](https://deep-paper.org/en/paper/2406.19593/images/cover.png)
Introduction
Imagine showing an AI a photo of a rare, specific species of bird perched on a branch and asking, “What is the migration pattern of this bird?”
A standard Multimodal Large Language Model (MLLM) like GPT-4V or LLaVA might recognize the bird correctly. However, if the specific migration details weren’t prevalent in its pre-training data, the model might “hallucinate”—confidently inventing a migration route that doesn’t exist. This is a persistent reliability issue in AI: models are great at looking, but they don’t always know everything about what they see.
In text-only AI, we solve this with Retrieval Augmented Generation (RAG). We give the model a reference document (context) containing the facts, and the model answers based on that text. But doing this for images—known as Context-Augmented VQA—is significantly harder. Why? Because we lack the training data. There simply aren’t enough naturally occurring datasets that combine an image, a complex question, and a specific text document required to answer it.
Enter SK-VQA (Synthetic Knowledge Visual Question Answering). In a new research paper, a team from Intel Labs and Amazon proposes a novel solution: if the data doesn’t exist, generate it. Using a fully automated pipeline involving GPT-4, they created a massive dataset of over 2 million visual question-answer pairs paired with detailed context documents.
In this post, we will dive deep into how SK-VQA is constructed, why synthetic data is the key to unlocking better Multimodal RAG systems, and what the experiments reveal about the future of AI reasoning.
The Problem: The Data Bottleneck in Multimodal RAG
To understand the value of SK-VQA, we first need to understand the landscape of Knowledge-Based Visual Question Answering (KB-VQA).
In standard VQA, you might ask, “What color is the car?” The answer is in the pixel data. in KB-VQA, you ask, “Who manufactured this car and in what year was this model discontinued?” The answer requires external knowledge not found in the image itself.
To train models for this, we need triplets of data:
- Image: The visual input.
- Context: A text document containing the external knowledge (e.g., a Wikipedia snippet).
- Question & Answer: A query that requires reasoning over both the image and the text.
The Limitation of Existing Datasets
Existing datasets like InfoSeek or OK-VQA have tried to fill this gap, but they suffer from significant limitations:
- Wikipedia Dependency: They usually start with a Wikipedia entity and search for an image. This limits the data to “things that have Wikipedia pages,” ignoring vast amounts of visual concepts.
- Lack of Diversity: Questions are often created using rigid templates (e.g., “What is the [attribute] of [entity]?”), which fails to capture natural language variety.
- Scale: Naturally occurring data of this specific triplet structure is scarce.
This scarcity makes it difficult to train MLLMs to effectively use retrieved context. The models haven’t “learned” how to look at an image and read a document simultaneously to find an answer.
The Solution: SK-VQA
The researchers introduce SK-VQA, the largest KB-VQA dataset to date. Instead of scraping the web for scarce data, they synthesize it.

As shown in Figure 1, the dataset provides an image (e.g., The Beverly Hilton), a generated context document (history, architect, owner), and several QA pairs that force the model to connect the visual (identifying the building) with the textual (identifying the architect).
1. The Generation Pipeline
The core innovation of SK-VQA is its generation methodology. The researchers use a strong foundation model (GPT-4) to function as both a knowledge base and a data annotator.
The process works as follows:
- Input: Feed an image into GPT-4.
- Context Generation: Ask GPT-4 to write a “Wikipedia-style” article about the image.
- QA Generation: In the same step, ask GPT-4 to generate questions that require reasoning over both the image and the generated text.
This approach decouples the image from the necessity of having an existing Wikipedia page. As illustrated in Figure 2, this allows the dataset to ingest images from diverse sources: historical photos, sports snapshots, nature photography, and even synthetic images.
