](https://deep-paper.org/en/paper/2502.20330/images/cover.png)
The capability of Large Language Models (LLMs) to process massive amounts of information has exploded. We have moved from context windows of a few thousand tokens to models capable of ingesting millions of words—entire books, codebases, or legal archives—in a single prompt. However, this “long-context” revolution comes with a steep price tag: latency.
Processing a 128K token document is computationally expensive. As the context grows, the Key-Value (KV) cache operations become memory-bound, causing generation speeds to crawl. To mitigate this, developers often choose between two extremes: strictly using Retrieval-Augmented Generation (RAG), which is fast but risks missing the “big picture,” or Long-Context (LC) inference, which is comprehensive but agonizingly slow.
In this post, we explore a new research paper, RAPID, which proposes a third way. By combining RAG with Speculative Decoding, the researchers have created a method that accelerates long-context inference by over \(2\times\) while simultaneously improving generation quality.
1. The Dilemma: Context vs. Speed
Before diving into the solution, we need to understand the bottleneck. When you ask an LLM a question based on a massive document, the model must attend to every single token in that document to generate an answer.
In standard Speculative Decoding (SD)—a popular technique to speed up inference—a smaller “draft” model quickly guesses the next few tokens, and the larger “target” model verifies them in parallel. If the draft is correct, you get free tokens and speed.
However, SD relies on the assumption that the draft model is significantly faster than the target model. In long-context scenarios, this assumption breaks down. Why? Because the draft model also has to process the massive 128K context to make its guesses. The sheer memory bandwidth required to load the KV cache for the draft model negates its speed advantage.
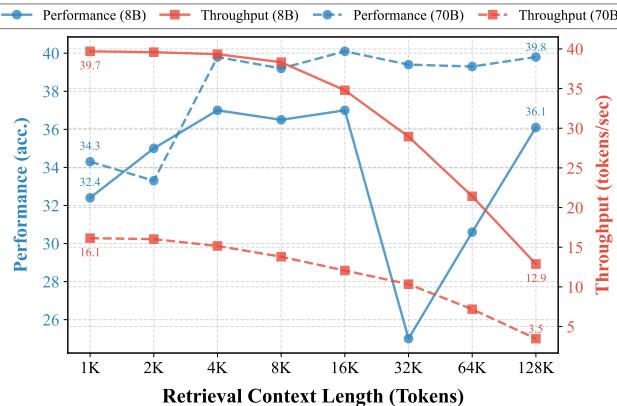
As shown in Figure 1, the throughput (red lines) crashes as the context length increases. Notice the dashed red line for the 8B model: it drops from ~40 tokens/sec at 1K context to ~12 tokens/sec at 128K context. The effectiveness of standard acceleration techniques evaporates when the context gets too long.
2. Enter RAPID: Retrieval-Augmented Speculative Decoding
The researchers introduce RAPID (Retrieval-Augmented SPeculatIve Decoding). The core insight is elegant: The draft model doesn’t need to read the whole book to make a good guess; it just needs the relevant pages.
RAPID modifies the standard Speculative Decoding workflow in two fundamental ways:
- The RAG Drafter: The draft model operates on a compressed, retrieved context, not the full document.
- Retrieval-Augmented Target Distribution: The target model (which reads the full document) is adjusted to be more receptive to the draft model’s insights via inference-time knowledge transfer.
2.1 The RAG Drafter
In traditional SD, if the target model processes a context \(\mathcal{C}\), the draft model also processes \(\mathcal{C}\). In RAPID, the draft model processes \(\mathcal{C}^S\)—a shortened version of the context containing only the top-\(k\) retrieved chunks relevant to the current query.
Let’s look at the mathematical formulation. The target model distribution \(p(x_i)\) is conditioned on the full context:
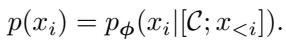
However, the draft distribution \(q(x_i)\) is conditioned on the compressed context \(\mathcal{C}^S\):
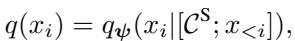
This decoupling is critical. Even if the target model is slogging through 100,000 tokens, the draft model might only be looking at 4,000 tokens. This restores the speed advantage of the drafter.
This efficiency allows for a paradigm shift called Upward-Speculation. Because the drafter is operating on such a small context, we can actually use a larger model as the drafter for a smaller target model, provided the drafter’s context is short enough. For example, using a 70B parameter model (reading 4K tokens) to draft for an 8B parameter model (reading 128K tokens).
