](https://deep-paper.org/en/paper/2410.19134/images/cover.png)
Imagine a friend telling you, “I’m fine.” Depending on their tone, pitch, and speed, they could mean they are genuinely happy, indifferent, or potentially furious. For a long time, AI has treated speech emotion as a classification task—simply categorizing that audio clip into buckets like “Sad,” “Happy,” or “Angry.”
But human emotion is rarely that simple. It is nuanced, mixed, and evolving. A simple label fails to capture the complexity of a voice that is “trembling with excitement” or “speaking quickly with a veiled tone of dissatisfaction.”
This limitation has given rise to Speech Emotion Captioning (SEC), a field dedicated to generating natural language descriptions of speech emotions. However, describing emotion is harder than it looks. Current models often “hallucinate”—inventing facts or emotions that aren’t there—or fail to generalize when they hear new voices.
In this post, we dive into AlignCap, a novel framework proposed by researchers from the University of Science and Technology of China. AlignCap addresses these issues by aligning speech processing not just with text, but with human preferences, using a clever mix of Knowledge Distillation and Preference Optimization.
The Problem: Hallucinations and the Distribution Gap
Why do current models fail? The researchers identify two primary culprits: Hallucination and Generalization gaps.
When an AI model listens to speech and tries to describe it, it faces a “training-inference mismatch.” Most of these models are trained heavily on text but are asked to infer from audio. Because the statistical distribution of speech data differs from text data, the model gets confused.
As illustrated below, this leads to three types of errors:
- Faithfulness Hallucination: The model ignores the user’s instructions or invents content.
- Factuality Hallucination: The model misinterprets the tone (e.g., calling a delighted voice “dissatisfied”).
- Loss of Generalization: The model defaults to generic, unhelpful phrases like “a person speaking” instead of capturing specific emotional cues.

To solve this, we need to bridge the gap between how the model “sees” text and how it “hears” audio.
Background: The Challenge of Alignment
In multimodal AI, “alignment” refers to mapping different types of data (like audio and text) into a shared space so the model understands they represent the same concept.
Traditional methods usually try to align these modalities before the Large Language Model (LLM) starts decoding. They might use Contrastive Learning (CL) or projection layers to force the audio embeddings to look like text embeddings.
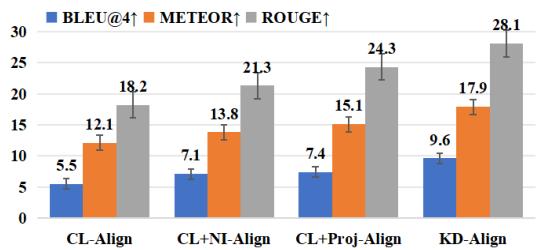
The researchers ran experiments to see how these traditional alignment methods performed. As shown in the chart below, while alignment (CL-Align and CL+Proj-Align) improves performance over no alignment, there is still significant room for improvement.
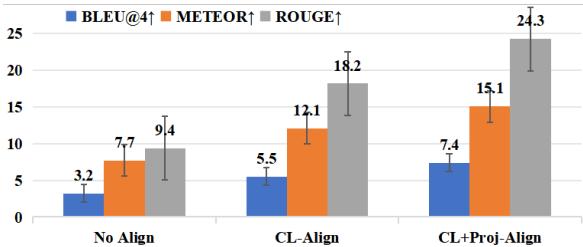
The problem with pre-decoding alignment is information loss. By forcing audio to strictly match text embeddings too early, we lose the rich, fine-grained details specific to speech. AlignCap takes a different approach: it aligns the modalities during and after the LLM decoding process.
The AlignCap Framework
AlignCap is built on two major pillars designed to guide the Large Language Model (specifically LLaMA-7B) to produce accurate, human-like descriptions.
- KD-Regularization: For Speech-Text Alignment.
- PO-Regularization: For Human Preference Alignment.
Let’s break down the full architecture.