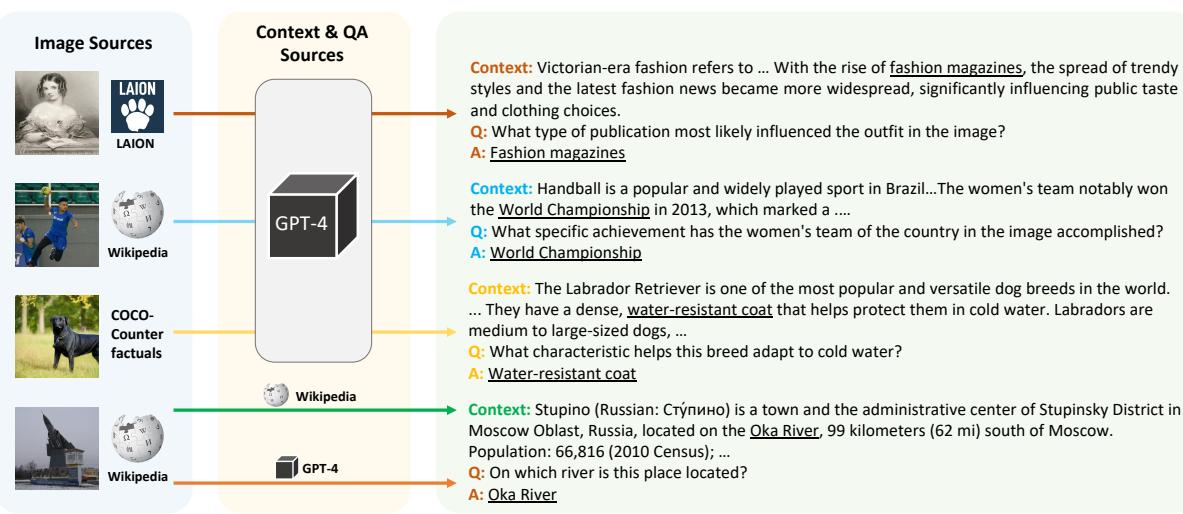
In Figure 2, notice the variety. The system handles a Victorian-era photo by generating context about fashion magazines, or a photo of a dog by explaining biological adaptations like water-resistant coats. This diversity is impossible to achieve with template-based scraping.
2. Prompt Engineering for Quality
Generating synthetic data carries the risk of “garbage in, garbage out.” If the prompt is weak, the resulting data will be noisy or trivial. The authors crafted a specific prompt to ensure high-quality, difficult questions.

Figure 3 shows the exact prompt used. Key constraints include:
- “Avoid mentioning the name of the object in the image” (prevents the answer from being given away in the question).
- “Question should be answered by reasoning over the Wikipedia article” (enforces the RAG requirement).
- “Answer should not be any objects in the image” (forces the model to look at the text for the answer).
This careful prompting ensures that the model trained on this data actually learns multimodal reasoning, rather than just guessing based on object recognition.
3. Dataset Composition and Scale
The scale of SK-VQA is massive compared to previous efforts. The researchers combined images from:
- LAION: A massive dataset of image-text pairs from the web.
- Wikipedia (WIT): Standard Wikipedia images.
- COCO-Counterfactuals: Synthetic images designed to be tricky.
The resulting dataset contains over 2 million QA pairs.
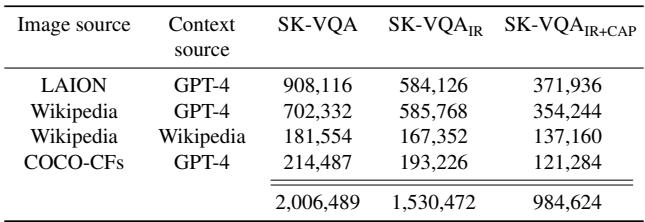
Table 1 breaks down the numbers. The researchers also created two filtered subsets to ensure quality:
- SK-VQA\(_{IR}\) (Image Reference Filtering): They removed context documents where GPT-4 explicitly mentioned “In this image…” or “As seen in the photo…”. Real-world encyclopedias don’t reference the specific JPEG you are looking at, so removing these makes the text more realistic.
- SK-VQA\(_{IR+CAP}\) (Context Answer Presence): This stricter filter ensures that the answer to the question is explicitly present as a string within the context document.
Unprecedented Diversity
One of the most striking statistics is the number of unique questions. In many datasets, questions repeat (e.g., thousands of instances of “What year was this built?”).
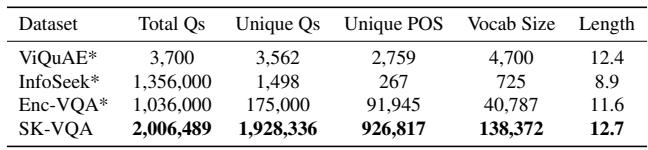
Table 2 highlights this disparity. While InfoSeek has 1.3 million QA pairs, it only has roughly 1,500 unique questions. SK-VQA, conversely, boasts nearly 1.9 million unique questions. This linguistic diversity is crucial for preventing models from memorizing templates.