2.2 The Challenge of Verification
Standard Speculative Decoding uses a strict acceptance criterion. A draft token \(x'\) is accepted based on the ratio of the target probability to the draft probability:
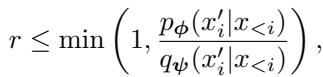
If the target model thinks the draft token is unlikely (\(p(x')\) is low), the token is rejected.
Here lies the problem: What if the drafter is right and the target is wrong? Long-context models often suffer from the “lost-in-the-middle” phenomenon, where they forget information buried in the middle of a long prompt. A RAG drafter, which explicitly retrieves relevant chunks, might actually generate a better token. But under standard SD rules, the target model would reject this superior token because it deviates from its own (flawed) distribution.
2.3 Retrieval-Augmented Target Distribution
To solve this, RAPID doesn’t just use the raw target distribution. It employs inference-time knowledge transfer. The idea is to treat the RAG drafter as a “teacher” that nudges the “student” (the target model) toward the retrieved information.
The researchers define a new, augmented target distribution \(\hat{p}(x_i)\). This distribution mixes the target model’s logits \(z(x_i)\) with the difference between the draft and target probabilities:
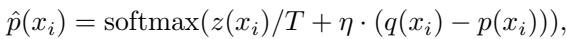
Here, \(\eta\) (eta) is a hyperparameter controlling the strength of the knowledge transfer, and \(T\) is the temperature.
Why does this work?
This equation is derived from the gradient of the knowledge distillation loss. If we view the RAG drafter’s output \(q(x)\) as the ground truth we want to approximate, the gradient of the loss with respect to the logits is:
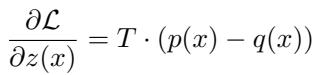
By updating the target logits using this gradient, we shift the target distribution closer to the RAG drafter’s distribution. The adjusted logit \(\hat{z}\) becomes:
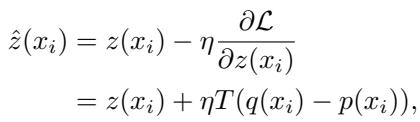
This results in a “Retrieval-Augmented Target Distribution” that retains the deep reasoning of the long-context model while being receptive to the precise, retrieved facts from the drafter.
The New Acceptance Criterion
With this adjusted distribution \(\hat{p}\), the verification step in the speculative decoding loop changes. We now check the draft token against the augmented target:
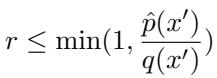
