](https://deep-paper.org/en/paper/2410.01036/images/cover.png)
Introduction
In the rapidly evolving world of Artificial Intelligence, “Open Source” has become a buzzword. From Large Language Models (LLMs) to Speech Foundation Models (SFMs), developers and researchers are flooded with new releases claiming to be open. But if you scratch beneath the surface, a complex problem emerges: Open Washing.
Many models release their weights (the trained parameters) but keep their training data and code proprietary. Even when data is released, it often comes with restrictive licenses—such as “Non-Commercial” or “No-Derivatives”—which strictly violates the definition of Open Source AI. For undergraduate and master’s students entering the field, this distinction is critical. You cannot build a truly open, community-driven, or commercial application if the foundation you are building on is legally shaky.
This is where the paper “MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages” steps in.
The researchers behind MOSEL tackled a massive challenge: creating a training dataset for the 24 official languages of the European Union (EU) that is 100% compliant with open-source principles. They collected nearly a million hours of speech data and, crucially, generated automatic transcripts for nearly half of it, releasing everything under permissive licenses.
In this post, we will explore why data licensing matters, how the MOSEL dataset was constructed, the clever techniques used to label massive amounts of audio, and the experimental proof that this data can train high-quality models for under-resourced languages like Maltese.
Background: The “Open Source” Definition Problem
Before diving into the dataset, we need to understand the landscape of Speech Foundation Models (SFMs). Models like OpenAI’s Whisper or Meta’s SeamlessM4T have revolutionized Automatic Speech Recognition (ASR). However, they have significant limitations regarding openness:
- Whisper: The model weights and inference code are open (MIT license), but the training data is not public. We don’t know exactly what it was trained on, which makes reproducibility impossible.
- SeamlessM4T: The model is released, but under a license that is not open-source compliant (it restricts how you can use it).
- OWSM (Open Whisper-style Speech Model): This project aimed for openness but trained on datasets like MuST-C, which has a “Non-Commercial” (NC) license. This restricts the resulting model from being used commercially.
What is True Open Source AI?
According to the Open Source Initiative (OSI), a system is only truly open source if it grants freedoms to use, study, modify, and share the system for any purpose. This implies that:
- The Code must be open.
- The Model Weights must be open.
- The Training Data must be available under an Open Source (OS) compliant license.
OS-compliant licenses include CC-BY (Creative Commons Attribution) or CC-0 (Public Domain). Licenses like CC-NC (Non-Commercial) or CC-SA (Share-Alike) are not OS-compliant because they restrict how the data (and any model derived from it) can be used or distributed.
The MOSEL project aims to fill the gap for EU languages by aggregating only data that meets these strict criteria.
Core Method: Building the MOSEL Dataset
The creation of MOSEL involves two main phases: surveying and collecting existing compliant data, and then enriching that data through pseudo-labeling.
1. Surveying Open Source Compliant Data
The researchers conducted an exhaustive survey of existing ASR datasets and unlabeled speech corpora. They applied a strict filter:
- Included: Public Domain, CC-0, CC-BY.
- Excluded: Any dataset with Non-Commercial (NC), No-Derivatives (ND), or Share-Alike (SA) clauses.
They also had to be careful about “poisoned” datasets. For example, a dataset might be released under a permissive license, but the source of the data (like YouTube videos) might have restrictive terms of service. The authors excluded datasets like GigaSpeech and MaSS because their underlying data sources (YouTube and Bible.is, respectively) did not permit unrestricted derivative works.
After this rigorous filtering, they amassed 950,192 hours of speech data.
The Distribution Problem
While the total number of hours is impressive—exceeding the data used for Whisper v2—the distribution is heavily skewed.
