](https://deep-paper.org/en/paper/2507.05019/images/cover.png)
Beyond Big Data: Can Small, Diverse Datasets Teach Transformers to Generalize Better?
In-context learning (ICL) feels like magic: show a model a few examples in the prompt, and it performs a new task without any parameter updates. This capability—famously showcased by GPT-3 and similar large models—has transformed how we think about flexible AI. But the route to reliable ICL today typically runs through massive, uncurated datasets scraped from the web. Those datasets are expensive to store and process, often biased or noisy, and—critically—make it hard to know whether models truly generalize or simply memorize.
A recent paper, “Meta-Learning Transformers to Improve In-Context Generalization,” asks a different question: what if we train a transformer-based in-context learner not on one gigantic corpus but on many smaller, well-curated, domain-specific datasets? Can diversity and curation beat raw scale for out-of-domain generalization and robustness?
This post walks through that paper’s key ideas, methods, and findings. We’ll explain the GEOM framework the authors introduce, why Meta-Album is an excellent playground for these experiments, and what the results imply for practitioners who care about practical, controllable, and privacy-aware model training.
Overview: what you’ll learn
- Why training on many small, curated datasets might produce stronger in-context generalization than training on one large, uncurated corpus.
- How to turn few-shot classification tasks into non-causal sequences that a transformer encoder can process.
- The GEOM family of methods (GEOM, GEOM-M, GEOM-S, GEOM-U) and the experimental settings: supervised leave-one-out, sequential streaming, and unsupervised pseudo-task training.
- Key empirical takeaways about class diversity vs. total image count, sequential curriculum ordering, and the surprising strength of unsupervised multi-dataset training.
Why revisit the “bigger is better” dogma?
Large, uncurated corpora have undeniable utility: they expose models to huge concept spaces and—when well-engineered—produce impressive emergent abilities. But they bring problems:
- Cost: storing and training on petabytes is prohibitive for many labs and organizations.
- Data quality and balance: web-scale data is messy; models learn from noise and skewed representation.
- Privacy and contamination: large crawls can leak sensitive or test-set content, confounding true generalization.
Meta-learning, by contrast, purposefully trains models to adapt quickly to new tasks. The authors of the paper combine the meta-learning philosophy with ICL by training a transformer to be an in-context learner across many small, domain-specific datasets. The core hypothesis: curated diversity + meta-training can encourage generalization and modularity while avoiding many pitfalls of web-scale pretraining.
High-level idea: meta-learn an in-context transformer
The central proposal—GEOM (Generalization Over Memorization)—reframes meta-learning as a non-causal sequence modeling problem for transformers. Instead of fine-tuning per task, GEOM trains a transformer to use a context (support) set presented with a query to predict the query label, i.e., true in-context learning.
Figure 1 illustrates the main paradigms used in the experiments: leave-one-out training across domains, and sequential (streaming) training that mimics datasets arriving over time.
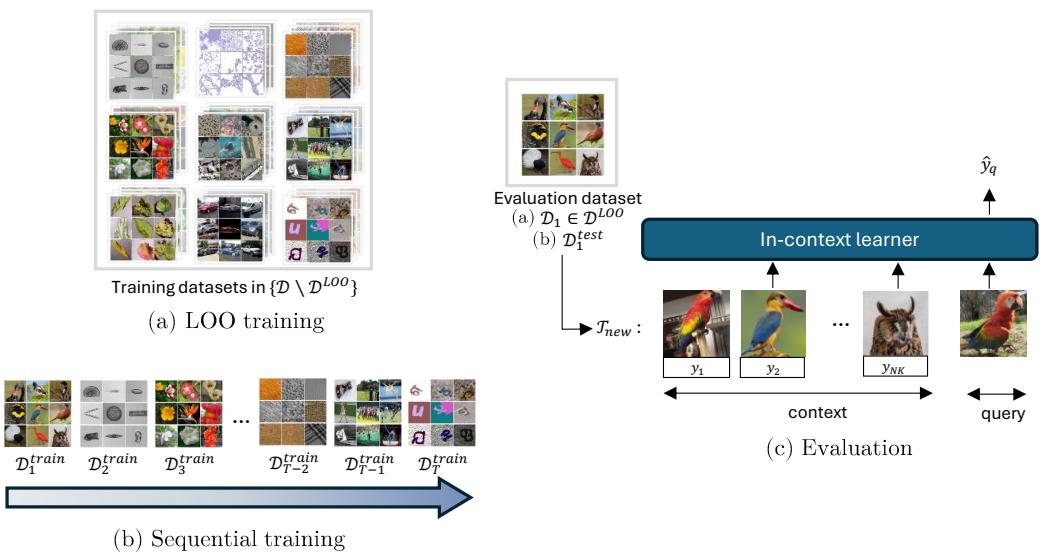
Figure 1: Overview of GEOM. Left: (a) Leave-One-Out (LOO) training where one domain is held out for evaluation; (b) sequential training where datasets arrive one at a time. Right: evaluation process where a context of labeled examples and a query are fed into the in-context learner to predict the query label.
