](https://deep-paper.org/en/paper/2504.08823/images/cover.png)
Imagine teaching a smart assistant to recognize different bird species. It first masters identifying robins. Then, you teach it about sparrows. But when you ask it to recognize a robin again, it’s completely forgotten what one looks like.
This frustrating phenomenon, known as catastrophic forgetting, is one of the biggest hurdles in creating truly intelligent and adaptive AI systems.
In a world that constantly changes, we need AI that can learn continuously—acquiring new skills and knowledge without overwriting the old. This is the essence of Continual Learning (CL). While humans do this effortlessly, deep learning models still struggle, often requiring complete retraining from scratch, which is slow, expensive, and impractical.
A recent research paper, “FM-LoRA: Factorized Low-Rank Meta-Prompting for Continual Learning”, introduces a compact and powerful framework to tackle this problem. The authors propose a method that enables large pre-trained models—especially Vision Transformers (ViTs)—to learn a sequence of tasks efficiently, without storing old data and without catastrophic forgetting.
Let’s unpack how this works.
The AI’s Dilemma: Stability vs. Plasticity
At the heart of continual learning lies a fundamental trade-off known as the stability–plasticity dilemma:
- Stability: The model must preserve previously learned knowledge.
- Plasticity: The model must remain flexible enough to learn new tasks.
Too much plasticity leads to forgetting; too much stability leads to stagnation.
Researchers have tried several approaches to strike the balance:
- Rehearsal Methods: Reuse a small portion of past data while training new tasks. Effective, but memory-heavy and privacy-sensitive.
- Regularization Methods: Penalize large updates to important parameters from previous tasks. Stable but restrictive.
- Architectural Methods: Attach new modules or adapters for each task. Scalable in theory but quickly bloats the model.
Recently, a promising alternative emerged: Parameter-Efficient Fine-Tuning (PEFT). Instead of retraining all parameters of a massive pre-trained model, PEFT updates only a small subset—like LoRA (Low-Rank Adaptation) modules—making it far more efficient.
However, PEFT methods such as LoRA were not designed with sequential, lifelong learning in mind and still stumble when adapting across multiple tasks.
That’s where FM-LoRA comes in.
The Core of FM-LoRA: A Three-Part Harmony
FM-LoRA achieves lifelong learning through three synergistic modules:
- Factorized Low-Rank Adaptation (F-LoRA)
- Dynamic Rank Selector (DRS)
- Dynamic Meta-Prompt (DMP)
Together, they allow the model to learn efficiently, adapt quickly, and remember persistently.
Let’s look at each piece in detail.
1. F-LoRA: Learning in a Shared, Stable Subspace
Standard LoRA introduces small matrices \( A_t \) and \( B_t \) for each new task to compute an incremental change to the weight matrix, \( \Delta W_t = A_t B_t^{\top} \). This helps the model learn efficiently but leads to redundancy and interference among tasks.
F-LoRA refines this idea with a powerful twist. Instead of learning new adapters for every task, FM-LoRA factorizes its low-rank updates into shared and task-specific components:
\[ \Delta W_t = A_{\text{shared}} M_t N_t^{\top} B_{\text{shared}}^{\top} \]- \(A_{\text{shared}}\) and \(B_{\text{shared}}\) are global low-rank bases learned once and frozen afterward, representing stable directions of adaptation common to all tasks.
- \(M_t\) and \(N_t\) are small task-specific matrices that adjust those shared bases for each task.
By fixing the shared bases, all updates lie within a controlled and consistent low-dimensional subspace.