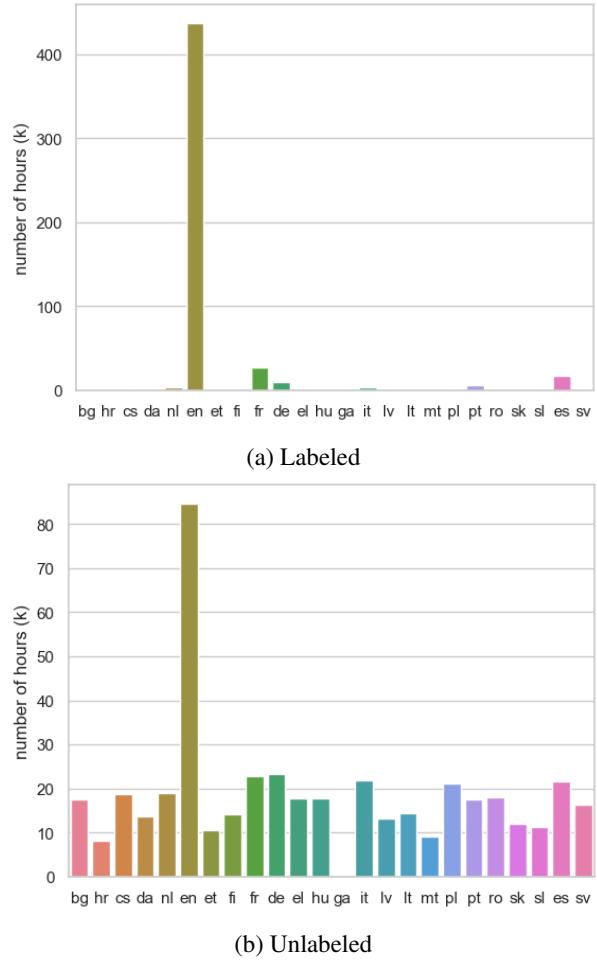
As shown in Figure 1 (top graph), the labeled data (data that comes with human transcripts) is dominated by English (en), which has over 400,000 hours. Other languages like German (de), Spanish (es), and French (fr) have decent amounts, but many EU languages have almost zero labeled data.
However, look at the bottom graph in Figure 1. This shows the unlabeled data (raw audio without text). Here, the distribution is much more balanced. Almost every language has at least 8,000 hours of audio available (except Irish). This observation is the key driver for the second part of their method: Pseudo-Labeling.
2. The Pseudo-Labeling Process
Since human-labeled data is scarce for languages like Maltese or Croatian, but raw audio is plentiful, the researchers turned to Weak Supervision, specifically pseudo-labeling.
They took 441,000 hours of unlabeled audio (primarily from the VoxPopuli and LibriLight datasets) and passed it through a powerful pre-existing ASR model to generate transcripts.
- The Teacher Model: They used Whisper Large v3. Even though Whisper’s training data isn’t open, the model weights are Apache 2.0 licensed, meaning the outputs (the transcripts) generated by the model can be released openly.
- The Scale: This process required roughly 25,500 GPU hours on NVIDIA A100s.
Green AI and Reproducibility
Why did the authors do this and release the transcripts? Why not just let every student or company run Whisper themselves?
Running 25,000 GPU hours creates an estimated 35,625 kg of CO2 emissions and would cost over $100,000 on cloud providers like AWS. By generating these labels once and releasing them under a CC-BY license, the MOSEL team prevents duplicated effort, saving money and reducing the environmental impact of AI research.
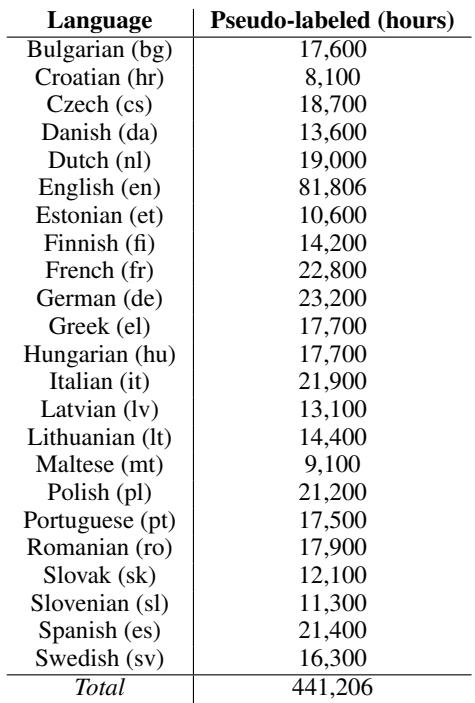
Table 4 lists the volume of pseudo-labeled data generated. This effectively turns “unlabeled” resources into “labeled” resources (albeit with slightly noisier machine-generated labels), leveling the playing field for languages other than English.
