](https://deep-paper.org/en/paper/2410.15182/images/cover.png)
The original promise of social media was a utopian one: a digital town square where we would untap our “virtuous selves,” seek new knowledge, and form connections across cultural divides. If you have spent any time online recently, you know that reality has taken a different turn. Instead of connection, we often find polarization, echo chambers, and toxicity.
To date, the vast majority of computer science research regarding online discourse has played defense. Researchers build models to detect “bad” things: hate speech, misinformation, and political polarization. While this is necessary, it is only half the battle. To truly improve online discourse, we can’t just suppress the negative; we must cultivate the positive.
This brings us to a fascinating research paper titled “The Computational Anatomy of Humility: Modeling Intellectual Humility in Online Public Discourse.” In this study, researchers from Dartmouth College and Northeastern University pivot the conversation from detecting toxicity to detecting virtue. Specifically, they focus on Intellectual Humility (IH)—the ability to acknowledge the limitations of one’s own beliefs.
This article explores how these researchers defined the “anatomy” of humility, built a massive codebook to measure it, and tested whether state-of-the-art Artificial Intelligence (specifically Large Language Models like GPT-4) is capable of recognizing this subtle human trait.
The Core Problem: Why Humility Matters
Before diving into the algorithms, we need to understand the social science. Intellectual Humility isn’t just about being modest; it is a cognitive virtue. It involves owning your limitations and welcoming diverse perspectives.
Social science tells us that high levels of IH are associated with:
- Higher scrutiny of misinformation.
- Less political “my side” bias.
- Reduced “affective polarization” (the tendency to dislike people just because they belong to a different group).
The researchers chose to study this in a very specific, high-stakes context: online religious discourse. Religion is a domain deeply tied to identity, where objective “truth” is subjective, and where the clash between science, faith, and differing dogmas often leads to conflict. If we can detect and foster humility in religious debates on Reddit, we can likely do it anywhere.
Part 1: Building the “Anatomy” of Humility
You cannot train a computer to detect something you haven’t clearly defined. The first major contribution of this paper is the creation of a rigorous IH Codebook—a taxonomy of what humility (and its opposite, Intellectual Arrogance) actually looks like in text.
The researchers didn’t just guess these definitions. They employed a multi-step, iterative process involving both human expertise and AI assistance.
The Workflow

As shown in the flowchart above, the process was methodical:
- Data Collection: They scraped posts from 48 religion-focused subreddits (like r/Christianity, r/Islam, r/Buddhism), resulting in over 17,000 posts.
- Defining the Codebook: They combined academic literature on psychology with categories suggested by GPT-3.5 to create an initial list of labels.
- Refining the Codebook: Two human annotators applied these labels to real posts, calculated how often they agreed (inter-annotator agreement), and refined the definitions until they reached a high level of consensus.
Filtering the Signal from the Noise
Initial brainstorming yielded a massive list of potential “tags” for humility and arrogance—55 in total. This was too noisy for a reliable study. The researchers had to merge similar concepts and remove vague ones.
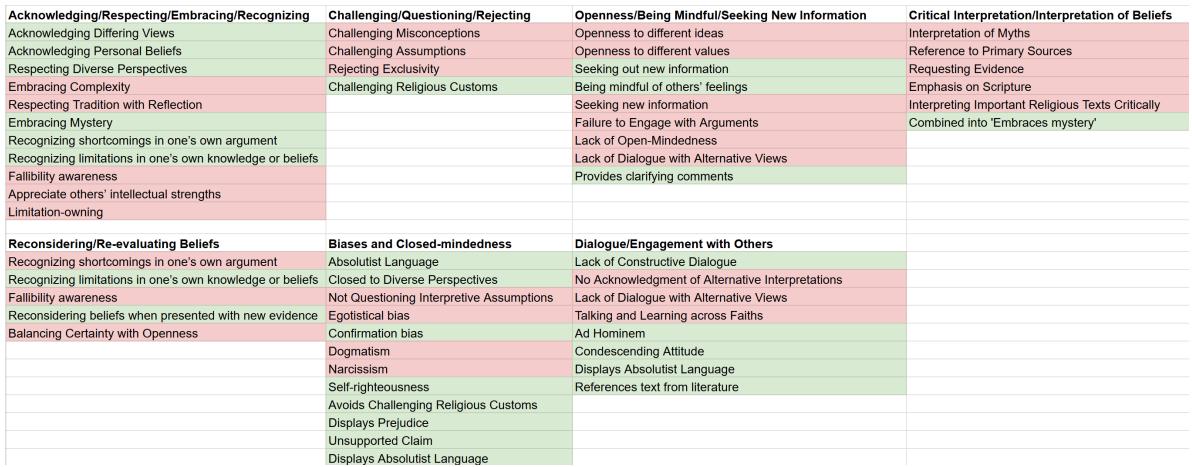
The figure above illustrates this consolidation process. For example, specific terms like “Openness to different ideas” and “Seeking new information” were refined into broader, distinct categories. Terms that were too specific or hard to prove (like “Narcissism” or “Self-righteousness”) were eliminated or merged into more observable behaviors like “Condescending Attitude.”
