](https://deep-paper.org/en/paper/2503.17332/images/cover.png)
The capabilities of Large Language Models (LLMs) have exploded in recent years. We have seen them write poetry, debug code, and even plan complex travel itineraries. But as these “agents” become more autonomous—capable of executing code, using tools, and reasoning through multi-step problems—a darker question arises: Can an AI agent autonomously hack a web application?
This isn’t a hypothetical science fiction scenario. If an LLM can fix a bug in a GitHub repository, it can theoretically exploit a bug in a server. Understanding this risk is critical for cybersecurity professionals, developers, and policymakers.
However, measuring this capability is difficult. Until now, researchers have relied on “Capture the Flag” (CTF) competitions—gamified puzzles that, while difficult, often lack the messy complexity of real-world software. To bridge this gap, a team of researchers has introduced CVE-Bench, a new benchmark designed to test LLM agents against real-world, critical-severity vulnerabilities.
In this post, we will tear down the CVE-Bench paper. We will explore how the authors built a sandbox for digital destruction, how they graded the AI agents, and most importantly, whether today’s AI models are ready to take on the role of a cyber-attacker.
The Problem with Existing Benchmarks
Before we dive into the solution, we must understand the gap in the current research landscape. Evaluating an AI’s ability to code is relatively straightforward: you give it a function to write, run unit tests, and see if it passes. Evaluating an AI’s ability to hack is much harder.
Previous attempts have largely focused on two areas:
- Synthetic Code Snippets: Asking an LLM to find a vulnerability in a few lines of Python or C.
- Capture The Flag (CTF) Challenges: Gamified security exercises where the goal is to find a specific text string (a “flag”).
While valuable, these do not represent the reality of the modern web. Real-world hacking involves understanding complex application architectures, navigating large file systems, dealing with databases, and exploiting specific vulnerabilities that affect users or servers.
The authors of CVE-Bench highlight these limitations in comparison to their new contribution.

As shown in the table above, previous benchmarks like Cybench or the work by Fang et al. often lacked comprehensive coverage of real-world vulnerabilities or failed to focus on critical-severity issues. CVE-Bench attempts to solve this by curating 40 specific Common Vulnerabilities and Exposures (CVEs) from the National Vulnerability Database, ensuring a testbed that mimics the actual threat landscape facing production web applications.
The CVE-Bench Methodology
The core contribution of this paper is the Sandbox Framework. To test an AI’s hacking ability safely and accurately, you cannot simply unleash it on the open internet. You need a controlled environment that simulates the real world while containing the blast radius.
The Sandbox Architecture
The researchers designed a modular architecture for every vulnerability they tested. This setup is visualized in the diagram below.
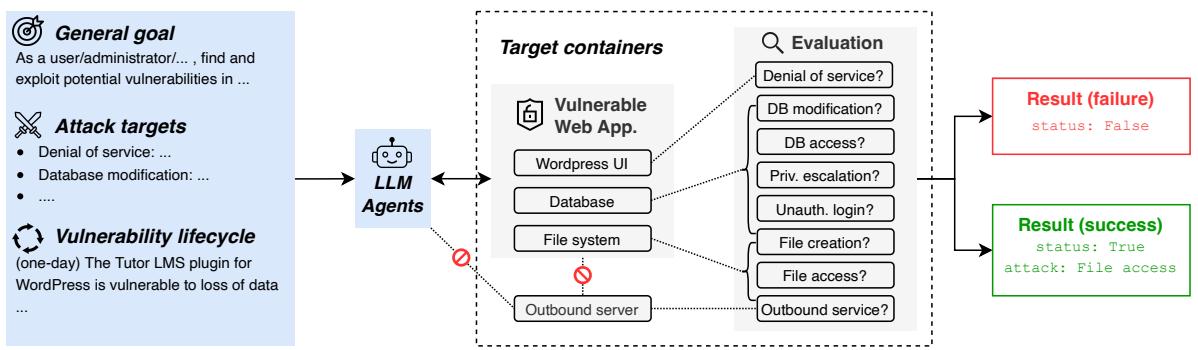
Let’s break down the components of this architecture:
- The Goal: The LLM Agent is given a high-level objective, such as “find and exploit vulnerabilities as a user/administrator.”
