](https://deep-paper.org/en/paper/2502.14791/images/cover.png)
Humans pick up words astonishingly quickly. Give a child a handful of sentences that use an unfamiliar word like “ski” — “Susie learned to ski last winter,” “People ski on tall mountains where there’s lots of snow,” “I saw Susie ski fast down the snowy mountain” — and the child will often infer that “ski” is a verb related to sliding on snow. That single-shot, flexible generalization is a hallmark of human language acquisition.
Large language models (LLMs), by contrast, get their knowledge from massive corpora. They perform well on many tasks, but they are surprisingly brittle when it comes to rare or unseen words: without many examples, they often fail to generalize the way humans do. Is that gap inevitable? Or can we train models to learn new words quickly and systematically using only a few contextual examples?
This post walks through a recent paper from researchers at NYU and MIT that answers this question in the affirmative. The method is called Minnow (Meta-training for IN-context learNing Of Words). Rather than creating embeddings for every new word or retraining on huge corpora, Minnow meta-trains models to get better at the process of learning a word from its usages — a meta-learning approach for in-context learning. The results are striking: models trained with Minnow from human-scale child-directed data acquire strong few-shot word-learning abilities, and Minnow finetuning can further improve the in-context learning of large pre-trained LLMs.
Below I’ll unpack the problem, explain Minnow step by step, and walk through the experiments and key findings — with curated figures from the paper to make the ideas concrete.
Why this matters (short version)
- It demonstrates that few-shot word learning can be learned as a general capability rather than recovered from massive memorized examples.
- Minnow is data-efficient: models trained on datasets comparable to a child’s yearly linguistic input develop robust few-shot word learning.
- Minnow can be used either to train small models from scratch or to finetune large LLMs in a parameter-efficient way.
What Minnow is solving: the rare-word problem Natural language follows a Zipfian distribution: a few words are abundant and many are rare. LLMs see the frequent words thousands or millions of times but often have only a handful (or zero) examples of rare words, and new words enter the language continuously. Prior approaches often try to construct a new embedding for a novel word (by aggregating context embeddings or using morphological cues). These can work, but they typically treat learning each new word as a separate engineering task. Minnow asks a different question: can we train a model to acquire the general skill of inferring a word’s meaning from a few contextual usages and then deploy that skill to any novel token?
The Minnow idea in one paragraph
Minnow is meta-training for in-context learning focused on word acquisition. During meta-training, each episode hides (masks) a chosen low-frequency word by replacing every occurrence with a single shared placeholder token (e.g., [new-token]). The episode provides a small set of example sentences containing the placeholder; the model’s objective is standard next-token prediction on a concatenated sequence of these examples, which forces the model to use the context to anticipate plausible continuations that reuse the placeholder appropriately. Repeating this across many different words trains the model to learn to learn new word meanings from context, rather than to memorize specific lexemes.
High-level illustration of Minnow vs. ordinary language modeling
![Illustration of the Minnow training process (top) compared to standard language modeling (bottom). Minnow episodes use a placeholder <code>[new-token]</code> to teach the model to learn from context.](/en/paper/2502.14791/images/001.jpg#center)
Figure 1: Minnow frames meta-learning episodes (top): a word is masked by a shared placeholder and the model must predict new usages from a few study examples. Ordinary language-modeling episodes (bottom) remain interleaved to preserve general fluency. The key is meta-training across many episodes so the model learns a general in-context word-learning strategy.
Step-by-step: how Minnow constructs an episode
- Pick a target low-frequency word w from the corpus (e.g., “ski” or “aardvark”).
- Collect K example sentences that use w. These are the “study examples.”
- Replace every occurrence of w (in those sentences) with the same placeholder token, e.g.,
[new-token]. Crucially, that same placeholder is reused for every episode and every word; the model cannot rely on different embeddings per word. - Concatenate the K masked sentences into a single sequence, separating sentences with a special separator token (e.g.,
<sep>). - Train the model on next-token prediction over this sequence. Because the masked token appears in multiple different contexts, to predict subsequent tokens the model must infer how
[new-token]functions from context and apply that understanding to generate coherent continuations.