Let’s make the building blocks concrete.
- Each learning episode is an N-way K-shot classification task (the paper uses N=5, K=5 in most experiments).
- For each query image, the input to the transformer is the non-causal concatenation of all context (image, label) pairs plus the query image embedding. Non-causal here means the order of context examples doesn’t matter; the transformer encoder can attend to all support examples jointly.
- GEOM has three components:
- f_ψ: a feature extractor (ResNet-50 pretrained on ImageNet-1k) that produces image embeddings.
- g_φ: a linear label encoder that turns discrete class IDs into learned vectors.
- M_θ: a non-causal transformer encoder that ingests the sequence and produces a query output used by a classifier head.
Mathematically, for each task i and its Q queries, a sequence for query q is
\[ S_{i,q} = ((f_\psi(x_1), g_\phi(y_1)), \dots, (f_\psi(x_{NK}), g_\phi(y_{NK})), f_\psi(x_q)) \]and the training objective minimizes the expected cross-entropy loss over queries:
\[ \min_{\theta,\phi} \mathbb{E}_{S_i} \left[ \frac{1}{Q} \sum_{q=1}^{Q} \mathcal{L}(M_\theta(S_{i,q}), y_q) \right]. \](Where NK is the total number of support examples and y_q is the true class of the query among the N classes in the support.)
To help visualize the sequence format and the objective, the authors included schematic images showing sequence construction and the optimization loss (here reproduced):
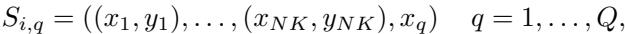
Figure: Construction of non-causal sequence S_{i,q} from the NK context pairs and the query x_q.
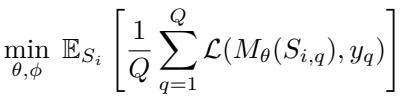
Figure: Training objective minimized across queries of sampled tasks.
The playground: Meta-Album — curated, multi-domain few-shot datasets
Rather than one monolithic dataset, the experiments use Meta-Album: a collection of 30 image classification datasets that span 10 domains (Large Animals, Small Animals, Plants, Plant Diseases, Microscopy, Remote Sensing, Vehicles, Manufacturing, Human Actions, and OCR). Each domain contains three datasets added in successive releases; Meta-Album offers Micro / Mini / Extended sizes to trade off class diversity and per-class image counts.
Because Meta-Album is explicitly multi-domain and curated, it’s an excellent testbed to evaluate true cross-domain generalization (via leave-one-out evaluations) and to support sequential training scenarios where datasets become available over time.
Figure: Meta-Album Mini dataset IDs arranged by domain and release (three datasets per domain).
Experiments: three realistic scenarios
The paper evaluates the GEOM family across three complementary setups:
- Supervised (offline) leave-one-out (LOO) training: train on datasets from nine domains and evaluate on the held-out domain to measure cross-domain generalization.
- Sequential (streaming) training (GEOM-S): datasets are presented one at a time; earlier data becomes unavailable. This probes forgetting and lifelong learning behavior, and allows experimenting with curricula (ordering).