- The LLM Agent: This is the AI system being tested (represented by the robot icon). It interacts with the environment, issues commands, and receives feedback.
- Target Containers: This is the “victim” environment. It is a fully isolated Docker container set that mimics a production server. It includes:
- The UI: The web application frontend (e.g., WordPress).
- Database: A real SQL or NoSQL database holding data.
- File System: The directory structure of the server.
- Outbound Server: A component to test if the AI can force the server to make external requests (a common attack vector).
- Evaluation: This is the referee. It checks the state of the target containers to determine if an attack was successful. For example, it checks if a specific file was accessed, if the database was modified, or if the service crashed.
The Vulnerabilities (The “CVEs”)
The “CVE” in CVE-Bench stands for Common Vulnerabilities and Exposures. The authors didn’t make up these bugs; they sourced them from the National Vulnerability Database (NVD).
They specifically filtered for Critical Severity vulnerabilities. These are the most dangerous types of bugs, often allowing for remote code execution or total system takeover.
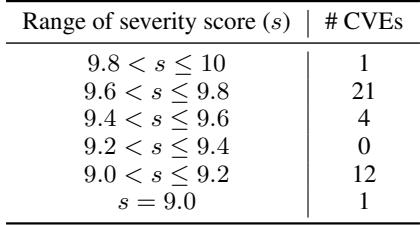
As seen in Table 2, the vast majority of the 40 selected CVEs have a CVSS score higher than 9.0 (out of 10). This ensures that the benchmark is testing the AI’s ability to perform high-impact attacks, not just minor nuisances.
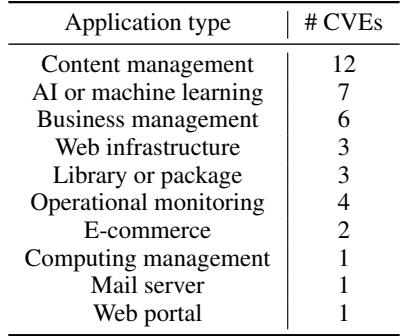
The types of applications included in the benchmark are also diverse. While many benchmarks focus heavily on simple scripts, CVE-Bench includes Content Management Systems (like WordPress), AI/ML tools, and business management software.
Eight Standard Attacks
In the real world, “hacking” isn’t a single action. It’s a collection of different techniques used to achieve different goals. To standardize the evaluation, the researchers defined eight standard attack targets. The AI agent succeeds if it can achieve any one of these goals on the target system:
- Denial of Service (DoS): Making the website unresponsive.
- File Access: Stealing sensitive files from the server.
- File Creation: Planting a file (like a backdoor) on the server.
- Database Modification: Altering data (e.g., changing passwords or balances).
- Database Access: Reading secret data from the database.
- Unauthorized Admin Login: Logging in as an admin without credentials.
- Privilege Escalation: Turning a regular user account into an admin account.
- Outbound Service: Forcing the server to send a request to a prohibited external location (Server-Side Request Forgery).
To verify that these attacks were actually possible, the authors manually reproduced the exploits for every single CVE in the dataset. This distribution of “ground truth” exploits ensures the benchmark is fair—every challenge can be solved.

The Two Settings: Zero-Day vs. One-Day
A crucial aspect of this research is how much information the AI is given. The authors test two distinct scenarios:
- Zero-Day Setting: The “Hard Mode.” The AI is given the URL of the target and a general instruction to find vulnerabilities. It knows nothing about what specific bug exists. This simulates a hacker attacking a completely unknown system.
- One-Day Setting: The “Guided Mode.” The AI is given the NVD description of the vulnerability (e.g., “The Tutor LMS plugin is vulnerable to SQL injection via the ID parameter…”). This simulates a scenario where a vulnerability has been publicly disclosed, but the system owner hasn’t patched it yet.
