](https://deep-paper.org/en/paper/2410.18050/images/cover.png)
In the rapidly evolving world of Large Language Models (LLMs), we have seen a massive push toward “Long-Context” capabilities. Models like Gemini 1.5 or GPT-4-Turbo boast the ability to process hundreds of thousands of tokens—entire novels or codebases—in a single prompt. Theoretically, this should solve the problem of answering complex questions based on large documents.
However, reality tells a different story. When presented with massive amounts of data, LLMs often suffer from the “lost in the middle” phenomenon: they are great at remembering the beginning and end of a document but tend to forget or hallucinate details buried in the middle.
The traditional fix for this is Retrieval-Augmented Generation (RAG). Vanilla RAG chops documents into small chunks, finds the most relevant ones, and feeds them to the LLM. While efficient, this approach often shatters the global context. You might get a chunk containing a specific name, but lose the paragraph explaining why that name matters.
Enter LongRAG. Proposed by researchers from the Chinese Academy of Sciences and Tsinghua University, LongRAG is a new paradigm designed to get the best of both worlds. It combines the “big picture” view of long-context models with the precision of retrieval systems. In this post, we’ll break down how LongRAG works, why it outperforms existing methods, and how it handles the delicate balance between global information and factual details.
The Problem: Why Vanilla RAG and Long-Context LLMs Struggle
To understand LongRAG, we first need to understand the limitations of current approaches to Long-Context Question Answering (LCQA). LCQA tasks usually involve “multi-hop” reasoning—you can’t just find one sentence to answer the question; you need to connect piece A to piece B to find the answer C.
- Long-Context LLMs: You can feed the whole document into the model. However, despite long context windows, the reasoning capabilities of models degrade as the context grows. They struggle to pinpoint specific evidence amidst the noise.
- Vanilla RAG: This method retrieves the top-\(k\) chunks similar to the query. The downside? Fragmentation. By cutting text into fixed chunks (e.g., 200 words), semantic connections are broken. The model might retrieve a chunk that mentions a “university” but miss the previous sentence that names it. Furthermore, the retrieval often pulls in “noisy” chunks that look relevant but aren’t, confusing the generator.
LongRAG was designed to fix these issues by adopting a Dual-Perspective approach: it explicitly extracts Global Information (background/structure) and filters for Factual Details (precise evidence).
The LongRAG Architecture
The LongRAG system is modular, consisting of four “plug-and-play” components. Unlike standard RAG, which is usually just Retrieve \(\rightarrow\) Generate, LongRAG adds sophisticated processing steps in the middle to refine the information.
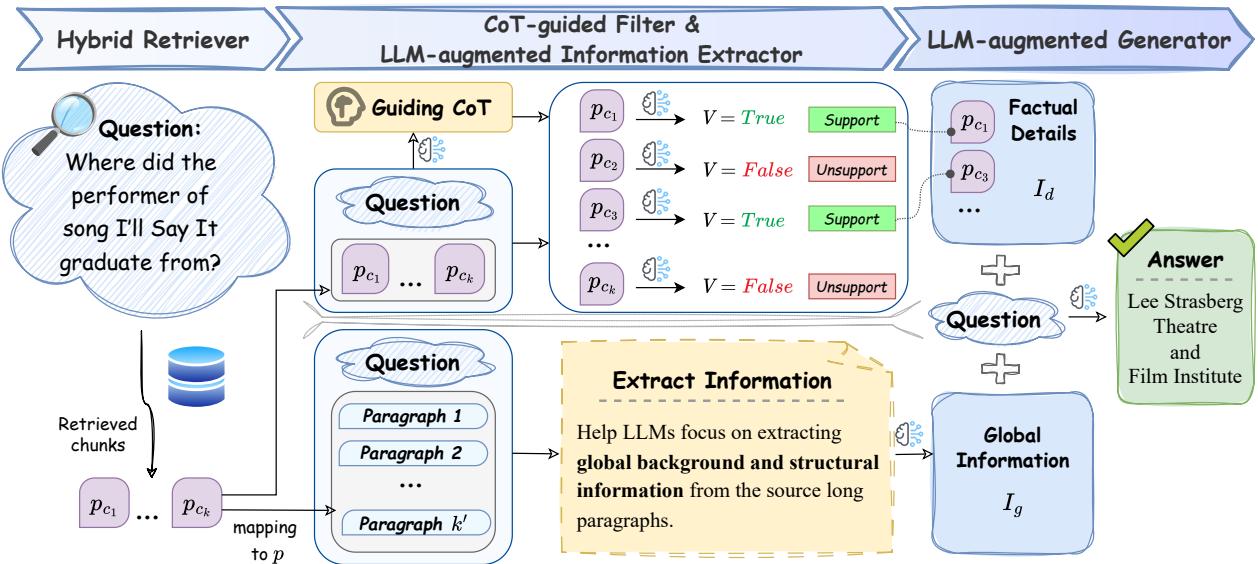
As shown in Figure 2, the process flows as follows:
- Hybrid Retriever: Retrieves relevant chunks.
