](https://deep-paper.org/en/paper/2406.17969/images/cover.png)
Large Language Models (LLMs) like GPT‑4 and Llama 3 are transforming our world—but a fundamental mystery remains: how do they actually think? We know that they’re built from billions of artificial neurons, yet peering inside this digital brain often reveals a tangled mess. Many neurons are polysemantic, meaning that a single neuron might fire for a strange mix of unrelated concepts—like the color red, the sport of baseball, and the feeling of sadness—all at once.
This complexity makes it extraordinarily difficult to understand, predict, or trust these models. To fix this, a growing field called mechanistic interpretability aims to reverse‑engineer LLMs. One of its holy grails is monosemanticity—the idea that each neuron should correspond to one specific, human‑understandable concept. A “Golden Gate Bridge” neuron. A “past tense” neuron. An “irony” neuron. If we could achieve that, we might finally begin mapping the internal logic of these systems.
But this raises a critical question: is monosemanticity actually good for performance? Some researchers have suggested that forcing neurons to be highly specialized could cripple the model’s ability to generalize, arguing that the chaotic, overlapping nature of polysemanticity might be a necessary evil for efficiency.
A new paper— “Encourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective” —challenges that view. The authors argue that not only is monosemanticity beneficial, it’s also a natural outcome of aligning models with human preferences. They propose a fresh way to measure and encourage it through feature decorrelation, offering a path to models that are both more interpretable and more capable.
Let’s unpack their findings.
What Is Monosemanticity, and Why Is It So Hard to Find?
Before diving deeper, it’s helpful to clarify some terms:
- Concept: An interpretable idea recognizable to humans (e.g., “love,” “computer programming,” “cat”).
- Neuron: A single computational unit in a neural network.
- Feature / Activation: The internal representation produced when a neuron or layer processes an input.
The challenge stems from the fact that the relationship between neurons and concepts isn’t clean. A polysemantic neuron activates for multiple unrelated ideas, while a monosemantic neuron forms a one‑to‑one mapping with a single concept.
To hunt for these rare, interpretable neurons, researchers often use a Sparse Autoencoder (SAE). Picture it as a microscope for the neural brain: it takes the complex activation vector inside an LLM, compresses it into a sparse version where only a handful of entries are non‑zero, and then reconstructs the original activation from that sparse code.
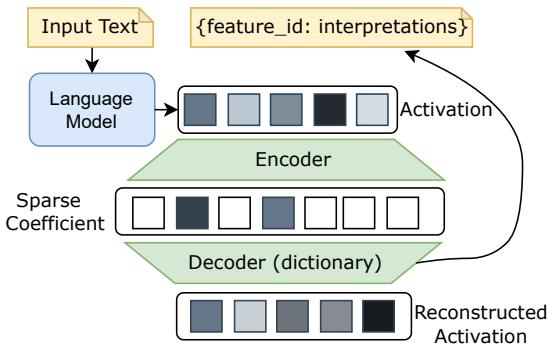
Figure 1: Sparse Autoencoder architecture used to identify monosemantic neurons by reconstructing model activations through sparse, interpretable features.
Each active feature in the sparse code ideally corresponds to a single, pure concept. By analyzing which inputs cause a feature to fire, researchers can manually label it (e.g., “this feature activates for text related to laws”). It’s a powerful method—but also computationally expensive and labor‑intensive, making it impractical to scale across millions of neurons. This bottleneck left a key question unanswered: should monosemanticity be encouraged or suppressed?
A Wrinkle in the Story: Is Monosemanticity Bad for Performance?
Earlier research suggested that inhibiting monosemanticity—that is, promoting polysemantic neurons—might improve model capacity. This conclusion came from analyzing a “monosemanticity proxy” across different model sizes in the Pythia family, where larger models appeared to show lower monosemanticity scores. The interpretation was that polysemanticity is an efficient trade‑off for scale.
The new paper re‑examines this by applying the same proxy to the GPT‑2 model family. The results, however, tell a different story.
