](https://deep-paper.org/en/paper/2502.00640/images/cover.png)
Introduction
We have all been there. You ask a Large Language Model (LLM) a vague question, and it immediately spit outs a generic, confident answer. It doesn’t ask for clarification. It doesn’t check if it understands your underlying goal. It just… responds. You then spend the next ten minutes prompting back and forth, correcting its assumptions, until you finally get what you wanted.
This happens because modern LLMs are typically “passive responders.” They are trained to maximize the likelihood of the very next response, satisfying the immediate query without considering the long-term trajectory of the conversation.
But what if an AI could think ahead? What if, like a good human colleague, it asked clarifying questions or proposed a strategy that might take a moment longer now but saves hours of work later?
This is the premise of COLLABLLM, a new framework introduced in a recent research paper. COLLABLLM moves beyond standard training methods by teaching models to optimize for long-term collaboration gains rather than short-term approval. By simulating future conversations and using a novel reward mechanism, the researchers have created a model that actively uncovers user intent and offers insightful suggestions.
In this post, we will deconstruct how COLLABLLM works, the mathematics behind its “forward-looking” rewards, and the results from both simulated and real-world experiments.
The Problem: The “Yes-Man” AI
To understand why COLLABLLM is necessary, we first need to look at how models like Llama or ChatGPT are currently fine-tuned. The standard standard is Reinforcement Learning from Human Feedback (RLHF). In RLHF, a model is given a prompt, generates a response, and a reward model scores that specific response.
The flaw here is the single-turn horizon. The model is incentivized to get a high score right now. If a user asks a vague question, the “safest” way to get a high score is to provide a generic, agreeable answer immediately. Asking a clarifying question might be seen as “refusing” the prompt or might risk a lower immediate reward if the reward model isn’t calibrated for dialogue flow.
This leads to passive behavior. As shown in Figure 2 below, a non-collaborative LLM (top left) takes a vague request and produces a mediocre result, leading to a frustrating back-and-forth loop. The user has to do the heavy lifting of refining the intent.
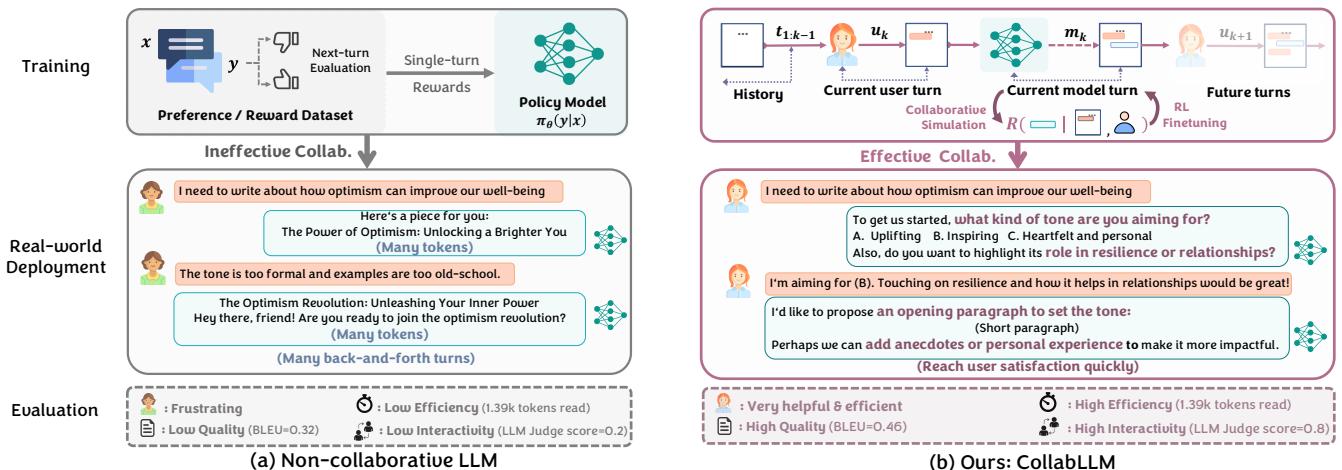
In contrast, COLLABLLM (right side) acts as an active collaborator. It identifies ambiguity in the request (“tone” and “content goals”) and asks about them before generating the full content. This “forward-looking” strategy results in higher quality output and a more efficient conversation overall.
