](https://deep-paper.org/en/paper/2407.06322/images/cover.png)
Large pre-trained models—such as CLIP, GPT, and ViT—have become the backbone of modern AI, accomplishing feats that were unthinkable just a few years ago. Yet these systems share a fundamental weakness: they are static. Once trained on a massive but fixed dataset, they struggle to incorporate new information without losing prior knowledge. This phenomenon, known as catastrophic forgetting, stands in the way of truly adaptive and intelligent systems.
Imagine teaching an AI model to recognize bird species. It performs flawlessly with robins and sparrows. But when you later train it to identify fish, it “forgets” how to spot a robin. This conflict between new and old learning is the core challenge of continual learning (CL): enabling models to absorb new information while retaining what they already know.
Traditional continual learning methods try to prevent forgetting during training—either by regularizing important weights to stay stable or by replaying old data (which raises privacy concerns). However, a recent study titled “MAGMAX: Leveraging Model Merging for Seamless Continual Learning” by Marczak et al. proposes a refreshingly different approach. Instead of fighting catastrophic forgetting during training, MAGMAX focuses on merging and consolidating knowledge after training is complete. Its strategy combines sequential fine-tuning with a clever model merging technique based on maximum magnitude selection, achieving state-of-the-art performance across continual learning benchmarks.
Let’s unpack the key ideas behind this breakthrough.
Background: The Building Blocks of Continual Learning
Before diving into MAGMAX itself, it helps to understand some foundational ideas.
The Continual Learning Setup
In continual learning, a model encounters a sequence of tasks \( \{D_1, D_2, \ldots, D_n\} \), learning each in turn. When training on task \(D_t\), the model only sees the current task’s data—no replay or revisiting of previous tasks. This is known as an exemplar-free scenario and fits applications where retaining past data is infeasible due to privacy or storage constraints.
The challenge is to produce a single model that performs well across all previously seen tasks.
Fine-Tuning Strategies
When adapting a large pre-trained model (LPM) with original parameters \( \theta_0 \), two common fine-tuning approaches exist:
Independent Fine-Tuning (Ind FT): Each task starts from the same original pre-trained weights \( \theta_0 \), creating separate task-specific models.
Sequential Fine-Tuning (Seq FT): Each new task builds on the model trained for the previous task—training for task \(D_t\) begins from \( \theta_{t-1} \). This allows knowledge transfer across tasks but often leads to catastrophic forgetting.
Task Vectors and Model Merging
Model merging is a concept gaining traction in transfer and continual learning. Instead of retraining, we combine the updates different models have learned. These updates are captured by task vectors:
\[ \tau_i = \theta_i - \theta_0 \]Each task vector represents how the model’s weights changed when learning task \(D_i\). By combining task vectors from multiple tasks, we can create a new model that embodies the knowledge of all previous tasks—without retraining. Strategies like simple averaging or weighted interpolation have shown promise, but they often suffer from conflicts between parameter updates.
The Motivation Behind MAGMAX
The authors of MAGMAX explored two fundamental hypotheses to guide their method.
Hypothesis 1: The Largest Changes Matter the Most
During fine-tuning, some parameters change significantly while others barely move. The researchers posited that high-magnitude changes are the ones most critical for the task.
To test this, they fine-tuned a model and then pruned its task vector, retaining only a fraction of parameters—either the highest-magnitude (“top‑k”), lowest-magnitude (“bottom‑k”), or random selections.
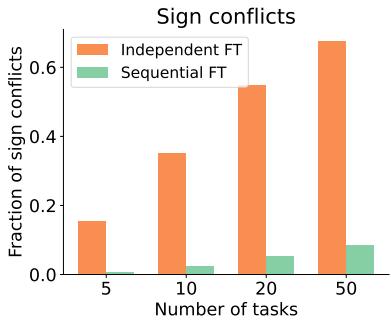
Figure 2: Retaining only 20% of the parameters with the highest magnitude yields nearly identical performance to full fine-tuning, confirming that large parameter updates are most impactful.