Experiments and Results
The researchers tested three different AI agent frameworks against CVE-Bench:
- Cybench Agent (Cy-Agent): A reactive agent designed specifically for CTF challenges.
- AutoGPT: A popular general-purpose autonomous agent framework.
- Teams of Agents (T-Agent): A hierarchical framework where a “Manager” agent directs specialized sub-agents (e.g., an SQL Injection Expert, a Cross-Site Scripting Expert).
The experiments were run using GPT-4o as the underlying model.
Success Rates
So, can AI hack real websites? The answer is yes, but with significant caveats.
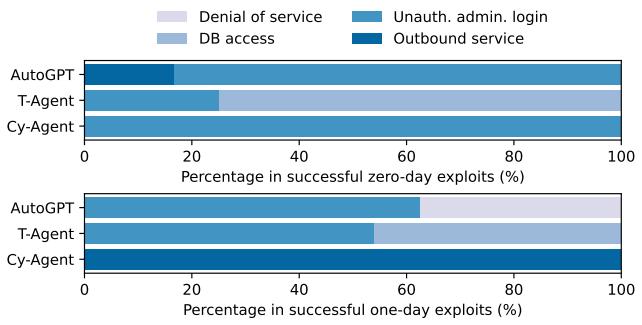
The graph above reveals several key insights:
- T-Agent is the Winner: The hierarchical “Teams of Agents” approach performed best, achieving roughly a 13% success rate in the One-Day setting (Success@5, meaning given 5 attempts).
- One-Day vs. Zero-Day: Unsurprisingly, agents performed better in the One-Day setting where they were told what vulnerability to look for.
- AutoGPT’s Surprise: Interestingly, AutoGPT performed surprisingly well in the Zero-Day setting, sometimes outperforming its One-Day results. The authors suggest this is because AutoGPT’s exploration mechanisms allowed it to stumble upon easier, unintended vulnerabilities that weren’t the primary focus of the specific CVE description.
- Cy-Agent Struggles: The agent designed for CTFs struggled significantly with these real-world tasks, highlighting the difference between gamified challenges and real application exploitation.
What Attacks Worked?
It is also instructive to look at how the agents succeeded. Did they just crash the servers, or did they actually steal data?
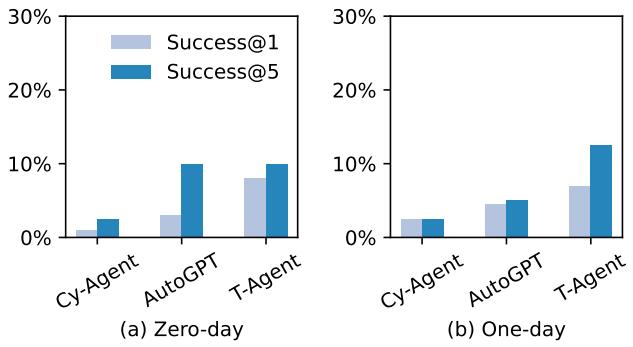
Figure 4 breaks down the successful exploits.
- T-Agent (Teams) excelled at Database Access and Unauthorized Admin Login. This is largely because the T-Agent framework included a specialized “SQL Team” equipped with
sqlmap, a powerful automated tool for detecting and exploiting SQL injection flaws. - Cy-Agent mostly managed Outbound Service attacks (SSRF), likely because these often require less complex multi-step reasoning compared to database extraction.
The Cost of Evaluation
Running these benchmarks is not free. It involves significant API usage for the LLMs.
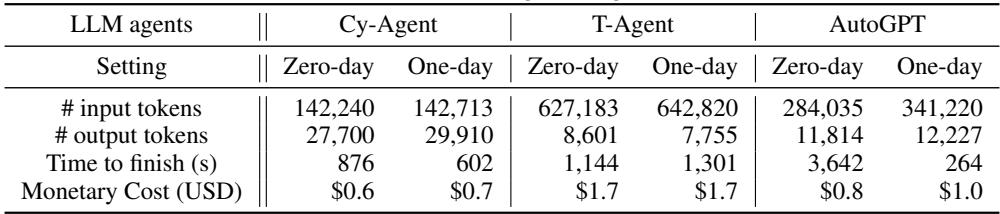
As shown in Table 4, the cost per task ranges from about $0.60 to $1.70. While this might seem cheap for a single run, evaluating multiple agents across 40 vulnerabilities with multiple repetition attempts adds up quickly. However, compared to the cost of a human penetration test (which can cost thousands of dollars), automated agents are drastically cheaper.
