](https://deep-paper.org/en/paper/2410.05725/images/cover.png)
Introduction
The rise of Large Language Models (LLMs) like GPT-4 and Llama has revolutionized how we interact with technology. From writing code to summarizing legal documents, these models seem capable of almost anything. However, for industries dealing with highly sensitive information—such as healthcare and finance—utilizing these powerful tools presents a massive dilemma.
Hospitals want to train models on patient records to assist doctors, and banks want to analyze transaction histories to detect fraud. But this data is strictly private. You cannot simply upload patient history to a public API without violating privacy laws (like HIPAA or GDPR) and risking data leaks.
This creates a fundamental tension between utility (making the model smart) and privacy (keeping the data safe).
Currently, practitioners usually choose one of two flawed paths:
- API-Based Methods: They use powerful external APIs (like OpenAI) to generate synthetic training data. While this produces high-quality text, it requires sending private data to a third-party server, creating a privacy risk.
- Local Model Methods: They keep everything in-house using smaller, local models. While this ensures privacy, these smaller models often lack the intelligence to generate high-quality data, leading to poor performance.
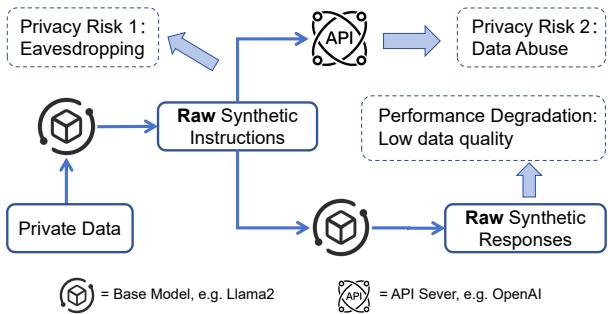
As illustrated above, we are often forced to choose between risking data privacy (Eavesdropping/Data Abuse) or accepting a “dumb” model (Performance Degradation).
In this post, we will dive deep into a new framework called KnowledgeSG (Knowledge-based Synthetic Data Generation). This approach, proposed by researchers from Zhejiang University and Shanghai Jiao Tong University, offers a clever third option: a client-server architecture that allows a local model to learn from a powerful server-side “Professional” model without ever exposing the raw private data.
Background: The Privacy-Utility Gap
Before understanding the solution, we need to understand why this problem is so hard to solve.
The Risk of Memorization
LLMs are essentially giant pattern-matching machines. If you train an LLM on a dataset containing the sentence “John Doe’s diagnosis is Type 2 Diabetes,” the model might memorize this fact. Later, if a user prompts the model with “What is John Doe’s diagnosis?”, the model could regurgitate the private information. This is known as memorization.
To combat this, researchers often use Differential Privacy (DP). In simple terms, DP adds mathematical “noise” to the training process. It ensures that the model learns general patterns (e.g., “symptoms X and Y usually mean diagnosis Z”) without learning the specific details of any single individual.
The “Kindergarten vs. PhD” Problem
Why not just train a small, privacy-preserving model locally? The issue is capability. Domain-specific data (like medical records) is complex.
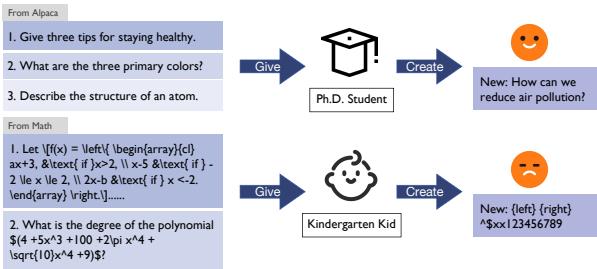
As shown in the analogy above, asking a small, general-purpose local model to generate synthetic medical data is like asking a kindergarten student to write a calculus exam. They might copy the format, but the content will be nonsense. A “PhD student” (a large, professional model) could do it easily, but that model usually lives on a cloud server, which we can’t access with private data.
The Core Method: KnowledgeSG
The researchers propose KnowledgeSG, a framework that bridges this gap. It draws inspiration from Federated Learning—a technique where you move the model to the data, rather than moving the data to the model.
The goal is to generate a high-quality synthetic dataset that captures the useful patterns of the private data but contains none of the sensitive information (Personally Identifiable Information, or PII). This synthetic data can then be used to train a powerful model safely.
System Architecture
The process is divided into two distinct environments: the Client (where the private data lives) and the Server (where the powerful “Professional” model lives).