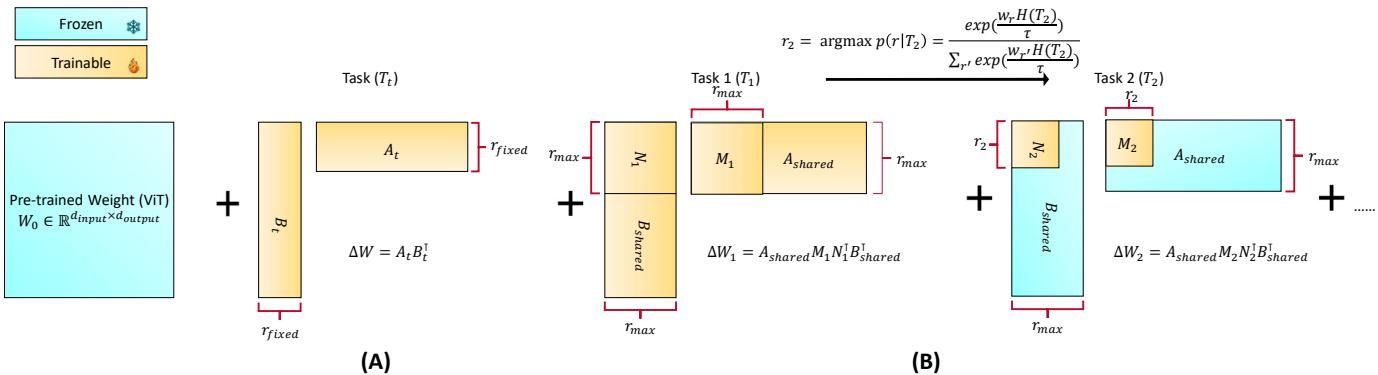
Figure 1: FM-LoRA learns shared bases \(A_{\text{shared}}\) and \(B_{\text{shared}}\) on the first task. Subsequent tasks only learn small matrices \(M_t\) and \(N_t\), keeping all updates within a stable, shared subspace.
Benefits of F-LoRA:
- Extreme Efficiency: It adds far fewer parameters per task—only \(2r^2\) compared to hundreds of thousands.
- Reduced Interference: Task updates are confined to shared bases, minimizing collisions between new and old knowledge.
In effect, F-LoRA creates a safe zone for adaptation—ensuring new learning happens in harmony with accumulated experience.
2. Dynamic Rank Selector (DRS): Adapting to Task Complexity
The next question is: how large should this subspace be? The rank (r) determines how flexible the adapter is—higher ranks allow more expressive adaptation but require more parameters.
Using a fixed rank for all tasks fails to account for the diversity of task complexity. This is where Dynamic Rank Selector (DRS) steps in.
DRS automatically adjusts the rank \(r_t\) for each task by estimating its complexity. The authors measure complexity via the validation loss from a short pretraining pass: harder tasks yield higher losses. Using a Gumbel-Softmax mechanism, the model selects a rank probabilistically:
\[ p(r|\mathcal{T}_t) = \frac{\exp\left(\frac{w_r H(\mathcal{T}_t)}{\tau}\right)}{\sum_{r'} \exp\left(\frac{w_{r'} H(\mathcal{T}_t)}{\tau}\right)} \]Here, \(H(\mathcal{T}_t)\) is the estimated complexity, \(w_r\) are learnable weights for different candidate ranks, and \(\tau\) controls smoothness. The most probable rank \(r_t\) is chosen for task \(t\).
This adaptive strategy translates into task similarity awareness:
- When a new task is similar to older ones, DRS picks a smaller rank to save capacity and avoid redundancy.
- When it’s distinct or more complex, DRS selects a larger rank to capture new information.
The result is a model that scales its capacity dynamically, preserving stability while staying flexible.
3. Dynamic Meta-Prompt (DMP): Creating an Implicit Memory
Even with stable adaptation, models without rehearsal may suffer representational drift—gradual loss of alignment across tasks. FM-LoRA solves this using Dynamic Meta-Prompt (DMP), a small shared set of tokens prepended to the input sequence before it passes through the Transformer.
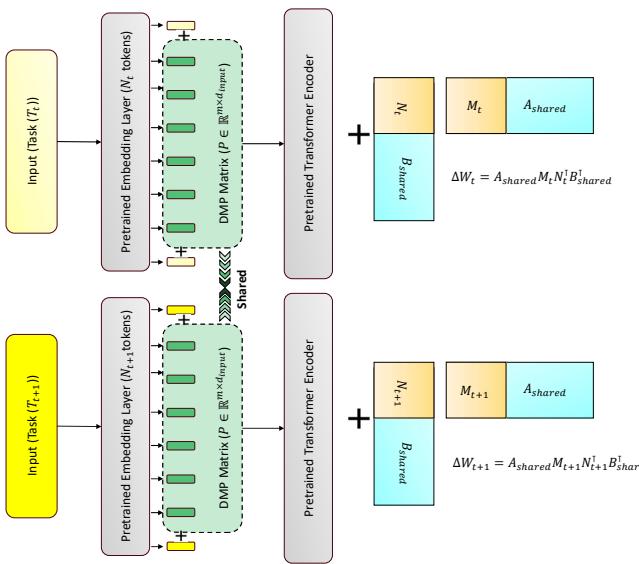
Figure 2: The Dynamic Meta-Prompt (DMP) adds learnable tokens to every input. They evolve across all tasks, serving as a shared context that anchors and stabilizes representations.