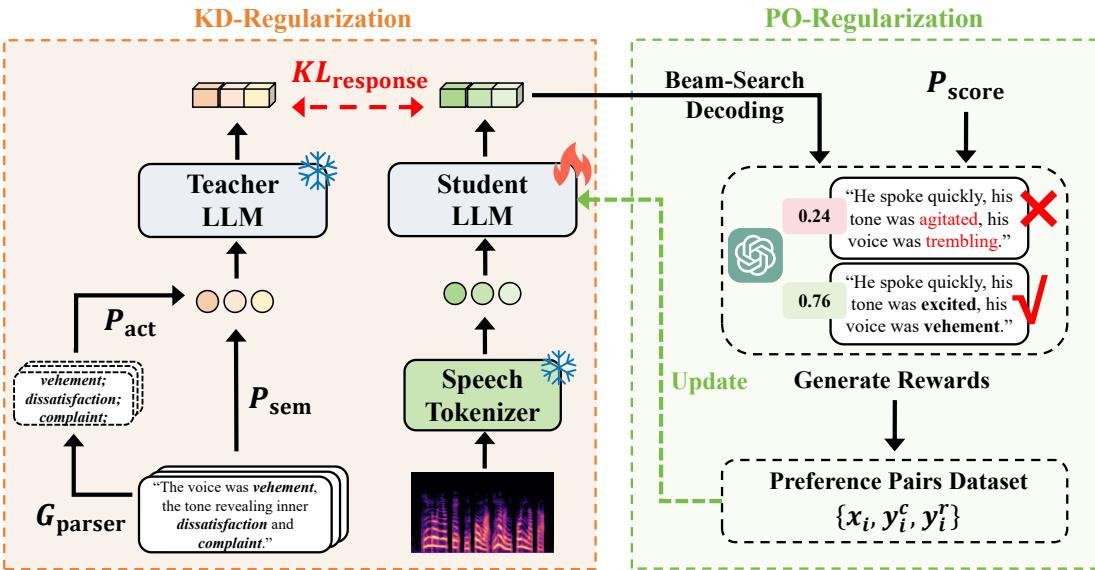
Pillar 1: Speech-Text Alignment via KD-Regularization
The core insight of AlignCap is Knowledge Distillation (KD). The researchers treat the LLM’s response to text (which it is very good at) as the “Teacher,” and its response to speech (which it struggles with) as the “Student.”
If the model is working correctly, its probability distribution for generating the next word should be roughly the same whether it reads the transcript of an angry speech or hears the angry audio itself.
The Acoustic Prompt To help the model, the researchers don’t just feed it raw audio tokens. They extract an Acoustic Prompt (\(P_{act}\)). Using a grammar parser on the text captions, they extract emotional clues (adjectives about tone, pitch, rhythm) and insert them into a template.
\[ \begin{array} { r l } & { e _ { 1 \sim n } = G _ { \mathrm { P a r s e r } } ( y _ { i } = \{ c _ { i } ^ { 1 } , . . . , c _ { i } ^ { | y _ { i } | } \} ) } \\ & { \mathrm { P } _ { \mathrm { a c t } } = \mathrm { I n s e r t } ( \mathrm { P } _ { \mathrm { T } } , i d x , e _ { 1 \sim n } ) } \end{array} \]This prompt acts as a “cheat sheet” for the Teacher model, ensuring it has rich emotional context.
The Distillation Process During training, the model tries to minimize the KL-Divergence (a measure of difference) between the Teacher’s prediction distribution (based on text + acoustic prompt) and the Student’s prediction distribution (based on audio tokens).
\[ \begin{array} { r l } { \displaystyle } & { \displaystyle \min _ { \mathrm { L L M } _ { \mathrm { s t u } } ( \cdot ) } \mathcal { L } _ { \mathrm { K L } } ( p , x , y ) = } \\ & { - \displaystyle \sum _ { t , y _ { n } } p _ { \theta } ( y _ { n } | p _ { n } , y _ { < n } ) \log p _ { \theta } ( y _ { n } | x _ { n } , y _ { < n } ) } \end{array} \]By minimizing this loss, the Student (speech model) learns to mimic the behavior of the Teacher (text model).