The Solution: COLLABLLM Framework
The core innovation of this paper is shifting the training objective from maximizing the immediate reward to maximizing the future reward over the course of a conversation.
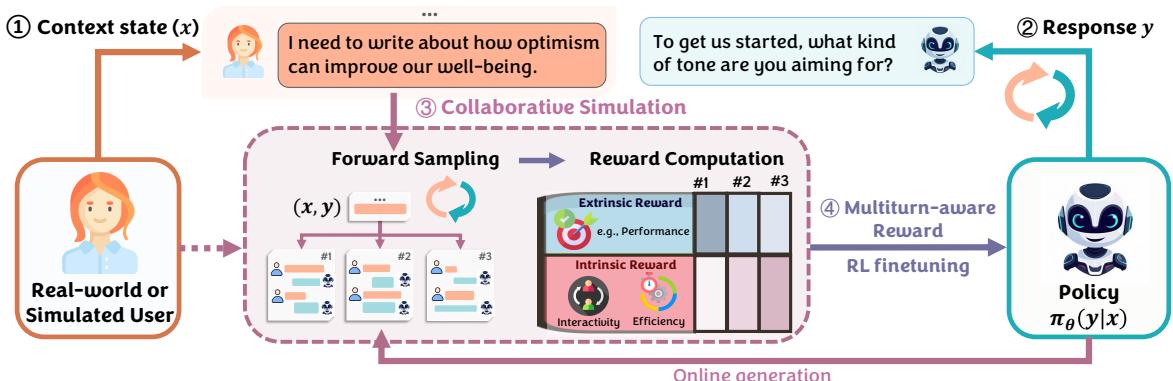
The framework consists of four main steps, illustrated in Figure 1:
- Context: The model receives the current conversation history.
- Response: The model generates a candidate response.
- Collaborative Simulation: Instead of scoring this response immediately, the system plays out the future! It uses a User Simulator to generate synthetic future turns based on that response.
- Multiturn-aware Rewards (MR): The system calculates a reward based on how well the entire future conversation went, and uses this to fine-tune the model.
1. The Core Concept: Multiturn-aware Rewards (MR)
This is the mathematical heart of the paper. Standard RLHF optimizes \(R(response | context)\). COLLABLLM optimizes the expected value of the conversation trajectory.
The researchers term this the Multiturn-aware Reward (MR). The MR for a response \(m_j\) at turn \(j\) is calculated by looking at the expectation (\(\mathbb{E}\)) of future conversation paths (\(t^f_j\)).
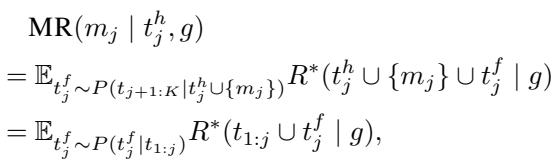
Here is what this equation tells us:
- The reward for the current response \(m_j\) is the expected value of the final goal achievement \(R^*\).
- This expectation is calculated over potential future conversations (\(t^f_j\)) sampled from a distribution \(P\).
- Essentially, a response is “good” not if it looks good now, but if it leads to a successful ending later.
2. Defining “Success”: The Reward Function
To calculate the reward \(R^*\) of a conversation, the researchers couldn’t just use standard accuracy. Collaboration is about more than just being right; it is about efficiency and experience.
They defined the conversation-level reward as a sum of Extrinsic (task success) and Intrinsic (experience) factors:
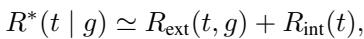
Extrinsic Reward (\(R_{ext}\))
This measures whether the job actually got done. For a coding task, does the code run? For a document editing task, is the text high quality?
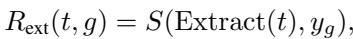
Intrinsic Reward (\(R_{int}\))
This is where the “human” element comes in. This component penalizes the model for wasting the user’s time (Token Count) and rewards it for being interactive (evaluated by an LLM judge).