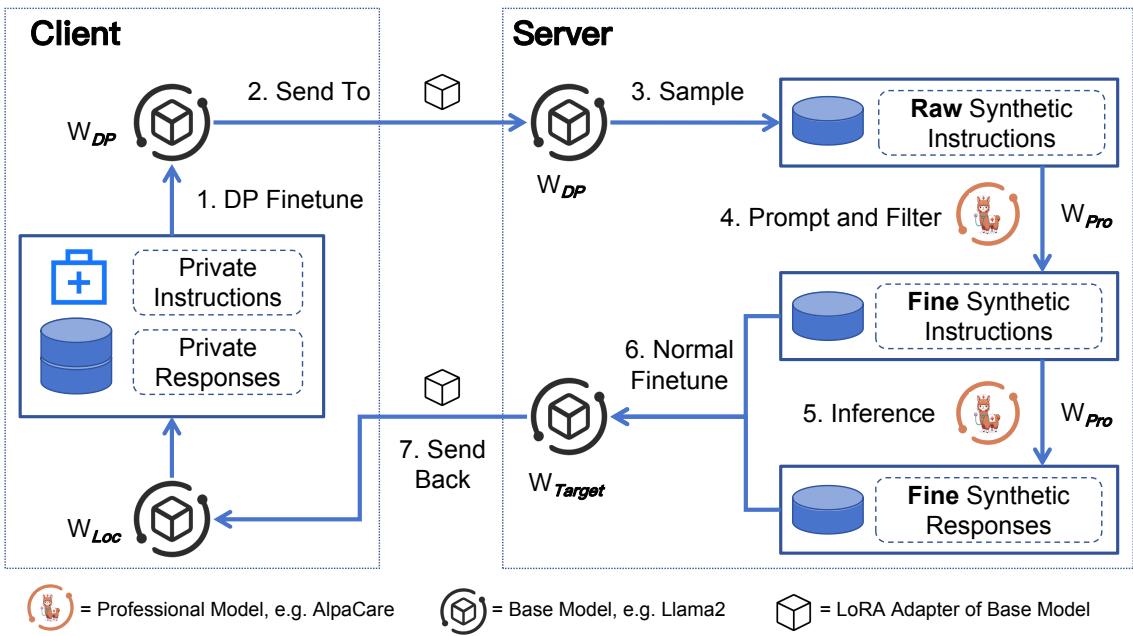
Let’s break down the workflow shown in the figure above, step-by-step.
Step 1: Client-Side Learning (DP-Fine-Tuning)
On the client side (the secure environment), we start with a local base model (\(\mathbb{W}_{Loc}\)), such as Llama-2-7B. We fine-tune this model on the private data (\(\mathbb{D}_{Pri}\)).
Crucially, this fine-tuning uses Differential Privacy (DP-SGD). This means the model learns the “shape” and topics of the private data (e.g., the structure of a doctor-patient conversation) but is mathematically prevented from memorizing specific names or sensitive details.
Step 2: Efficient Transmission (LoRA)
Fine-tuning a whole LLM is heavy, and sending a massive model over the internet is slow. To solve this, the researchers use LoRA (Low-Rank Adaptation). LoRA freezes the main model and only trains a tiny “adapter” layer.
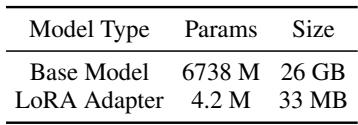
As detailed in Table 1, the difference is staggering. Instead of transmitting a 26 GB model, the client only needs to send a 33 MB adapter. This makes the communication extremely fast and efficient.
Step 3: Server-Side Generation and Filtering
Once the server receives the privacy-protected adapter, it combines it with its own copy of the base model. Now, the server has a model that “knows” what the private data looks like but hasn’t memorized the secrets.
- Generation: The server prompts this model to generate “Raw Synthetic Instructions.” These are questions or prompts similar to what users might ask in the private dataset.
- Filtration: The server generates many instructions and filters them. It can use simple metrics (like BLEU scores) to ensure the new instructions aren’t too similar to existing ones, or it can ask the Professional Model (\(\mathbb{W}_{Pro}\)) to judge if the instruction is relevant to the specific domain (e.g., “Is this a valid medical question?”).
Step 4: Knowledge Distillation ( The “Teacher” Steps In)
This is the most critical innovation of KnowledgeSG.
The local model is good at generating the questions (instructions) because it saw the private data structure. However, it is likely bad at generating correct answers (responses) because it is a smaller model and the DP noise reduces its accuracy.
To fix this, the framework uses the Professional Model (\(\mathbb{W}_{Pro}\)) residing on the server. This is a large, expert model (like AlpaCare for medicine or FinGPT for finance). The server feeds the synthetic instructions into the Professional Model to generate high-quality, accurate responses.
We now have a perfect pair:
- Instruction: Derived from the private data distribution (via the local model).
- Response: Derived from expert knowledge (via the Professional model).
