](https://deep-paper.org/en/paper/2502.09838/images/cover.png)
Introduction
In the rapidly evolving landscape of Artificial Intelligence, Large Language Models (LLMs) have made headlines for their ability to pass medical licensing exams and act as diagnostic assistants. However, medicine is not just about text; it is an inherently visual field. Radiologists interpret X-rays, pathologists analyze tissue slides, and surgeons rely on MRI reconstructions.
While recent “Vision-Language” models can look at an X-ray and write a report (comprehension), they often lack the ability to perform the reverse: creating or enhancing medical images based on instructions (generation). Existing models that try to do both often suffer from a “jack of all trades, master of none” problem, where learning to generate images degrades the model’s ability to understand them, and vice versa.
Enter HealthGPT, a groundbreaking unified Medical Large Vision-Language Model (Med-LVLM) developed by researchers from Zhejiang University, Alibaba, and NUS. HealthGPT is designed to handle both medical visual comprehension (like diagnosing a disease from a scan) and generation (like reconstructing a high-resolution MRI from a low-quality scan) within a single framework.
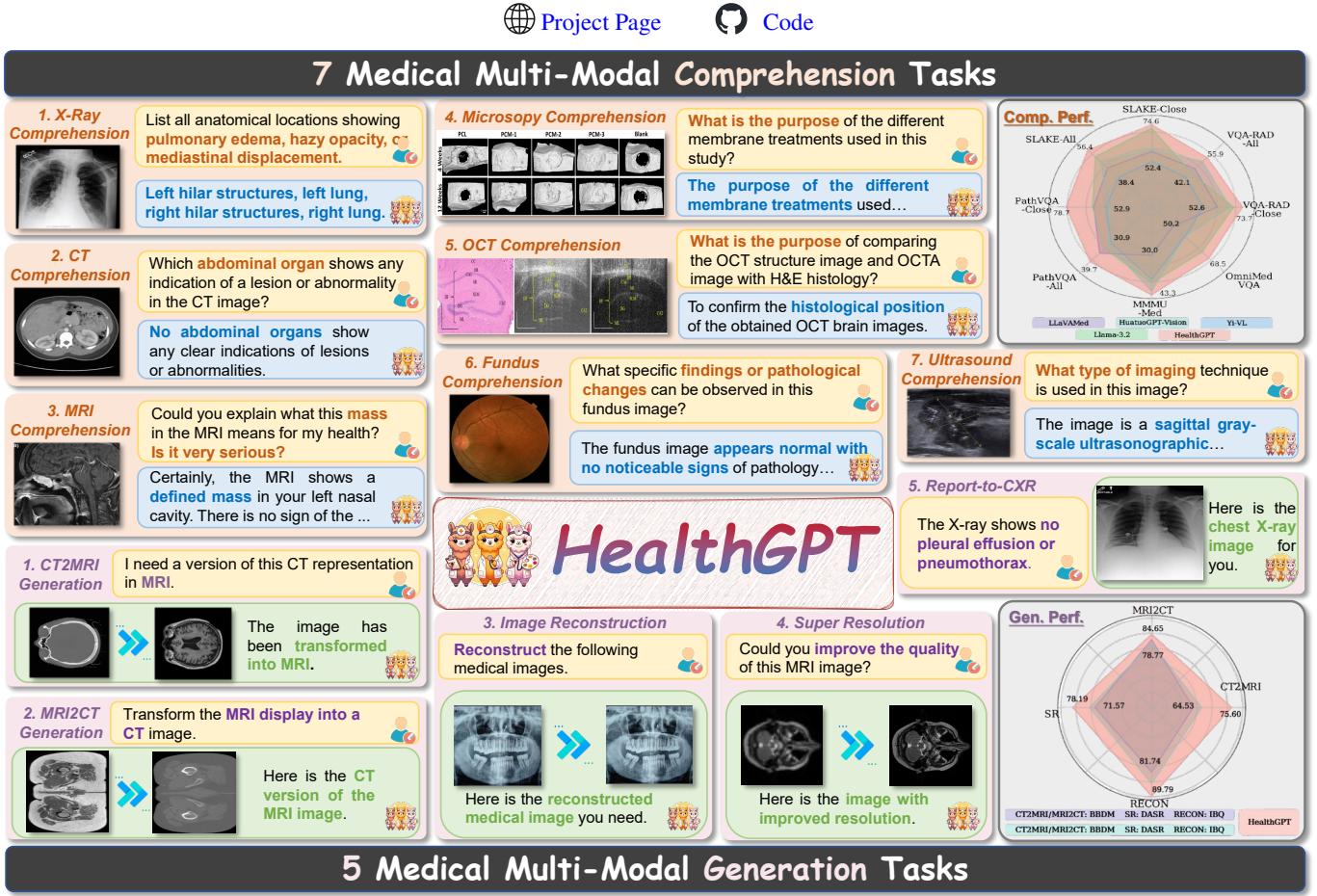
As illustrated in Figure 1 above, HealthGPT covers a vast array of tasks ranging from X-Ray and MRI comprehension to complex generation tasks like converting CT scans to MRI scans. In this post, we will dive deep into the architecture of HealthGPT, explaining how it solves the conflict between comprehension and generation using a novel technique called Heterogeneous Low-Rank Adaptation (H-LoRA).
The Core Problem: The Comprehension-Generation Conflict