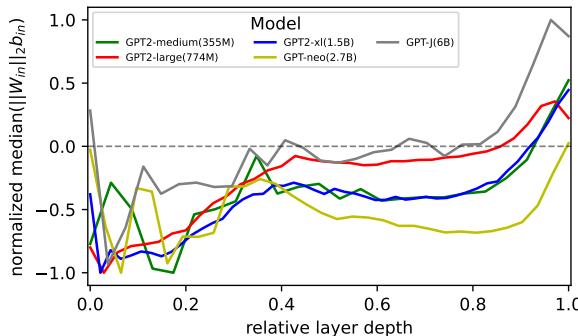
Figure 2: Measured monosemanticity proxy across GPT‑2 variants. The lack of a clear trend suggests no consistent relationship between model size and monosemanticity.
As seen above, the 1.5 B parameter GPT‑2 XL shows more monosemanticity than smaller models, while the 2.7 B GPT‑Neo model shows less. There’s no consistent pattern, implying that comparisons across models are unreliable—different architectures and training processes confound the result. So, instead of comparing models externally, what if we look at monosemanticity within a single model as it learns?
A New Lens: Monosemanticity as Feature Decorrelation
To explore monosemanticity “from the inside,” the authors introduce a concept from superposition theory. Superposition occurs when a model encodes more features than neurons: each neuron represents multiple overlapping features. This overlap—shared activations, or correlation between features—is the essence of polysemanticity.
Conversely, decorrelated features are independent, orthogonal signals. In a perfectly monosemantic system, neurons would act independently, each representing one unique feature.
This insight allows a practical proxy: the correlation between internal activations. Low correlation → high monosemanticity; high correlation → polysemanticity.
Mathematically, if two neuron weight vectors \( \mathbf{W}_i \) and \( \mathbf{W}_j \) are orthogonal, minimizing their dot product
\[ \sum_{j \neq i} (\mathbf{W}_i \cdot \mathbf{W}_j)^2 \]leads to decorrelated activations. Under linear assumptions with normalized inputs, this means
\[ \mathbf{Z}^{\top}\mathbf{Z} = \mathbf{X}^{\top}\mathbf{W}^{\top}\mathbf{W}\mathbf{X} \approx \mathbf{D} \]where \( \mathbf{D} \) is diagonal—representing perfectly decorrelated (monosemantic) features. Hence, the closeness of the activation correlation matrix \( \mathbf{Z}^{\top}\mathbf{Z} \) to a diagonal identity provides a measurable monosemanticity score.
The Surprising Link Between Alignment and Monosemanticity
Equipped with this proxy, the authors examined how monosemanticity evolves during preference alignment, a fine‑tuning step that teaches models to favor human‑preferred outputs. They focused on Direct Preference Optimization (DPO), which trains a model on pairs of responses—one preferred, one rejected—to adjust its internal reward function.
When they applied DPO to several GPT‑2 variants, they found that DPO consistently increased monosemanticity, especially in earlier layers.
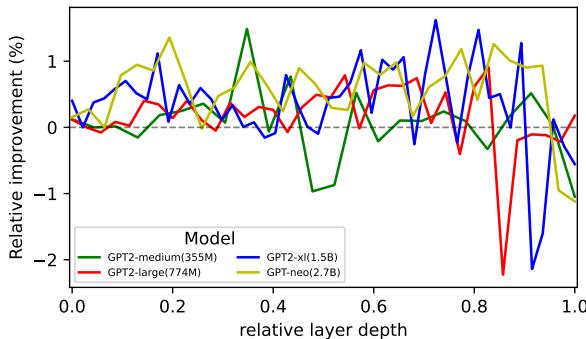
Figure 3: Relative change in monosemanticity proxy after DPO training. DPO improves monosemanticity across GPT‑2 models, particularly in early layers.
To validate further, they trained Llama 2 with DPO and measured internal feature decorrelation. The improvement was clear.
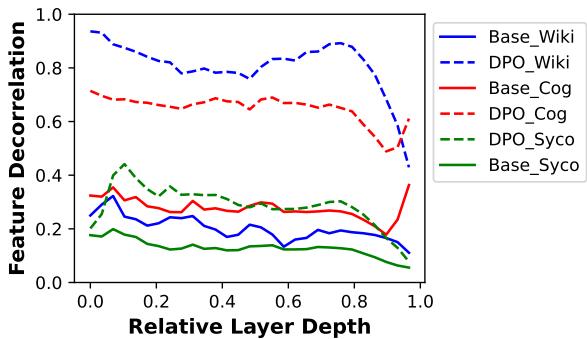
Figure 4: Feature decorrelation in Llama 2. DPO significantly increases decorrelation—indicating enhanced monosemanticity—across multiple datasets.