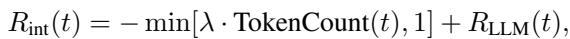
By including the token count penalty (\(\lambda \cdot \text{TokenCount}\)), the model learns that asking too many questions is bad. It needs to find the balance: ask enough to clarify, but not so much that it becomes annoying.
3. The Crystal Ball: Forward Sampling with User Simulators
You might be asking: “How can the model know the future conversation during training?”
The answer is Collaborative Simulation. The researchers employ a second LLM to act as a User Simulator. This simulator is prompted to role-play as a human with a specific, implicit goal.
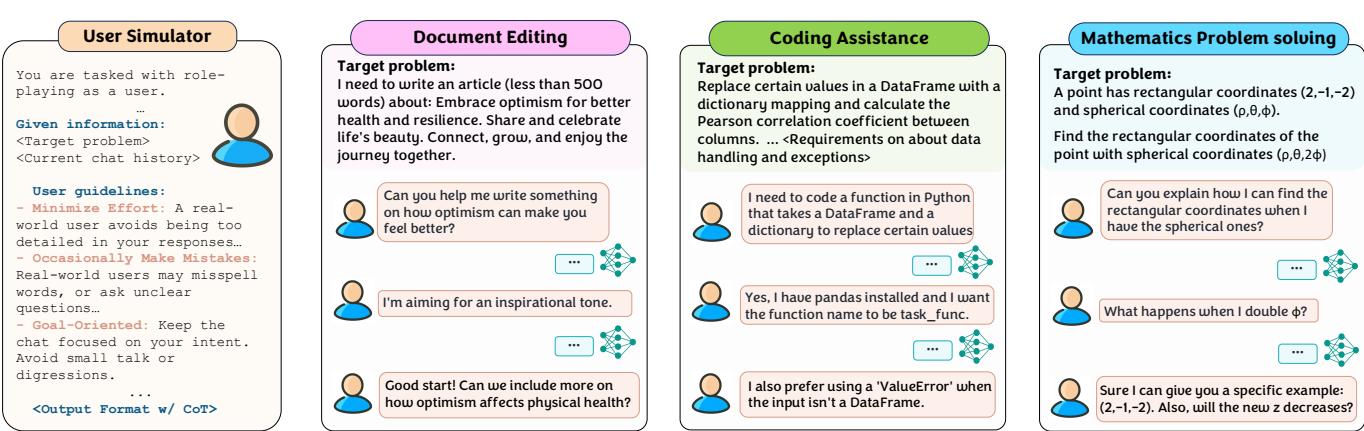
As shown in Figure 3, the User Simulator is given a “target problem” (which is hidden from the main model). When the main model produces a response, the User Simulator replies based on that target. This creates a synthetic “future” that allows the system to estimate the Multiturn-aware Reward defined in the equations above.
4. Training Pipeline: SFT and DPO
With the reward mechanism and simulator in place, training becomes a data generation problem. The framework generates vast amounts of synthetic conversations.
- Generate Candidates: For a given context, the model proposes several responses.
- Simulate Futures: The User Simulator plays out the conversation for each response.
- Calculate MR: Each response gets a score based on how those simulations ended.
- Rank and Train: The response that led to the best future is marked “Chosen,” and the one that led to a poor future is “Rejected.”
