](https://deep-paper.org/en/paper/2505.07450/images/cover.png)
Imagine teaching a smart system to identify different types of birds. It masters robins, sparrows, and eagles. Then, you teach it about fish—tuna, salmon, and clownfish. But when you ask it to identify a robin again, it stares blankly. It has forgotten. This phenomenon, known as catastrophic forgetting (CF), is one of the biggest hurdles in building truly adaptable AI. A model trained on a new task often overwrites the knowledge it learned from previous tasks, effectively suffering from a form of digital amnesia.
For AI to be useful in dynamic, real-world environments such as autonomous driving or personalized healthcare, it must learn new tasks without discarding old ones. The field dedicated to solving this is called Continual Learning (CL).
A recent research paper, Prototype Augmented Hypernetworks for Continual Learning, presents an innovative framework called PAH that addresses this challenge head-on. Rather than storing large amounts of past data or freezing parts of the network, the authors introduce a system where a single “master” network can generate task-specific classifier heads on demand. The trick? It uses compact, learnable prototypes that act as memory keys for each task. Let’s explore how this works.
The Challenge: Why Neural Networks Forget
To grasp PAH’s contribution, we first need to understand what causes forgetting in neural networks.
A neural network fine-tunes its internal parameters—its weights—to maximize performance on a given task. When training on Task A, it adjusts these weights to recognize patterns relevant to Task A’s data. Next, when learning Task B, the same weights are updated again. The new adjustments overwrite the old ones, erasing Task A’s learned representations. This is catastrophic forgetting.
Researchers have proposed several approaches to mitigate this:
- Regularization Methods: Add penalties that discourage altering weights critical to previous tasks.
- Rehearsal Methods: Store and replay a subset of old data (“rehearsal buffers”) to remind the network of past knowledge—though this requires extra memory.
- Architecture-Based Methods: Allocate new network units for new tasks, preventing overwriting but causing uncontrolled model growth.
Studies show that catastrophic forgetting often occurs in classification layers, not feature extractors. The deep layers that learn generic features tend to remain stable, while the classifier’s task-specific layers deteriorate. Addressing this instability is where PAH shines.
The PAH Architecture: Hypernetworks Meet Prototypes
PAH integrates two powerful concepts: Hypernetworks and Prototypes.
- A Hypernetwork is a neural network that generates the weights for another network (called the main network). Instead of storing multiple classifier heads, a hypernetwork can produce them dynamically.
- A Prototype is a compact, learnable representation of a class—an idealized feature that captures the essence of “catness” or “dogness” in the learned feature space.
In PAH, the hypernetwork receives a set of task-specific prototypes and outputs the corresponding classifier weights. This single generator can reconstruct any previously learned classifier head, eliminating the need to store one per task.
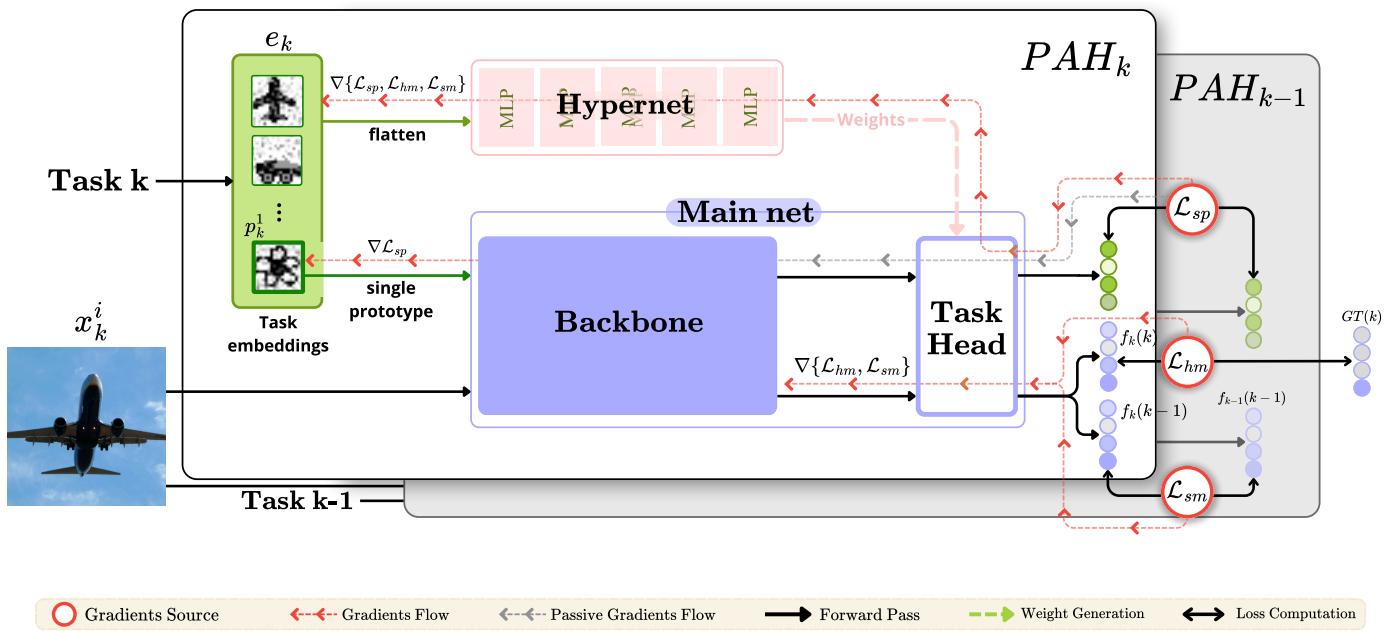
Figure 1. Overview of the PAH architecture. The hypernetwork, conditioned on learnable task prototypes, generates classifier weights dynamically. Knowledge distillation helps preserve information from previous tasks.
