capability and expert performance.