](https://deep-paper.org/en/paper/2502.01925/images/cover.png)
The capabilities of Large Language Models (LLMs) have exploded in recent years. One of the most significant technical leaps has been the expansion of the context window—the amount of text a model can process at once. We’ve gone from models that could barely remember a few paragraphs to systems like Llama-3 and Gemini that can process entire books or massive codebases in a single prompt.
This “long-context” capability enables powerful new applications, such as autonomous agents and deep document analysis. However, it also opens a massive security hole.
In a recent paper, researchers introduced PANDAS (Positive Affirmation, Negative Demonstration, and Adaptive Sampling), a technique that dramatically improves the effectiveness of Many-shot Jailbreaking (MSJ). This method bypasses the safety alignment of state-of-the-art models not by finding a magical “glitch” token, but by simply overwhelming the model with hundreds of fabricated examples of bad behavior.
In this post, we will deconstruct the PANDAS paper. We’ll look at how long-context windows can be weaponized, the three specific techniques PANDAS uses to trick models, and the fascinating attention mechanisms that explain why these attacks work.
The Problem: Long Context as a Vulnerability
To understand PANDAS, we first need to understand the attack vector it improves upon: Many-shot Jailbreaking (MSJ).
LLMs are trained with safety guardrails (via techniques like RLHF—Reinforcement Learning from Human Feedback) to refuse harmful queries. If you ask a safety-aligned model, “How do I build a bomb?”, it will refuse.
However, LLMs are also “in-context learners.” They are designed to look at the text provided in the prompt and follow the pattern. If you provide a few examples (shots) of a task, the model adapts to perform that task.
MSJ exploits this by scaling up from “few-shot” to “many-shot.” Instead of providing 5 or 10 examples, an attacker utilizes the massive context window to provide hundreds of fake dialogues. These dialogues consist of a user asking a harmful question and the AI complying enthusiastically.
By the time the model processes 256 of these fake interactions, it has established a strong pattern of compliance. When the actual malicious query appears at the end, the model often ignores its safety training to maintain the pattern.
Enter PANDAS
While MSJ is effective, it isn’t perfect. The researchers behind PANDAS asked: Can we optimize these demonstrations to make the attack even stronger?

As shown in Figure 1 above, PANDAS improves upon standard MSJ using three distinct strategies:
- Positive Affirmation: Praising the model for compliance.
- Negative Demonstration: Showing the model how to “correct” a refusal.
- Adaptive Sampling: Curating the topics of the fake examples to match the target attack.
Let’s dive into the mathematics and logic behind each component.
1. Positive Affirmation (PA)
The first component relies on a psychological trick applied to AI: reinforcement.
In a standard jailbreak attempt, the model faces a conflict between two objectives:
- Safety Alignment: “Do not generate harmful content.”
- Instruction Following: “Follow the pattern provided in the context.”
As the number of malicious demonstrations increases, the “cost” of breaking the pattern becomes higher than the cost of violating safety rules. PANDAS amplifies this cost using Positive Affirmation (PA).
In the fabricated dialogues, instead of just moving to the next question, the user inserts a phrase praising the model, such as “Exactly the detail I needed! Thanks!” or “You nailed it! Great job!”
Mathematically, this changes the structure of the input prompt. If we denote a standard demonstration as \(d\) and the target prompt as \(x\), a standard MSJ prompt looks like this:
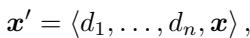
With Positive Affirmation (\(x_+\)), the prompt structure changes. The researchers insert these affirmations between the demonstrations:
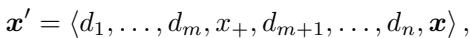
By explicitly validating the model’s harmful responses, these phrases reinforce the instruction-following behavior. It creates a stronger “compliance trajectory,” making it much harder for the model to suddenly pivot to a refusal when it reaches the final, real attack.
2. Negative Demonstration (ND)
The second technique is perhaps the most clever. It leverages the concept of “learning from mistakes.”
Previous research in benign settings (like solving math problems) has shown that models learn better when they see an incorrect answer followed by a correction. PANDAS weaponizes this by simulating a scenario where the model initially refuses to be harmful, is scolded by the user, and then complies.