The Final Codebook
The result of this rigorous process was a final codebook containing 12 Intellectual Humility (IH) labels and 13 Intellectual Arrogance (IA) labels.
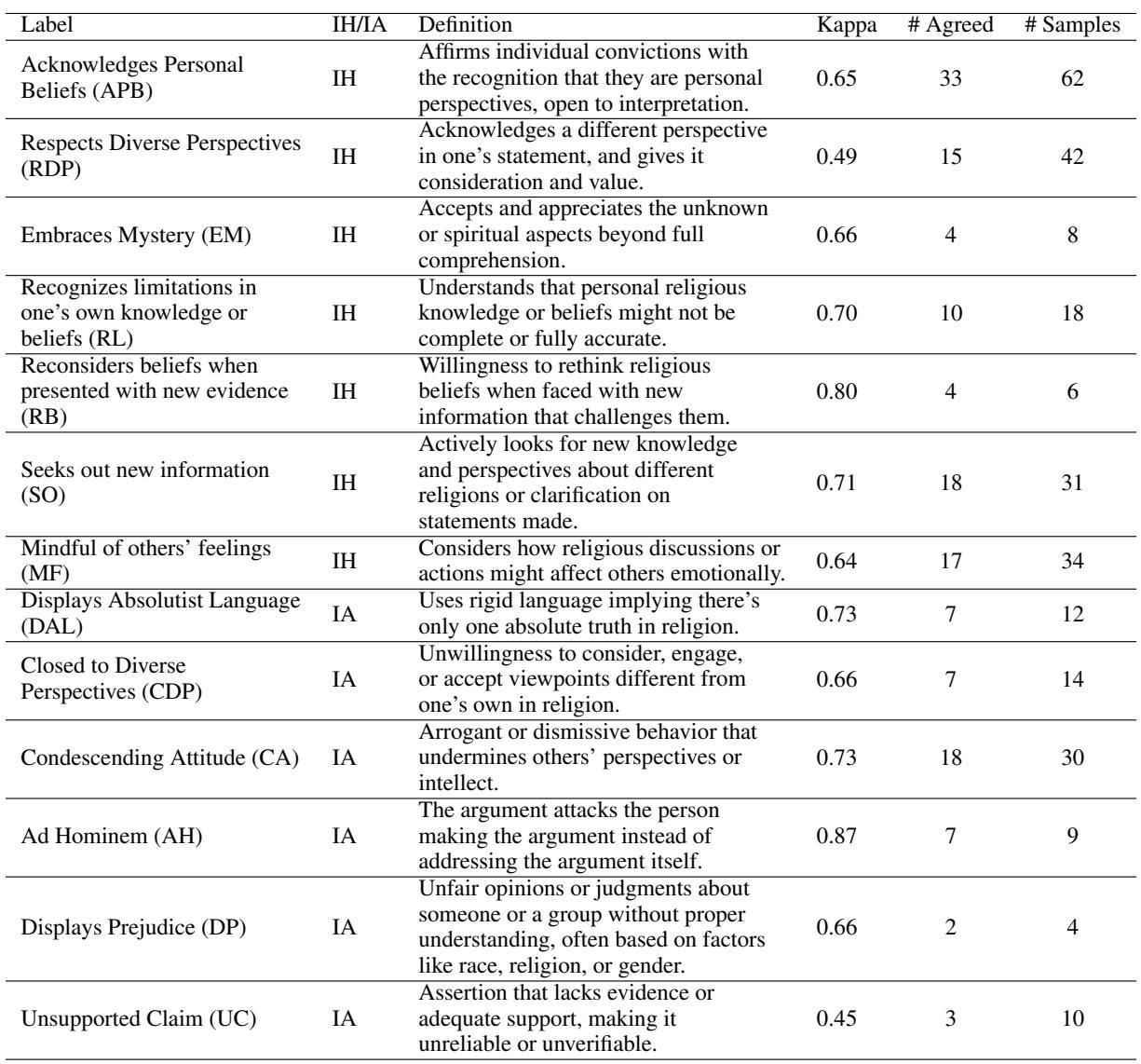
This table is the heart of the “computational anatomy.” It breaks down abstract virtues into detectable text features.