3. Addressing Hallucinations and Data Quality
One significant risk of using model-generated transcripts is that the model might make mistakes. Whisper, like many generative models, is prone to hallucinations.
In the context of speech recognition, a hallucination isn’t just a typo; it’s often a complete fabrication. If the audio has heavy background noise or long silences, Whisper might output text that isn’t there.

Table 6 provides some amusing but problematic examples.
- In row 2, the model generates a repetitive string of “No, no, no, no.”
- In other cases, models might get stuck in a loop, outputting “Amen. Amen. Amen.” or “Thank you” (e.g., “Děkuji” in Czech) repeatedly for the entire duration of a silent file.
To mitigate this, the MOSEL team implemented filtering strategies:
- Language Identification (LID): They used a model to verify that the language spoken in the audio actually matches the metadata. If a file is labeled “Maltese” but sounds like “English,” it is discarded.
- Hallucination Detection: They flagged segments containing repetitive loops or known hallucination patterns (like the “Thank you” loop) so developers can choose to filter them out during training.
Experiments & Results: The Case of Maltese
To prove that this dataset is actually useful, the authors conducted a “Proof of Concept” experiment. They chose Maltese, a Semitic language that is an official EU language but is historically very low-resource.
Why Maltese?
Maltese is a perfect stress test because:
- It has very little human-labeled data (only roughly 19 hours in MOSEL).
- Whisper performs terribly on it. As the authors noted, Whisper Large v3 has a Word Error Rate (WER) of over 70-80% on Maltese, which is practically unusable.
Experimental Setup
The researchers trained a Sequence-to-Sequence ASR model:
- Encoder: 12-layer Conformer (a hybrid of Convolutional Neural Networks and Transformers, excellent for capturing both local and global audio patterns).
- Decoder: 6-layer Transformer.
- Training Data: They compared training on just the small amount of labeled data vs. combining labeled data with the new MOSEL pseudo-labeled data.
The Results
The results were transformative.

Table 3 showcases the performance in Word Error Rate (WER), where lower is better.
- Whisper Large v3 (Baseline): Achieving a WER of 80.8 on CommonVoice and 73.8 on FLEURS. This indicates the model is mostly guessing.
- MOSEL (Labeled + Pseudo-labeled): By training on the MOSEL data, the WER drops dramatically to 39.4 and 38.9. This is practically a 50% reduction in errors compared to the giant Whisper model.
- MOSEL (Filtered): When they applied the filtering techniques discussed earlier (removing wrong languages and hallucinations), the WER dropped further to 23.8.
Interpretation
This experiment demonstrates a crucial finding for students: Data quality and quantity often matter more than model architecture.
Even though the pseudo-labels were generated by Whisper (which is bad at Maltese), the sheer volume of data, combined with the fact that the audio was valid Maltese speech, allowed the new model to learn acoustic patterns that Whisper missed. The “student” model (trained on MOSEL) significantly outperformed the “teacher” model (Whisper).
Conclusion and Implications
The MOSEL paper represents a foundational shift in how we approach Open Source AI in the speech domain. It moves beyond “open weights” to “open science,” ensuring that the entire pipeline—from raw data to final model—is transparent and legally compliant.
Key Takeaways for Students:
- License Literacy: Always check the license of your training data. “Publicly available” does not mean “Open Source.”
- The Power of Pseudo-Labeling: You don’t always need expensive human annotations. If you have enough unlabeled data and a decent teacher model, you can bootstrap high-performance systems.
- Language Equity: Resource imbalance is a major issue. English has 400k+ hours of labeled data; languages like Maltese have less than 20. Projects like MOSEL are essential for preserving and digitizing linguistic diversity.
- Green AI: Reusing computations (like transcripts) is a vital practice for sustainable AI development.
By releasing 950k hours of compliant data and 441k hours of transcripts, MOSEL provides the bedrock for the next generation of truly open EU Speech Foundation Models. It invites the community not just to download a model, but to understand, rebuild, and improve it from the ground up.