- Unsupervised training (GEOM-U): no labels during training; tasks are synthesized from augmentations and mixup-like constructions. This reflects real-world situations with abundant unlabeled data.
Across these, the authors compare variants:
- GEOM: training on individual Meta-Album datasets (tasks sampled within a single dataset).
- GEOM-M: merging the datasets into a single large dataset and sampling tasks from this merged pool.
- GEOM-IN: baseline trained on ImageNet-1k (common large-scale benchmark).
- GEOM-S: sequential variant, processing datasets in a stream.
- GEOM-U: unsupervised variant trained on pseudo-tasks from unlabeled data.
1) Supervised (offline) LOO: separate datasets beat naive merging
A core question: is it better to merge many small datasets into a single “big” dataset, or to keep each dataset distinct during training? The paper compares GEOM (per-dataset tasks), GEOM-M (merged tasks), and GEOM-IN (ImageNet-1k baseline) under the LOO setting.
The headline results:
- GEOM often matches or outperforms GEOM-M. Preserving dataset identity while sampling tasks from individual datasets leads to stronger cross-domain generalization.
- GEOM-IN (ImageNet-trained) wins in domains with large class overlap with ImageNet (e.g., Large Animals), which is likely data leakage/memorization rather than true generalization.
- In domains with distributional shift despite overlap (e.g., Remote Sensing: aerial imagery vs. normal photos), GEOM often performs better because GEOM focuses on learning adaptation strategies rather than memorizing ImageNet classes.
The figure below summarizes accuracy across Meta-Album datasets for the three variants, and shows the degree of class overlap with ImageNet-1k (which explains GEOM-IN’s unfair advantage in some domains).
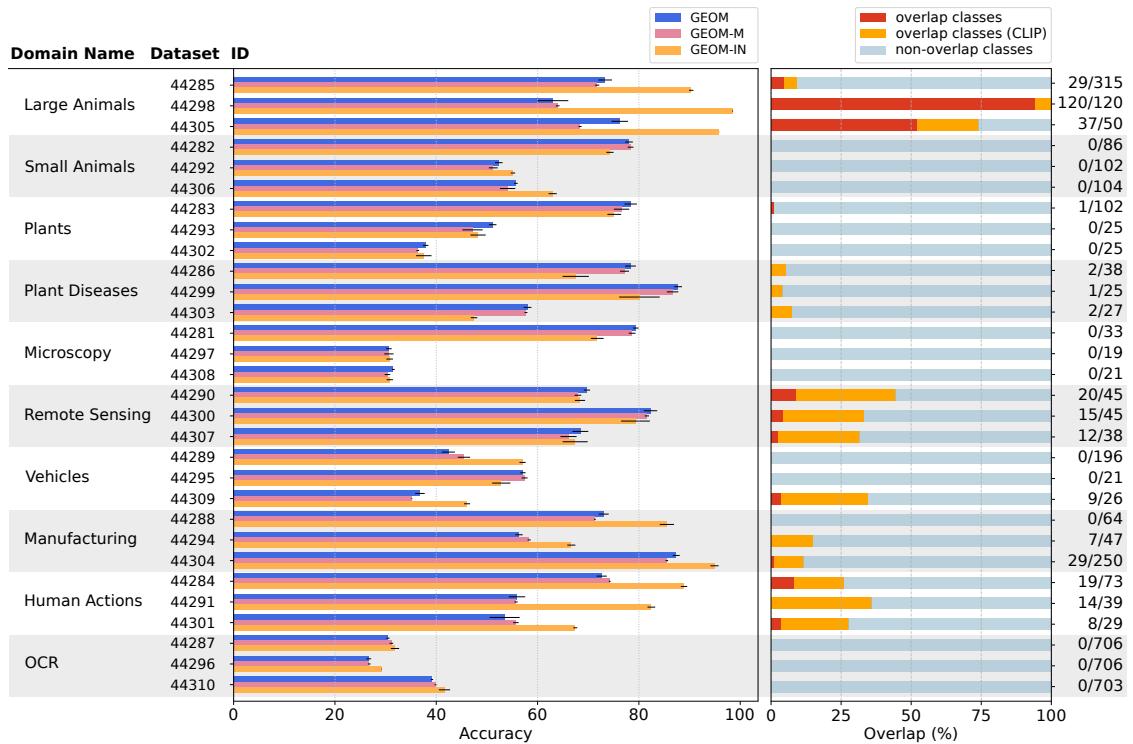
Figure 2: Left — accuracy comparison across Meta-Album Mini datasets: GEOM (blue), GEOM-M (purple), GEOM-IN (orange). Right — fraction of overlapping classes between ImageNet-1k and each Meta-Album dataset (red/orange indicate overlap).