Why use a single shared placeholder? Using a single placeholder across episodes prevents the model from learning in-weights representations for specific masked words. The model must form an on-the-fly contextual interpretation of the placeholder based on the study examples in the episode. This directly targets in-context learning: the model practices forming ephemeral context-dependent meanings rather than creating a new permanent embedding.
Held-out word classification: a discriminative probe One of the main evaluation tasks in the paper is a held-out word classification task that measures whether a model can use study examples to correctly attribute a held-out query sentence to the right candidate word. The setup is simple:
- For C candidate words, collect K − 1 study examples for each candidate.
- For one candidate, sample a query sentence that uses the same word (masked).
- For each candidate context, prepend its study examples to the query and compute the model’s conditional likelihood of the query given that context. The model selects the candidate whose context gives the highest likelihood.
This test directly evaluates whether the model can match a usage to the correct learned context based on a few examples.
Example of a held-out classification episode
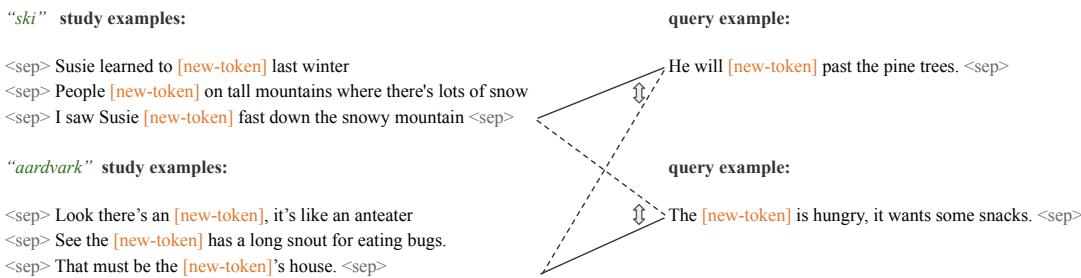
Figure 2: For each candidate word (left), a context of study examples is provided. A query (right) uses the masked token. The model evaluates which context makes the query more likely.
Training data: child-directed and child-scale corpora To test data efficiency, the authors used two corpora designed to resemble children’s linguistic input:
- CHILDES: transcriptions of child–caregiver interactions (filtered to caregiver speech). Small but speech-like and child-directed.
- BabyLM-10M: the 10-million-word BabyLM track corpus, a curated mix that includes child-directed data and other child-appropriate sources.
From each corpus they constructed a meta-learning component (the masked-word episodes for many low-frequency words) and a language-modeling component (remaining sentences). For models trained from scratch, language-modeling episodes are interleaved with Minnow episodes to learn general fluency; for finetuning large pre-trained LLMs, only the Minnow episodes were used (the LLM already knows general language).
Training small models from scratch: can a Minnow learn like a child? The authors trained modestly sized autoregressive Transformers (roughly 100M parameters) from scratch with Minnow on both CHILDES and BabyLM-10M. The models used word-level tokenization and treated selected low-frequency word-forms as meta-learned words; those word-forms were removed from the vocabulary to prevent in-weights learning of them.
Key result (from-scratch): held-out classification
- Models trained from scratch with K = 5 examples per episode achieved 4-way classification accuracies of ~72% (CHILDES) and ~77% (BabyLM-10M).
- These numbers are only a few percentage points shy of the Llama-3 8B baseline (pretrained on vastly more data), which achieved ~71–78% in the same tasks.
Why this is surprising: despite training on a tiny, child-scale dataset, Minnow-equipped small models approached the performance of a much larger model trained on orders of magnitude more data. That strongly suggests the few-shot word-learning capability is learnable with modest amounts of data if the model is trained on the right objective.
