](https://deep-paper.org/en/paper/2410.24218/images/cover.png)
Introduction
Imagine you are teaching a friend how to cook a complex dish. If they make a mistake, you wouldn’t just give them a “thumbs down” or a numerical score. You also wouldn’t limit yourself to robotic commands like “pick up spoon.” instead, you would likely say something like, “You added too much salt just now, so you should add more potatoes to balance it out.”
This rich form of communication—containing both a critique of the past (hindsight) and guidance for the future (foresight)—is natural to humans. Yet, in the world of Reinforcement Learning (RL), embodied agents (like robots or virtual avatars) are often trained with much cruder signals. They typically receive sparse numerical rewards or very simple, repetitive instructions.
A recent research paper titled “Teaching Embodied Reinforcement Learning Agents: Informativeness and Diversity of Language Use” tackles this discrepancy. The researchers pose a fascinating question: Can we improve an agent’s ability to learn and generalize by making the language input more informative and diverse?
This post explores how the authors integrated the richness of human language into Offline RL using Decision Transformers, demonstrating that when AI agents are “taught” with varied and detailed feedback, they don’t just memorize tasks—they begin to truly understand them.
Background: The Limits of Simple Instructions
To understand the contribution of this paper, we first need to look at the status quo of language in Reinforcement Learning.
Traditionally, RL agents learn through trial and error, guided by a reward function (e.g., +1 for winning, -1 for losing). While effective, this is slow. Recent approaches have introduced language as a way to “shape” behavior. However, existing methods usually rely on:
- Low-Informativeness Instructions: Simple commands like “go north” or “open door.”
- Low-Diversity Expressions: Rigid templates where the sentence structure never changes.
Real-world environments are open-ended. A robot in a home will encounter thousands of variations of the same request. If it only knows “put apple on table,” it might fail when asked to “move the fruit to the dining area.”
The researchers propose that to build robust agents, we need to leverage two key properties of natural language: Informativeness (providing context on past errors and future goals) and Diversity (using varied vocabulary and sentence structures).
The Environments
To test this hypothesis, the authors utilized four distinct embodied AI environments, ranging from grid worlds to robotic manipulation:
- HomeGrid: A household simulation where agents find objects, clean up, and rearrange items.
- ALFWorld: A text-based game aligned with household tasks (e.g., heating an egg).
- Messenger: A game requiring an agent to deliver messages while avoiding enemies.
- MetaWorld: A robotic arm simulation performing assembly and tool-use tasks.
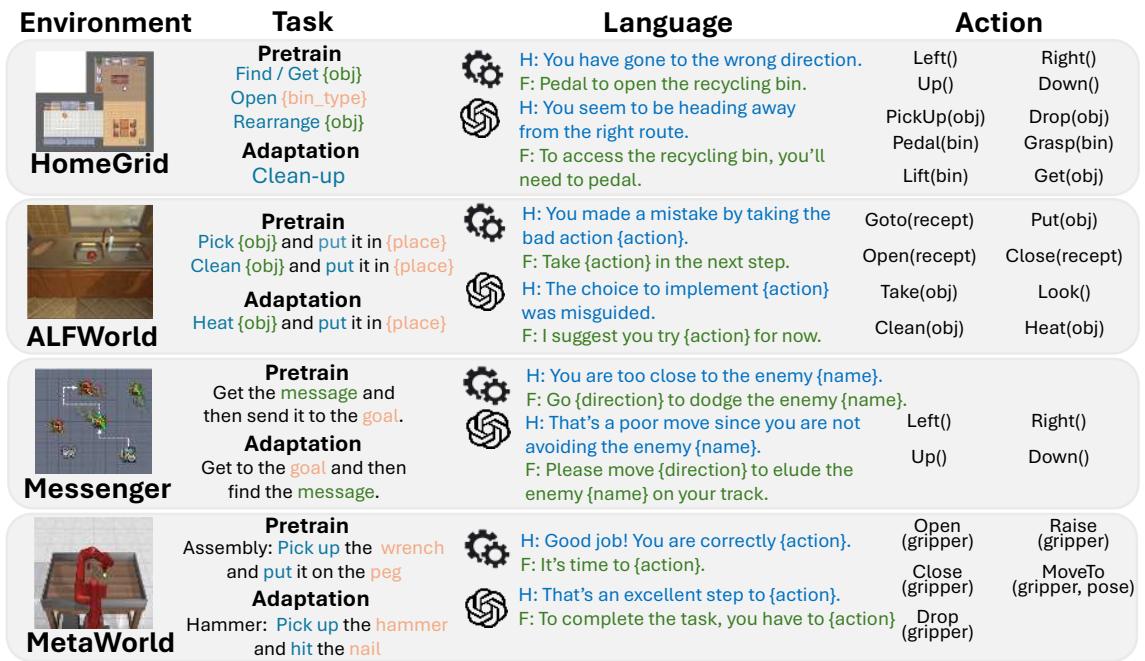
As shown in Figure 1 above, each environment presents unique challenges, but they all share a common need: the agent must map visual or textual states to actions to achieve a goal.