Examples of Intellectual Humility (IH):
- Acknowledges Personal Beliefs (APB): Phrasing statements as personal convictions rather than objective facts (e.g., “In my view…” vs “The truth is…”).
- Embraces Mystery (EM): Accepting that some spiritual aspects are beyond human comprehension.
- Seeks Out New Information (SO): Asking questions to clarify or learn, rather than to trap an opponent.
Examples of Intellectual Arrogance (IA):
- Displays Absolutist Language (DAL): Using rigid words like “always,” “never,” or “undeniably” regarding faith.
- Condescending Attitude (CA): Dismissive behavior that undermines the intellect of others.
- Ad Hominem (AH): Attacking the person rather than the argument.
Using this codebook, human annotators labeled a dataset of 350 posts. They achieved a Cohen’s Kappa score of 0.67, which indicates “substantial agreement.” This human-annotated dataset became the “Gold Standard” against which AI models would be tested.
Part 2: Can AI Read the Room?
With a solid dataset in hand, the researchers posed the critical question: Can Large Language Models (LLMs) automate this?
Detecting humility is significantly harder than detecting keywords. It requires understanding context, tone, and intent. The researchers tested two primary models: GPT-3.5 and GPT-4. They explored various “prompt engineering” strategies to see which method yielded the best results.
The Experimental Setup
They tested the models on two levels:
- Coarse Classification: Simply labeling a post as “Intellectual Humility,” “Intellectual Arrogance,” or “Neutral” (IH/IA/Neutral).
- Fine-Grained Labeling: Identifying specific traits (e.g., “Does this post demonstrate Respect for Diverse Perspectives?”).
They also varied how they asked the AI:
- Code-Only: Just giving the model the label name.
- Description-Only: Giving the definition but not the name.
- Code-and-Description (C&D): Giving both.
- Format: Asking via multiple-choice lists (MS) vs. yes/no binary questions (BQ).
The Results
The performance was measured using the F1 score, a metric that balances precision and recall.
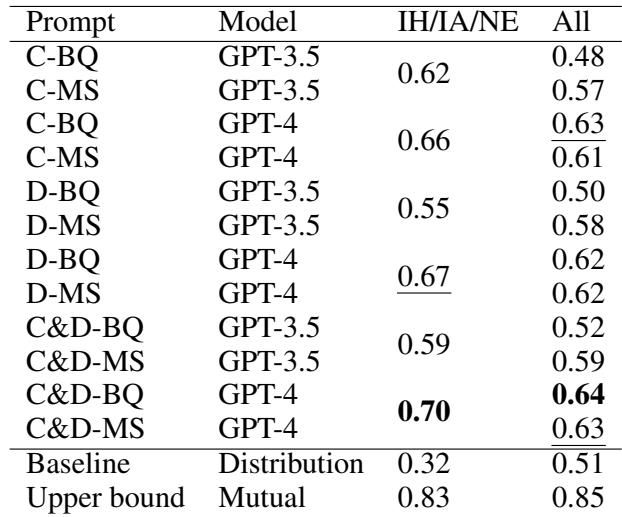
The results in the table above reveal several key insights:
- GPT-4 is Superior: GPT-4 consistently outperformed GPT-3.5 across almost all metrics.
- Context Matters: The “Code-and-Description” (C&D) prompt format generally worked best. The AI needs the specific definition of humility provided in the prompt; it cannot rely solely on its internal training data.
- The “Human Gap”: The most important numbers are at the bottom. The Upper Bound (how well humans agree) is 0.85. The best AI performance (GPT-4 with C&D) is 0.64.