This modification increases the acceptance rate for high-quality tokens generated by the RAG drafter, preventing the target model from stubbornly rejecting valid information it might have overlooked in the massive context window.
If a token is still rejected, RAPID resamples from a residual distribution that ensures the final output remains mathematically consistent with the augmented target distribution:
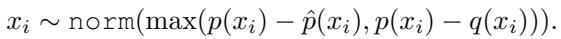
3. Experimental Results
The researchers evaluated RAPID on major benchmarks like \(\infty\)Bench (InfiniteBench) and LongBench v2, using LLaMA-3.1 (8B and 70B) and Qwen2.5 models. The results highlight both speed and quality improvements.
3.1 Performance and Speedup
Table 1 below presents a comprehensive comparison. The key metrics to look at are Accuracy (AVG) and Speedup.
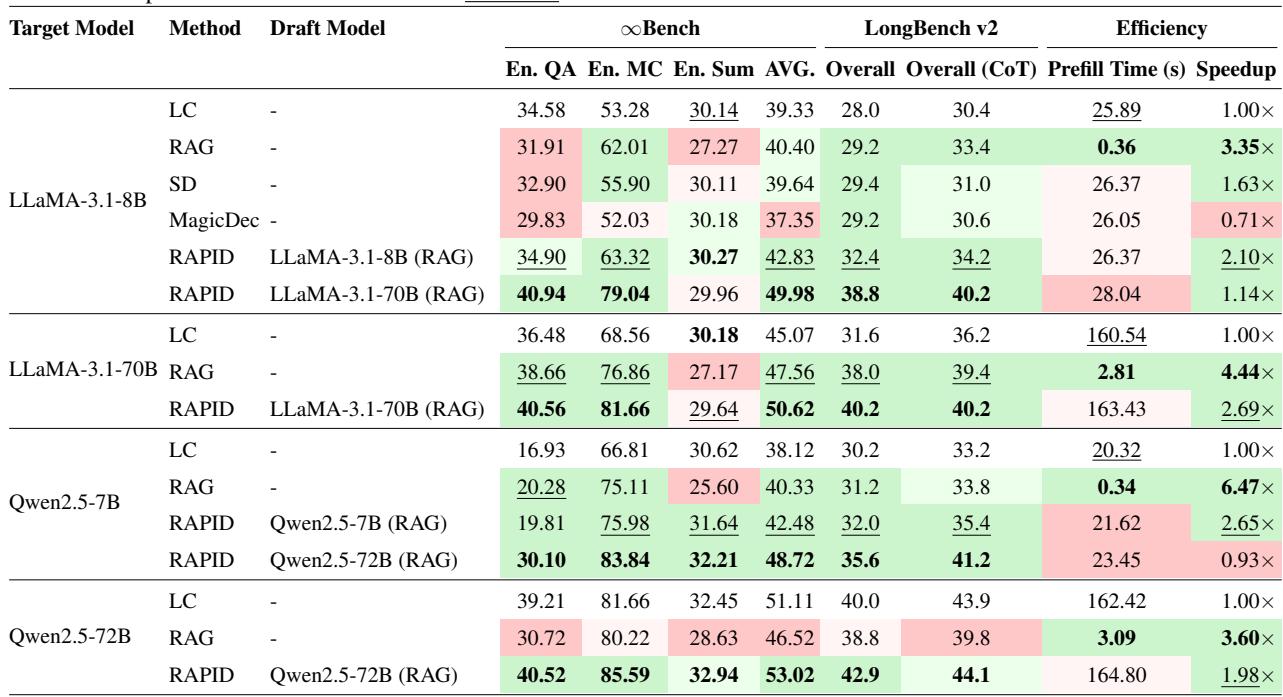
Key Takeaways from Table 1:
- Self-Speculation (Same size drafter): For LLaMA-3.1-8B, RAPID improves accuracy from 39.33 (LC baseline) to 42.83, while achieving a 2.10x speedup. It beats standard SD and “MagicDec” in both speed and quality.
- Upward-Speculation (Larger drafter): Look at the row where LLaMA-3.1-8B is the target, but LLaMA-3.1-70B is the drafter. The score jumps to 49.98. This effectively allows a small, efficient 8B model to perform like a 70B model by leveraging the larger model’s reasoning on retrieved chunks.
- Efficiency: RAPID consistently delivers >2x speedups compared to the Long-Context (LC) baseline, approaching the throughput of pure RAG but with significantly better correctness.
3.2 Where do the gains come from?
Is RAPID just averaging the two models? Not quite. The interaction creates a synergy where the system performs better than either model individually.
Figure 2 breaks down the relative success and failure rates.
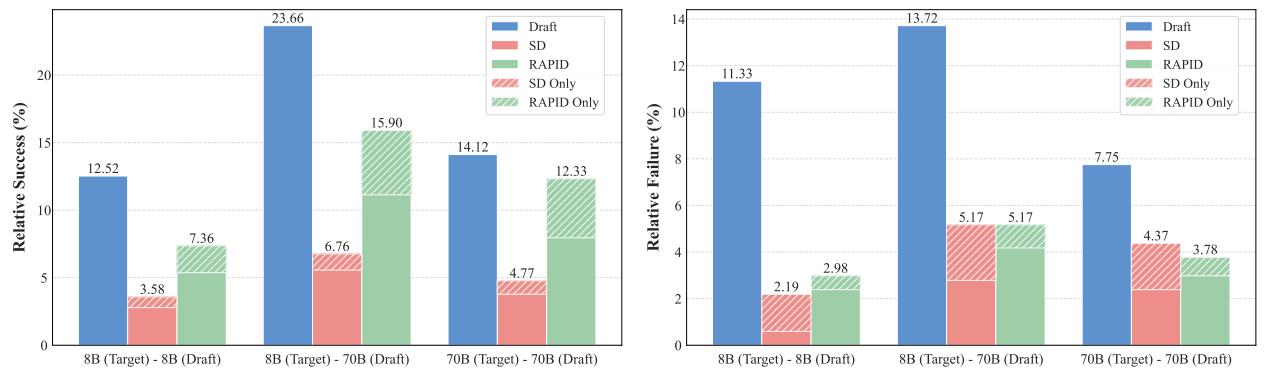
Focus on the green sections labeled RAPID. In the “8B (Target) - 70B (Draft)” column:
- RAPID Only (Green horizontal stripes): This represents cases where neither the target 8B model nor the draft 70B model got the answer right individually, but RAPID did. This “emergent” capability suggests that combining full-context understanding with sharp, retrieved focus yields superior reasoning.
- Relative Success: RAPID captures the benefits of the draft model (Blue) while mitigating the failures.
3.3 Robustness and Context Length
A common question with RAG is: “What if the retrieval is bad?” or “Does this only work for massive contexts?”