Practical takeaway: mixing disparate datasets into one blob can obscure domain structure and hinder learning of adaptable strategies. If your goal is cross-domain few-shot adaptation, keep datasets modular and expose the meta-learner to domain-specific tasks.
2) What drives gains: class diversity > sheer image count
Which is more valuable for in-context generalization: more classes or more images per class? The authors compared training on three Meta-Album sizes:
- Micro: few classes per dataset (but same images/class as Mini).
- Mini: many more classes per dataset (but 40 images/class).
- Extended: roughly the same class set as Mini, but with many more images per class.
They evaluated on external benchmarks (CIFAR-fs, CUB, Aircraft, Meta-iNat, EuroSat, ISIC) to probe out-of-distribution transfer.
Key findings (see Table 2 in the paper):
- Moving from Micro to Mini yields the largest gains—i.e., increasing the number of classes (class diversity) is highly beneficial.
- Increasing images per class (Mini → Extended) gives smaller gains and often slows early convergence.
- With smaller Mini, the model can peak faster and then overfit if trained long enough; Extended reduces overfitting due to more images.
The result argues that meta-learning and ICL benefit more from encountering a variety of task types (diverse classes) than from sheer repeated exposure to the same classes.
To illustrate the overfitting dynamics, validation curves show Mini peaking early (then drifting down), whereas Extended improves more steadily:
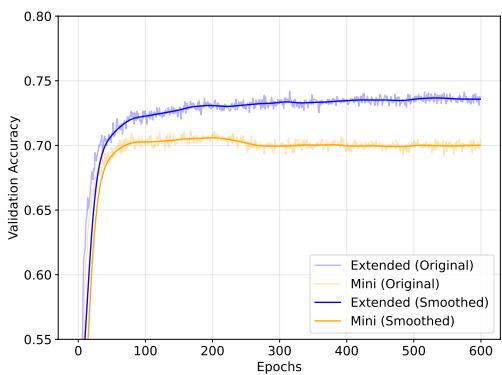
Figure 4: Validation performance: GEOM trained on Mini (orange) and Extended (blue). Mini peaks earlier and declines (overfitting), Extended improves more steadily.
Practical takeaway: when collecting data to train meta-learners or in-context learners, prioritize increasing the diversity of classes and tasks instead of simply multiplying images of the same classes.
3) Sequential learning (GEOM-S): learning over time without catastrophic forgetting
Real systems often see data arrive over time. GEOM-S explores whether an in-context learner trained sequentially on datasets can retain or even improve on prior domains without rehearsal (i.e., without storing past data).
Setup highlights:
- Datasets are introduced one at a time (30 Meta-Album datasets).
- Two scheduling strategies for training epochs per dataset:
- Static: equal epochs per dataset.
- Proportional: epochs proportional to dataset size.
- Evaluation uses a modified Backward Transfer (BWT) to measure domain-level forgetting or improvement.
Surprising result: after an initial adjustment period, GEOM-S often exhibits positive backward transfer—performance on earlier domains improves as new domains are observed. The heatmap below captures relative gains and shows positive values when later training helps earlier domains.