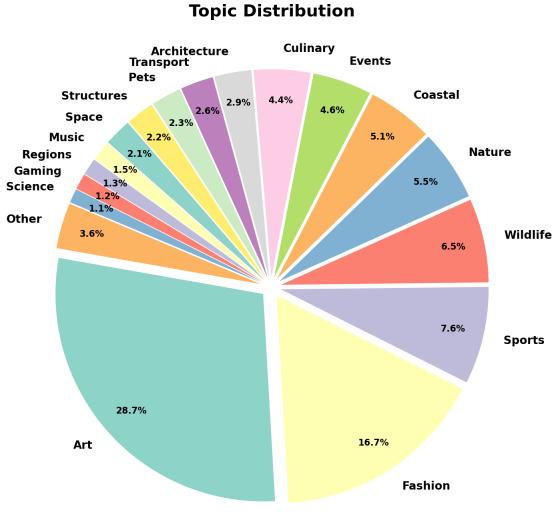
Furthermore, the topics covered are broad. Unlike datasets focused heavily on famous landmarks or celebrities (Entity-heavy), SK-VQA covers Art, Fashion, Wildlife, and Nature extensively.
4. Quality Assurance
Can we trust synthetic data? The authors conducted human evaluations to verify the quality.
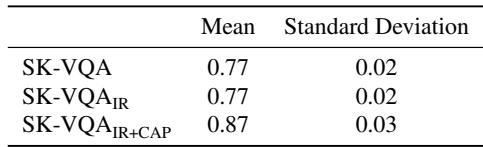
Table 3 shows that human annotators achieved high accuracy (87% on the strictly filtered set), confirming that the questions are answerable and the generated contexts are relevant. They also performed automated “LLM-as-a-judge” evaluations, finding that over 90% of the generated answers were factually correct with respect to the generated description.
Experiments: Does SK-VQA Improve Models?
The ultimate test of a dataset is whether it trains better models. The researchers performed extensive experiments using state-of-the-art MLLMs like LLaVA, PaliGemma, and Qwen-VL.
1. Zero-Shot Evaluation
First, they tested how existing “off-the-shelf” models perform on SK-VQA without any specific training.
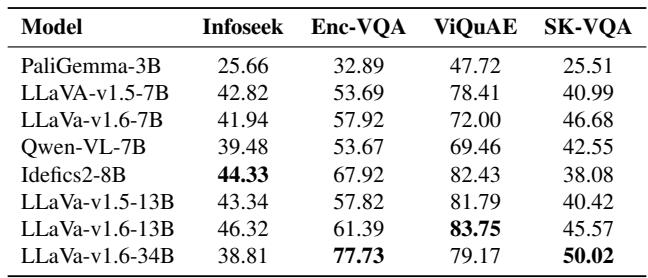
Table 4 reveals that SK-VQA is a difficult benchmark. Models like LLaVA-v1.6-34B perform relatively well on older datasets like ViQuAE (79% accuracy), but drop significantly on SK-VQA (50% accuracy). This suggests that SK-VQA captures a level of reasoning complexity that current models have not yet mastered.
2. Fine-Tuning and Generalization
This is the most critical experiment. The researchers fine-tuned models on SK-VQA and compared them to models fine-tuned on existing datasets (InfoSeek and Enc-VQA).
The goal is Out-of-Domain (OOD) Generalization. If you train on Dataset A, do you get better at Dataset B? This is the hallmark of a robust model.
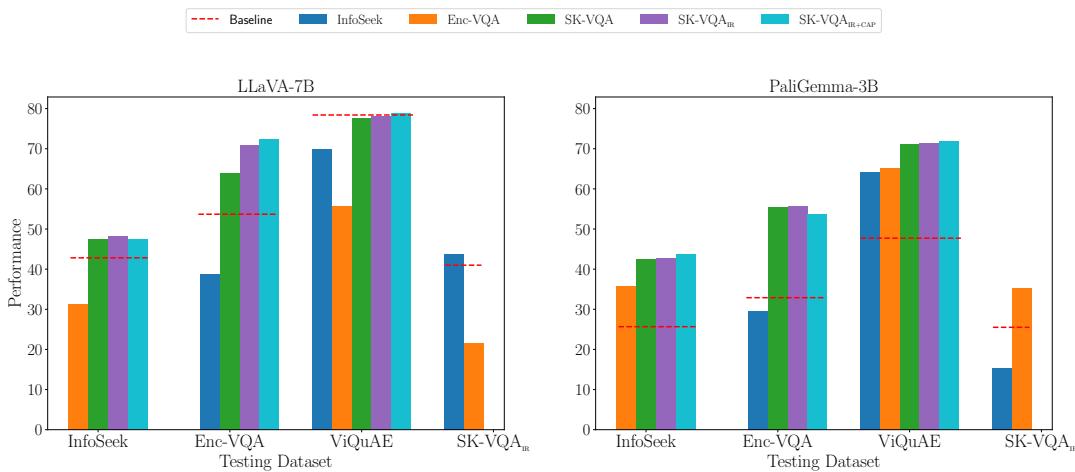
Figure 5 tells a compelling story. Let’s look at the LLaVA-7B chart on the left:
- The Red Line: The baseline performance of the model (no training).