Core Method: The Language-Teachable Framework
The core contribution of this work is a pipeline that generates rich language data and a model architecture capable of ingesting it. Let’s break down how the researchers taught their agents.
1. Defining Informativeness: Hindsight and Foresight
The researchers categorize “helpful language” into two distinct buckets:
- Hindsight Feedback: This looks backward. It critiques what the agent just did.
- Example: “You are getting too close to the enemy.”
- Benefit: It helps the agent understand why a previous action was suboptimal.
- Foresight Feedback: This looks forward. It guides the agent on what to do next.
- Example: “You should go right to get closer to the target.”
- Benefit: It narrows down the search space for the next correct action.
The hypothesis is that combining both (Hindsight + Foresight) provides the most potent learning signal.
2. Achieving Diversity: The GPT-Augmented Pool
Using templates (e.g., “Go [Direction]”) is easy to implement but results in brittle agents that fail when the wording changes slightly. To solve this, the authors employed GPT-4 to expand their dataset.
They started with hand-crafted templates for hindsight and foresight. Then, they fed these templates into GPT-4 to generate dozens of semantically equivalent variations. For example, “You are doing well” might become “So far, so good, you’re doing great!” or “Excellent progress.”
This created a GPT-Augmented Language Pool, ensuring the agent never sees the exact same sentence pattern too many times, forcing it to learn the meaning rather than memorizing the syntax.
3. Data Generation Pipeline
Since this is an Offline RL approach (learning from a pre-collected dataset rather than live interaction), the researchers needed to generate a training dataset containing trajectories (sequences of states and actions) paired with this rich language.
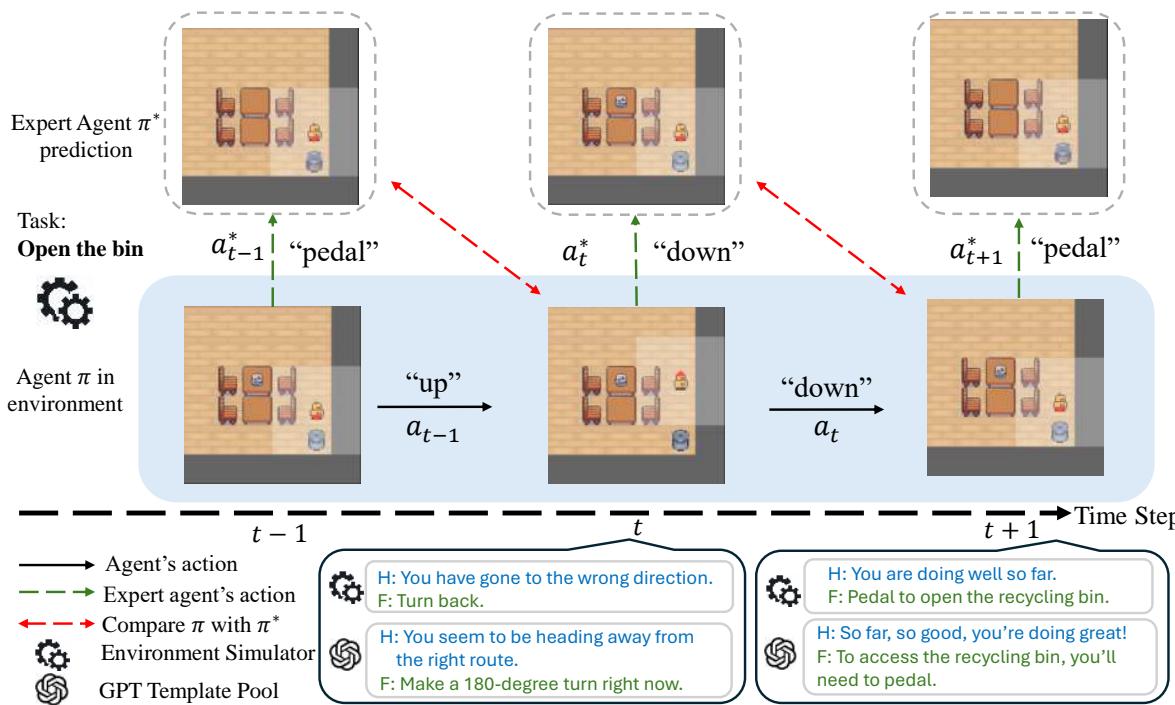
Figure 2 illustrates the generation process:
- The Agents: Two agents are running. A Non-Expert Agent (the student) performs the task but makes mistakes due to noise injection. An Expert Agent (the teacher) runs in the background, knowing the optimal moves.
- The Comparison: At every step, the system compares the Student’s action to the Expert’s.
- The Feedback:
- If the Student diverged from the Expert at step \(t-1\), Hindsight is generated (e.g., “You went the wrong way”).
- Based on what the Expert would do at step \(t\), Foresight is generated (e.g., “Now turn left”).