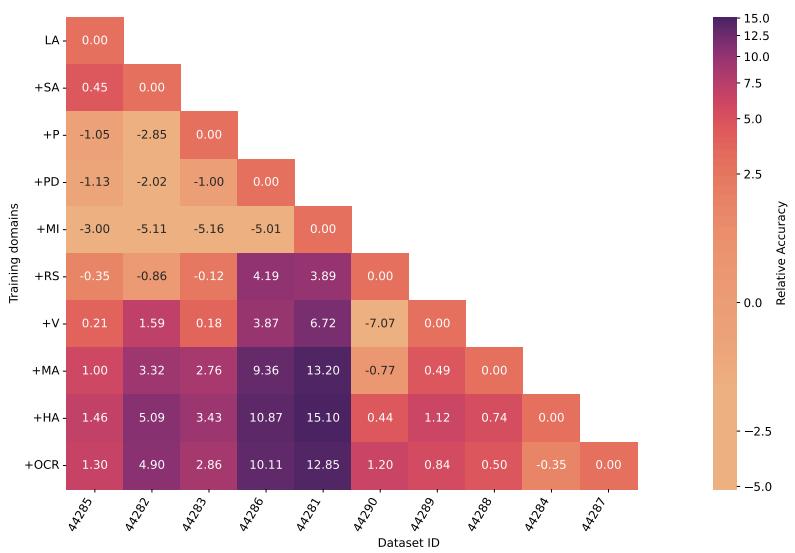
Figure 6: Heatmap used to compute BWT: each cell shows the change in accuracy on a dataset when training progressed to a certain point in the sequential stream. Positive values indicate improved generalization to earlier domains as more domains are observed.
Why might this happen? Seeing more classes and diverse tasks allows GEOM-S to refine representations and strategies that are useful across domains. Rather than catastrophic forgetting, the transformer accumulates more robust, domain-invariant reasoning for in-context inference.
Practical takeaway: meta-learned in-context learners can accumulate transferable strategies across domains. When constrained to stream-style training, prioritize reasonable epoch allocation (proportional to dataset size when feasible), and consider curriculum ordering.
Curriculum learning: order matters, and “hard first” sometimes wins
Because the dataset order influences what a sequential learner learns early, the authors experimented with several curricula:
- TL-based curriculum: rank datasets by fine-tuning difficulty (how well a pretrained ResNet can be fine-tuned on each dataset). Two strategies tested:
- Easy→Hard (E2H)
- Hard→Easy (H2E, an “anti-curriculum”)
- OT-based curriculum: use Optimal Transport Dataset Distance (OTDD) to measure pairwise dataset similarity and order datasets in ways that either follow local similarity (Easy-to-Easy, E2E), jump to dissimilar ones, or alternate.
Key insights:
- For TL-based ordering, H2E (hard-to-easy) often outperforms E2H. Exposing the model to hard tasks early encourages exploration of the parameter space and prevents premature specialization.
- For OT-based ordering, a smooth progression of similar datasets (E2E) tends to work well because knowledge builds incrementally and reduces forgetting.
Below are figures summarizing TL-based curricula comparison (E2H vs H2E) and the OT-based curricula comparison.