This creates a dataset for Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
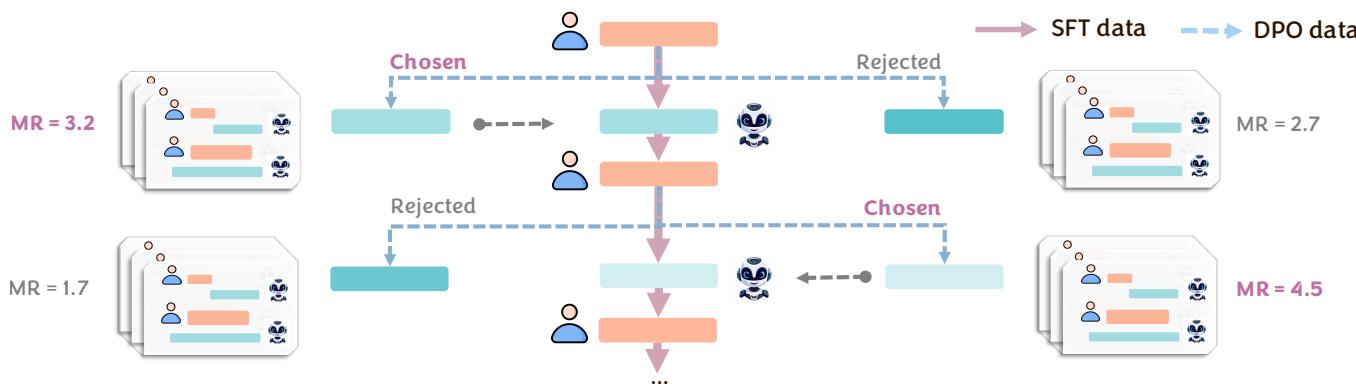
As seen in Figure 8, the “Chosen” path (solid red) represents the trajectory where the model successfully guided the user to the goal (high MR), while the “Rejected” path (dashed blue) represents a failure to collaborate.
Case Study: Coding Assistance
Let’s make this concrete with a coding example from the paper’s experiments.
The user asks for a function to tokenize text using NLTK (a natural language processing library).
- Non-Collaborative Model: Immediately writes code. It assumes the user wants to remove stopwords and punctuation. It writes a function that crashes if the file doesn’t exist.
- COLLABLLM: Pauses. It asks: “Do you want to handle file errors? Do you want to keep punctuation?”
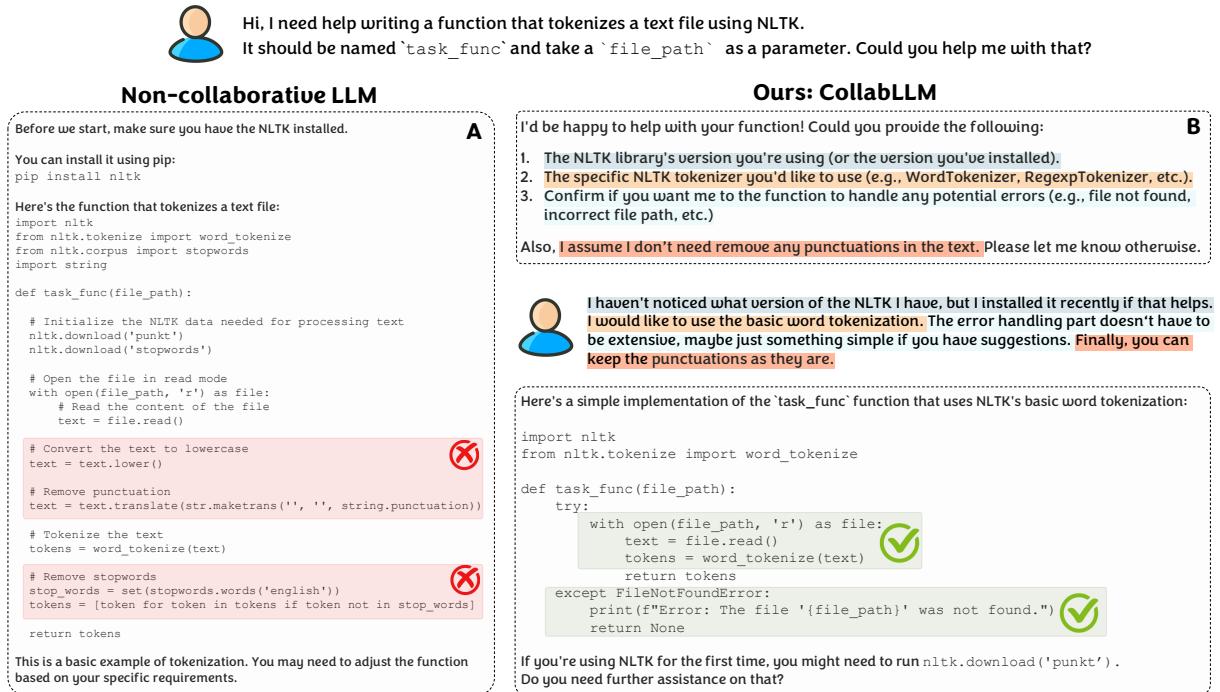
Figure 5 clearly shows the difference. The baseline model provides code that is technically “valid” Python but functionally wrong because it made incorrect assumptions about the user’s requirements. COLLABLLM’s clarifying questions ensure the final code is exactly what the user needed (100% Pass Rate).