To understand why HealthGPT is significant, we first need to understand the difficulty of building a “unified” model.
In the general domain (non-medical), models like GPT-4V or Gemini are starting to handle mixed modalities. However, applying this to medicine presents unique challenges. Medical data is scarce compared to internet data, and it requires high precision.
The researchers identified a critical conflict between the two main goals:
- Comprehension tasks (e.g., “Is there a tumor?”) require the model to abstract away visual noise and focus on high-level semantics.
- Generation tasks (e.g., “reconstruct this image”) require the model to preserve every single pixel detail.
These two goals are fundamentally at odds. If you train a model to be hyper-sensitive to pixel details for generation, it loses the ability to generalize for diagnosis. If you train it to abstract concepts for diagnosis, it becomes terrible at generating detailed images.
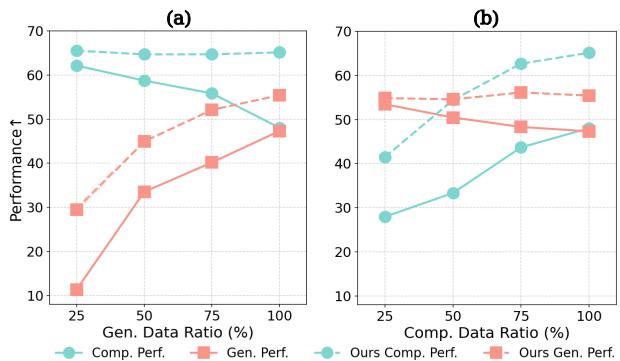
Figure 2 vividly illustrates this “seesaw” effect. In chart (a), as the ratio of generation data increases (x-axis), the comprehension performance (cyan line) drops. Conversely, in chart (b), focusing too much on comprehension data hurts generation performance.
The HealthGPT team needed a way to decouple these conflicting requirements while keeping them in one unified model.
The HealthGPT Architecture
HealthGPT is built on a “bootstrapping” philosophy. Instead of training a massive model from scratch, it adapts a pre-trained Large Language Model (LLM) using visual encoders.
The architecture treats everything as a token. Text input is tokenized, and images are converted into discrete visual tokens. This allows the LLM to process images and text in a unified, autoregressive manner—predicting the next token one by one.