- The Blue Bar (InfoSeek trained): Performs well on InfoSeek (in-domain), but poorly on other datasets.
- The Orange Bar (Enc-VQA trained): Good on Enc-VQA, poor elsewhere.
- The Purple/Pink Bars (SK-VQA trained): These models show consistent improvement across all datasets.
This proves that SK-VQA teaches the model a generalizable skill—how to use context—rather than just helping it memorize specific dataset patterns.
3. Real-World RAG Simulation
In the real world, you don’t always have the perfect paragraph of text handed to you. You have to retrieve it from a massive database. The researchers simulated this “Open-Retrieval” setting, where the model must pick the right information from top-10 retrieved passages.
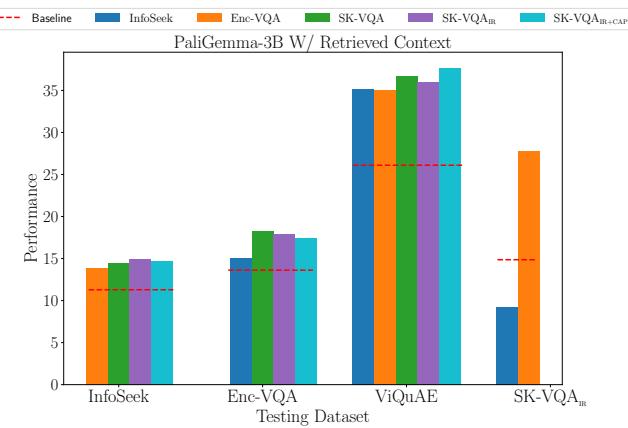
Figure 6 shows the results for the PaliGemma model in this RAG setup. The SK-VQA trained models (Purple/Pink) consistently outperform the baseline and competitors on out-of-domain tasks (ViQuAE and InfoSeek). This confirms that the synthetic training data prepares the model for the noise and ambiguity of real-world retrieval tasks.
4. Does Image Source Matter?
The authors also analyzed whether the source of the image (Wikipedia vs. LAION vs. Synthetic) impacted training.
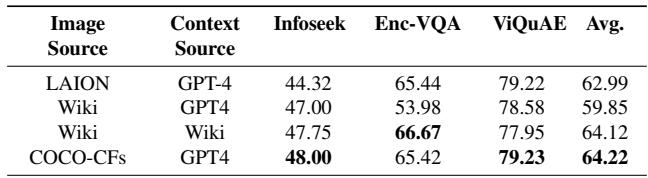
Table 5 shows an interesting finding: Training on synthetic images (COCO-CFs) paired with GPT-4 contexts (Row 4) actually yielded excellent results, comparable to or better than using real Wikipedia images. This suggests that for training reasoning capabilities, high-quality synthetic data can be just as effective as real-world data, potentially solving data privacy and scarcity issues simultaneously.
Conclusion
The SK-VQA paper presents a significant step forward for Multimodal LLMs. It addresses the “hallucination” and knowledge-gap problems by enabling effective Retrieval Augmented Generation (RAG) for vision-language tasks.
Key Takeaways:
- Synthetic Data is Viable: We can generate high-quality, large-scale training data using existing strong models (GPT-4), bypassing the limitations of web scraping.
- Diversity is King: By breaking the dependency on Wikipedia-linked images, SK-VQA introduces significantly more linguistic and visual diversity than previous benchmarks.
- Better Generalization: Models trained on SK-VQA don’t just learn the dataset; they learn the skill of context-augmented reasoning, improving their performance on entirely different datasets.
As MLLMs continue to integrate into real-world applications—from medical imaging to personal assistants—the ability to ground visual understanding in textual facts will be essential. SK-VQA provides the roadmap and the fuel to get there.
The SK-VQA dataset is publicly available on Hugging Face Hub for researchers and students interested in pushing the boundaries of multimodal AI.