](https://deep-paper.org/en/paper/2407.02987/images/cover.png)
Introduction
The rapid evolution of Large Language Models (LLMs) has brought us capable conversational assistants, coding partners, and creative writers. However, this capability comes with a significant caveat: without careful alignment, these models can generate toxic, offensive, or illegal content. While “safety tuning” (like Reinforcement Learning from Human Feedback) helps, it isn’t a silver bullet. Jailbreaks—cleverly crafted prompts designed to bypass safety filters—remain a persistent threat.
To combat this, the industry has turned to guardrails: separate, dedicated models that monitor the conversation and flag harmful content. The problem? Running a massive LLM is already computationally expensive. Running a second massive model just to police the first one is often impossible, especially on resource-constrained devices like mobile phones or laptops.
This creates a dilemma: do we sacrifice safety for efficiency, or do we limit powerful AI to massive server farms?
In a recent paper from Samsung R&D Institute UK, researchers propose an elegant solution called LoRA-Guard. By leveraging parameter-efficient fine-tuning, specifically Low-Rank Adaptation (LoRA), they have created a system that integrates content moderation directly into the chat model. The result is a guardrail system that reduces parameter overhead by 100-1000x compared to existing solutions, making robust on-device moderation a reality.
Background: The Cost of Safety
Before diving into the architecture of LoRA-Guard, it is essential to understand the current landscape of LLM safety and the specific bottleneck this paper addresses.
The Limits of Alignment
Standard LLMs undergo pre-training on vast corpora of text, followed by instruction tuning and safety alignment. Despite this, models act like “stochastic parrots”—they can be tricked. Attackers use strategies like role-playing (“Act as a villain…”), ciphering (encoding prompts in Morse code or Base64), or logical distractions to bypass safety training. This necessitates an external verification step.
The Guard Model Problem
The standard industry response is to deploy a Guard Model (like LLaMA-Guard). This is a separate LLM fine-tuned specifically to classify text as safe or unsafe.
In a server environment, this is manageable. You pipe the user’s prompt to the Guard Model first. If it passes, you send it to the Chat Model. However, for on-device AI, memory is scarce. If your phone is struggling to load an 8-billion parameter chat model, it certainly cannot load a separate 8-billion parameter guard model alongside it. This redundancy is inefficient because the chat model and the guard model share a lot of the same fundamental knowledge—they both understand English syntax, semantics, and concepts.
Enter LoRA (Low-Rank Adaptation)
LoRA is a technique originally designed for efficient fine-tuning. Instead of updating all the weights in a massive neural network during training, LoRA freezes the pre-trained weights. It then injects pair of small, trainable rank-decomposition matrices into each layer.
Mathematically, if a layer has weights \(W\), LoRA adds a small update \(\Delta W\) computed as \(B \times A\), where \(B\) and \(A\) are very narrow matrices. Because \(B\) and \(A\) are small, the number of trainable parameters drops comfortably, often to less than 1% of the original model size.
The LoRA-Guard Method
The core innovation of LoRA-Guard is the realization that we don’t need a separate model for safety. We can use the chat model’s own understanding of language to police itself, using LoRA to steer it towards moderation tasks only when needed.
The Dual-Path Architecture
LoRA-Guard employs a dual-path design. It treats the LLM as a backbone with two distinct modes of operation that share the vast majority of their parameters.
- The Generative Path: This is the standard chat mode. The input goes through the frozen transformer weights (\(W\)) and exits through the standard language modeling head to generate a response.
- The Guarding Path: This is the safety mode. The input goes through the same frozen transformer weights (\(W\)), but acts in parallel with the LoRA adapters (\(\Delta W\)). The output is then routed not to the language head, but to a specialized classification head that outputs a harmfulness score.
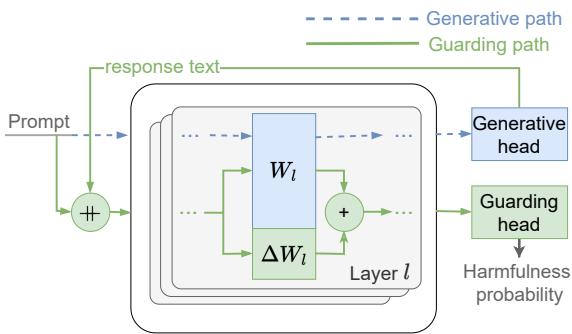
As shown in Figure 1 above, the architecture allows for a “switch” mechanism.
