](https://deep-paper.org/en/paper/2410.09350/images/cover.png)
Introduction
We are living in the golden age of Large Language Models (LLMs). From ChatGPT to Claude, these models can write poetry, code, and casual conversation with frightening fluency. However, anyone who has used them for factual research knows their dirty secret: hallucinations. Because LLMs generate text based on statistical likelihood rather than a database of facts, they can confidently assert falsehoods.
To fix this, researchers often turn to Knowledge Graphs (KGs). Instead of relying solely on the model’s internal memory, we ground the conversation in a structured graph of entities and relationships (e.g., Lionel Messi – plays for – Inter Miami).
But there is a problem. Traditional methods for combining KGs with dialog systems often use a “retriever-reader” architecture that relies on external graph encoders. They compress the complex history of a conversation into a single vector representation. This creates an information bottleneck—nuance is lost, and the retrieval system often fetches the wrong facts.
Enter DialogGSR (Dialog Generation with Generative Subgraph Retrieval). In a recent paper, researchers propose a novel approach that ditches the external graph encoders. Instead, they treat the retrieval of knowledge subgraphs as a generation task. By teaching the LLM to “speak” the language of the graph, they achieve state-of-the-art results in factual dialog generation.
In this post, we will break down how DialogGSR works, exploring the concepts of Knowledge Graph Linearization and Graph-Constrained Decoding, and see why this might be the future of truthful AI conversations.
The Problem: The Information Bottleneck
Before diving into the solution, let’s understand the status quo. In a typical Knowledge Graph–Grounded Dialog system, the process looks like this:
- Input: The user asks a question (e.g., “Who starred in the movie Inception?”).
- Encoding: The system encodes the conversation history into a vector.
- Retrieval: It compares this vector against vectors representing triplets in a Knowledge Graph (using Graph Neural Networks or GNNs).
- Generation: The relevant triplets are fed to the LLM to generate an answer.
The flaw lies in step 2 and 3. Compressing a long, multi-turn conversation into a single vector is like trying to summarize a novel in one sentence; you lose the context needed to find the specific “needle in the haystack.” Furthermore, by using separate GNNs for the graph, these systems fail to utilize the massive pre-trained linguistic knowledge the LLM already possesses.
DialogGSR proposes a shift: Generative Retrieval. Instead of searching for a graph node by comparing vectors, just ask the LLM to generate the sequence of tokens that represents the relevant subgraph.
The Architecture of DialogGSR
The core philosophy of DialogGSR is that both the retrieval of knowledge and the generation of the response should be handled by the Language Model itself.
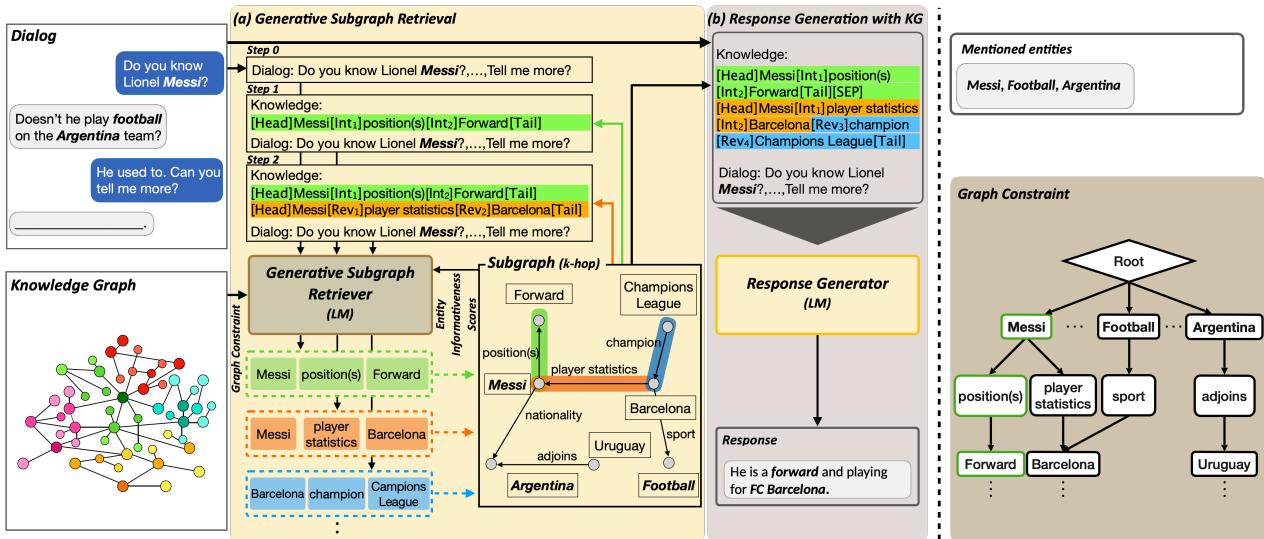
As shown in Figure 1 above, the process is split into two distinct but integrated phases:
- Generative Subgraph Retrieval (GSR): The model looks at the dialog and autoregressively generates the text representation of the relevant subgraph.