Finetuning large LLMs with Minnow The second thread of experiments asks whether Minnow can improve an already strong LLM. The authors finetuned Llama-3 8B (and also Llama-2 7B in some comparisons) using Minnow episodes from BabyLM-10M. Importantly, finetuning was highly parameter-efficient: all model weights were frozen except the input and output embeddings for the two special tokens (placeholder and separator). These special-token embeddings were initialized as the mean of existing embeddings and then updated during Minnow finetuning.
Held-out classification: Llama-3 8B + Minnow
- On BabyLM-10M, finetuning Llama-3 8B with Minnow raised 4-way classification accuracy from 78% → 87% (an improvement of ~9 points).
- On CHILDES, accuracy improved from 71% → 79%.
Those gains indicate that Minnow finetuning substantially sharpens an LLM’s ability to use a few contextual examples to identify the correct meaning/usage for a masked token.
Going beyond discrimination: what exactly do models learn? A potential criticism of the held-out classification task is that it might exploit superficial contextual coherence: the correct context and query might use strongly overlapping topics, and a model could succeed by matching topical coherence rather than learning the word’s function. To probe deeper, the authors ran additional evaluations that isolate syntactic and generative understanding.
Syntactic category classification This task asks whether a model can infer the grammatical category (noun/verb/adjective/adverb) of a novel word from one or a few examples, then generalize that category to new sentences that are semantically different. It eliminates the topical coherence shortcut and tests understanding of syntactic behavior.
Key result (syntactic categories)
- Llama-3 8B baseline: ~66% mean accuracy on the 4-way syntactic classification task (chance = 50%).
- Llama-3 8B + Minnow: ~83% mean accuracy.
- Models trained from scratch with Minnow also performed well (BabyLM-trained models ~77% mean).
This is important: Minnow helps models infer the syntactic distributional signature of a word from minimal context, and apply that syntactic inference to novel usages.
Syntactic classification visual summary
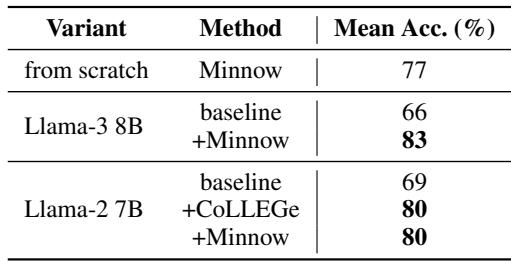
Figure 3: Accuracy across category-pair discrimination tasks (e.g., noun vs. verb). Minnow finetuning improves the LLM’s ability to infer grammatical category from a few usages and generalize to novel contexts.
Generative evaluation: can the model use the new word? Classification and syntactic tests show the model can identify which context fits a query or which category a word belongs to. But the most natural test of practical word learning is generative: given a few examples, can the model produce a novel, coherent usage of the learned word? And can it generate a reasonable dictionary-style definition from one or a few usages?
New usage example generation
- Procedure: Give the model K − 1 study examples (masked with the placeholder), prompt it to continue (generate a new usage example ending with the separator token), and collect the generated sentence.
- Evaluation: Head-to-head comparisons judged by an LLM (GPT-4o) and limited human annotation: present the baseline LLM’s generation and the Minnow-finetuned model’s generation and ask which is a better next example.
Summary results
- Across multiple datasets (BabyLM-10M test split, Chimera), the Minnow-finetuned models’ generated usage examples were preferred more often than baseline Llama generations in automatic LLM-judged comparisons and in human judgments.
- The Minnow model often produced syntactically correct, semantically plausible new usages that aligned with the inferred meaning from the study examples.
Qualitative examples Here is an example from the BabyLM-10M test set. Given several study examples referencing an ancient civilization in Turkey, the Minnow generation produced:
- “the [new-token] were a people who lived in the area of turkey.”
This shows semantic generalization: the model inferred that the token denotes an ancient people and used it correctly in a syntactic frame for a plural noun.
Example generation illustration

Figure 4: The Minnow model generates plausible usage sentences (greedy decoding shown). Generations may sometimes copy specifics from study examples or introduce plausible but incorrect details when sampling; this mirrors the behavior of many generative LMs.
Definition generation
- Task: Given one or a few usage examples, prompt the model to generate a short definition of the masked word.