This demonstrates that alignment training naturally drives models toward monosemanticity. In other words, models not only become more human‑aligned but also develop cleaner, more interpretable internal representations.
DecPO: A Simple Regularizer for Smarter, More Interpretable Models
If DPO already promotes monosemanticity, why not help it along? The authors propose a variant called Decorrelated Policy Optimization (DecPO)—adding a small regularization term to the DPO objective that directly penalizes correlated activations:
\[ \mathcal{L}_{\text{dec}} = ||\mathbf{z}\mathbf{z}^{\top} - \mathbf{I}||_F^2 \]This term encourages diverse, non‑redundant features. The addition is small but powerful.
The Results: Higher Decorrelation, Sparsity, and Interpretability
DecPO quickly increased feature decorrelation beyond DPO and reduced overfitting during longer training runs.
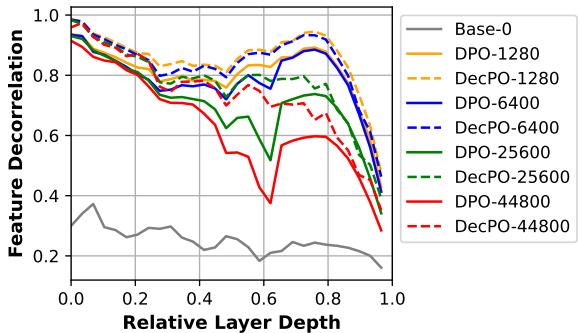
Figure 5: Feature decorrelation during fine‑tuning. DecPO maintains higher decorrelation and mitigates late‑stage overfitting.
Next, they measured activation sparsity (the variance of neuron activations). Sparse patterns indicate monosemanticity—only a few specific neurons activate per concept.
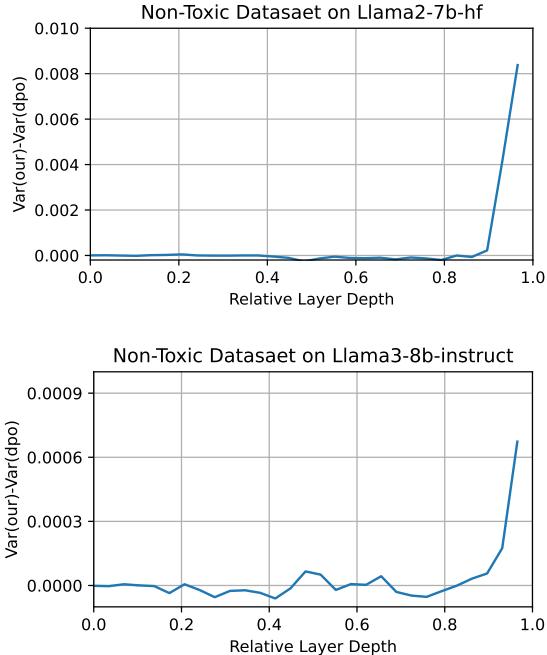
Figure 6: Difference in activation variance between DecPO and DPO. Higher variance reflects greater sparsity and thus higher monosemanticity.
Finally, they examined whether this leads to more human‑interpretable neurons by mapping dominant MLP dimensions back to vocabulary tokens.
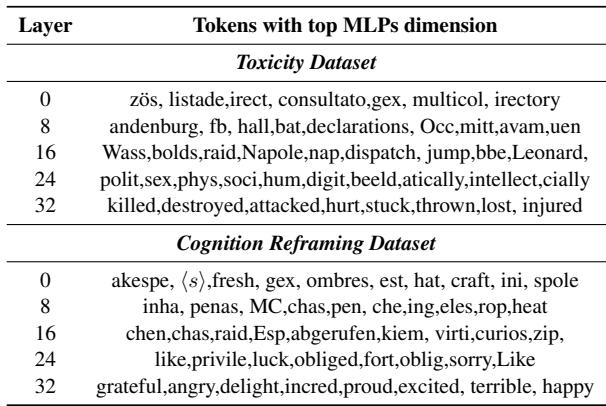
Table 1: Representative tokens linked to top MLP dimensions at different model depths. Deeper layers correspond to clearer, task‑specific concepts like violence (Toxicity) or emotion (Cognition Reframing).