The results were decisive: keeping just 20% of the highest-magnitude parameters gave almost the same accuracy as using all parameters. By contrast, random or low‑magnitude selections required far more parameters for similar results. This confirmed that large weight updates capture the essence of a task’s learning.
Hypothesis 2: Sequential Fine-Tuning Reduces Conflicts
When merging models trained on different tasks, parameters can conflict—some tasks might increase a weight while others decrease it. These sign conflicts lead to interference and poor merging performance.
The authors hypothesized that sequential fine-tuning naturally reduces these conflicts because the model’s updates align across tasks.
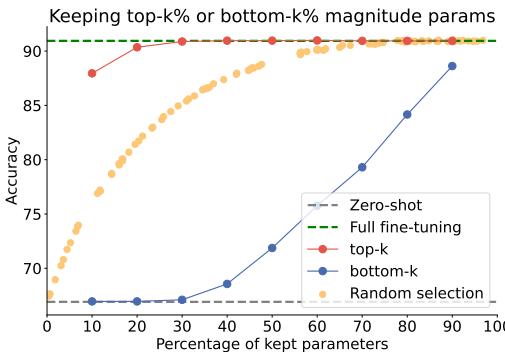
Figure 3: Sequential fine-tuning produces far fewer parameter sign conflicts compared to independent fine-tuning, making the models easier to merge.
Experiments validated this intuition: sequential fine-tuning consistently produced more harmonized task vectors with fewer sign conflicts.
The MAGMAX Method: Merging with Maximum Magnitude Selection
Armed with these insights, the researchers formulated MAGMAX—a two-step continual learning algorithm that applies sequential fine-tuning followed by maximum magnitude merging.
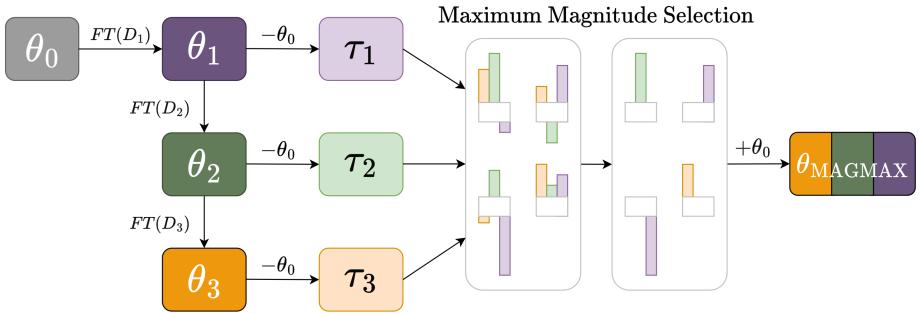
Figure 1: Overview of MAGMAX. The model is sequentially fine-tuned on successive tasks, generating task vectors. These vectors are merged using the maximum magnitude strategy to create a consolidated multi-task model.
Here’s how MAGMAX learns a new task \(D_t\):
Sequential Adaptation: The model starts from the previously fine-tuned weights \( \theta_{t-1} \) and trains on the new data, producing \( \theta_t \).
Knowledge Consolidation:
- Create task vectors for all tasks seen so far: \( \tau_i = \theta_i - \theta_0 \) for \( i = 1, \ldots, t \).
- For each parameter \( p \), select the value with the maximum absolute magnitude among all task vectors: \[ \tau^{p}_{MAGMAX} = \arg\max_i |\tau_i^p| \]
- Apply the merged task vector to the original pre-trained model, scaled by a factor \( \lambda \): \[ \theta_{MAGMAX} = \theta_0 + \lambda \cdot \tau_{MAGMAX} \]
A practical implementation stores only two objects at any time—the latest checkpoint \( \theta_t \) and the running merged vector \( \tau_{MAGMAX} \)—yielding a constant memory footprint that scales efficiently with the number of tasks.