Crucially, we can see why the model chose to ask questions by looking at the reward distribution in Figure 6 below.
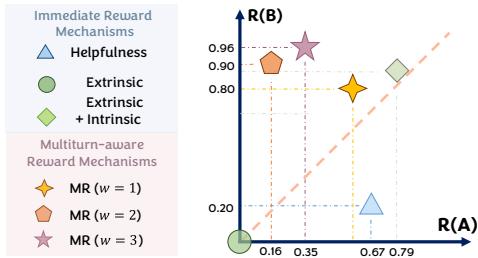
- Helpfulness Reward (Blue Triangle): A standard “helpfulness” judge actually prefers Response A (the immediate code) because it looks like a complete answer.
- Multiturn-aware Reward (Orange/Purple Stars): The MR mechanism assigns a much higher score to Response B (asking questions). Why? Because the simulation showed that Response A leads to bugs and user corrections later, whereas Response B leads to a clean, working solution.
Experimental Results
The researchers tested COLLABLLM on three distinct domains: Document Editing, Coding, and Math.
Quantitative Gains
The results were impressive across the board. The model didn’t just “chat” better; it solved problems better.
- Task Success: Improved by an average of 18.5% across tasks compared to baselines.
- Interactivity: LLM judges rated COLLABLLM 46.3% higher on interactivity.
- Efficiency: Despite asking questions, the overall conversation length (in tokens) decreased because it avoided long correction loops.
An ablation study (analyzing the components) revealed that the “look-ahead” window is critical.
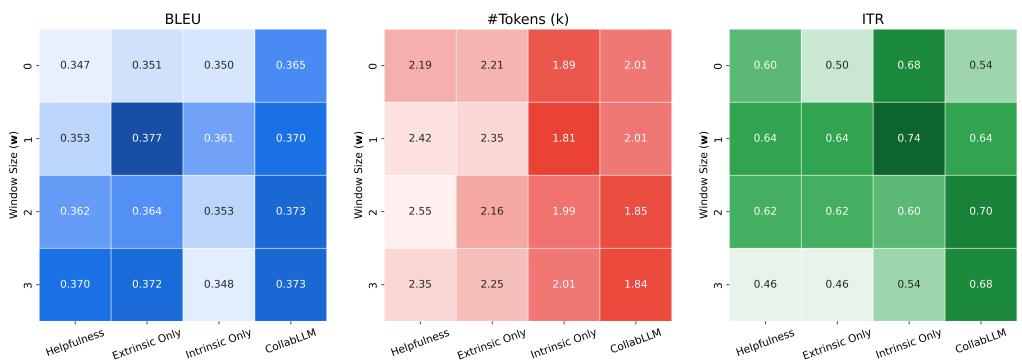
In Figure 9, looking at the MediumDocEdit-Chat task:
- w=0 (Immediate reward only): Lower BLEU scores (task success) and low Interactivity.
- w=2 (Looking 2 turns ahead): A sweet spot where task performance (BLEU) and Interactivity (ITR) significantly increase, while keeping token counts reasonable. This proves that simulating just a couple of steps into the future is enough to drastically change the model’s behavior for the better.
Generalization
A major concern with fine-tuning is overfitting. Does COLLABLLM only know how to ask questions about code or math?
To test this, the researchers ran the model on a completely different benchmark: Abg-CoQA (Ambiguous Conversational Question Answering). This dataset tests whether a model can spot ambiguity in a story.
