](https://deep-paper.org/en/paper/2407.16920/images/cover.png)
Large Language Models (LLMs) are astonishing knowledge systems—but they have a chronic flaw: the world keeps changing, and their internal knowledge often does not. When we attempt to teach them new facts—like a recently elected leader or a novel scientific discovery—they frequently suffer from catastrophic forgetting, where learning new information causes the loss of prior knowledge. It’s like pouring water into a full cup—the new water displaces what was already there.
The field of Continual Knowledge Learning (CKL) aims to equip models with the ability to learn new facts while preserving old ones. Existing strategies—such as regularization, architectural modifications, and rehearsal-based retraining—help reduce forgetting to some extent. Yet they all rely on the same inefficient underlying assumption: every token in the training data is equally important.
Consider the model learning the sentence “The president of the US is Biden.” During training, the model invests as much effort learning the trivial grammar “The president of…” (which it already understands) as it does learning the essential factual update linking “Biden” to “US president.” This unnecessary re-learning wastes compute and can actually increase forgetting.
What if we could train a model to be a more selective learner, focusing its energy only on the most useful tokens in a document? That question motivated the paper “Train-Attention: Meta-Learning Where to Focus in Continual Knowledge Learning.” The authors propose the Train-Attention-Augmented Language Model (TAALM)—a meta-learning framework that dynamically predicts token importance. By applying adaptive “train-attention” weights, TAALM performs targeted knowledge updates, achieving faster learning and minimizing forgetting.
This post explores:
- The inefficiency at the heart of traditional continual learning.
- How Train-Attention uses meta-learning to predict “useful” tokens.
- The introduction of a new benchmark, LAMA-CKL, that reveals the trade-off between learning and retention.
- The state-of-the-art results achieved by TAALM.
The Challenge: Learning Without Forgetting
The goal of Continual Knowledge Learning (CKL) is to balance two opposing forces:
- Plasticity: The ability to absorb new knowledge quickly.
- Stability: The ability to avoid forgetting prior information.
Traditional methods fall into three families:
- Regularization: Adds loss penalties to discourage drastic parameter changes from the original model [Kirkpatrick et al., 2017].
- Architectural approaches: Freeze most parameters while training small adapter modules (e.g., LoRA, K-Adapters), reducing interference.
- Rehearsal: Mix old data with new data during training to reinforce previous knowledge.
While effective to some extent, these methods share one underlying flaw—they treat every token’s contribution to learning as equal.

Figure 1: Comparison between the standard uniform weighting (left) and Train-Attention (right), where token weights are learned dynamically to emphasize important information during updates.
In CKL settings, this inefficiency compounds because the model already knows a vast amount of world knowledge and grammar. Updating every token uniformly causes two issues:
- Increased Forgetting: Over-updated parameters distort the internal representation of previously learned facts.
- Slower Convergence: The model wastes computation relearning irrelevant or redundant content.
What if, instead, the model could selectively focus on tokens that truly update knowledge—like “Biden” in the example above? The authors hypothesized that focusing on important tokens improves CKL performance. Their experiments confirm this decisively.
The Core Idea: Train-Attention-Augmented Language Model (TAALM)
TAALM introduces a simple yet powerful modification to standard language model training: replace uniform token weighting with dynamically learned weights predicted by a meta-learner.
From Uniform Loss to Token-Weighted Learning
A regular causal LLM minimizes perplexity \( PPL_\theta \), defined as:
\[ PPL_{\theta} = -\frac{1}{N} \sum_{i} \log p(x_i \mid x_{TAALM replaces this with Token-Weighted Learning (TWL), where each token has its own weight \(w_i\):\[ PPL_{\theta}^{TW} = -\frac{1}{\sum_i w_i} \sum_i w_i \log p(x_i \mid x_{
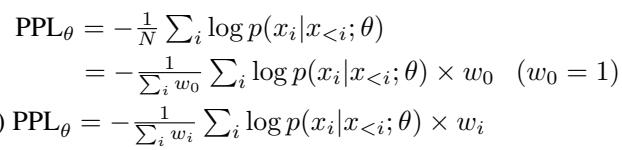
Figure 2: Standard loss (uniform weights) vs Token-Weighted Learning objective.
Token weights reflect how informative or useful a token is for the model’s downstream tasks. The question then becomes: How can the model discover which tokens are useful?
Defining Token Importance as “Usefulness”
Past token selection methods often used mistakes as signals—tokens with higher prediction errors were deemed important [Hou et al., 2022; Lin et al., 2024]. However, high error doesn’t always mean high value. Difficult tokens might represent noise, not knowledge.
The authors propose redefining token importance as usefulness—the expected utility of a token in future related tasks. Intuitively, knowing who the US president is is far more useful than reinforcing syntax.
This redefinition allows the problem to be reframed as a meta-learning task: training a model that learns how to learn which tokens are useful.
How Train-Attention Works
TAALM consists of two parts:
- Base Model (\( \theta \)) – The language model that learns knowledge.
- Train-Attention Model (\( \phi \)) – A meta-learner that predicts token importance weights.

