](https://deep-paper.org/en/paper/2410.09629/images/cover.png)
Introduction
Imagine you ask a state-of-the-art Large Language Model (LLM) a question about a very recent event—say, the winner of the 2024 Champions League final. Or perhaps you ask a highly specific question about a 2024 tax regulation change.
Despite their brilliance, the model might fail. It might tell you it doesn’t know, or worse, it might confidently guess the wrong team (a hallucination). This happens because LLMs suffer from three main knowledge issues: outdated knowledge (their training data has a cutoff date), domain deficits (they lack specialized knowledge like finance or medicine), and catastrophic forgetting (they lose old facts when learning new ones).
The standard solution is to feed the model new data, either by letting it look up documents (Retrieval Augmented Generation, or RAG) or by retraining it (Fine-Tuning). But there is a hidden problem: Raw text is hard to digest. Simply throwing a PDF or a news article at an LLM doesn’t guarantee it will understand or retrieve the specific fact you need.
In a fascinating new paper titled Synthetic Knowledge Ingestion: Towards Knowledge Refinement and Injection for Enhancing Large Language Models, researchers from Intuit AI Research propose a solution called Ski (Synthetic Knowledge Ingestion). Instead of forcing models to learn from raw text, Ski transforms that text into high-quality, synthetic Question-Answer pairs that are much easier for models to learn from.
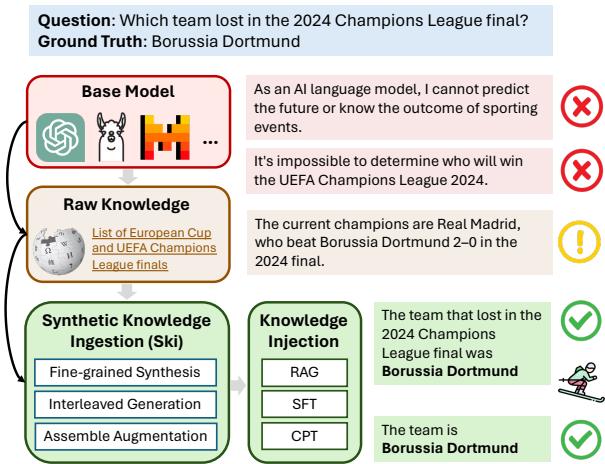
As shown above, while a standard model might fail to answer who lost the 2024 Champions League final, the Ski method processes the raw news into a Q&A format that helps the model generate the correct answer: Borussia Dortmund.
In this post, we will break down how Ski works, the mathematics behind its “ingestion” process, and how it dramatically improves performance across different AI architectures.
The Gap: Ingestion vs. Injection
To understand this paper, we first need to distinguish between two concepts:
- Knowledge Injection: This is how we put knowledge into the model. You likely know the three main strategies:
- RAG (Retrieval Augmented Generation): The model searches a database for help during a conversation.
- SFT (Supervised Fine-Tuning): The model is retrained on labeled examples.
- CPT (Continual Pre-Training): The model reads more unlabeled text to update its general knowledge.
- Knowledge Ingestion: This is what we put into the model. This is the acquisition and processing of raw data before it ever reaches the injection stage.
Most research focuses on Injection (better model architectures, better training loops). This paper argues that we are neglecting Ingestion. If we feed the model unprocessed, unstructured text, we are making its job harder. The goal of Ski is to transform raw knowledge into a “digestible” format.
Mathematically, if \(\mathcal{K}_{\mathcal{Q}}\) is our raw knowledge base, we want to apply a transformation \(\mathcal{T}\) to create a refined knowledge base \(\mathcal{K}_{\mathcal{Q}}^*\):
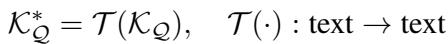
The goal is that when we inject this refined knowledge into a model \(\mathcal{M}\), the model’s score \(\mathcal{S}\) on factual questions increases:
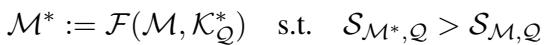
The Core Method: How Ski Works
The researchers drew inspiration from human learning. We don’t just memorize paragraphs; we ask “why” and “what.” We test ourselves with questions. Ski automates this process using a synthetic data generation pipeline.
The Ski method consists of three key innovations: Fine-grained Synthesis, Interleaved Generation, and Assemble Augmentation.

1. Fine-grained Synthesis (The “N-Gram” Strategy)
If you have a long document, how do you create good questions from it? If the question is too broad, it misses details. If it’s too specific, it loses context.
Ski solves this using an n-gram strategy (where \(n\) represents the number of sentences). Instead of looking at a whole document, the system looks at a sliding window of sentences (1 sentence, 2 sentences, etc.) and uses a “teacher” LLM to generate hypothetical questions for that specific chunk.