- LLM-Augmented Information Extractor: Zooms out to understand the global context (\(I_g\)).
- CoT-Guided Filter: Zooms in to verify factual details (\(I_d\)).
- LLM-Augmented Generator: Combines both perspectives to answer the question.
Let’s break down these components in detail.
1. Hybrid Retriever
The process starts with a hybrid retrieval strategy. The system uses a dual-encoder for fast, coarse-grained retrieval (finding roughly relevant areas) and a cross-encoder for fine-grained re-ranking (scoring how well a specific chunk answers the question). This ensures the initial pool of chunks is high quality.
2. LLM-Augmented Information Extractor (\(I_g\))
This component addresses the “fragmentation” issue of Vanilla RAG. If we only look at small chunks, we lose the story.
The extractor first maps the retrieved short chunks (\(p_c\)) back to their source paragraphs (\(p\)). It essentially asks, “Where did this chunk come from?” and pulls the surrounding context.
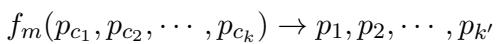
Once the system has the longer parent paragraphs, it uses an LLM to extract Global Information (\(I_g\)). This isn’t just summarizing; it uses a specific prompt (\(prompt_e\)) to identify background information and structural relationships relevant to the question (\(q\)).
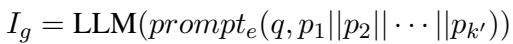
The result, \(I_g\), serves as a condensed “map” of the relevant documents, preserving the connections that simple chunking would destroy.
3. CoT-Guided Filter (\(I_d\))
While the Extractor looks at the big picture, the CoT-Guided Filter acts as a strict gatekeeper for details. In long documents, “evidence density” is low—meaning most of the text is irrelevant noise.
This component uses Chain-of-Thought (CoT) reasoning to determine if a retrieved chunk actually helps answer the question. It’s a two-stage process:
Stage A: CoT Guidance First, the LLM generates a “thought process” or clue based on the retrieved chunks. It tries to reason through what kind of information is needed to answer the question.

Stage B: Filtering Next, the system checks each chunk against this CoT guidance. It assigns a binary label: True (Support) or False (Unsupport).
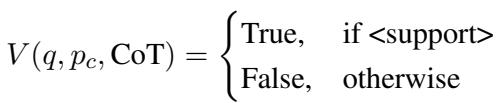
Only the chunks marked as “True” are kept. This set of high-quality, verified chunks is defined as Factual Details (\(I_d\)).
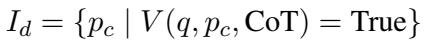
This step is crucial because it removes the “noise” that often causes hallucinations in standard RAG systems.
4. LLM-Augmented Generator
Finally, we have the generation phase. The generator doesn’t just receive a pile of random chunks. It receives two structured inputs:
- \(I_g\): The Global Information (context/background).
- \(I_d\): The Factual Details (verified evidence).
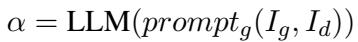
By interacting with both perspectives, the generator can answer complex multi-hop questions with high accuracy and low hallucination.
Instruction Tuning: Teaching the Model to Reason
One of the key contributions of this paper is how they trained the components. They didn’t just use off-the-shelf prompts; they created a high-quality dataset called LRGinstruction.