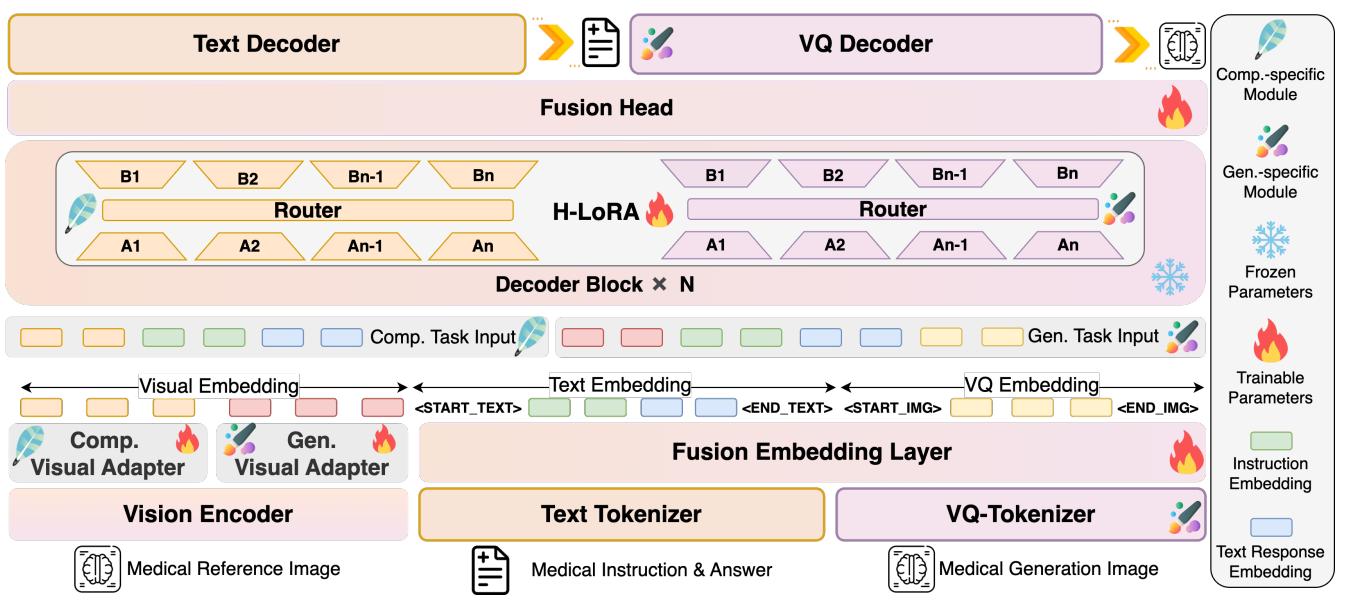
As shown in Figure 3, the architecture has two main innovations that distinguish it from standard multimodal models:
- Hierarchical Visual Perception (HVP)
- Heterogeneous Low-Rank Adaptation (H-LoRA)
Let’s break these down step-by-step.
1. Hierarchical Visual Perception (HVP)
Standard vision models feed the final layer of a Vision Transformer (ViT) into the LLM. The HealthGPT researchers realized that the “conflict” we discussed earlier starts at the visual encoding level.
- Deep layers of a ViT contain abstract, semantic information (perfect for answering questions).
- Shallow layers contain concrete, fine-grained details (perfect for reconstructing images).
Instead of forcing the model to use just one output, HealthGPT dynamically selects the visual features based on the task.
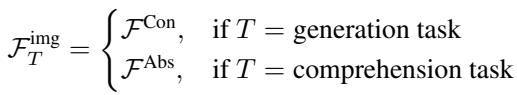
As defined in the equation above, if the task is generation (\(T = \text{generation task}\)), the model uses Concrete-grained features (\(\mathcal{F}^{\mathrm{Con}}\)) from the shallow layers. If the task is comprehension, it uses Abstract-grained features (\(\mathcal{F}^{\mathrm{Abs}}\)). This ensures the LLM receives the right kind of visual information for the job at hand.
2. Heterogeneous Knowledge Adaptation (H-LoRA)
This is the engine room of the paper. Fine-tuning a massive LLM (like Llama or Phi) is computationally expensive. A common technique to solve this is LoRA (Low-Rank Adaptation). LoRA freezes the main model weights and trains small, low-rank matrices to inject new knowledge.
However, a single LoRA module struggles to hold the conflicting knowledge required for both medical drawing and medical seeing.
The researchers introduced H-LoRA, which treats comprehension and generation knowledge as “heterogeneous” (different in kind). It stores this knowledge in independent “plugins” (sets of LoRA parameters) and dynamically routes the input to the correct plugin.