For a set of sentences \(\{k_j, ... k_{j+n-1}\}\), the model generates a question \(q^n\):
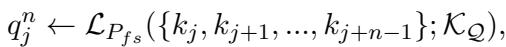
This creates a massive set of hypothetical questions mapped to specific slices of the text. This is much more precise than asking a model to “summarize this page.”
2. Interleaved Generation (Harmonizing Q and A)
Sometimes, simply having a question and a text chunk isn’t enough. For Supervised Fine-Tuning (SFT), models need concise, direct answers, not long paragraphs of context.
Ski uses Interleaved Generation to create aligned Question-Answer (QA) pairs. It prompts a model to generate the question and the answer simultaneously based on the text slice. This mimics the natural information-seeking process.
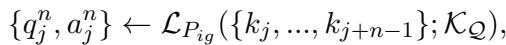
This results in a dataset of pairs \(\{\tilde{Q}^n, \tilde{A}^n\}\) where the answer is perfectly tailored to the question, removing the noise found in the original raw text.
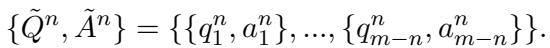
3. Assemble Augmentation (Diversity + Repetition)
Effective learning requires repetition, but rote memorization leads to overfitting. To solve this, Ski uses Assemble Augmentation.
It combines the data generated from different n-gram levels (1-sentence chunks, 2-sentence chunks, etc.). This means the model sees the same fact represented in multiple different ways—sometimes as a detailed question about a specific sentence, sometimes as a broader question about a paragraph.
For RAG applications, Ski creates “augmented articles” where questions and contexts are stitched together:
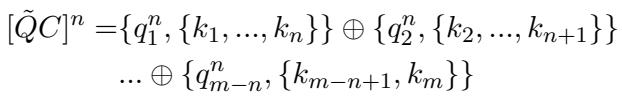
For Fine-tuning (SFT), it creates a union of all QA pairs across different n-grams:
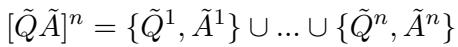
This creates a dataset that balances repetition (reinforcing the fact) with diversity (asking about it in different ways).
Implementing Ski: The Injection Pipelines
Once the data is synthesized, how is it used? The authors integrated Ski into the three standard pipelines mentioned earlier.
RAG with Ski
In a standard RAG setup, a user asks a question, and the system searches for a raw document snippet. With Ski-RAG, the system searches the synthetic data.
- Ski-Q: The system searches for a synthetic question that matches the user’s query (Question-to-Question matching).
- Ski-QC-ASM: The system searches through the assembled Question-Context pairs. This often works better because the synthetic questions contain keywords that might be missing from the raw text, bridging the “semantic gap.”
SFT with Ski
Here, the model is trained directly on the Ski-QA (Question-Answer) or Ski-QC (Question-Context) datasets. The experiments focused on whether training on these clean, synthetic pairs was better than training on raw text or “vanilla” QA pairs generated without the n-gram strategy.
CPT with Ski
For Continual Pre-Training, the model is fed the assembled datasets (Ski-QC-ASM or Ski-QCA-ASM) in an unsupervised manner, allowing it to absorb the structures and facts before being fine-tuned.
Experiments and Results
The researchers tested Ski on tough datasets including FiQA (Finance), BioASQ (Biomedical), and HotpotQA (Multi-hop reasoning). They used Llama2-7B and Mistral-7B as the base models.
1. RAG Performance
The results for Retrieval Augmented Generation were striking. The team compared Ski against standard retrieval (finding raw articles) and “Inverse HyDE” (a method where you search via hypothetical document embeddings).
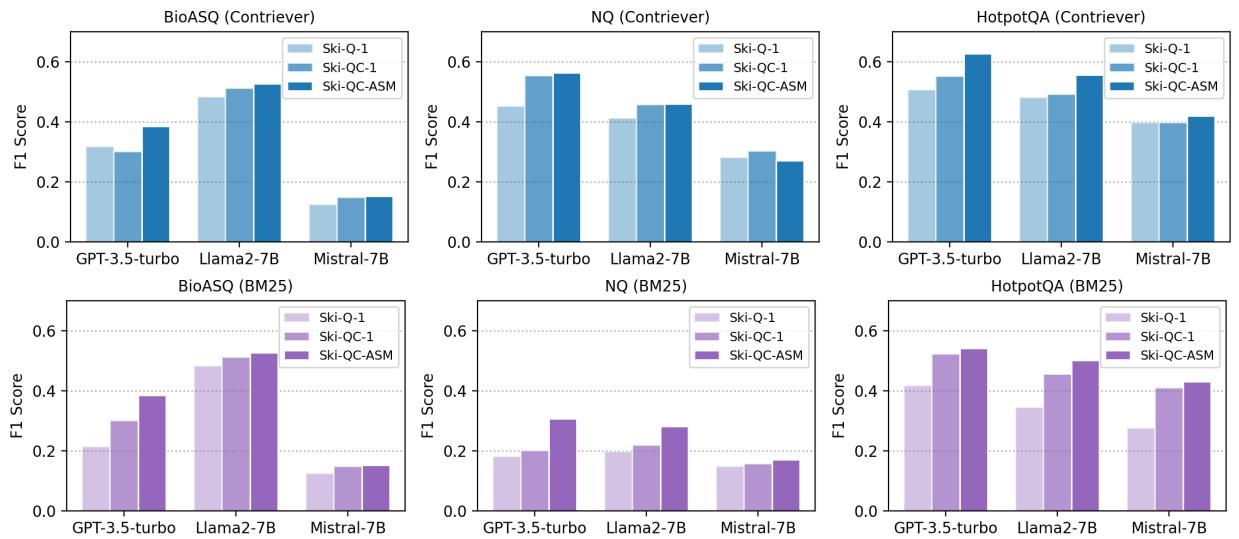
Key Takeaway: Look at the chart above. Ski-QC-ASM (the darkest bars) consistently outperforms the other methods.