Using a larger “teacher” model (ChatGLM3-32B), they automatically generated training data for the Extractor and the Filter. This “Instruction Tuning” ensures that the smaller models used in the actual system are experts at following instructions, extracting context, and filtering noise. Remarkably, they achieved top-tier results using only 2,600 samples for fine-tuning.
Experimental Results
The researchers tested LongRAG on three challenging multi-hop QA datasets: HotpotQA, 2WikiMultiHopQA, and MusiQue. They compared their system against:
- Long-Context LLM Methods: LongAlign, LongLoRA.
- Advanced RAG: Self-RAG, CRAG.
- Vanilla RAG: Using models like GPT-3.5, Llama3, and Qwen.
Overall Performance
LongRAG significantly outperformed the competition. As seen in the table below, LongRAG (especially when fine-tuned, or “SFT”) consistently achieves the highest scores.
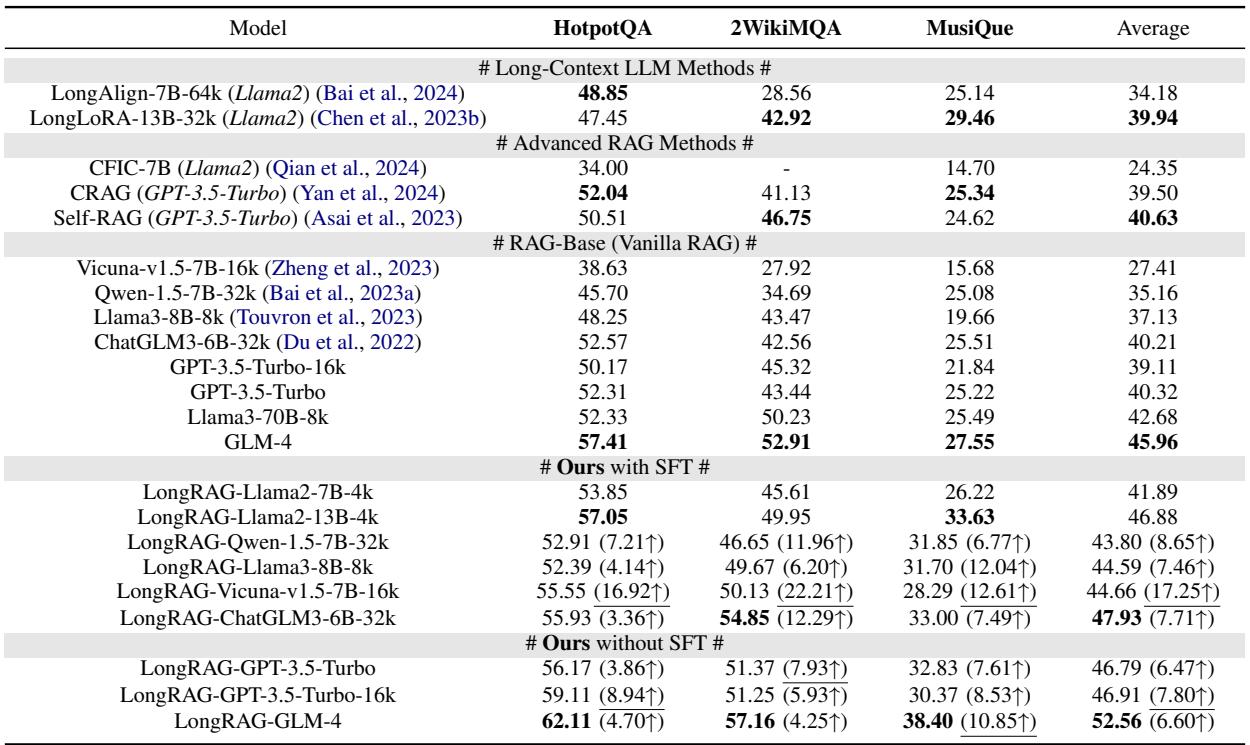
Notably, LongRAG achieves a relative improvement of over 17% compared to Vanilla RAG. It even beats Self-RAG (a highly complex adaptive retrieval method) by over 6%.