- When the user types a prompt, the system activates the Guarding Path (green lines). The model computes a safety score.
- If the prompt is safe, the system switches to the Generative Path (dotted blue lines). The adapters are deactivated, and the model generates a response using its original, unaltered weights.
- Finally, the system can switch back to the Guarding Path to check the model’s own response before showing it to the user.
Why This is Clever
This design solves two major problems simultaneously:
- Memory Efficiency: Since the Guarding Path shares the main transformer weights (\(W\)) with the Generative Path, you only need to load the tiny LoRA adapters and the classification head into memory. This eliminates the need for a second multi-gigabyte model.
- Performance Preservation: A common issue with fine-tuning a model for safety is “catastrophic forgetting”—the model gets so focused on being safe that it loses its ability to chat creatively. In LoRA-Guard, the base weights (\(W\)) are frozen. The generative path is literally identical to the original model, ensuring zero degradation in chat quality.
Training Strategy
The researchers trained the LoRA adapters and the classification head using the BeaverTails-30k dataset, which contains prompt-response pairs labeled with 14 categories of harm (e.g., Hate Speech, Violence, Financial Crime).
The loss function used during training is a combination of two objectives:
- Binary Classification: Is the content Safe or Unsafe?
- Multi-label Classification: Which specific categories of harm (if any) are present?
Crucially, the LoRA adapters were only applied to the Query and Key projection matrices within the attention mechanism, keeping the parameter count incredibly low.
Experiments and Results
The researchers evaluated LoRA-Guard using LLaMA-3 variants (1B, 3B, and 8B parameters) as the base models. They compared performance against state-of-the-art baselines, including LLaMA-Guard-3 (which are full-sized separate models).
Efficiency vs. Effectiveness
The most striking result is the relationship between model size and detection capability.
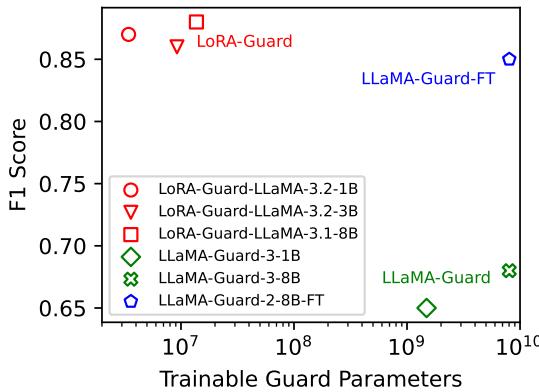
Figure 2 illustrates the efficiency breakthrough. The X-axis represents the number of trainable guard parameters (log scale), while the Y-axis shows the F1 Score (a measure of accuracy).
- The green markers on the far right represent traditional guard models (LLaMA-Guard). They require billions of parameters.
- The red markers on the far left represent LoRA-Guard models.
Notice that the LoRA-Guard models achieve similar, and in some cases superior, F1 scores while using orders of magnitude fewer parameters. Specifically, the parameter overhead is reduced by a factor of 100 to 1000. For a mobile developer, this is the difference between an app that works and one that crashes the phone.
Detailed Harm Detection
The system is not just good at a binary “safe/unsafe” toggle; it is also effective at categorizing specific types of harm.