- Response Generation: The model takes the dialog and the newly generated subgraph to produce the final answer.
Let’s break down the two main innovations that make this possible: Structure-Aware Linearization and Graph-Constrained Decoding.
1. Structure-Aware Knowledge Graph Linearization
How do you feed a graph structure (nodes and edges) into a Transformer model designed for linear text? You have to linearize it.
Simple linearization might look like “Messi plays for Barcelona.” But this loses structural information, such as the direction of relationships or the distinction between entities and relations. DialogGSR introduces a set of learnable special tokens to solve this.
The researchers treat a path in the graph not just as words, but as a structured sequence:
[Head]: Marks the start of an entity.[Int](Interaction): Marks a relation.[Tail]: Marks the end of a path.[SEP]: Separates different paths.
Crucially, they also introduce a [Rev] token. Knowledge graphs are directed, but in a conversation, we often need to traverse backward (e.g., going from “Barcelona” back to “Messi”). The [Rev] token allows the model to represent these reverse relationships explicitly.
The mathematical representation of a linearized subgraph looks like this:

Here, \(z_{\hat{\mathcal{G}}}\) is the sequence of tokens representing the graph. By training these special tokens, the LLM learns to “understand” the graph structure without needing an external Graph Neural Network.
Self-Supervised Learning via Reconstruction
To ensure the model truly understands these tokens, the researchers use a “Graph Reconstruction” pre-training task. They take a valid path from the KG, mask out an entity or relation, and force the model to fill in the blank.
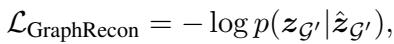
For example, if the triplet is <Scarlet Letter, written by, N. Hawthorne>, the model might see <Scarlet Letter, [MASK], N. Hawthorne> and must predict the relation written by. This teaches the model the internal logic of the Knowledge Graph before it even attempts to handle dialog.
2. Graph-Constrained Decoding
If we simply let an LLM generate graph tokens, it might hallucinate. It could generate a triplet like <Elon Musk, CEO of, Apple>, which is grammatically correct but factually wrong according to our Knowledge Graph.
To prevent this, DialogGSR uses Graph-Constrained Decoding.
When the model tries to predict the next token in the subgraph, it isn’t allowed to pick any word from its vocabulary. It is restricted to a valid set of next tokens based on the actual connections in the Knowledge Graph. This is implemented using a prefix tree (trie) constructed from the neighbors of the entities mentioned in the dialog.
The Entity Informativeness Score
However, constraints aren’t enough. A generic connection might be valid but irrelevant. To guide the model toward the most useful facts, the researchers introduce an Entity Informativeness Score.
The probability of generating a specific token isn’t just based on the language model’s preference; it’s a weighted mix of the vocabulary probability (\(p_{vocab}\)) and a graph-based probability (\(p_{graph}\)).