The Mathematics of H-LoRA
In a standard LoRA, the modification to the model weights is calculated as \(\Delta W = AB\), where \(A\) and \(B\) are small matrices.
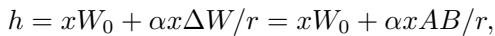
In H-LoRA, the model doesn’t just have one set of \(A\) and \(B\). It has task-specific sets.
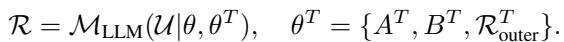
Here, \(\theta^T\) represents the parameters specific to the task \(T\). But HealthGPT goes further than just simple task switching. Within a specific task, it uses a Mixture of Experts (MoE) approach efficiently.
Usually, MoE is slow because it requires computing many different matrix multiplications. H-LoRA optimizes this by merging the expert matrices into one large matrix.
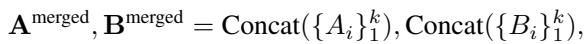
By concatenating the experts (\(A_i\) and \(B_i\)) into \(\mathbf{A}^{\mathrm{merged}}\) and \(\mathbf{B}^{\mathrm{merged}}\), the model can perform the computation in a single pass. A “router” determines which experts contribute to the output.
The routing weights \(\mathcal{W}\) are calculated and then expanded to match the dimensions of the merged matrices:
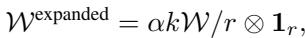
Finally, the output of the H-LoRA module is computed via element-wise multiplication (\(\odot\)) and standard matrix multiplication, which is computationally much faster than standard MoE implementations:
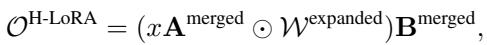
This output is added to the frozen pre-trained weights (\(W_0\)) to get the final result:
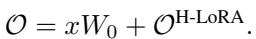
Why is H-LoRA Better?
The researchers compared H-LoRA against standard LoRA and MoE-LoRA (Mixture of Experts LoRA).
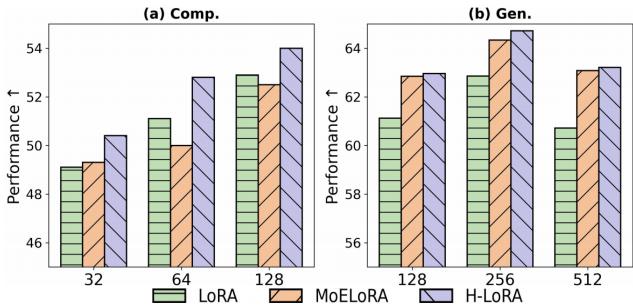
Figure 5 shows the results. H-LoRA (the purple bars) consistently achieves higher performance in both comprehension (Comp) and generation (Gen) tasks across different model sizes (ranks). Crucially, it does this without the massive training time penalty usually associated with Mixture of Experts models.
Three-Stage Training Strategy
To train this complex architecture effectively, the team used a three-stage pipeline:
- Multi-modal Alignment: They trained separate adapters for comprehension and generation to align the visual encoder with the LLM. The LLM itself was frozen.
- Heterogeneous H-LoRA Plugin Adaptation: They froze the H-LoRA modules and only trained the embedding layers and output heads using mixed data. This creates a “unified base” where text and visual tokens can coexist.
- Visual Instruction Fine-Tuning: Finally, they trained the H-LoRA plugins on specific downstream tasks (like “convert this CT to MRI”).
The VL-Health Dataset
A model is only as good as its data. Since no dataset existed that combined medical QA with medical image generation, the researchers curated VL-Health.

As shown in Figure 4, VL-Health is comprehensive. It aggregates classic datasets like VQA-RAD and SLAKE for comprehension, while incorporating datasets for Super-Resolution (IXI) and Modality Conversion (SynthRAD2023) for generation. This balanced diet of data allows HealthGPT to learn its dual nature.
Experimental Results
So, does it work? The researchers tested HealthGPT against several benchmarks.
Comprehension Performance
First, they checked if the model could still “see” and understand medical images.