These tokens act like anchors of shared memory, stabilizing internal representations across tasks. They’re updated with every new task, becoming a universal context learned across all experiences. Over time, DMP provides consistent cues that reduce drift and help the model retain previously learned patterns.
Putting It to the Test: Experiments and Results
The researchers evaluated FM-LoRA on several continual learning benchmarks, including ImageNet-R, CIFAR100, CUB200, and DomainNet, covering both class-incremental and domain-incremental scenarios.
Two major metrics were used:
- Accuracy (Acc): Overall performance on all tasks after sequential training.
- Average Anytime Accuracy (AAA): Average performance throughout learning, reflecting how well the model avoids forgetting.
Performance Under Pressure: Longer Task Sequences
On the ImageNet-R benchmark, FM-LoRA showed exceptional resilience as the number of tasks increased.
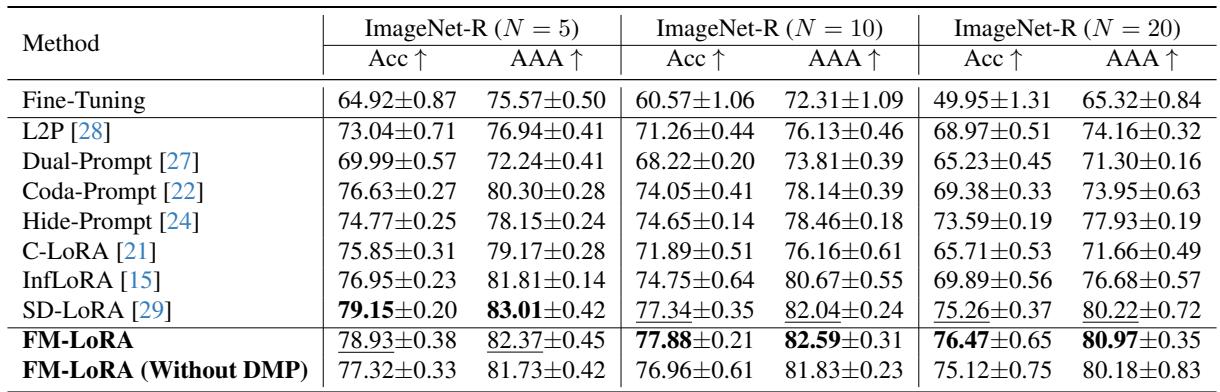
As most methods degrade drastically with more tasks, FM-LoRA remains stable—even improving its margin over competing approaches as sequences lengthen.
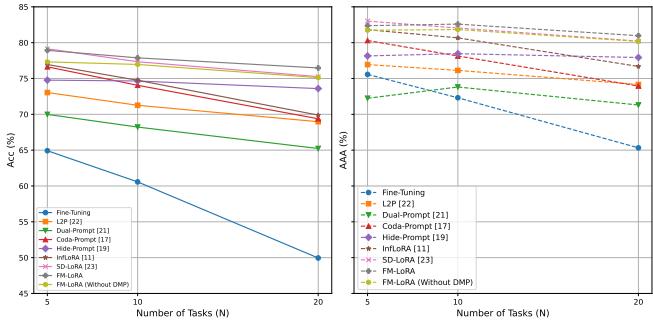
Figure 3: As the number of tasks increases, FM-LoRA maintains high accuracy. Fine-tuning (grey line) collapses completely, showing severe forgetting. FM-LoRA’s curves remain strong, confirming its stability.
For 20 tasks, FM-LoRA outperformed the leading alternative, SD-LoRA, by over 1% in accuracy and 0.7% in AAA, confirming its robustness in long-term learning.
Versatility Across Datasets
What’s truly impressive is FM-LoRA’s consistency across diverse benchmarks. The authors tested it on CIFAR100 (general object classes), CUB200 (fine-grained birds), and DomainNet (six domains with style shifts).