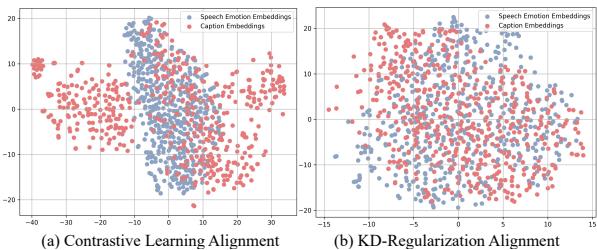
Why Align After Decoding? The researchers visualized the embeddings of speech and text outputs using t-SNE (a technique for visualizing high-dimensional data).
In the image below, (a) shows traditional alignment before decoding. Notice how the blue dots (speech) and red dots (text) form somewhat separate clusters. In (b), which uses AlignCap’s KD-Regularization (after decoding), the blue and red dots are tightly intermingled. This proves that the model is treating speech and text almost identically, effectively bridging the distribution gap.
Pillar 2: Human Preference Alignment via PO-Regularization
Even if the model understands the speech, it might still generate robotic or repetitive captions. To fix this, AlignCap employs Preference Optimization (PO).
This is distinct from the famous RLHF (Reinforcement Learning from Human Feedback) used in models like ChatGPT, which requires training a separate reward model and is computationally expensive. Instead, AlignCap uses Direct Preference Optimization (DPO), a simpler and more stable approach.
Creating Preference Pairs First, the model generates multiple candidate captions for a speech clip. These are scored using GPT-3.5 based on a specific rubric:

Based on these scores, the researchers create pairs of “Chosen” (\(y_c\)) and “Rejected” (\(y_r\)) responses.
The Optimization The model is then fine-tuned to increase the likelihood of generating the “Chosen” caption while decreasing the likelihood of the “Rejected” one. This effectively pushes the model away from hallucinations and towards high-quality, human-preferred descriptions.
\[ \begin{array} { r } { \mathcal { L } _ { \mathrm { P O } } = \mathbb { E } _ { ( x , y _ { g } , y _ { n } ^ { c } ) } \Big [ \beta \log \sigma ( \log \frac { \pi _ { \theta } ( y _ { g } | x ) } { \pi _ { r e f } ( y _ { g } | x ) } } \\ { - \log \frac { \pi _ { \theta } ( y _ { n } ^ { c } | x ) } { \pi _ { r e f } ( y _ { n } ^ { c } | x ) } ) \Big ] } \end{array} \]Experiments and Results
The team evaluated AlignCap on several datasets, including MER2023, NNIME, and a new dataset they constructed called EMOSEC.
Zero-Shot Performance
One of the toughest tests for an AI model is “zero-shot” inference—performing a task on data it has never seen before.
As shown in Table 1, AlignCap (specifically the version with both KD and PO) significantly outperforms baseline models like HTSAT-BART and SECap.