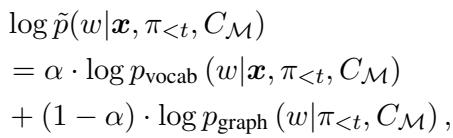
The term \(\alpha\) controls the balance. But what is \(p_{graph}\)? It is proportional to how “informative” an entity is relative to the current conversation.
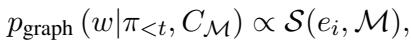
To calculate this informativeness \(\mathcal{S}\), the authors use the Katz Index, a metric from social network analysis that measures the influence of a node based on the number of walks connecting it to other nodes. This helps the model prioritize entities that are closely and strongly connected to the concepts already mentioned in the dialog.
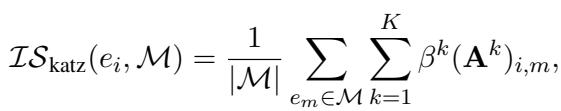
This sophisticated decoding strategy ensures that the generated subgraph is valid (it exists in the KG) and relevant (it is structurally close to the dialog topic).
Putting It Together: Response Generation
Once the subgraph is retrieved (generated), the hard work is done. The linearized subgraph \(z_{\hat{G}}\) is concatenated with the dialog history \(x\).
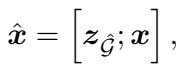
This combined input \(\hat{x}\) is fed into the response generator. Because the subgraph is now just text (albeit structured text), the standard encoder-decoder architecture of the LLM can easily attend to specific facts within the graph to construct a natural, fluent, and factually correct response.
Experiments and Results
The researchers evaluated DialogGSR on two major benchmarks for knowledge-grounded dialog: OpenDialKG and KOMODIS. They compared their approach against strong baselines, including SURGE and DiffKG.
Quantitative Performance
The results were impressive. On the OpenDialKG dataset, DialogGSR achieved state-of-the-art performance across almost all metrics.
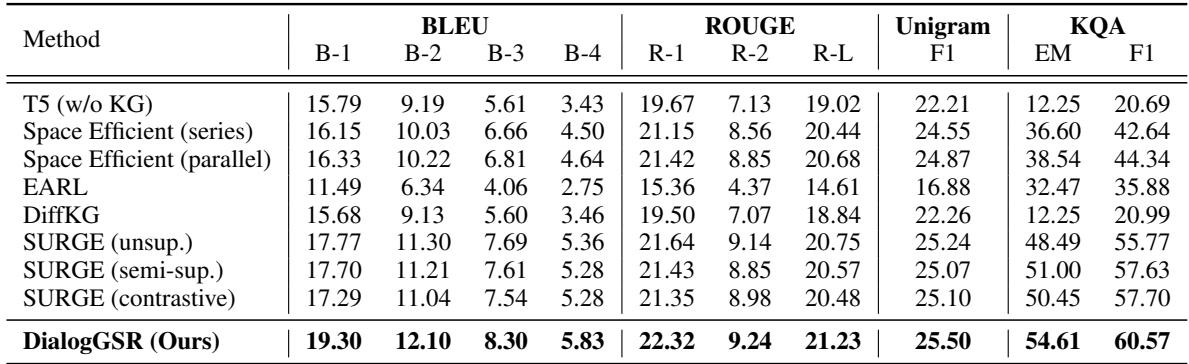
Notable takeaways from Table 1:
- BLEU & ROUGE: The model generates responses that overlap significantly more with ground-truth answers than previous methods.
- KQA (Knowledge Quality): This metric specifically measures if the correct knowledge entity was present in the response. DialogGSR scored 54.61% in Exact Match (EM), significantly higher than the closest competitor, SURGE (50.45%). This proves the model isn’t just chatting smoothly; it’s citing its sources correctly.
Solving the Bottleneck
One of the main claims of the paper was that Generative Retrieval solves the information bottleneck found in vector-based retrievers. The results support this.