Why do we need both Extractor and Filter? (Ablation Study)
Is the complexity of LongRAG worth it? The authors conducted an ablation study, removing the Extractor and Filter one by one to see what happens.
- RAG-Base: The worst performer.
- RAG-Long: Mapping chunks to paragraphs but without processing. Better, but noisy.
- Ext. (Extractor Only): Significant improvement. Global context helps!
- Fil. (Filter Only): Minor improvement. Reducing noise helps, but you lose context.
- E&F (Extractor & Filter): The winner.
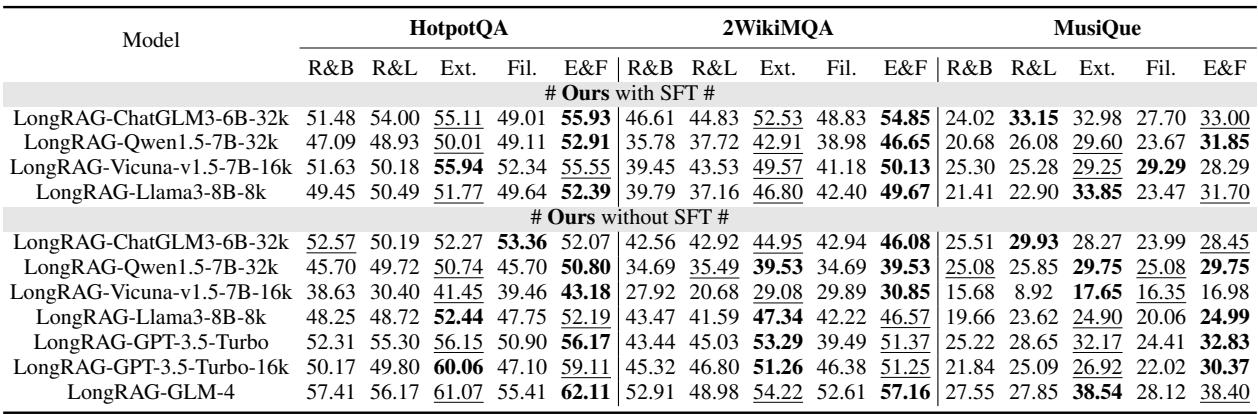
The combination (E&F) ensures the model has the context to understand the question and the precise details to answer it, without being overwhelmed by garbage text.
Efficiency: Doing More with Less
Perhaps the most practical finding for developers is the token usage. Because the CoT-Guided Filter is so aggressive at removing irrelevant chunks, the final prompt sent to the Generator is much shorter than in other methods.
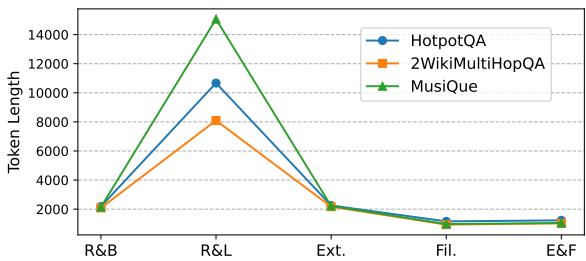
As shown in Figure 3, the “E&F” strategy (the bottom line) drastically reduces the input size (token length) compared to RAG-Long or standard retrieval methods. This translates to lower API costs and faster generation times, all while achieving higher accuracy.
Conclusion
LongRAG represents a significant step forward in making Retrieval-Augmented Generation robust for complex, long-context tasks. By acknowledging that LLMs need both a “bird’s-eye view” (Global Information) and “boots on the ground” (Factual Details), the authors have created a system that solves the “lost in the middle” problem.
Key Takeaways:
- Dual-Perspective: Combining global context extraction with strict detail filtering is superior to simple chunking.
- Noise Reduction: The CoT-Guided filter removes irrelevant data, preventing hallucinations and saving tokens.
- Cost-Effective: LongRAG allows smaller, fine-tuned models (like 6B-7B parameters) to outperform massive models (like GPT-3.5) on specific tasks.
For students and researchers working on QA systems, LongRAG demonstrates that we don’t always need larger context windows; sometimes, we just need smarter ways to process the context we have.