Figure 3: (a) Train-Attention architecture replaces the LM head with a single-value “TA head” outputting a weight per token. (b) TAALM integrates Train-Attention with a base language model to perform token-weighted updates.
The Train-Attention module mirrors an LLM architecture but replaces the final linear layer with a lightweight head that outputs one scalar between [0,1] per token—its predicted weight. These weights guide the base model’s updates.
The Meta-Learning Loop
Training this meta-learner involves two alternating stages—learning and solving:
Predict weights: \( \phi \) observes data \( \mathcal{D} \) and outputs token weights \( W_{\mathcal{D},\phi} \).
Simulate update: The base model \( \theta \) is updated with one step of token-weighted training:
\[ \theta' \leftarrow \theta - \alpha \nabla_{\theta} \mathsf{TWPPL}_{\theta}(\mathcal{D}, W_{\mathcal{D},\phi}) \]Evaluate performance: Using the temporary \( \theta' \), evaluate how well the model performs on related task \( \mathcal{T_D} \), measuring loss \( \mathcal{L}_{\theta'}(\mathcal{T_D}) \).
Update meta-learner: Update \( \phi \) based on that loss:
\[ \phi \leftarrow \phi - \beta \nabla_{\phi} \mathcal{L}_{\theta'}(\mathcal{T_D}) \]

Figure 4: Meta-learning aligns token weights so that single-step updates move the base model toward the ideal task performance.

Figure 5: The system updates \( \theta \) (base) and \( \phi \) (meta-learner) alternately. Gradients flow through both components, capturing higher-order dependencies.
After every outer update of \( \phi \), the inner model \( \theta' \) is reset to its initial state, ensuring that \( \phi \) learns general weighting patterns rather than memorizing data.
Once training completes, the frozen \( \phi \) can generate token weights for any compatible LLM, enabling efficient continual knowledge updates.
A New Benchmark: LAMA-CKL
To properly test learning vs retention trade-offs, the authors built LAMA-CKL, derived from the LAMA dataset [Petroni et al., 2019]. Previous benchmarks (like TEMPORALWIKI [Jang et al., 2022]) blurred the boundary between new and old knowledge due to overlapping evidence. LAMA-CKL fixes this by providing two clearly separated sets.

Figure 6: LAMA-CKL workflow—models train on the “To-Learn” data and are tested on both To-Learn (plasticity) and Not-To-Forget (stability) tasks across epochs.
- TO-LEARN set: 500 time-variant facts the model initially gets wrong (plasticity).
- NOT-TO-FORGET set: 500 time-invariant facts the model initially gets right (stability).
Each epoch involves training on TO-LEARN evidence, followed by testing on both sets. The benchmark measures four metrics:
Top Acc, Epoch, NF Acc, and Total Knowledge (Top + NF)—the ideal system learns quickly and forgets minimally.

Figure 7: Token-weight heatmap showing Train-Attention prioritizing entity tokens over generic grammar.
Experimental Results
LAMA-CKL Performance

Figure 8: TAALM achieves rapid gains in To-Learn accuracy and maintains solid stability on Not-To-Forget accuracy.

Table 1: TAALM reaches the highest accuracy (0.429 in 4 epochs) and the greatest total knowledge capacity, surpassing all baselines.
TAALM achieved 0.429 To-Learn accuracy in just 4 epochs, triple the performance of the next best method (RHO-1) and four times faster convergence. It also preserves prior knowledge effectively—demonstrating the lowest trade-off between plasticity and stability.
How Close Is the Optimum? The Oracle Experiment
The authors tested a theoretical upper bound by assigning a perfect weight (1) only to the factual object token manually—an “Oracle” version.

Figure 9: TAALM (green) nearly matches the Oracle (orange) upper bound, achieving 78% of its maximal learning capacity.
Results show that token-weighted learning yields immense improvement over standard fine-tuning, and TAALM reaches 78.2% of the Oracle’s top accuracy—evidence that meta-learning accurately approximates optimal weighting.
Synergy with Other Methods
Because Train-Attention operates on the loss level, it integrates easily with existing techniques such as K-Adapter, Mix-review, and RecAdam. When combined, all baseline methods show enhanced learning and stability simultaneously—highlighting TAALM’s versatility.
TEMPORALWIKI Performance
TAALM also excels on TEMPORALWIKI, the standard CKL benchmark. Even though trained primarily on LAMA-CKL, TAALM generalized well across different temporal domains.

Table 2a: TAALM consistently achieves lowest perplexity across periods (0910, 1011, 1112) for both changed and unchanged knowledge.

Table 2b: TAALM maintains best performance under K-Adapter architecture, confirming robustness across architectures.
TAALM demonstrates superior results in every setting, reaffirming that learning token usefulness captures transferable patterns across datasets.
Why LAMA-CKL Matters
Existing benchmarks like TEMPORALWIKI often fail to show a clear plasticity–stability trade-off because of overlapping data and massive scale (hundreds of thousands of documents per period). LAMA-CKL resolves this by splitting variant and invariant subsets and running multi-epoch training on smaller curated data—producing clear, interpretable learning dynamics.
Conclusion and Outlook
The insight behind Train-Attention is elegantly simple: not every word deserves equal focus. By redefining token importance as usefulness and applying meta-learning to predict these weights, TAALM teaches models where to focus while learning. This leads to:
- Faster learning of new facts.
- Minimal loss of existing knowledge.
- Compatibility and synergy with prior CKL methods.
Train-Attention marks a significant advance toward adaptable LLMs that evolve as the world does. While its training depends on paired data-task examples, future research may extend this to broader domains—using search or synthetic task generation to automatically build such pairs.
By optimizing how models learn rather than merely what they learn, TAALM embodies a paradigm shift: making LLMs not just larger, but smarter learners.