While the AI performed significantly better than a random guess (the Baseline of 0.51), it is still far from matching human intuition.
Drilling Down: Where Does AI Struggle?
When we look at specific labels, the difficulty becomes clearer.
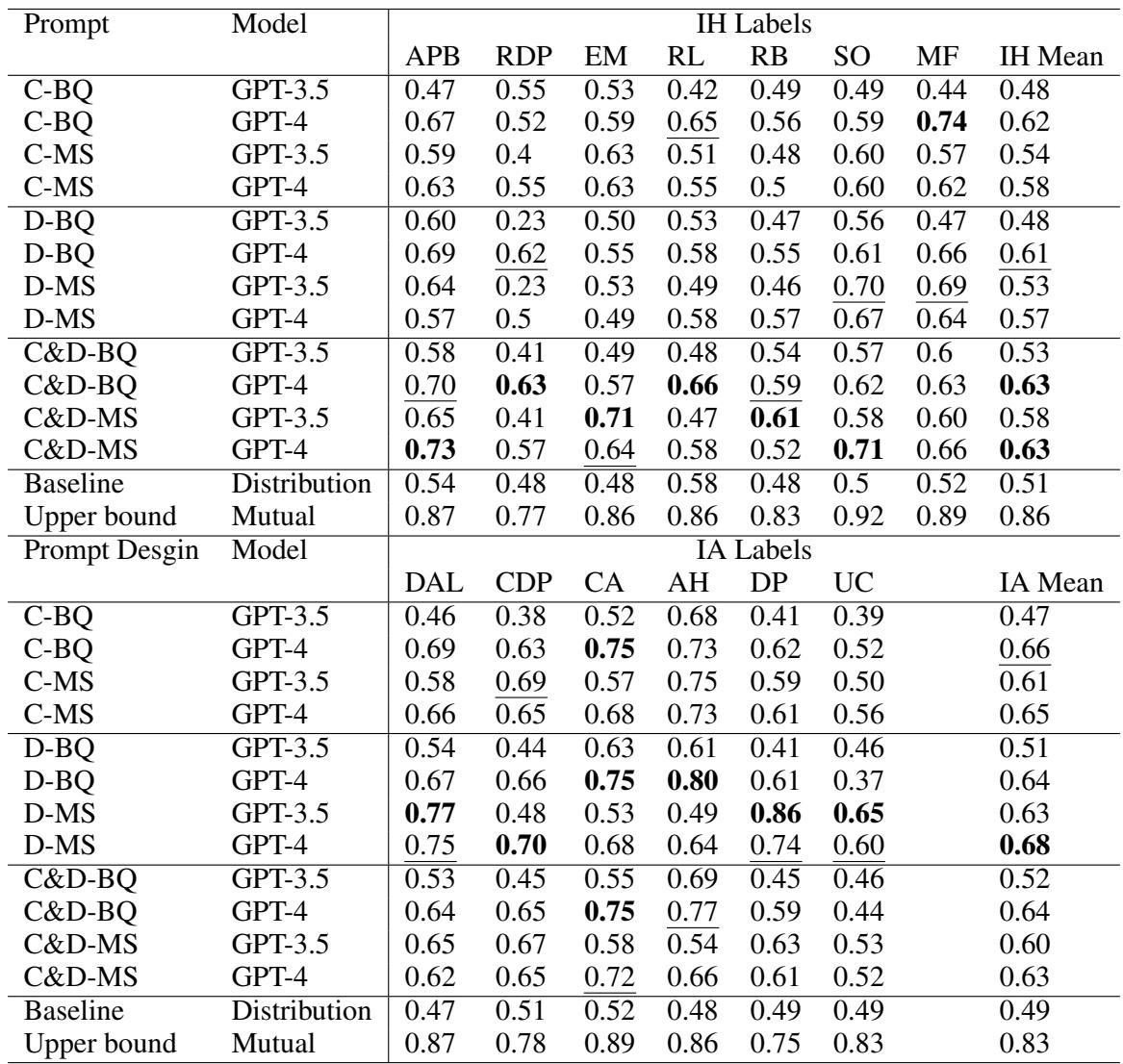
Table D2 details the breakdown. The AI is reasonably good at detecting Ad Hominem attacks (0.75 score) or Absolutist Language (0.69). These are linguistic features that often use specific keywords (insults or words like “absolutely”).