Experiments: Putting MAGMAX to the Test
The authors evaluated MAGMAX across several benchmarks—including CIFAR100, ImageNet-R, CUB200, and Cars—comparing it against standard CL methods such as LwF and EWC, and against merging baselines like Model Soup (Avg), Task Arithmetic (TA), and TIES-Merging (TIES).
Class-Incremental Learning (CIL)
Each new task introduces new classes. The model must learn these classes while retaining performance on previously learned ones.
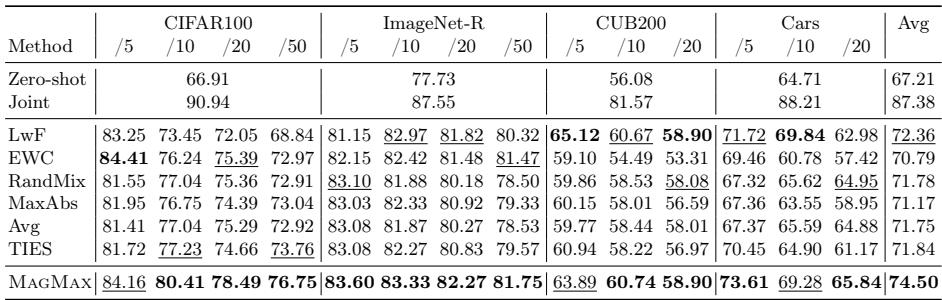
Table 1: Across CIFAR100, ImageNet-R, CUB200, and Cars datasets, MAGMAX achieves superior or second-best performance, surpassing other continual learning and merging approaches.
MAGMAX consistently outperformed other methods across varying task counts and dataset granularities, averaging a 2.1% accuracy improvement over the next best approach. Simpler baselines like ‘Avg’ and ‘RandMix’ performed unexpectedly well but still fell short of MAGMAX.
To understand how MAGMAX manages forgetting, the authors visualized task-specific performance as training progressed.
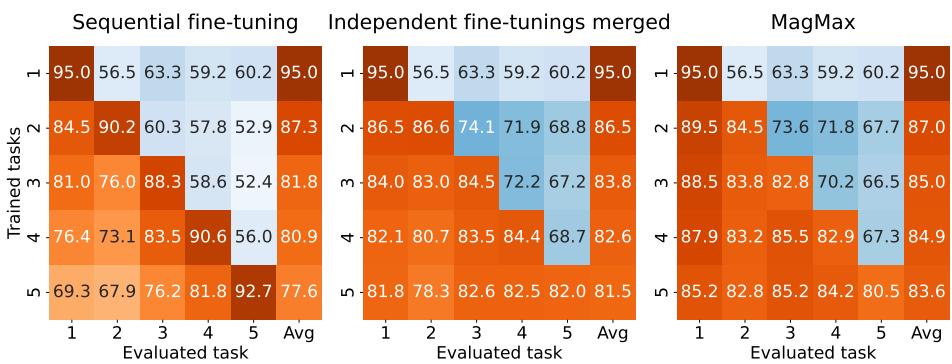
Figure 4: Sequential fine-tuning alone exhibits severe forgetting (left). Independent merges reduce forgetting (middle). MAGMAX achieves minimal forgetting and highest overall accuracy (right).
MAGMAX retains high accuracy on earlier tasks while mastering new ones, demonstrating its capacity for multi-task retention.
Domain-Incremental Learning (DIL)
In DIL, tasks share classes but differ in domains—for instance, distinguishing the same objects across sketches, photos, and paintings.