1. The Main Network: Learning Features
The main network consists of two parts:
- Backbone (\(\beta_{\theta}\)): A feature extractor, such as a ResNet, that transforms input images into feature vectors.
- Task-Specific Head (\(\tau\)): A classifier that predicts class labels based on extracted features.
Instead of keeping separate heads for each task, PAH generates their weights on demand:
\[ f_k(x_k \mid k) = \tau\left(\beta_{\theta}(x_k) \mid \theta_k^{\tau}\right) \]This keeps memory usage low and maintains flexibility.
2. The Hypernetwork: Generating Weights on Demand
The hypernetwork (\(\Upsilon\)) acts as the “weight generator.” For each task \(T_k\), it takes a task embedding \(e_k\) as input and outputs the classifier weights:
\[ \theta_k^{\tau} = \Upsilon(e_k) \]If the hypernetwork can be fed the right task descriptor, it can regenerate any task head accurately—no need to store them.
3. Task Embeddings: Learnable Prototypes
The task embedding \(e_k\) captures the identity of task \(T_k\). PAH constructs this embedding by concatenating a set of learnable class prototypes:
\[ e_k = \text{Flatten}\left(p_k^{1}, p_k^{2}, \ldots, p_k^{C}\right) \]Each prototype \(p_k^c\) represents a class in the task, typically structured as a small \(10 \times 10\) feature grid. These prototypes adapt throughout training, encoding informative patterns about the task.
Rather than starting from random noise, prototypes are semantically initialized using real examples from their corresponding classes—e.g., resized and normalized sample images. This initialization simplifies learning and improves task embedding quality.
Training PAH: The Three-Part Loss Strategy
To learn new tasks while retaining old ones, PAH uses a composite loss with three components: one for classification, two for distillation.
1. Hard Margin Loss (\(L_{hm}\))
The standard cross-entropy loss optimizes classification on the current task:
\[ L_{hm} = -\sum_{c=1}^{C} y_c \log \hat{y}_c \]This drives accuracy and allows gradients to update the backbone, hypernetwork, and current prototypes.
2. Soft Loss Main (\(L_{sm}\))
A knowledge distillation loss—preserving old task behaviors. For each image \(x_k\) from task \(T_k\), PAH aligns predictions between the previous model (\(f_{k-1}\)) and the current one (\(f_k\)):
\[ L_{sm} = \frac{1}{k-1} \sum_{j=1}^{k-1} \text{KL}(f_{k-1}(x_k \mid j) \parallel f_k(x_k \mid j)) \]This helps the new model maintain decision boundaries learned from earlier tasks, stabilizing feature representations.
3. Soft Loss Prototypes (\(L_{sp}\))
The subtle but essential prototype alignment loss. After \(L_{hm}\) updates the backbone, the old prototypes may no longer match the updated feature space. \(L_{sp}\) adapts them:
\[ L_{sp} = \frac{1}{k-1} \sum_{j=1}^{k-1} \sum_{c=1}^{C} \operatorname{KL}(f_{k-1}(p_j^c \mid j) \parallel f_k(p_j^c \mid j)) \]During this step, only prototypes are updated; the backbone and hypernetwork are frozen. This lets prototypes evolve with the network without causing instability.
The overall training objective is:
\[ L_{\text{total}} = L_{hm} + \lambda_{sm} L_{sm} + \lambda_{sp} L_{sp} \]Does It Work? Experimental Validation
PAH was tested on two standard benchmarks:
- Split-CIFAR100 – 100 classes divided into 10 tasks.