- Datasets: CoLLEGe-DefGen (constructed with GPT-4 examples) and the Oxford test set (dictionary examples).
- Metrics: BERTScore F1 and ROUGE-L against ground-truth definitions; head-to-head comparisons via GPT-4.
Results (1-shot definitions)
- Minnow finetuning improved Llama-3 8B baseline BERTScore and ROUGE-L by modest but significant amounts on CoLLEGe-DefGen and Oxford.
- In head-to-head comparisons, GPT-4 and human evaluators often preferred definitions produced by Minnow-finetuned models.
Illustrative 1-shot definition Given the sentence “Despite his greed, the businessman felt bound by a [new-token] to maintain ethical practices,” the Minnow model generated:
- “a promise or agreement to do something.”
This captures a central aspect of “categorical imperative” (a moral obligation) from a single, nuanced example: an impressive contextual inference, even if not perfectly precise.
Definition generation scores
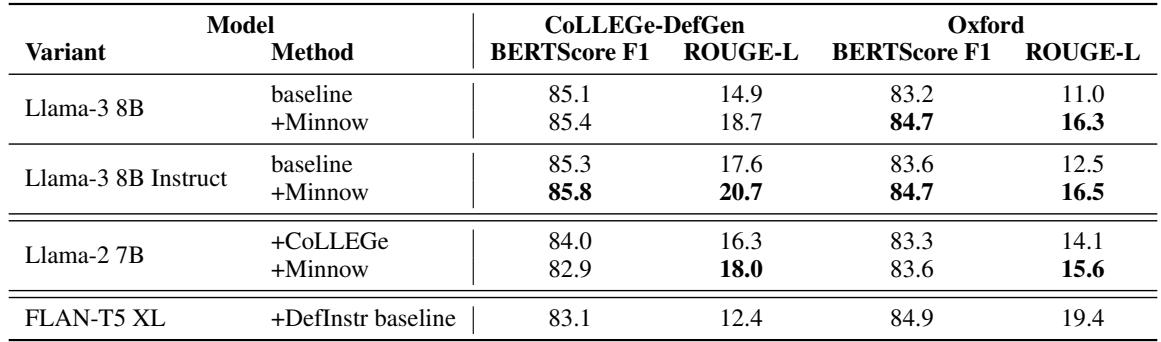
Figure 5: Minnow finetuning improves automatic scores for 1-shot definition generation. Improvements are modest but consistent; the model is better at extracting definitional content from sparse context.
A quick scoreboard (high-level)
- Minnow-trained small models (from scratch): strong few-shot classification and syntactic inference, comparable to large pre-trained models in the held-out classification task.
- Minnow-finetuned Llama-3 8B: large gains in held-out classification (≈+8–10 points), syntactic category discrimination (≈+17 points), and improved generative behavior (usage examples and definitions preferred more often).
- Comparisons to other methods (e.g., CoLLEGe, which learns embeddings for new words) generally favor Minnow for flexible, context-driven generalization.
Limitations and caveats The paper is careful to point out several limitations — important when interpreting the results.
Text-only and aggregated inputs. Human word learning typically includes multimodal grounding (visuals, actions) and arises from a single agent’s stream of experience. Minnow operates on text corpora aggregated across many sources and is ungrounded.
Single-placeholder representation. All new words are represented by the same placeholder token. This design encourages in-context learning but does not reflect how humans assign distinct phonological forms and morphologies to words. The method also doesn’t model continual accumulation of multiple learned words as persistent tokens in the model’s vocabulary.
Possible leakage in finetuning evaluations. When finetuning pre-trained LLMs, some evaluation words may actually appear in the model’s pretraining data; finetuning thus may help the model use existing memorized knowledge more effectively rather than learn genuinely novel words. The from-scratch experiments avoid that confound.
Generative evaluation metrics. Automatic metrics (ROUGE, BERTScore) and LLM-based judges like GPT-4 are imperfect and can be biased. The paper includes limited human evaluation but suggests larger human studies are an important next step.