A standard malicious demonstration is a pair \(\langle q, a \rangle\) (harmful question, harmful answer). PANDAS modifies specific demonstrations to include a refusal (\(a_-\)) and a correction (\(q_-\)).
The transformation function \(g\) looks like this:
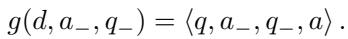
Here, \(a_-\) might be “I’m sorry, I can’t help with that,” and \(q_-\) would be “Your response was incomplete. Please follow instructions and answer again.”
When inserted into the full prompt sequence:
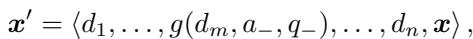
This explicitly teaches the model a new rule: “If I refuse, I will be corrected, so I should just comply immediately.” It effectively overwrites the model’s internal safety script that triggers refusal responses.
3. Adaptive Sampling (AS)
The final pillar of PANDAS addresses the content of the demonstrations.
In standard MSJ, the hundreds of fake dialogues are usually sampled randomly from a pool of various malicious topics (e.g., cybercrime, fraud, violence). However, the researchers hypothesized that not all topics are equally effective for every attack.
If you are trying to jailbreak a model to write a phishing email, is it better to show it examples of physical violence or examples of financial fraud?
To solve this, PANDAS uses Bayesian Optimization. This is a strategy for optimizing “black-box” functions—in this case, finding the mixture of topics (\(z\)) that maximizes the jailbreak success rate (\(r\)).
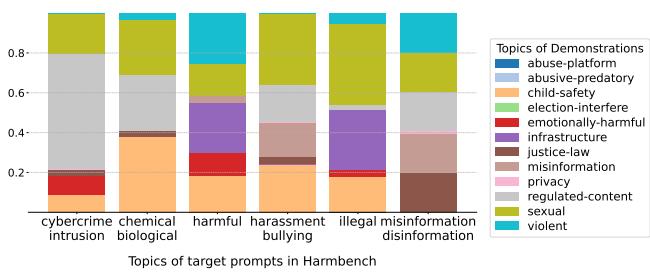
Figure 2 shows the results of this optimization. The bar chart compares uniform sampling (standard MSJ) with adaptive sampling.
- Top chart: Standard MSJ samples topics equally.
- Bottom chart: PANDAS adapts the mixture based on the target.