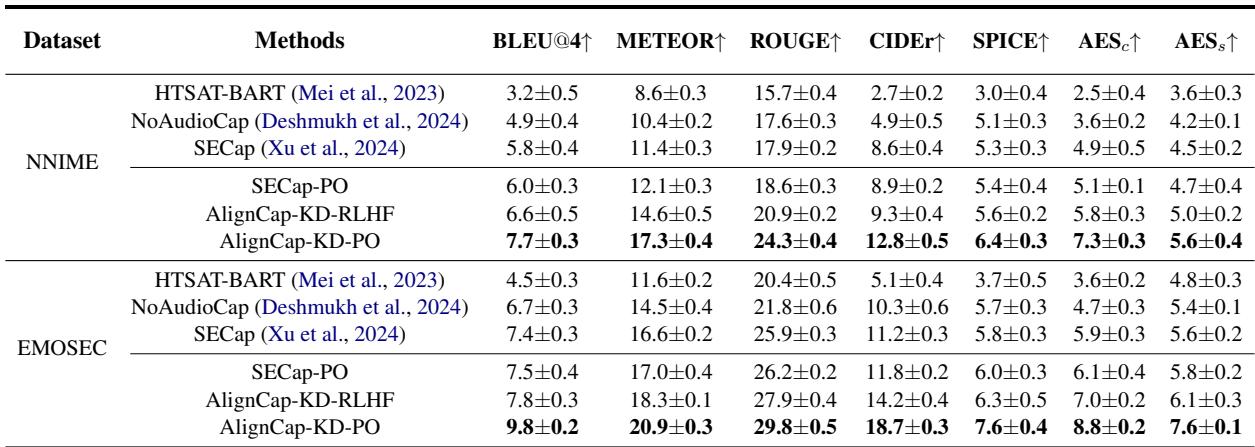
Key takeaways from the results:
- Metrics: AlignCap leads in BLEU@4 (accuracy of phrasing) and METEOR/ROUGE (richness and recall).
- PO Impact: The models with Preference Optimization (PO) consistently beat those without, proving that aligning to human preference reduces hallucinations.
Why KD-Alignment Wins
The researchers compared their KD-based alignment against other popular methods like Contrastive Learning (CL) and Projection. The results were clear: treating alignment as a knowledge distillation problem yields far better translation quality (BLEU) and semantic richness (METEOR).
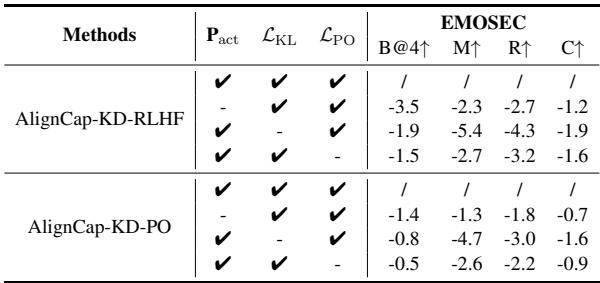
Ablation Studies: Do we need all the parts?
To ensure every component was necessary, they removed parts of the model one by one.
- Removing \(P_{act}\) (Acoustic Prompt): Led to a drop in emotional consistency.
- Removing \(\mathcal{L}_{KL}\) (KD-Regularization): Caused a significant drop in factual accuracy, showing the importance of speech-text alignment.
- Removing \(\mathcal{L}_{PO}\) (Preference Optimization): Resulted in lower faithfulness scores, meaning the model started ignoring instructions more often.
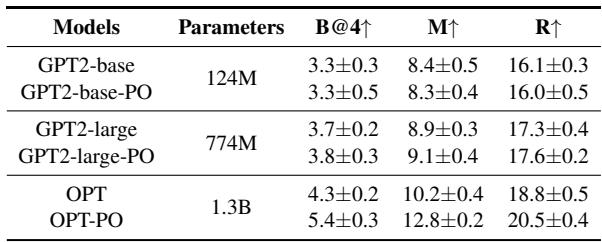
Does it work on small models?
Interestingly, the researchers applied PO-Regularization to smaller models like GPT-2 and OPT. While extremely small models (GPT2-base) saw little benefit, slightly larger ones (OPT-1.3B) saw significant gains. This suggests that the model needs a certain “capacity” to understand and benefit from preference optimization.
Conclusion
AlignCap represents a significant step forward in how machines understand human speech. It moves beyond simple “Happy/Sad” labels to generate rich, descriptive captions that capture the nuance of how we speak.
By using KD-Regularization, it forces the model to treat audio as reliably as it treats text. By using PO-Regularization, it ensures those descriptions actually make sense to humans and stay true to the facts.
As we move toward more interactive AI assistants, this kind of technology will be crucial. It enables an AI not just to understand what you said, but to grasp how you felt when you said it—without hallucinating emotions that aren’t there.