Figure 3 illustrates the impact of context length (X-axis) and retrieval length (lines) on accuracy and speed.
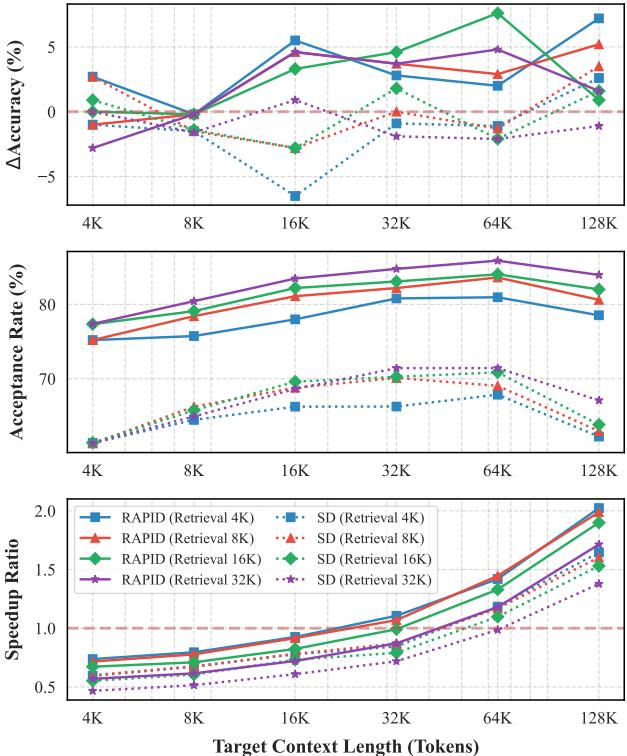
- Bottom Graph (Speedup): Notice that the speedup ratio climbs as the target context length increases. RAPID becomes efficient (Speedup > 1) once the context exceeds ~32K tokens. Before that, the overhead of managing two models might not be worth it.
- Top Graph (Accuracy): RAPID (colored lines) consistently maintains higher accuracy improvements (\(\Delta\) Accuracy) compared to standard SD (grey line), which often degrades performance in long contexts.
3.4 Real-World Application: Multi-Turn Dialogue
Benchmarks are great, but how does it feel in a chat application? The researchers tested RAPID on a multi-turn dialogue setup with extended chat history (~122K tokens).

As shown in Table 2, RAPID achieves a quality score of 4.21 (rated by GPT-4), significantly higher than the target LLM alone (2.82) or standard SD (2.94). It also maintains a healthy acceptance rate of almost 77%, ensuring the user interface feels snappy.
3.5 Robustness to Bad Retrieval
Finally, the researchers stress-tested the system by feeding it unrelated retrieval contexts (deliberately bad RAG).
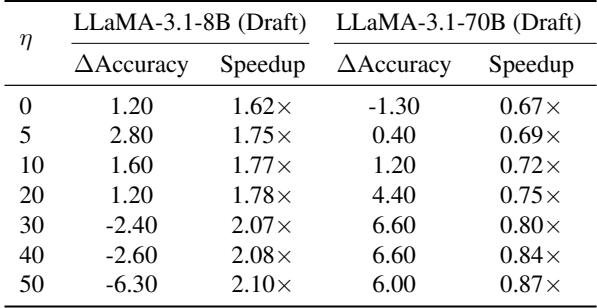
Table 3 shows that even with unrelated retrieval, RAPID (with \(\eta \le 20\)) maintains positive accuracy gains and speedups. The target model’s internal knowledge acts as a safeguard. However, if \(\eta\) is set too high (forcing the target to listen to the drafter too much), performance drops. This highlights the importance of the knowledge transfer parameter \(\eta\): it balances the “reading” (Target) vs. the “skimming” (RAG).
4. Conclusion and Implications
RAPID represents a significant step forward in serving Long-Context LLMs. By acknowledging that reading every word is slow and skimming can be inaccurate, the authors have engineered a system that does both.
The implications are particularly exciting for deployment:
- Cost Reduction: We can serve long-context requests using smaller GPUs for the target model while relying on RAG for speed.
- Model Synergy: The concept of “Upward Speculation” allows us to boost the intelligence of small models using larger models without incurring the massive latency of running the large model on the full context.
For students and researchers in NLP, RAPID serves as a masterclass in hybrid system design—showing that sometimes, the best way to solve a memory bottleneck isn’t better hardware, but a smarter algorithm.
This post is based on the paper “RAPID: Long-Context Inference with Retrieval-Augmented Speculative Decoding” (2025).