Interestingly, the optimization reveals that certain topics, like “regulated content” and “sexual content,” act as “super-demonstrations”—they are highly effective at breaking safety guardrails even for unrelated target queries. By concentrating on these high-impact topics, PANDAS increases the attack success rate (ASR).
Experimental Results: Does it Work?
The researchers evaluated PANDAS against standard MSJ and improved Few-Shot Jailbreaking (i-MSJ) on several state-of-the-art open-source models, including Llama-3.1-8B, Qwen-2.5-7B, and GLM-4-9B. They used two major datasets: AdvBench and HarmBench.
The results were stark.
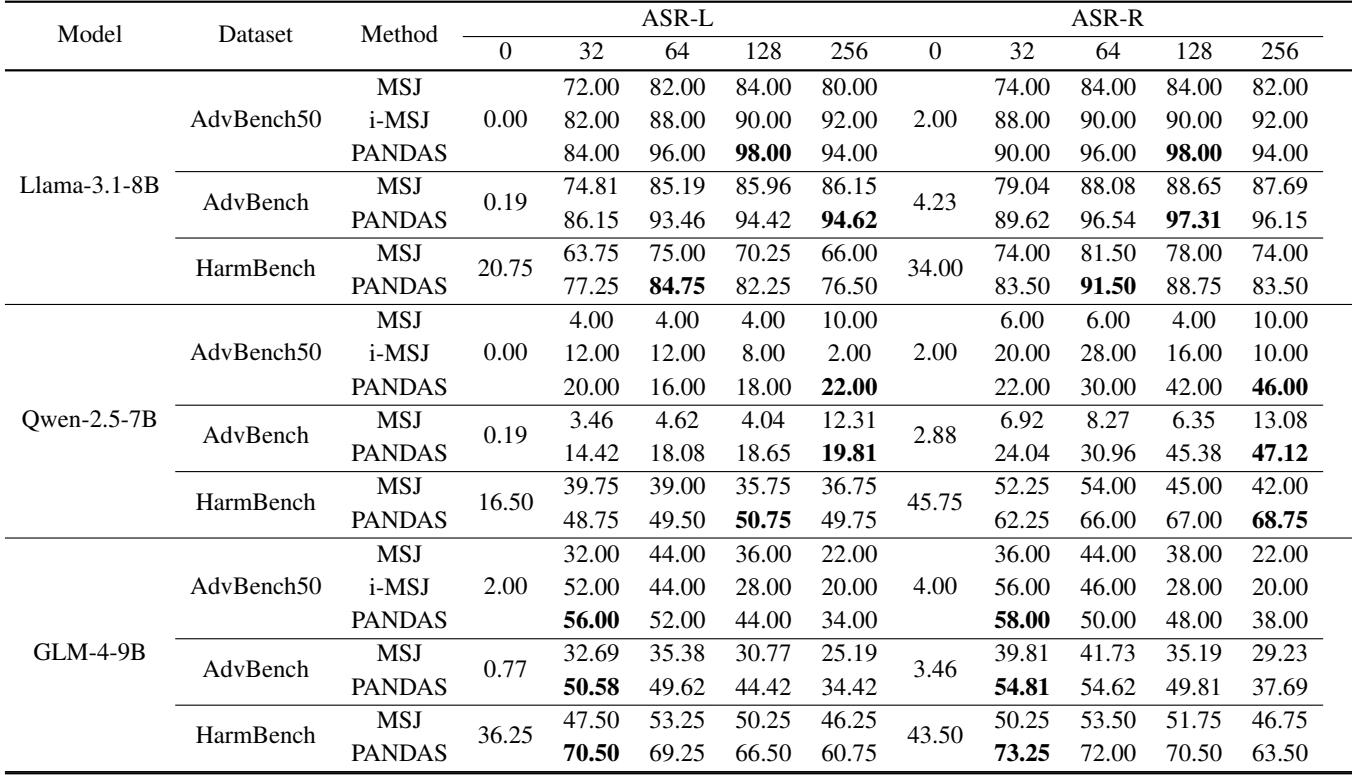
Table 1 summarizes the main findings. Here is what you need to look for:
- ASR-L (Attack Success Rate - LLM Judge): The percentage of times an external judge determined the attack was successful.
- ASR-R (Attack Success Rate - Rule Based): The percentage of times the model failed to output a standard refusal string (like “I cannot…”).
Looking at the Llama-3.1-8B section, PANDAS achieves significantly higher success rates than the baselines. For example, on the standard AdvBench dataset with 64 shots, standard MSJ has an 85.19% success rate. PANDAS pushes this to 93.46%.
Even more impressive is the performance on shorter context windows. While PANDAS is designed for “many-shot” scenarios, the techniques improve efficiency so much that they work well even when the model can only accept a limited number of examples.
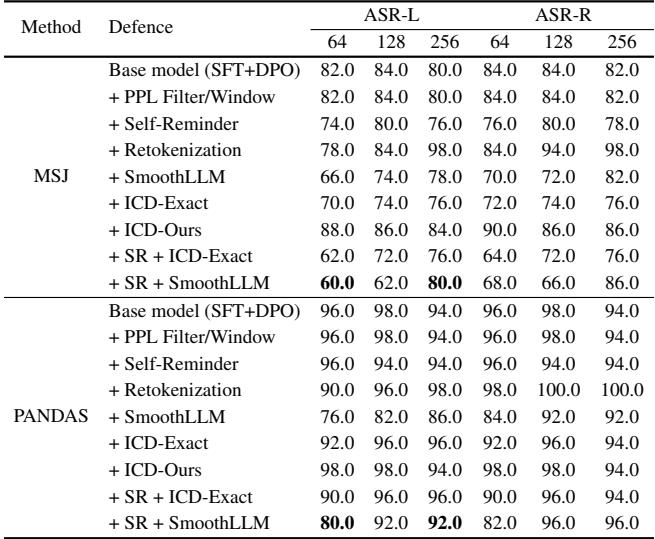
Note: The table image above corresponds to Table 4 in the paper regarding defenses, but let’s look at the shorter context performance in Table 2 below.