- By retrieving the “Question + Context” block, the model gets the best of both worlds: the keyword matching of a question and the factual detail of the context.
- It significantly outperformed searching for raw articles (the “Contriever” baseline in the paper’s tables).
2. SFT Performance
Can a model learn facts just by being fine-tuned on Ski data? Yes.
The researchers found that training on Ski-QA-1 (1-gram Question-Answer pairs) yielded the best results for Supervised Fine-Tuning. This suggests that for fine-tuning, models prefer concise, direct Q&A pairs over longer context blocks.
Interestingly, the “n-gram” size mattered significantly.
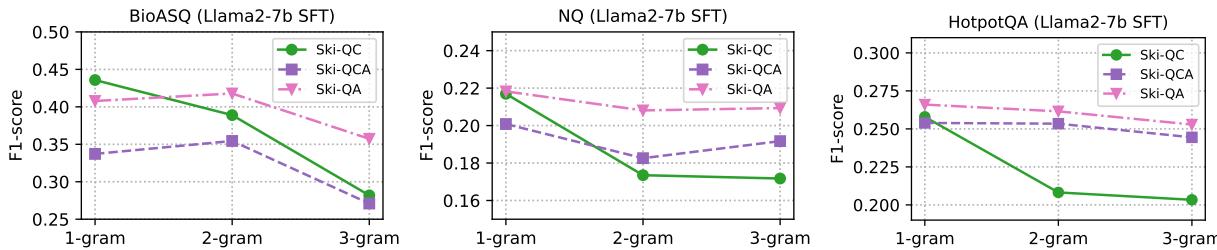
In the graph above, notice the downward trend. 1-gram (fine-grained) synthesis generally performs better than 2-gram or 3-gram. This confirms the hypothesis that breaking knowledge down into its smallest atomic units (fine-grained synthesis) helps the model learn more effectively than feeding it large chunks.
3. Overall Comparison: RAG vs. SFT vs. CPT
Finally, the paper asks the big question: Which injection method benefits the most from Ski?
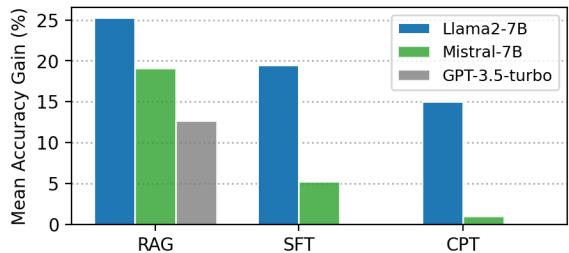
The chart above shows the relative performance gain over the base model:
- RAG (Left): Shows the massive gains. Ski transforms RAG from a “lookup” tool into a highly accurate knowledge engine.
- SFT (Middle): Shows strong improvements, particularly for Llama2-7B.
- CPT (Right): Shows modest gains. It seems that simply reading the data (pre-training) is less effective than being forced to answer questions about it (SFT) or retrieving it dynamically (RAG).
Conclusion and Implications
The Synthetic Knowledge Ingestion (Ski) paper shifts the conversation from “how do we build better models?” to “how do we build better data?”
By using Fine-grained Synthesis to break text down, Interleaved Generation to align questions with answers, and Assemble Augmentation to create diverse datasets, Ski allows LLMs to “digest” complex information that they would otherwise miss.
Key Takeaways for Students:
- Data Representation Matters: Raw text is not the optimal format for machines to learn facts. Q&A pairs are superior.
- Granularity is Key: Generating questions from single sentences (1-gram) often works better than generating them from whole paragraphs.
- Ingestion before Injection: Before you decide whether to RAG or Fine-tune, focus on processing your source data.
As LLMs continue to integrate into specialized fields like law, medicine, and finance, methods like Ski will be essential for ensuring that these generalist models can become reliable specialists.