However, the AI struggles with nuanced IH concepts like Respects Diverse Perspectives (RDP), where it scored lower (around 0.63). This suggests that while AI can catch “rude” or “loud” writing, it has a harder time detecting the quiet grace of genuine open-mindedness.
Part 3: Can We Boost the AI?
Since the standard prompts didn’t reach human-level performance, the researchers tried advanced techniques to “boost” the models.
They tested:
- Few-Shot Learning: Giving the model 3 examples of positive and negative posts before asking it to classify.
- Chain-of-Thought (CoT): Asking the model to “explain its reasoning” before giving a final label.
- Auto-Optimization: Using an LLM to rewrite and improve the prompts automatically.
- Self-Refinement: Asking the model to critique its own answer and try again.
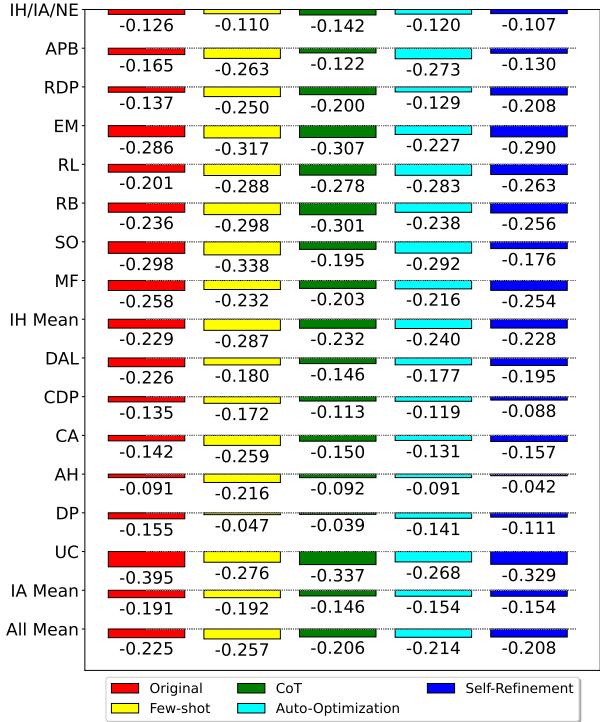
This chart shows the gap between the model and human performance (negative values mean the AI is worse than humans).
Surprising Findings:
- Few-shot learning actually hurt performance in some cases (likely due to overfitting on the few examples provided).
- Chain-of-Thought (CoT) and Self-Refinement helped, bringing the coarse “IH/IA/Neutral” detection very close to human levels.
- However, for specific labels (the rows below the top one), a significant gap remains.
Seeing the AI “Think”
To understand why the models succeed or fail, looking at the Chain-of-Thought output is illuminating.

In the second example in Figure E2, we see a failure case. The post discusses “saving a life” and “eternity.” The model hallucinates that this is “Embracing Mystery” because it mentions eternity. However, a human reader might recognize this as a theological assertion rather than a humble admission of the limits of knowledge. The AI confuses talking about spiritual concepts with possessing intellectual humility.
Conclusion: The Future of Virtuous AI
The paper “The Computational Anatomy of Humility” opens a new door in Natural Language Processing. It moves us away from simply flagging “bad words” and toward understanding high-level cognitive virtues.
Key Takeaways:
- Humility can be codified: It is possible to create a rigorous taxonomy for Intellectual Humility in online threads.
- Humans are still essential: Current AI models (even GPT-4) cannot fully replicate human discernment of humility, though they are getting closer.
- Prompting is powerful: How we ask the AI matters immensely. Giving the AI definitions and asking it to “show its work” (Chain of Thought) significantly improves accuracy.
Why This Matters for the Real World
Imagine a future social media platform that uses these models not to ban you, but to nudge you. Before you hit “post” on a heated debate, an algorithm could analyze your draft and say:
“It looks like you’re using absolutist language. Would you like to rephrase this to acknowledge that this is your personal perspective? It might lead to a more productive conversation.”
By building the computational infrastructure to measure humility, these researchers have laid the groundwork for technology that doesn’t just connect us, but potentially makes us better to one another. While the technology isn’t perfect yet, the “anatomy” has been defined—now it’s up to future research to bring it to life.