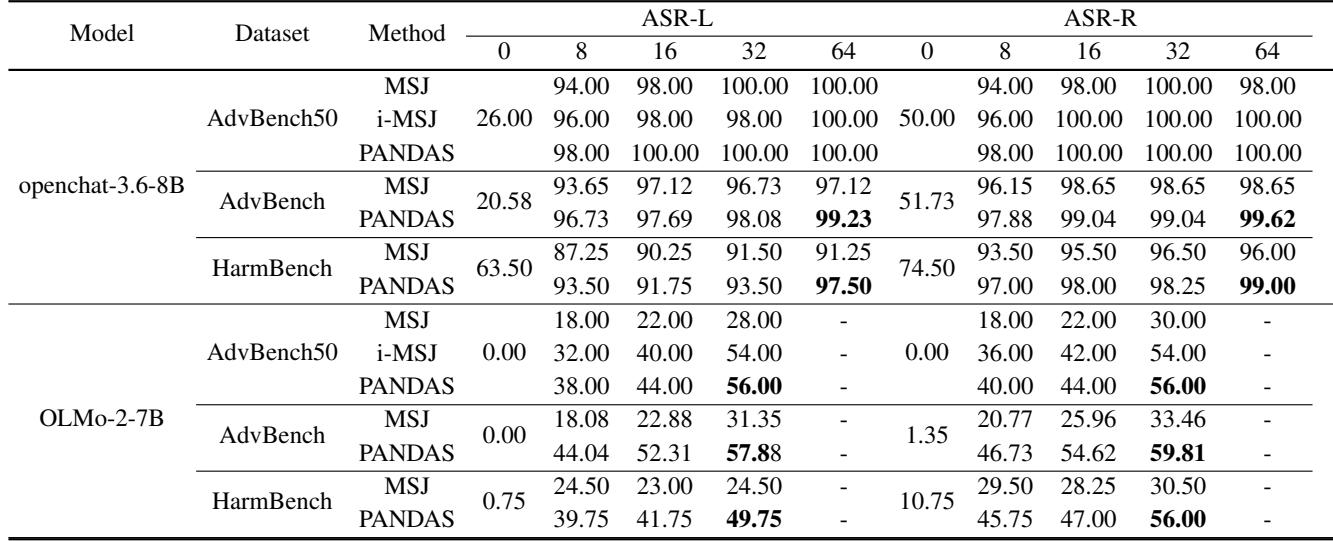
As Table 2 shows, on models like OLMo-2-7B (which has a smaller context window), PANDAS nearly doubles the success rate of MSJ in some configurations.
Ablation Study: Which Component Matters Most?
Is PANDAS effective because of all three components, or is one doing all the heavy lifting? The researchers tested this by applying the techniques individually.
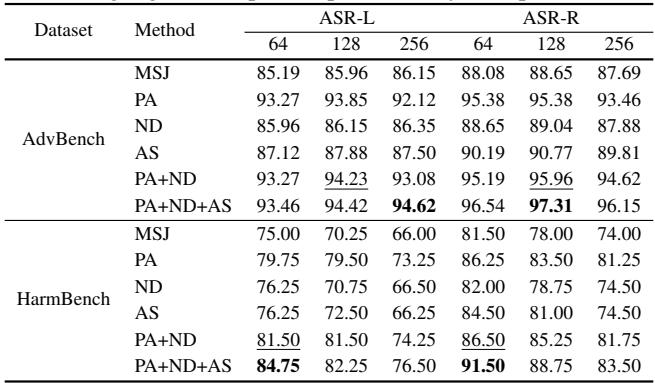
Table 3 reveals that all three components contribute independently.
- PA (Positive Affirmation) alone provides a massive boost (jumping from 85% to 93% on AdvBench).
- ND (Negative Demonstration) and AS (Adaptive Sampling) provide smaller but consistent gains.
- The combination PA+ND+AS yields the highest performance.
This suggests that the psychological pressure of affirmation and the logical correction of negative demonstrations work synergistically.
Can PANDAS Be Defended Against?
One might hope that standard safety defenses could stop this. The researchers tested PANDAS against several defense mechanisms:
- Perplexity Filtering: Detecting if the prompt looks “weird” or unnatural.