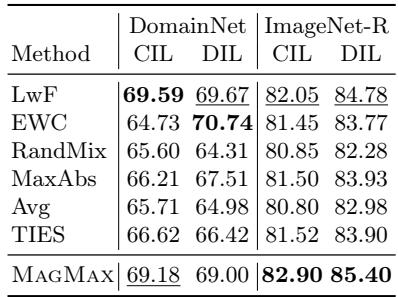
Table 2: MAGMAX outperforms other merging-based methods in domain-incremental scenarios, matching or exceeding dedicated continual learning techniques.
MAGMAX not only leads among merging strategies but also rivals traditional continual learning techniques, highlighting its robust adaptability across domains.
Why Maximum Magnitude Selection Works
The team further analyzed why choosing the highest-magnitude parameters was so effective.
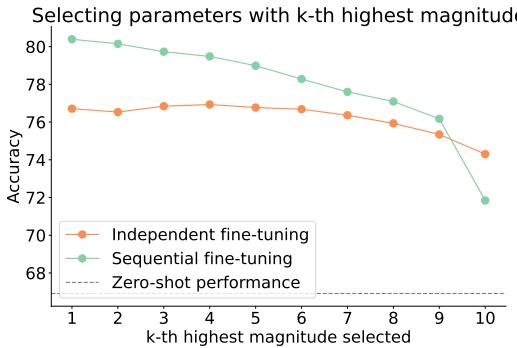
Figure 5: Selecting the absolute highest-magnitude parameters (k=1) yields the best results, especially under sequential fine-tuning.
For sequential fine-tuning, selecting the top‑magnitude parameters consistently gave the best performance. As the selection moved to lower magnitudes (higher k), accuracy dropped—showing that large updates are meaningful indicators of beneficial learning.
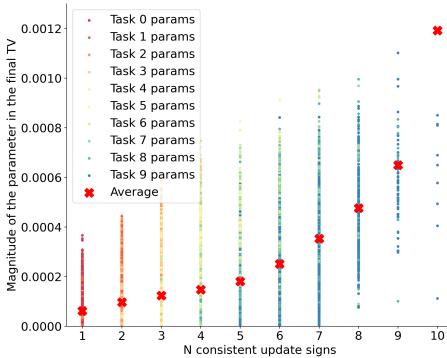
Figures 6 & 7: Parameters with consistent update directions across tasks have higher magnitudes (left). Later task vectors contribute most when merging, as they accumulate previous task knowledge (right).
Further experiments revealed strong correlations:
- Parameters consistently updated in the same direction across tasks had higher magnitudes.
- Later task vectors contributed more heavily during merging in sequential fine-tuning, confirming that knowledge accumulates as tasks progress.
Removing early task vectors had minimal effect, as their information was embedded in later ones.
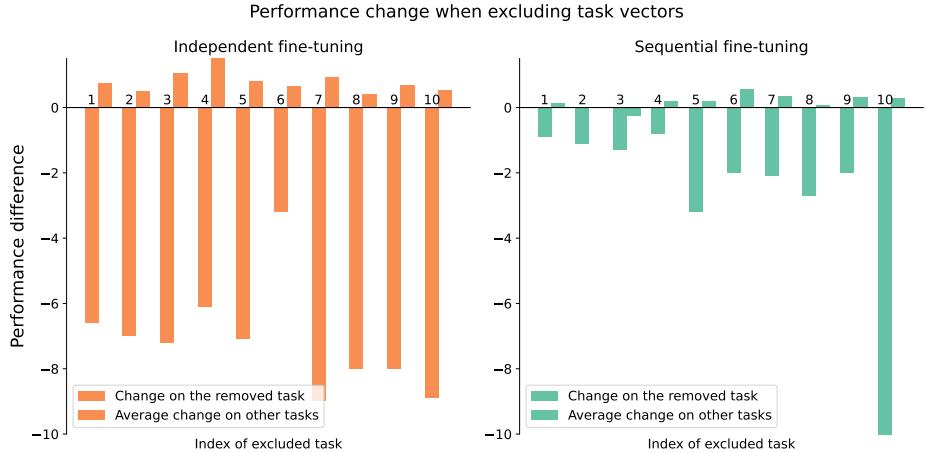
Figure 8: Sequential fine-tuning makes the model robust to excluding earlier task vectors, proving effective knowledge retention in later stages.