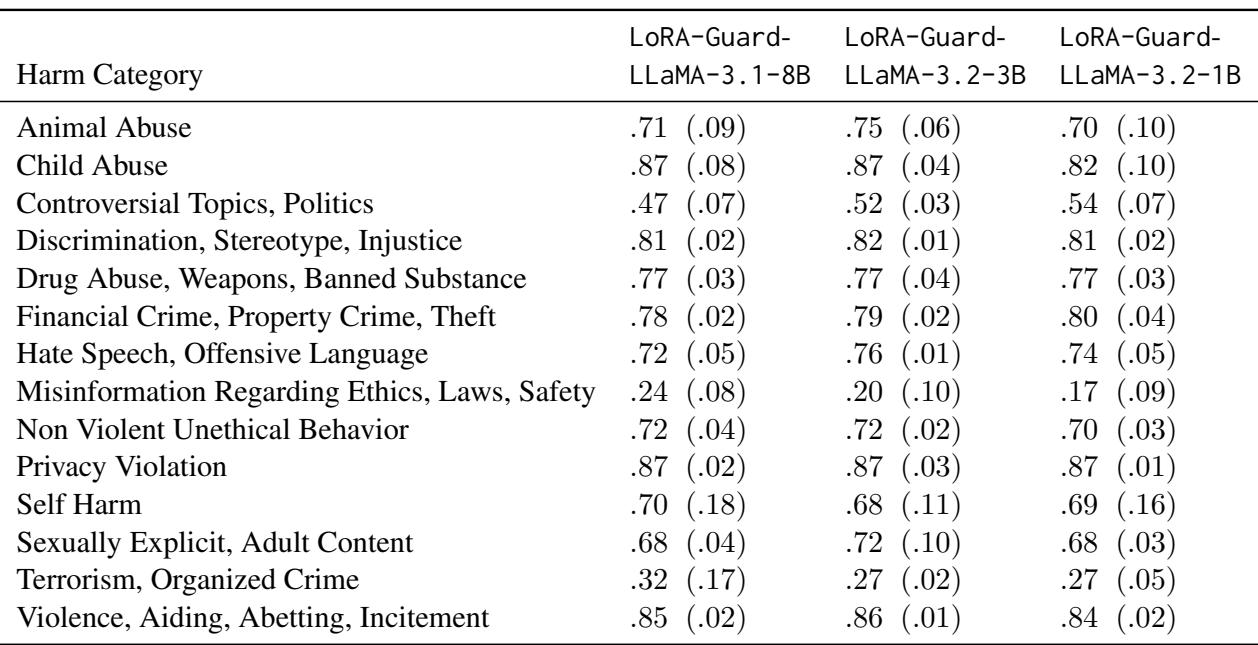
Table 2 (above) breaks down performance by category. The model shows high proficiency (AUPRC > 0.8) in detecting clear harms like Violence, Child Abuse, and Privacy Violations.
However, looking at the False Positive Rate (FPR) is equally important. A guardrail that flags everything as unsafe makes the model unusable.
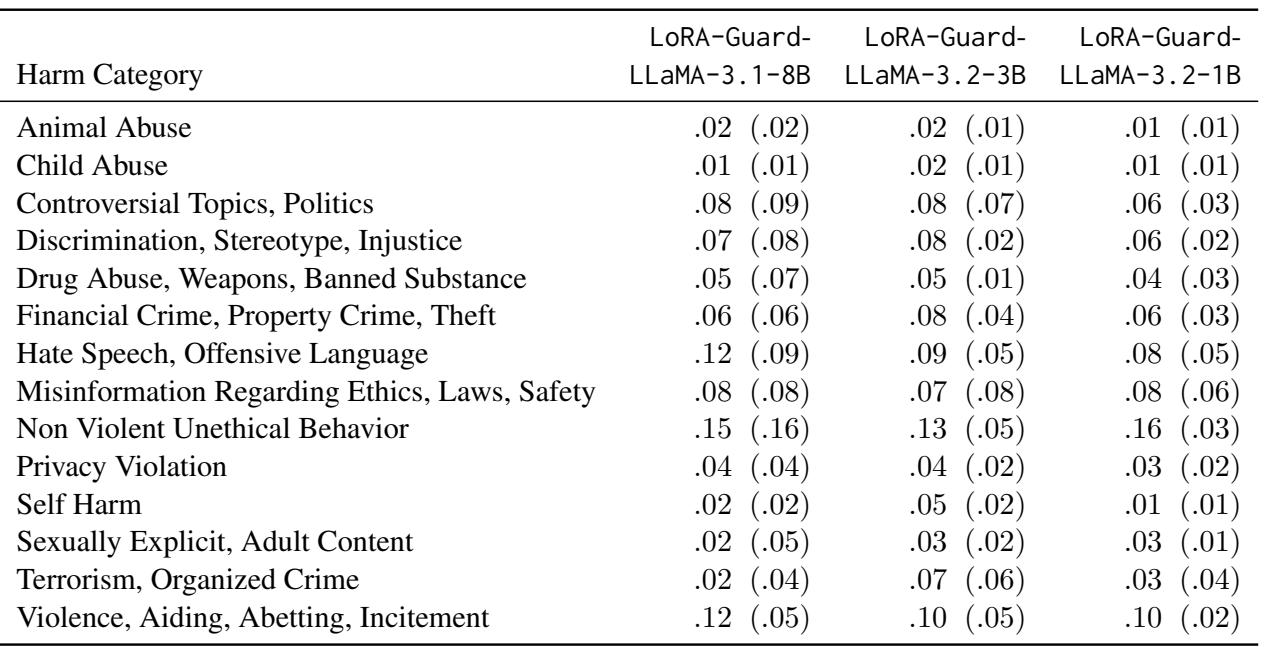
As seen in Table 3, the False Positive Rate remains very low (mostly under 5-8%) for specific categories. This indicates the model is precise: when it flags something as “Violence,” it is likely actually violence.