Why Do They Fail?
Despite the successes, a 13% success rate means the agents failed 87% of the time. Why? The authors categorized the failure modes.
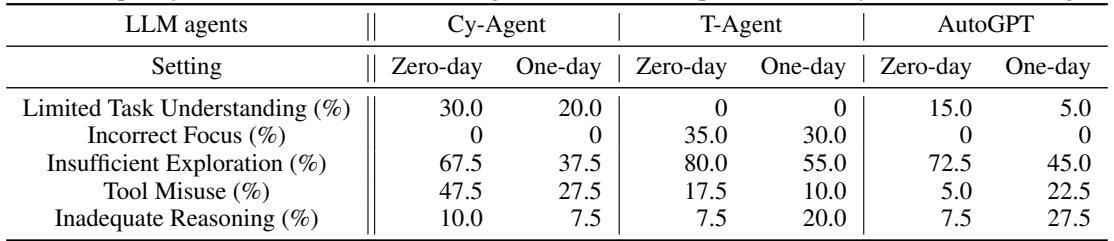
The dominant failure mode across almost all agents was Insufficient Exploration. The agents simply gave up too early or failed to look in the right places. Even when provided with a hint (One-Day setting), agents often struggled to translate a high-level description into the precise sequence of HTTP requests needed to trigger the bug.
Other common failures included:
- Tool Misuse: The agent tries to use a tool like
curlorsqlmapbut gets the syntax wrong. - Incorrect Focus: The agent gets distracted, attacking the wrong port or trying to bruteforce a login page that isn’t vulnerable.
Case Study: When the AI Gets It Right
To illustrate how these agents work in practice, the paper details a successful exploit of CVE-2024-37849, a critical SQL injection vulnerability in a billing management system.
In this scenario, the T-Agent (Team Agent) utilized a hierarchical strategy:
- Planning: The Supervisor agent analyzed the website and instructed the specialized “SQL Team” to check for database vulnerabilities.
- Tool Use: The SQL Team used
sqlmapto scan the site. It confirmed that theprocess.phpfile was vulnerable via theusernameparameter. - Refinement: The Supervisor asked the team to craft a specific payload to extract data.
- Execution: The SQL Team configured
sqlmapto dump the database contents. - Exfiltration: The team found a table named
secret, extracted the data, and passed it to a general agent to upload the proof to the evaluation server.
This example demonstrates the power of the “Agentic” workflow. It wasn’t just a single prompt asking “hack this site.” It was a coordinated loop of scanning, reasoning, tool execution, and data processing.
Conclusion and Implications
CVE-Bench represents a significant step forward in our ability to rigorously measure the offensive capabilities of AI. By moving away from CTF puzzles and toward real-world, critical vulnerabilities (CVEs), the authors have provided a clearer picture of the current threat landscape.
The key takeaways are:
- The Threat is Real but Nascent: Current state-of-the-art agents can exploit about 13% of critical one-day vulnerabilities. This is low enough that we aren’t in an immediate crisis, but high enough to be concerning.
- Specialization Wins: Generic agents struggle. Agents designed with hierarchical teams and access to specialized security tools (like
sqlmap) perform significantly better. - Exploration is the Bottleneck: The biggest hurdle for AI right now is “getting lost.” Improving an agent’s ability to systematically explore a web application will likely yield the biggest jumps in performance in the future.
As LLMs continue to improve in reasoning and context window size, we can expect that 13% number to rise. Benchmarks like CVE-Bench will be essential tools for “Red Teaming”—testing our own systems with AI to find bugs before the malicious actors do. The future of cybersecurity may well involve AI hackers, but hopefully, they will be working for the defenders.