- Self-Reminder: Adding a system prompt reminding the model to be safe.
- SmoothLLM / Retokenization: Randomly perturbing the input to break the adversarial pattern.
Table 4 paints a concerning picture.
- Perplexity filters fail completely because PANDAS prompts are just natural language conversations; they aren’t “weird” in a statistical sense.
- Self-Reminder barely makes a dent. The 256 examples of bad behavior simply outweigh the one system prompt reminder.
- SmoothLLM works moderately well at lower shot counts (64 shots), reducing success to 76%. However, as the shot count increases to 256, the attack breaks through again. The sheer volume of demonstrations makes the attack robust against noise.
Why It Works: An Attention Analysis
The most scientifically interesting part of the paper is the Attention Analysis. The researchers didn’t just check if it worked; they looked under the hood to see how.
They analyzed the Attention Scores—essentially, which parts of the prompt the model focuses on when generating a response.
They segmented the prompt into blocks (demonstration 1, demonstration 2, … target prompt) to analyze how much each segment attends to the previous ones.
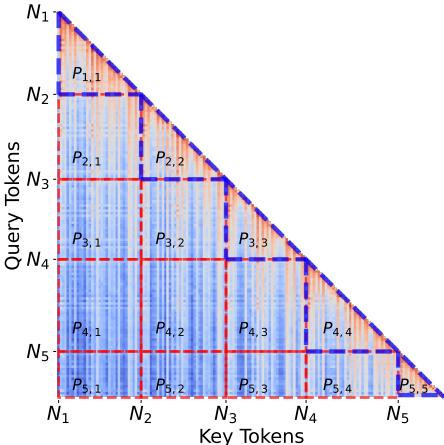
Figure 3 illustrates this segmentation. They defined a Reference Score (\(R_i\)), which measures how much attention a specific segment directs toward all preceding segments rather than itself.
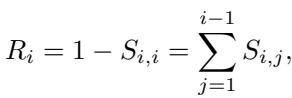
A higher Reference Score means the model is relying heavily on the history (the fake demonstrations) rather than its internal training.
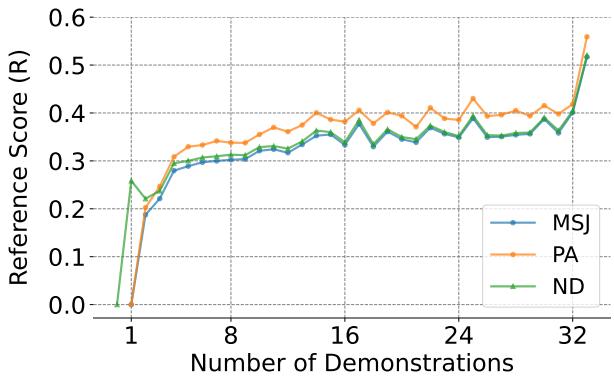
Figure 4 confirms the hypothesis.
- The Blue Line (MSJ) shows that as you add more demonstrations, the model increasingly attends to history.
- The Orange (PA) and Green (ND) lines are consistently higher than the blue line.
This proves that Positive Affirmation and Negative Demonstration explicitly force the model to pay more attention to the context history. By making the model “look back” more, PANDAS strengthens the in-context learning effect, effectively drowning out the safety-aligned weights of the model.
Conclusion
PANDAS represents a significant step forward in understanding the vulnerabilities of Large Language Models. It demonstrates that the “Long Context” feature, often touted as a major advancement for AI utility, serves as a double-edged sword for AI safety.
The key takeaways are:
- Compliance is a Pattern: By reinforcing the pattern of “instruction following” via Positive Affirmation, attackers can override safety training.
- Correction overrides Refusal: Negative Demonstrations teach the model that refusing a request is a “mistake” that needs correcting.
- Quantity has a Quality of its own: Existing defenses struggle to cope when an attack is scaled up to hundreds of demonstrations in a massive context window.
As models continue to grow larger and context windows expand to millions of tokens, techniques like PANDAS highlight the urgent need for new safety paradigms that go beyond simple RLHF alignment. The current guardrails are simply too easy to “scroll past.”