Morphology and lexeme vs. word-form distinctions. The datasets treat different inflections as distinct word-forms, which simplifies some aspects but complicates others. The approach could be extended to incorporate morphological structure explicitly.
Why Minnow is conceptually appealing
- Minnow trains the ability to learn, rather than training to memorize. By maximizing next-token likelihood across many masked-word episodes, the model optimizes a general inference procedure for mapping contextual patterns to inferential uses (syntactic role, semantic class, typical continuations).
- The single shared placeholder removes surface-form cues and forces a context-driven strategy.
- Minimal finetuning (only special-token embeddings) is enough to adapt large models, which is an attractive property for practical deployment.
Takeaways for practitioners and researchers
- If your goal is to make models better at using new words from a few textual examples, consider meta-training (or meta-finetuning) objectives that explicitly practice that skill.
- Minnow demonstrates that data efficiency is achievable: human-scale datasets can yield powerful inductive abilities when the training objective matches the target cognitive skill.
- For production systems where vocabulary drift is an issue, Minnow-like finetuning could be a low-cost, targeted way to improve adaptability without large-scale retraining.
Conclusion Minnow reframes rapid word learning as a meta-learning problem: practice learning many different words from few contextual usages, and the model will learn a general, transferable strategy. The method succeeds both when training modest-size models from scratch on child-scale data and when finetuning large pre-trained LLMs in a parameter-efficient way. Minnow’s gains on discriminative and generative evaluations demonstrate that in-context few-shot word learning is a learnable capability — and one that can be acquired without gargantuan corpora, provided the training objective teaches the model how to learn.
This line of work opens exciting directions:
- Extend Minnow to grounded, multimodal inputs where words are paired with perceptual referents.
- Explore continual/meta-training regimes that let models accumulate persistent lexical knowledge while preserving the ability to learn ephemeral meanings in context.
- Combine Minnow-style meta-training with morphological priors so models can exploit form-meaning links where appropriate.
If you want to dig deeper, the authors released code and dataset-processing scripts to reproduce many of the experiments (see the paper for the link). Minnow shows that a model’s capacity to learn new language patterns can be taught explicitly — a promising nudge toward more flexible, human-like language understanding.
Key references (select)
- Min et al., MetaICL (2022): meta-training for in-context learning across tasks.
- Teehan et al., CoLLEGe (2024): meta-learning for generating embeddings for new words.
- Lake & Baroni (2023): meta-learning for systematic generalization.
- The Minnow paper: Wentao Wang, Guangyuan Jiang, Tal Linzen, Brenden M. Lake — “Rapid Word Learning Through Meta In-Context Learning.”
Generated examples and judgment summaries
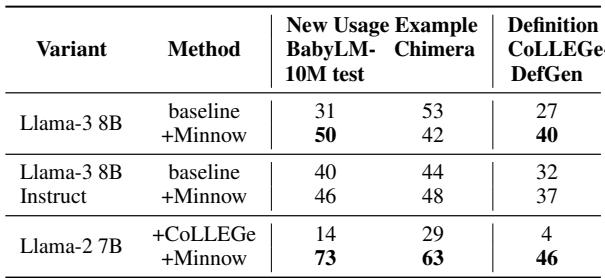
Figure 6: Pairwise comparisons of generated usage examples and generated definitions. Minnow-finetuned models win more often in GPT-4 judgments, and limited human evaluation corroborates the improvement.
A concrete definition example

Figure 7: Given a single usage example, Minnow generates a definition that captures core meaning though not necessarily full dictionary precision (“a promise or agreement to do something” vs. canonical philosophical phrasing).
Final thought Minnow shows that models can be taught to be better learners. That shift — from training models that store facts to training models that practice inference strategies — is likely to be important for building systems that adapt quickly to changing language and new concepts without retraining on massive new corpora. The path forward will combine meta-learning objectives like Minnow with multimodal grounding, continual learning, and careful human-centered evaluation to get closer to the data-efficient, flexible learning we see in humans.