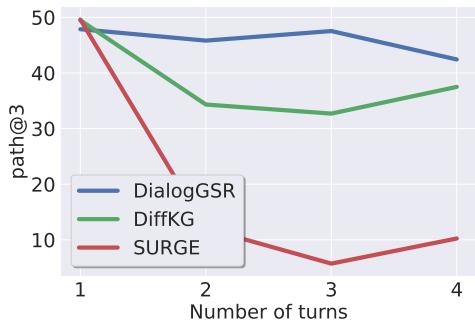
Figure 2 shows retrieval performance as the conversation gets longer (more turns).
- Red Line (SURGE): Performance collapses as the dialog lengthens. The vector representation gets “muddy.”
- Blue Line (DialogGSR): Performance remains stable and high, even at 4 turns. By interacting with the dialog history directly through generation, the model maintains context much better.
Qualitative Examples
Numbers are great, but how does it look in practice? Let’s compare DialogGSR against the baseline (SURGE) in a real scenario.

In the example shown in Table 7:
- The Context: The user asks who Mila Kunis is married to.
- The Baseline (SURGE): It gets confused by previous context (Justin Timberlake was mentioned earlier) and retrieves triplets about him. It hallucinates that Mila Kunis is married to Jennifer Lawrence (factually impossible).
- DialogGSR: It correctly identifies the relation
romantic relationshiplinked toAshton Kutcherand generates the correct answer.
Here is another example showing the precision of the retrieval:
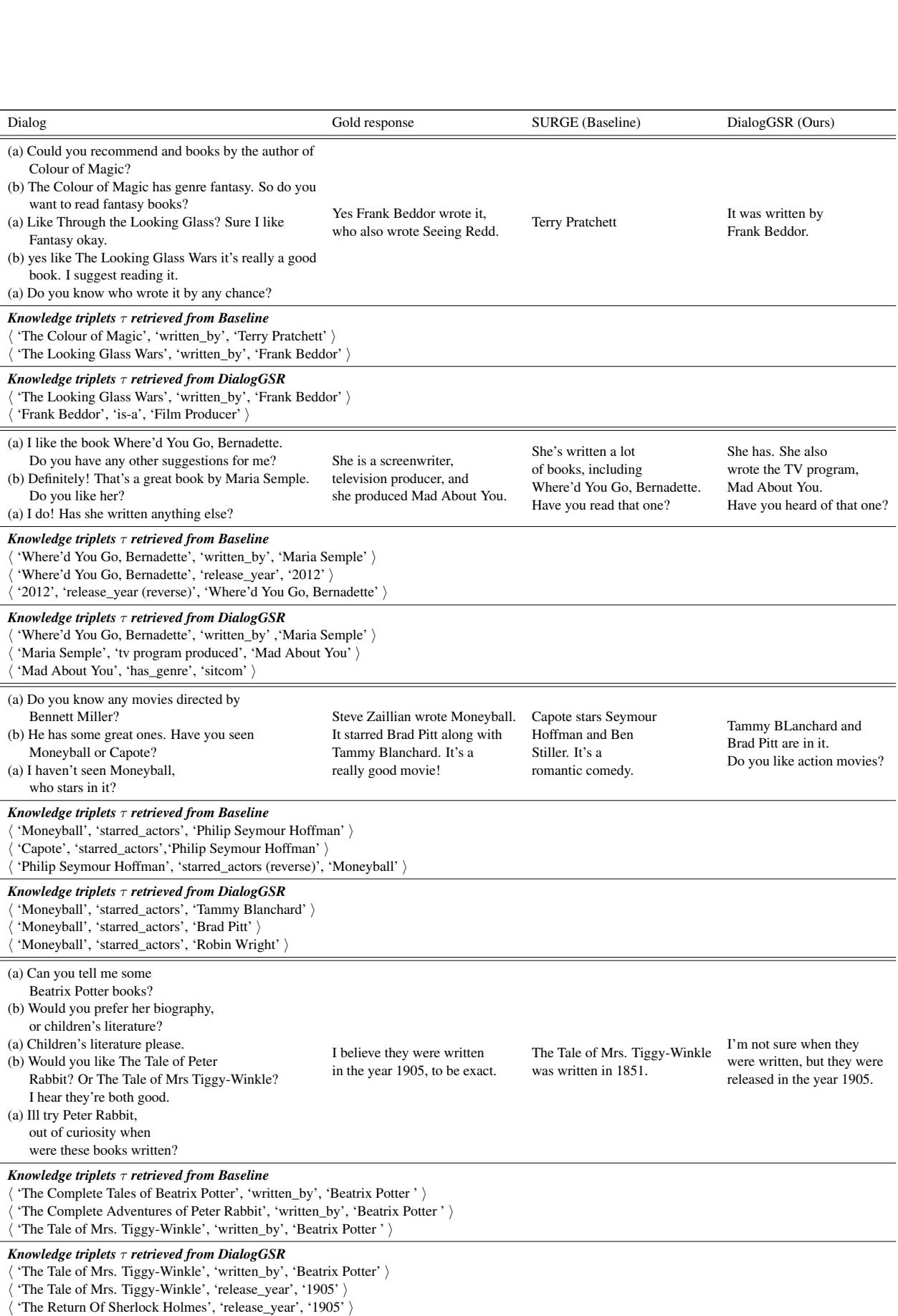
In the first row of Table 9, the user asks about the author of “The Looking Glass Wars.”
- SURGE retrieves “Terry Pratchett” (author of The Colour of Magic, mentioned previously).
- DialogGSR correctly navigates to “Frank Beddor.”
Ablation Studies
Are all these complex components necessary? The authors performed ablation studies to find out.