- TinyImageNet – 200 classes divided into either 10 or 20 tasks.
Performance was measured using Average Accuracy (AA) and Forgetting Metric (FM), which quantify task retention after multiple updates.
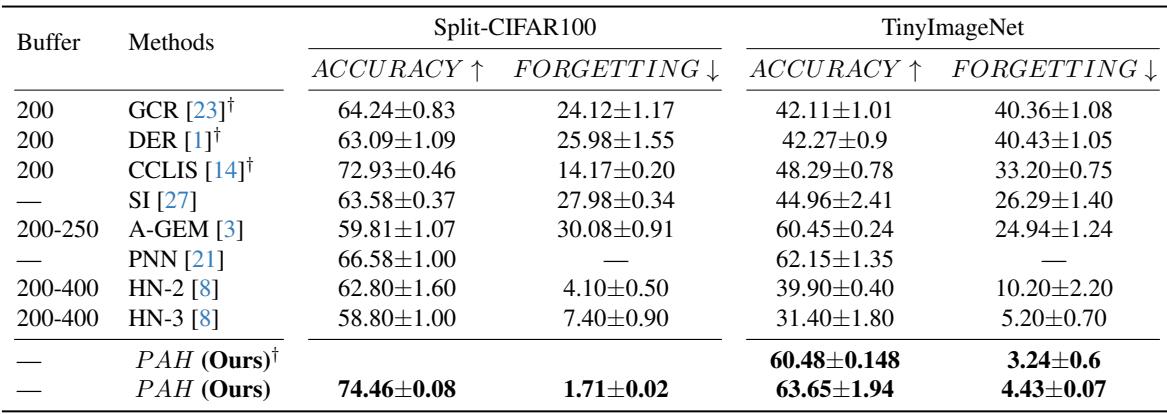
Figure 2. Comparison of PAH against strong baselines on Split-CIFAR100 and TinyImageNet. PAH achieves top accuracy with minimal forgetting.
Benchmark Results
Split-CIFAR100: PAH reached 74.5% accuracy and just 1.7% forgetting—substantially better than rehearsal-based methods like DER (63.1% accuracy, 26% forgetting) or hypernetwork alternatives like HN‑2 (62.8% accuracy, 4.1% forgetting).
TinyImageNet: PAH achieved 63.7% accuracy and 4.4% forgetting, outperforming all baselines, including replay-based methods that store hundreds of samples. Even without retaining past data, PAH maintained knowledge effectively.
These results highlight PAH’s ability to prevent forgetting particularly in classifier layers, the usual bottleneck for continual learning systems.
Ablation Studies: What Makes PAH Tick?
To identify what drives PAH’s success, the authors conducted ablation studies, altering individual factors like prototype shape, loss coefficients, and initialization method.
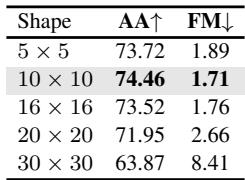
Figure 3. Ablation results on Split-CIFAR100. Prototype size, stability coefficients, and semantic initialization all significantly affect performance.
Key insights:
- Prototype Shape Matters: A \(10 \times 10\) grid provided the best balance of expressiveness and efficiency. Smaller prototypes lacked detail; larger ones overfit.
- Balancing Stability and Plasticity: The weight on distillation losses controls forgetting. A coefficient of 0.5 achieved the best trade-off.
- Adaptive Prototypes Are Essential: Removing \(L_{sp}\) caused performance drops, proving prototype adaptation is critical.
- Semantic Initialization Helps: Starting prototypes from real images instead of random noise boosted accuracy (74.46% vs. 72.54%) and lowered forgetting (1.71% vs. 2.32%).
Together, these findings reinforce that learnable, semantically initialized prototypes combined with precise hypernetwork conditioning are the cornerstone of PAH’s effectiveness.
Conclusion: Toward Lifelong Learning in AI
Catastrophic forgetting remains one of AI’s toughest obstacles. Prototype-Augmented Hypernetworks (PAH) offer an elegant, scalable way forward. By having a hypernetwork generate task-specific classifier heads trained via learnable prototypes and guided by dual distillation losses, PAH achieves state-of-the-art results without growing model size or relying on replay buffers.
Key takeaways:
- Dynamic Classifier Generation: No need to store task heads—weights are created when needed.
- Prototypes as Memory Keys: Learnable prototypes encode task-specific contexts efficiently.
- Dual Distillation: Separate mechanisms stabilize both backbone features and task prototypes, minimizing forgetting.
PAH demonstrates that continual learning can be practical, memory-efficient, and nearly free of forgetting. It represents a meaningful step toward AI systems capable of adaptive, lifelong learning—systems that remember, evolve, and grow just as humans do.