Early layers emit nonsensical fragments, but deeper layers reveal clear semantic clusters—violence and loss for Toxicity; emotions for Cognition Reframing. The model literally carved out neurons representing human‑interpretable features.
The Payoff: Better Alignment Performance
Encouraging monosemanticity isn’t just philosophically elegant—it tangibly improves performance. Compared with baselines like Supervised Fine‑Tuning (SFT), DPO, and SimDPO, DecPO achieved the best results across three alignment tasks: toxicity reduction, cognitive reframing, and sycophancy suppression.
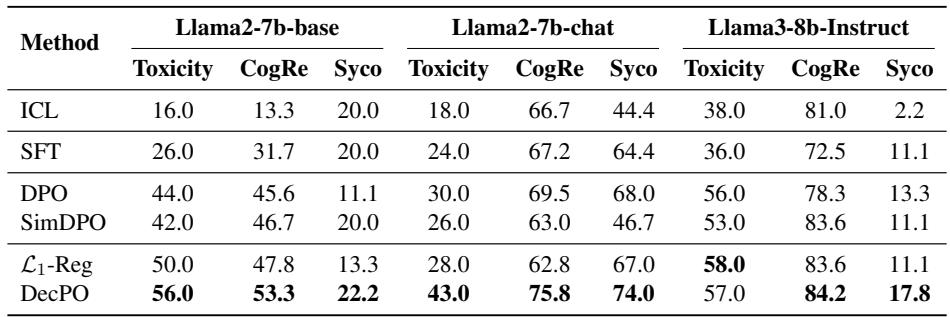
Table 2: Preference alignment results. DecPO delivers consistent gains—up to 13 % improvement—over standard DPO across datasets.
DecPO prevents “shortcut learning,” where a model memorizes superficial cues to win preference comparisons. By forcing diversity and orthogonality in features, it guards against reward‑hacking and aligns neurons with genuine semantic distinctions.
This is reflected in the reward margin—the gap between internal scores for good vs. bad responses.
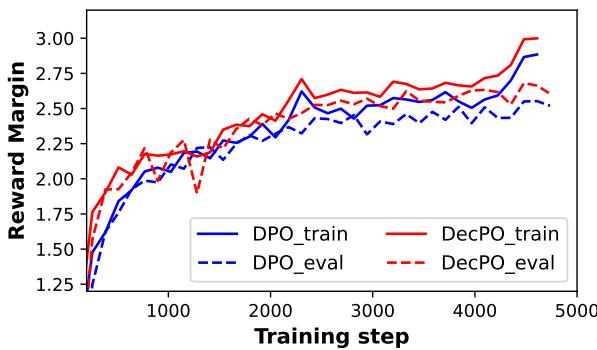
Figure 7: Reward margin during training. DecPO sustains a larger margin, showing more confident discrimination between preferred and dispreferred responses.
DecPO’s broader reward margin means it forms sharper boundaries between acceptable and unacceptable outputs—precisely what alignment aims for.
Conclusion: A Win‑Win for Interpretability and Capability
This study reframes mechanistic interpretability in a new light. It challenges the notion that polysemanticity is inevitable or even advantageous, presenting strong evidence that monosemanticity is desirable—and that alignment processes naturally increase it.
By viewing monosemanticity through the lens of feature decorrelation, the researchers offer not only a theoretical bridge but also a practical method, DecPO, for promoting interpretable neurons. DecPO makes models both easier to understand and better aligned with human values.
The takeaway is powerful: interpretability and capability aren’t competing goals—they’re two sides of the same coin. When we help models organize their internal understanding in ways that make sense to us, we’re also helping them become more robust, fair, and effective.
The journey to fully decode the black box of LLMs is long, but this work marks a promising step forward. Encouraging monosemanticity may not only help us understand our models—it may help our models understand us.