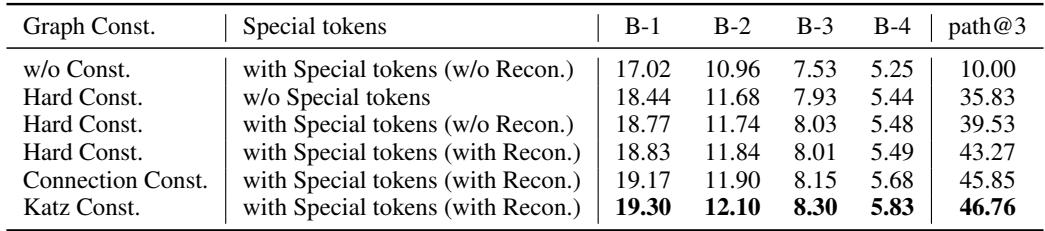
Table 5 shows that removing the Graph Constraints (w/o Const.) drastically hurts performance (BLEU-1 drops from 19.30 to 17.02). Similarly, using the Katz Index for informativeness yields better results than simple connection counts. This confirms that guiding the LLM with structural graph data is essential—you can’t just rely on the LLM’s raw generation capabilities.
Conclusion and Implications
The paper “Generative Subgraph Retrieval for Knowledge Graph–Grounded Dialog Generation” presents a compelling step forward for AI. By framing retrieval as a generation task, DialogGSR bridges the gap between the structured world of Knowledge Graphs and the fluid world of Language Models.
Key Takeaways:
- Don’t Compress: Compressing dialog history into a single vector hurts performance in long conversations.
- Speak the Graph’s Language: Linearizing graphs with special tokens allows LLMs to leverage their pre-trained capabilities on structured data.
- Constrain the Output: We cannot trust LLMs to be factual on their own. Using structural constraints (Prefix Trees + Katz Index) during decoding ensures the generated knowledge is both valid and relevant.
As we move toward AI agents that need to function in the real world—booking appointments, checking medical facts, or navigating legal databases—methods like DialogGSR that tightly couple generation with structured verification will be essential in building systems we can actually trust.