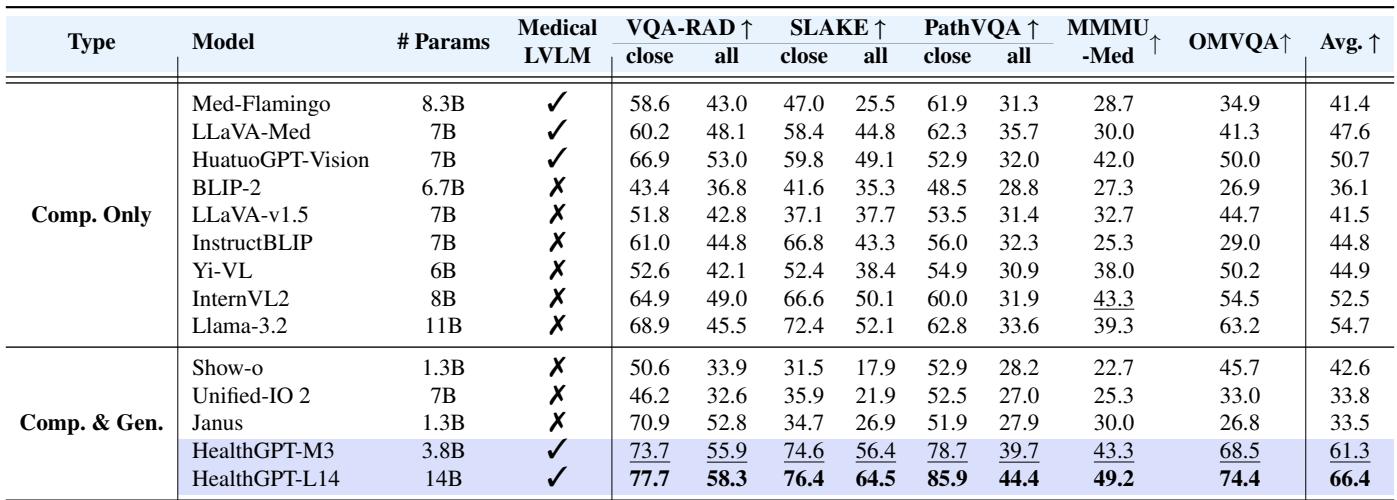
Table 1 highlights HealthGPT’s dominance.
- HealthGPT-M3 (3.8B params) outperforms massive general models like Unified-IO 2 (7B) and medical-specific models like LLaVA-Med.
- HealthGPT-L14 (14B params) sets a new state-of-the-art across almost every metric, including VQA-RAD and SLAKE.
This proves that adding generation capabilities did not hurt the model’s ability to understand images—in fact, thanks to the H-LoRA decoupling, it excels.
Generation Performance: Modality Transfer
One of the most impressive capabilities of HealthGPT is Modality Transfer. This is the ability to take a CT scan (which uses X-rays) and hallucinate an accurate MRI scan (which uses magnetic fields) of the same anatomy. This is incredibly difficult because CTs and MRIs highlight different tissues.