The Challenge of Distribution Shift
No model is perfect. The researchers tested LoRA-Guard on “Out-of-Distribution” data—datasets that look different from the one it was trained on. They used ToxicChat, a dataset of real-world user conversations which often contain slang, subtle toxicity, or jailbreak attempts.
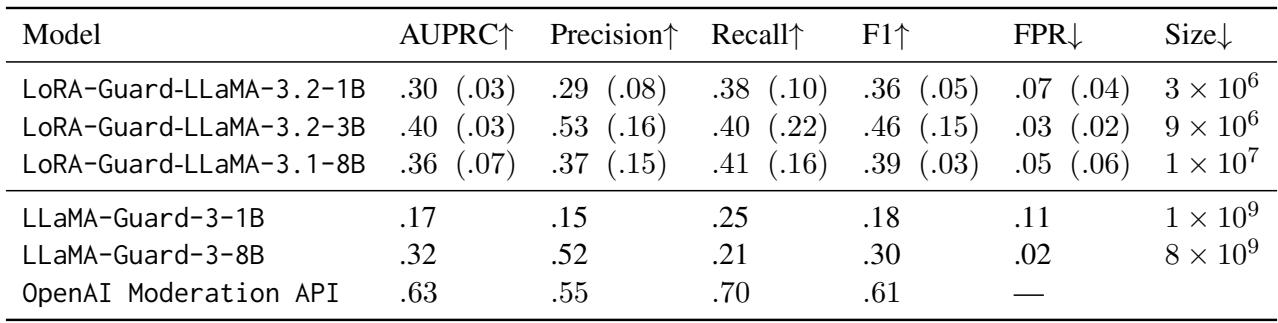
Table 5 reveals a limitation shared by almost all current safety models. Performance drops significantly when moving from the training data (BeaverTails) to the wilder ToxicChat dataset. While LoRA-Guard performs competitively against the much larger LLaMA-Guard-3 on this task, all models struggled compared to the OpenAI Moderation API. This highlights that while the architecture (LoRA-Guard) is efficient, the data used for training still needs to be diverse and comprehensive to handle real-world unpredictability.
Conclusion and Implications
LoRA-Guard represents a significant step forward for the practical deployment of safe AI. By decoupling the “guarding” capability from the “generative” capability using Low-Rank Adapters, the researchers have demonstrated that safety doesn’t have to come at the cost of massive computational resources.
Key Takeaways:
- Massive Efficiency Gains: LoRA-Guard enables content moderation with 100-1000x fewer active parameters than separate guard models.
- No Performance Penalty: Because the base model is frozen, the chat capabilities remain exactly as capable as the original model.
- On-Device Feasibility: This architecture is specifically impactful for mobile and edge computing, where loading a second model is impossible.
For students and researchers entering the field, this paper underscores the value of Parameter-Efficient Fine-Tuning (PEFT) not just for adapting models to new tasks, but for architecting systems that can multitask efficiently. As we move toward AI agents that run locally on our devices, techniques like LoRA-Guard will likely become the standard for ensuring those agents remain helpful and harmless.