Step 5: Final Optimization and Return
Finally, the server uses this new, high-quality synthetic dataset to fine-tune the local model one last time (without DP, because the synthetic data is already safe). This “Target Model” (\(\mathbb{W}_{Target}\)) is then sent back to the client.
The client now possesses a model that performs like an expert and understands their specific domain, yet the private data never left the building, and the server never saw it.
Experiments and Results
The researchers tested KnowledgeSG in two highly sensitive domains: Medicine and Finance. They compared their method against several baselines, including:
- Non-Private: Training directly on private data (the “illegal” upper bound of performance).
- ICL / Self-Instruct: Standard methods for synthetic data generation.
- DP-Gene / DP-Instruct: Previous state-of-the-art privacy methods.
Privacy Evaluation: The Reconstruction Attack
The most important metric is privacy. Can an attacker reconstruct the real patient names from the model?
To test this, the researchers performed a “Reconstruction Attack.” They masked names in the training data and tried to force the model to guess the missing name.
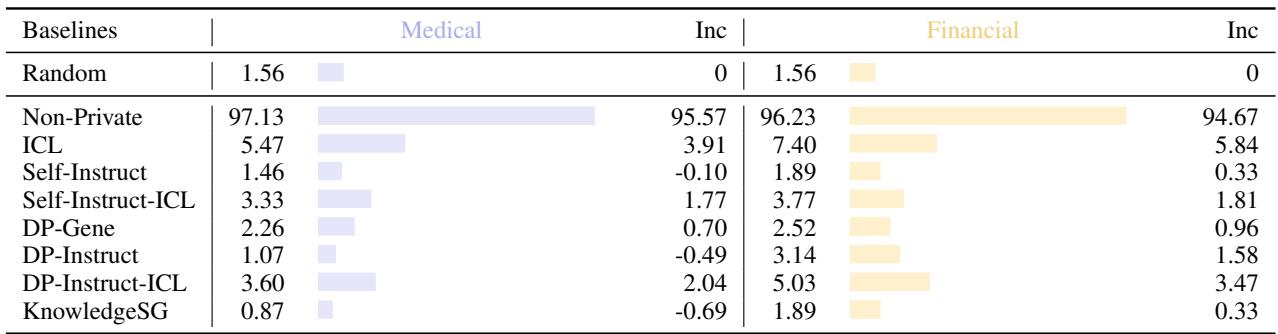
Table 2 shows the results.
- Non-Private training has a massive reconstruction rate (~97%), meaning it memorized almost everyone’s names.
- KnowledgeSG drops this to 0.87% in the medical domain—basically random guessing. It offers top-tier privacy protection, even outperforming some other synthetic data methods.
Performance Evaluation: Does the Model Actually Work?
Privacy is useless if the model becomes stupid. The researchers evaluated how well the models could answer questions and follow instructions.
Financial Domain
In finance, they tested the models on sentiment analysis tasks (determining if financial news is positive or negative).
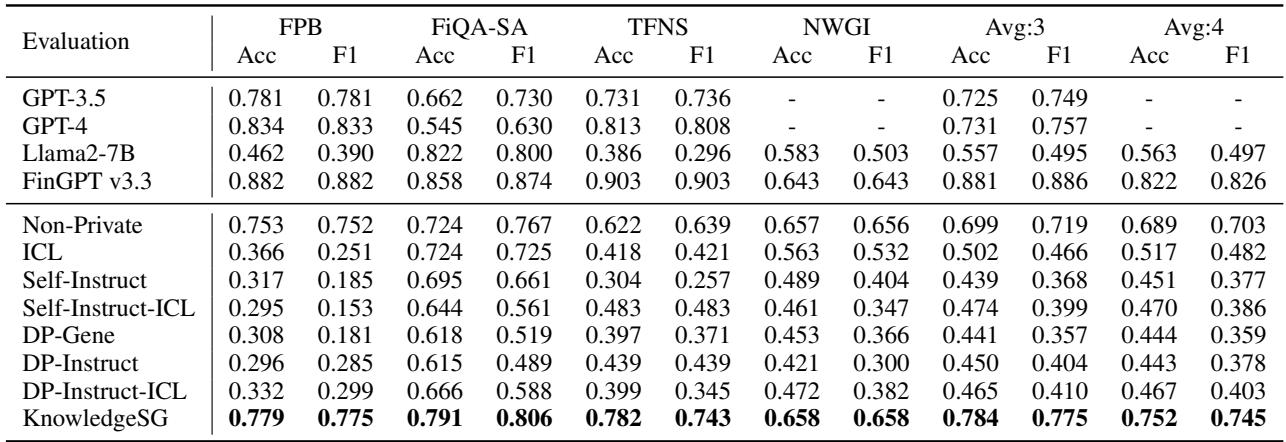
As seen in Table 3, KnowledgeSG (bottom row) dominates the other private baselines. Remarkably, it even achieves performance comparable to GPT-3.5 and GPT-4 on several benchmarks, despite being a much smaller model trained with privacy constraints.