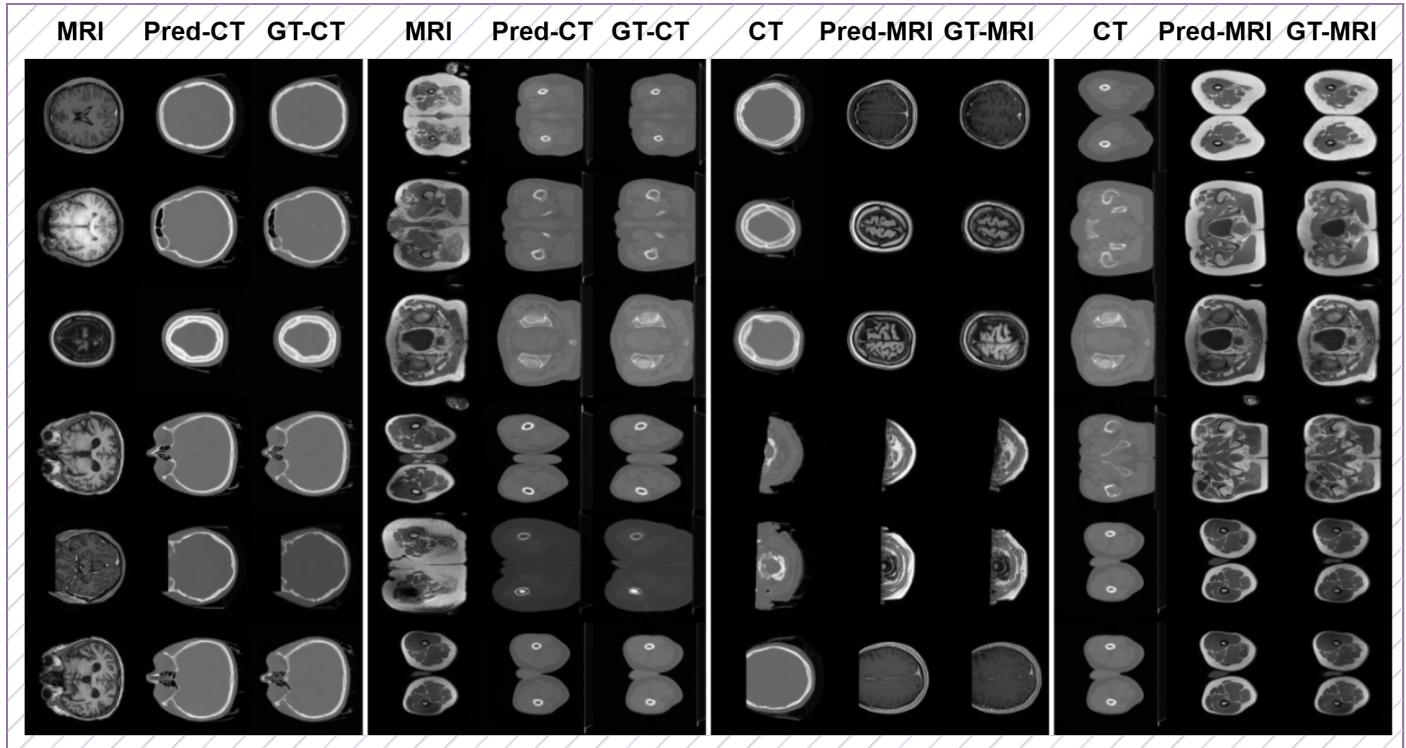
Figure 11 shows the results. The “Pred-MRI” (Predicted MRI) columns generated by HealthGPT are strikingly similar to the “GT-MRI” (Ground Truth) columns. The model accurately predicts the soft tissue contrast of the brain and abdomen, translating the Hounsfield units of a CT into the signal intensities of an MRI.
Generation Performance: Super-Resolution
Another critical task is taking a low-quality, blurry MRI and reconstructing it into a high-resolution image.