- The Diversity: These raw signals are swapped with random variations from the GPT-augmented pool.
4. The Architecture: Language-Teachable Decision Transformer (LTDT)
To process this data, the authors extended the Decision Transformer (DT).
Standard RL methods (like Q-Learning) estimate the value of actions. The Decision Transformer, however, treats RL as a sequence modeling problem—similar to how LLMs predict the next word. It takes a sequence of past states, actions, and rewards, and predicts the next action.
The researchers introduced the Language-Teachable Decision Transformer (LTDT). As shown in Figure 3, they augmented the input sequence to include the language feedback token (\(l_t\)) at every time step.
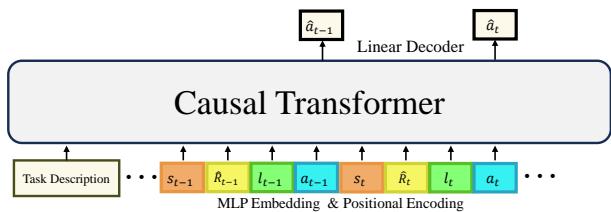
The model receives a sequence like:
[Task Description] -> (State, Reward, Language, Action) -> (State, Reward, Language, Action)...
The transformer attends to the history of language feedback alongside physical states to decide its next move. This allows the agent to correct its course based on the “teacher’s” comments.
Experiments & Results
The researchers conducted extensive experiments to answer two main questions:
- Does rich language improve performance on known tasks?
- Does it help agents adapt to new, unseen tasks?
Result 1: Richer Language = Better Performance
The first set of experiments compared agents trained with different levels of language quality.
- No Language: The baseline.
- Template Hindsight / Foresight: Simple, repetitive feedback.
- Template H+F: Both types combined.
- GPT-Augmented H+F: The proposed method with high diversity.

The results in Figure 4 are striking. In every environment, adding language helps. However, the GPT-Augmented Hindsight + Foresight (Purple bars) consistently achieves the highest rewards.
This proves two things:
- Informativeness matters: Combining reflection (Hindsight) and guidance (Foresight) is better than either alone.
- Diversity is crucial: The “Template” agents (Yellow and Blue bars) often plateaued. The GPT-augmented agents learned more robust policies because they were forced to understand varied linguistic patterns.
Result 2: Faster Adaptation to New Tasks
A major goal in AI is generalization. Can an agent trained to “pick up apples” quickly learn to “clean a bowl”?
The researchers pre-trained agents on a set of tasks and then tested them on unseen tasks using “few-shot adaptation” (allowing the agent to practice the new task for just a few episodes).