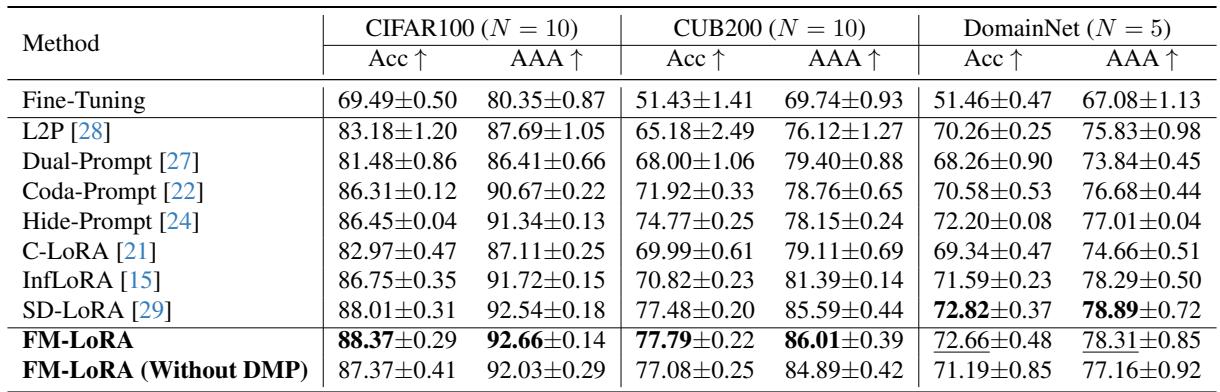
FM-LoRA achieved top or near-top results in all settings—whether dealing with new class labels or entirely new domains. The framework generalizes remarkably well, proving its broad applicability in lifelong learning scenarios.
Do the Components Really Matter? Ablation Studies
No strong method goes untested. The researchers ran detailed ablation studies to verify each component’s contribution.
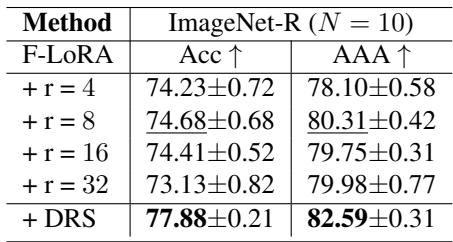
- Impact of DRS: Comparing F-LoRA with fixed ranks against F-LoRA + DRS revealed that DRS consistently outperforms all fixed-rank versions, adapting capacity perfectly to task complexity.
- Impact of DMP: Evaluating different numbers of prompt tokens showed tangible gains from DMP. A moderate token count gave the best performance, balancing memory and effectiveness.
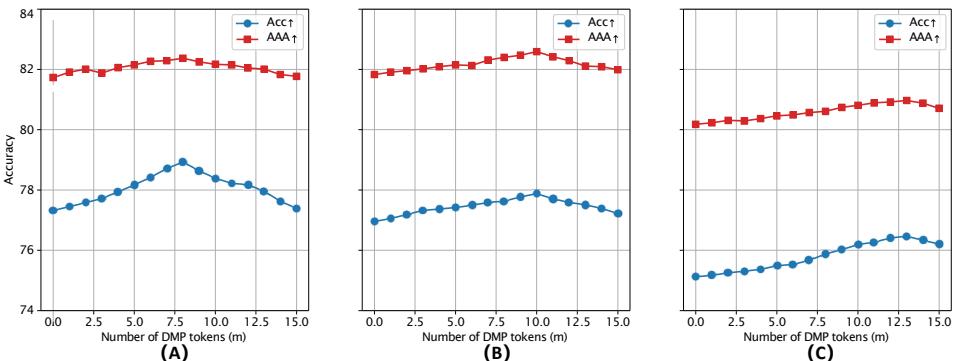
Figure 4: Varying the number of prompt tokens \(m\) affects performance. More tokens help longer task sequences, while fewer suffice for shorter ones.
These studies confirm that each part of FM-LoRA—F-LoRA, DRS, and DMP—contributes meaningfully to overall performance. Together, they yield a cohesive and adaptive system.
Conclusion: A Step Toward True Lifelong Learning
FM-LoRA represents a significant step toward AI that learns for a lifetime. By combining:
- F-LoRA, which confines learning to a stable, low-rank subspace,
- DRS, which intelligently adapts model capacity per task, and
- DMP, which anchors representations through shared prompts,
the framework achieves a delicate balance between stability and plasticity—the hallmark of true continual learning.
FM-LoRA doesn’t just learn new things. It remembers, adapts, and improves as it learns—without needing old data or bloated models. This unified approach brings us closer to building AI systems that, much like humans, grow wiser with experience rather than forgetful over time.