Extending the Idea: Improving Other Methods
MAGMAX’s principles—sequential fine-tuning and merging by maximum magnitude selection—proved valuable beyond the method itself.
1. Model Merging Boosts Existing CL Techniques
Applying MAGMAX’s merging step to traditional methods like LwF and EWC substantially improved their performance.
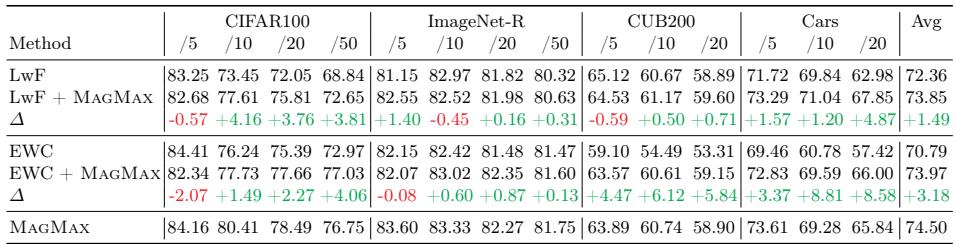
Table 3: Integrating MAGMAX’s merging step enhances regularization-based CL techniques (LwF, EWC), indicating merging effectively consolidates post-training knowledge.
2. Sequential Fine-Tuning Improves All Merging Methods
When sequential fine-tuning was combined with other merging algorithms (e.g., RandMix, Avg, TIES), performance increased across all benchmarks.
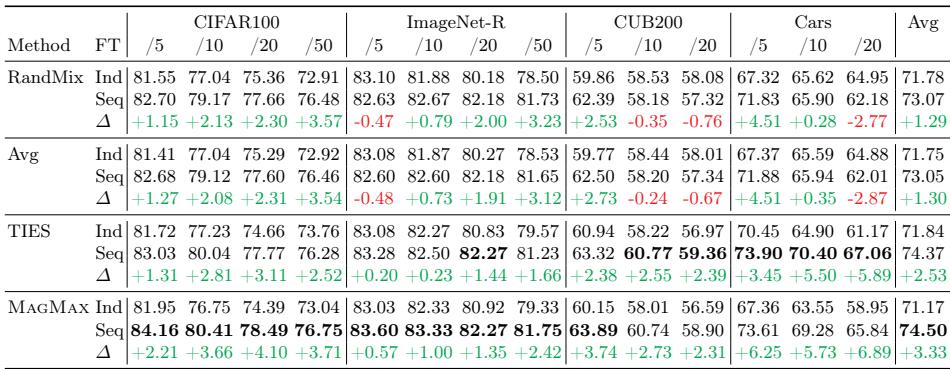
Table 4: Sequential fine-tuning consistently elevates merging outcomes across multiple strategies, underscoring its general applicability.
The synergy between sequential fine-tuning and merging by magnitude appears universally beneficial—even when tasks share little similarity.
Conclusion: A New Path for Lifelong Learning
MAGMAX introduces an elegant solution to a decades-old challenge. By shifting attention from preventing forgetting during training to consolidating knowledge after training, it redefines how large pre-trained models can learn continuously.
Two principles drive its success:
- Sequential Fine-Tuning aligns updates across tasks, reducing conflicts and preserving compatibility.
- Maximum Magnitude Selection identifies the most meaningful, consistent parameter changes across tasks.
Together, these ideas enable large models to evolve gracefully without losing their past knowledge.
The implications extend far beyond this single method. MAGMAX shows that model merging may be a cornerstone of the next generation of continual learning systems—offering simplicity, scalability, and resilience. In the pursuit of AI that never forgets, MAGMAX lights a clear and promising path forward.