Figure 5 shows the adaptation curves. The Purple bars (GPT-Augmented H+F) are significantly higher, even with only 5 or 10 “shots” (attempts). This suggests that training with rich language gives the agent a “meta-learning” ability. It learns how to listen and adjust its behavior based on feedback, skill that transfers to completely new problems.
Insight: When is Language Most Useful?
Does language help in every scenario? The researchers plotted the “Efficiency Gain” (how much language helped) against “Task Difficulty.”
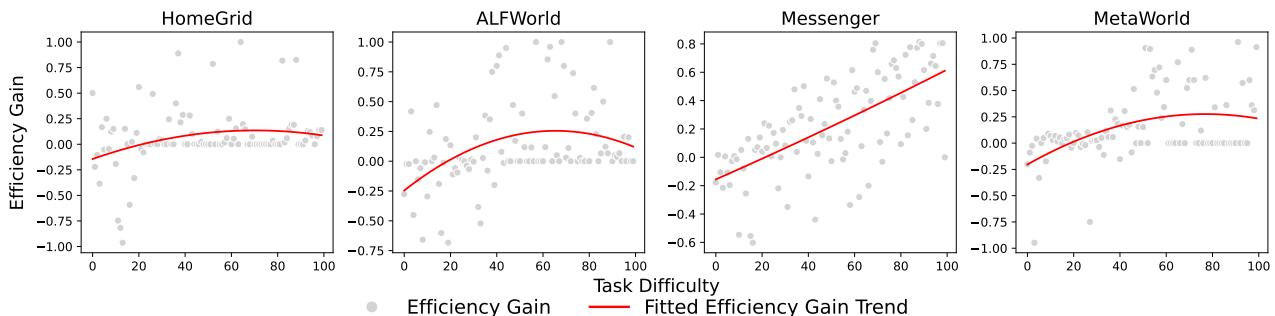
As Figure 6 illustrates, there is a “Goldilocks zone.”
- Too Easy: If a task is trivial, the agent solves it easily without help; language adds overhead.
- Too Hard: If a task is impossibly complex, the agent fails regardless of the feedback.
- Moderate: In the middle, language provides the critical nudge needed to solve the problem efficiently.
Robustness: What if the Teacher vanishes?
A concern with “teachable” agents is dependency. Does the agent become helpless if the human stops talking?
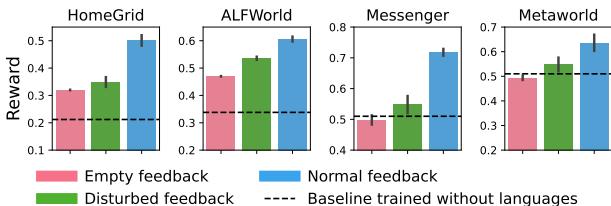
Figure 8 provides a reassuring answer. The researchers tested the agents in a “No Language” setting (Pink bars) where the feedback was cut off during the test.
- Surprisingly, the language-trained agents still performed well, often matching or beating the baseline. This indicates they internalized the task dynamics during training—they learned the skill, not just how to follow orders.
- Even when given “Disturbed” (incorrect or garbage) feedback (Green bars), they maintained decent performance, showing they aren’t brittle to bad inputs.
Conclusion and Implications
The paper “Teaching Embodied Reinforcement Learning Agents” offers a compelling argument for the integration of Natural Language Processing (NLP) and Robotics. It moves us away from viewing language as merely a static label or a trigger command. Instead, it frames language as a dynamic, shaping signal—a way to transfer human intuition to machines.
Key Takeaways:
- Context is King: Telling an agent what it did wrong (Hindsight) is just as important as telling it what to do next (Foresight).
- Variety prevents Overfitting: Training with diverse, GPT-generated phrasing prevents the agent from memorizing specific commands, leading to robust understanding.
- Learning to Learn: Agents trained this way don’t just master a specific task; they master the art of utilizing feedback, making them adaptable to new challenges.
As we move toward a future of general-purpose home robots and assistants, this research highlights that the key to smarter AI might not just be better algorithms, but better, richer communication between the human teacher and the digital student.