Medical Domain
In the medical field, accuracy is life-or-death. The researchers used a “Free-form evaluation,” where they asked the models medical questions and had GPT-4 judge which answer was better (Win Rate).
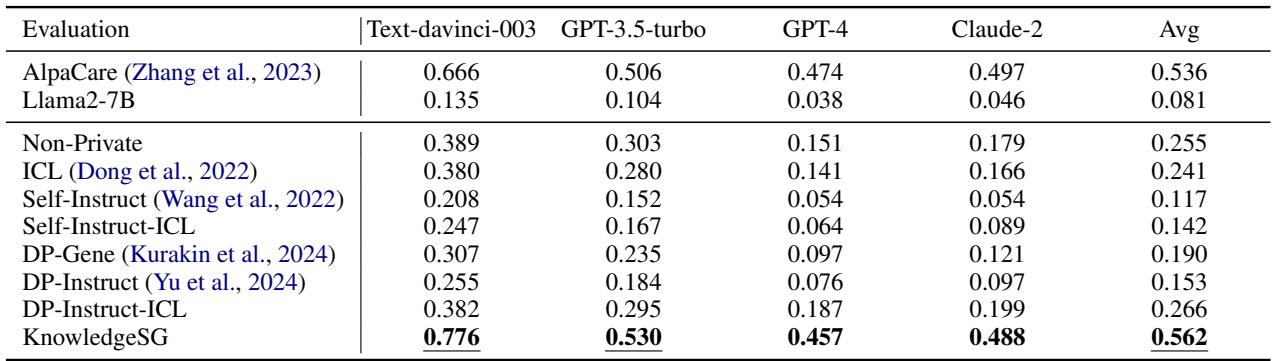
The results in Table 4 are stunning. KnowledgeSG achieved a win rate of 0.562, significantly higher than the Non-Private method (0.255). This implies that the synthetic data generated by the server-side Professional model was actually better for training than the raw, noisy private data. In fact, on some metrics, the student (KnowledgeSG) even outperformed the teacher (AlpaCare)!
Why is KnowledgeSG Better?
The researchers analyzed the quality of the synthetic data itself using a metric called IFD (Instruction Following Difficulty). A lower score means the data is cleaner and easier for a model to learn from.
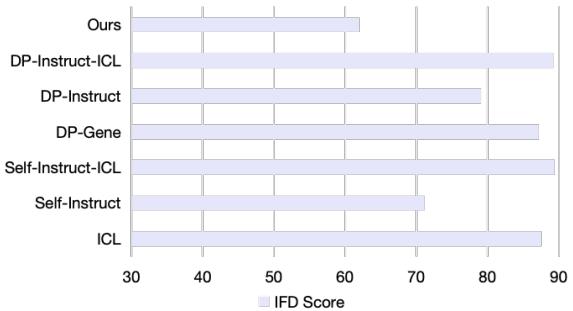
Figure 3 confirms that the data generated by KnowledgeSG (labeled “Ours”) has the lowest IFD score. By filtering bad instructions and using a Professional model to write the answers, the framework creates a “Golden Dataset” that is superior to what the local model could produce on its own.
Discussion and Implications
You might be wondering: “Why can’t we just use a program to find and delete names (scrubbing)?”
While tools exist to scrub Personally Identifiable Information (PII), they are not perfect.

Figure 4 shows how subtle PII can be. It’s not just “My name is X.” It can be “Dear Dr. Eluned,” or a doctor replying “Hi Elaine.” Automated scrubbing tools often miss these nuances (with recall rates around 80-97%), leaving dangerous gaps. KnowledgeSG avoids this entirely by never training the final model on the raw text—it only trains on synthetic text generated from mathematical weights.
Conclusion
KnowledgeSG represents a significant step forward in privacy-preserving AI. It successfully solves the dilemma of having to choose between privacy and performance.
By splitting the workload—letting the client provide the “local context” via privacy-protected weights, and letting the server provide the “intelligence” via a Professional model—we get the best of both worlds.
Key Takeaways:
- Privacy First: Differential Privacy and synthetic data generation effectively prevent the model from memorizing sensitive user data.
- Server-Side Distillation: Small local models aren’t enough. leveraging a large “Professional” model on the server to refine synthetic data creates a massive boost in quality.
- Low Bandwidth: Using LoRA adapters allows clients to upload their “knowledge” without uploading massive files or raw data.
For students and researchers entering the field of Trustworthy AI, KnowledgeSG highlights a crucial trend: the future isn’t just about building bigger models, but about building smarter architectures that allow us to use these models safely in the real world.