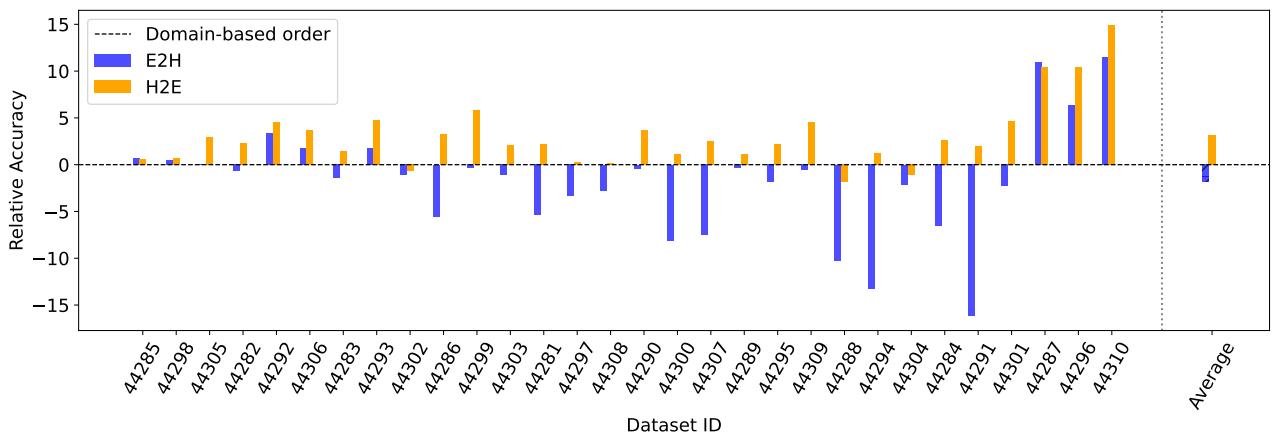
Figure 7: Relative accuracy differences: E2H vs H2E compared to the domain-based order baseline. H2E achieves the best average relative gain in these TL-based curriculum experiments.
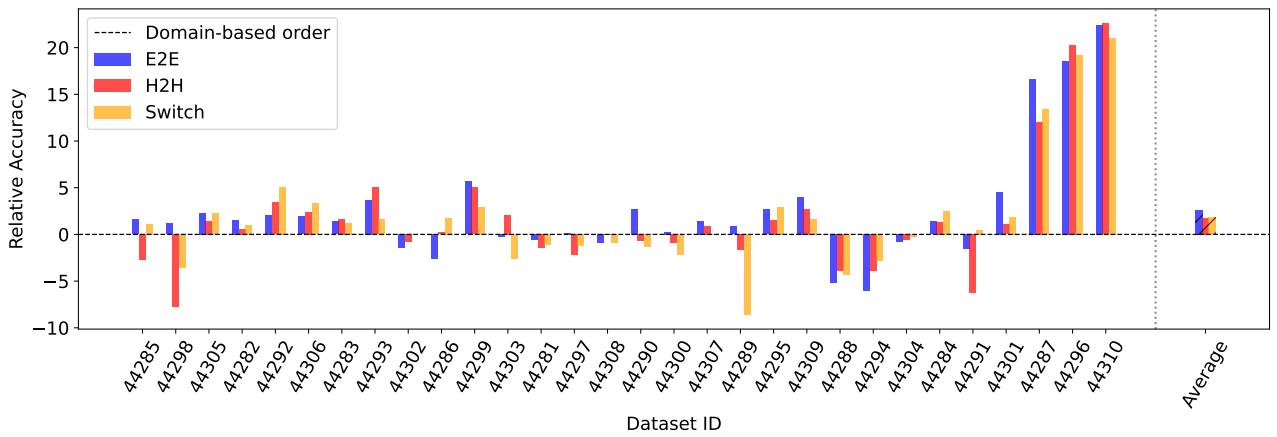
Figure 9: OT-based curricula comparison: E2E, H2H, Switch vs domain-based baseline. E2E tends to produce smooth improvements by presenting similar datasets sequentially.
Practical takeaway: curriculum design is not one-size-fits-all. Where a pretrained feature extractor biases the learning (TL-based ranking), training hard tasks early can force broader representation learning. When you can measure dataset similarity directly (OTDD), structured incremental curricula that present similar datasets successively often improve retention and performance.
4) Unsupervised training (GEOM-U): unlabeled small datasets beat unlabeled ImageNet
Collecting labeled data is expensive. So the authors also investigate an unsupervised variant inspired by CAMeLU: create pseudo-tasks from unlabeled data by grouping augmented versions of the same image as a pseudo-class, and generate query examples via augmentations and mixing (mixup-like). GEOM-U is trained on Meta-Album Mini without labels; CAMeLU (baseline) is trained similarly on ImageNet-1k without labels.
Result: GEOM-U outperforms CAMeLU (ImageNet-unlabeled) on most Meta-Album domains under the LOO evaluation. The diversity across many domain-specific small datasets yields better domain-invariant in-context learners than training on one huge unlabeled corpus.