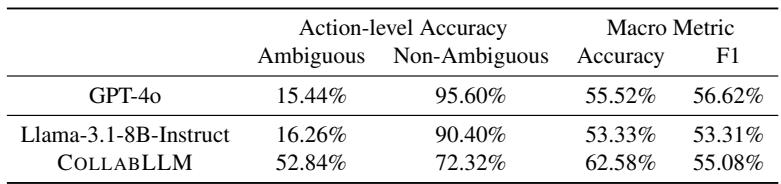
As shown in Table 2, standard Llama-3 and even GPT-4o struggle to identify ambiguity, often guessing the answer (low action-level accuracy on Ambiguous inputs). COLLABLLM, despite never seeing this dataset during training, successfully asked clarifying questions 52.84% of the time when faced with ambiguity, compared to just 15-16% for the baselines. This suggests the model learned a generalizable skill: “If unsure, ask.”
Real-World Human Evaluation
Simulations are useful, but the ultimate test is human interaction. The researchers conducted a study with 201 participants on Amazon Mechanical Turk. Users were asked to co-write documents with an anonymous AI (randomly assigned as Base, Proactive Base, or COLLABLLM).
The results validated the simulation findings:
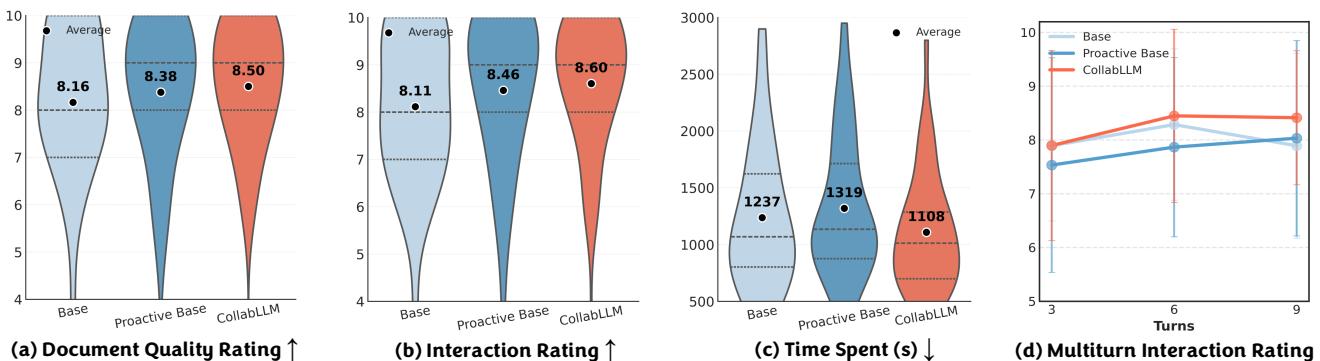
Looking at Figure 7:
- Document Quality (a): Users rated documents produced with COLLABLLM higher (8.50 average vs 8.16).
- Time Spent (c): Users spent significantly less time achieving their goals with COLLABLLM (median ~1100s vs ~1240s).
- Engagement (d): This is the most interesting graph. The “Base” model (blue line) starts with high ratings but drops off as the conversation gets complex. COLLABLLM (red line) actually improves as the conversation goes on. The collaboration gets better the longer it lasts.
Conclusion
COLLABLLM represents a significant shift in how we think about training dialogue agents. By moving from next-token prediction to future-goal prediction, the framework aligns the model’s incentives with the user’s actual needs.
The key takeaways are:
- Passive is Inefficient: Immediate answers often lead to long correction loops.
- Simulation is Powerful: We can use LLMs to simulate users, allowing us to estimate the long-term value of a response without expensive human data collection.
- Active Collaboration Works: Models trained this way are not just more polite; they are more accurate, safer, and faster at solving complex tasks.
As AI models integrate deeper into complex workflows—from software engineering to creative writing—the ability to act as a partner rather than a tool will be the defining characteristic of the next generation of assistants. COLLABLLM offers a robust blueprint for how to build them.