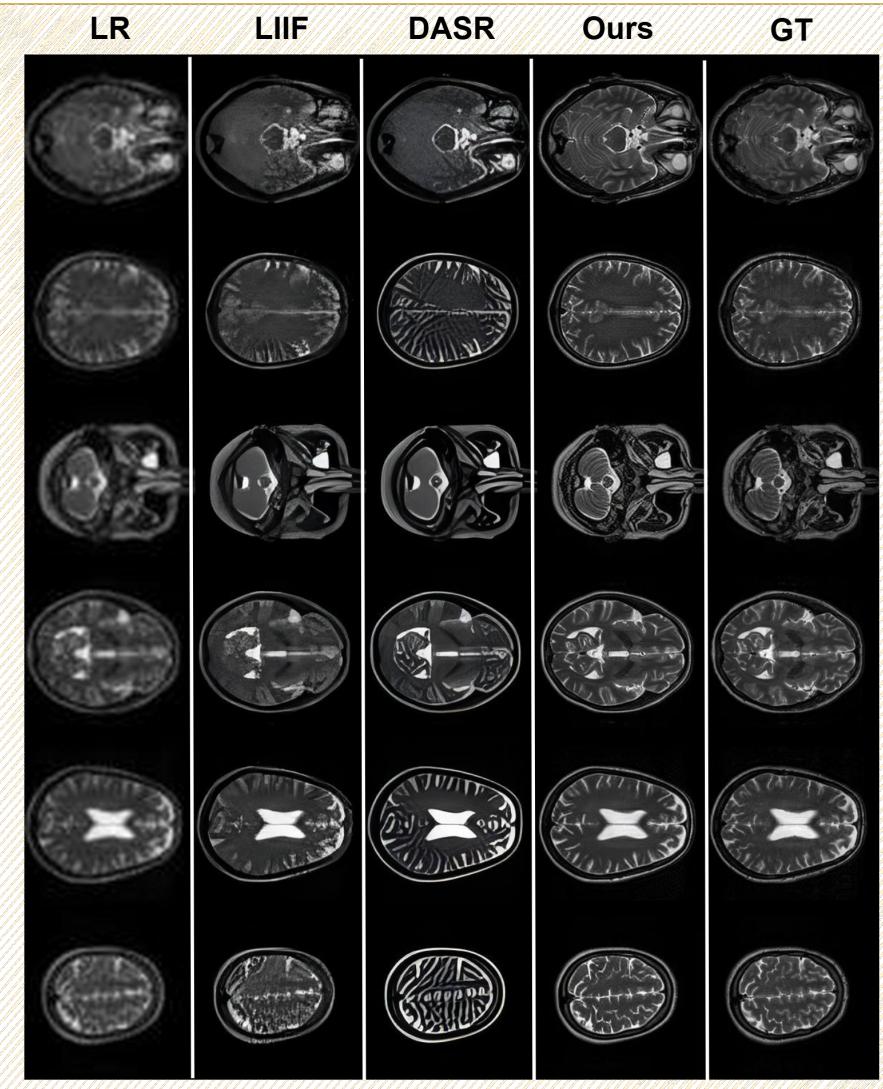
In Figure 12, compare the “LR” (Low Resolution) column with the “Ours” (HealthGPT) column. The difference is night and day. HealthGPT restores the fine folding patterns of the brain’s cortex that are completely lost in the low-resolution input.
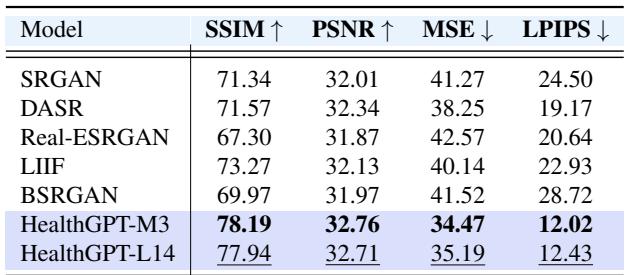
Quantitative results for this task (shown in Table 3 below) confirm that HealthGPT achieves higher Structural Similarity (SSIM) and Peak Signal-to-Noise Ratio (PSNR) than dedicated super-resolution models like SRGAN or SwinIR.
Conclusion and Implications
HealthGPT represents a significant step forward in Medical AI. By acknowledging the inherent conflict between visual abstraction (comprehension) and visual detail (generation), the authors designed an architecture that respects both.
The key takeaways are:
- Unified Capability: It is possible to build a single model that acts as both a radiologist (interpreting images) and a medical artist (reconstructing images).
- Architectural Innovation: H-LoRA and Hierarchical Visual Perception are effective techniques for managing heterogeneous knowledge in Large Language Models.
- Scalability: The methods work on smaller models (3.8B parameters) and scale well to larger ones (14B parameters).
For students and researchers, HealthGPT serves as a masterclass in parameter-efficient fine-tuning. It demonstrates that we don’t always need to retrain massive models from scratch; with clever engineering like H-LoRA, we can adapt existing powerful LLMs to perform highly specialized, complex tasks in critical domains like healthcare.
As these unified models mature, we may soon see AI assistants that don’t just write reports, but actively help enhance the quality of the medical imaging data itself, leading to faster and more accurate diagnoses.