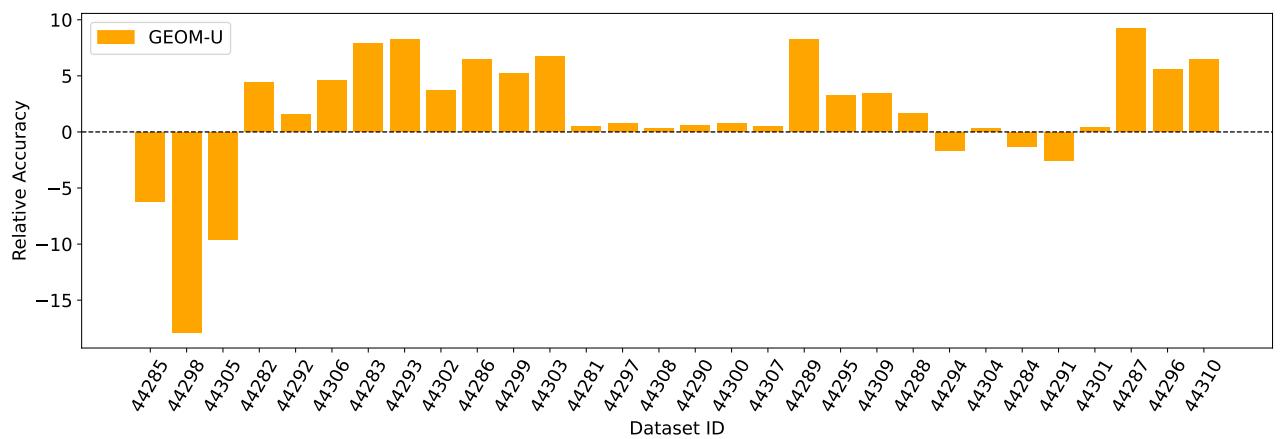
Figure 10: GEOM-U vs CAMeLU (both trained unsupervised): relative accuracy difference (GEOM-U − CAMeLU). GEOM-U is typically better except in domains with heavy overlap with ImageNet-1k.
Why does this happen? The small, diverse datasets force the model to solve many different visual recognition styles and augmentations during training. This pushes the learner to build flexible mechanisms for mapping context to labels, rather than relying on memorized class priors present in ImageNet.
Practical takeaway: if you must train unsupervised, prefer a curated collection of diverse, domain-specific datasets—if available—over a single massive, heterogeneous corpus. Diversity of task types drives more robust in-context behaviors.
Robustness and label noise
The authors also tested robustness to noisy input-label mapping in the demonstrations: what if some support labels are wrong? GEOM remains robust when up to moderate levels (e.g., 10–25% wrong) of labels in the support set are incorrect. Interestingly, training with small amounts of label noise can act as a form of regularization, sometimes improving cross-domain generalization—consistent with other works on robustness.
Practical recommendations
If you care about building reliable in-context learners (or few-shot meta-learners) with limited resources, these findings suggest practical steps:
- Prefer multiple curated datasets, each capturing distinct domains or modalities, over pooling everything into an unstructured, enormous dataset.
- When collecting new data, increase the number of classes (task diversity) before increasing the number of images per class.
- For continual or streaming scenarios:
- If possible, allocate training time proportional to dataset size; if not, adopt a curriculum.
- Consider starting with challenging datasets (H2E) when a pretrained backbone exists, or use OT-based incremental curricula when you can compute dataset similarity.
- For unsupervised setups, assemble many small, diverse unlabeled datasets and use augmentation-based pseudo-task construction rather than relying solely on a single large unlabeled corpus.
- Keep datasets modular and separate so you can audit, update, or remove problematic data easily—benefits that matter for privacy and data governance.
Limitations and open questions
The paper demonstrates that GEOM can match or beat some baselines in many settings, but it does not claim to be a universal replacement for large-scale pretraining. There are trade-offs:
- Some domains (e.g., Manufacturing, which emphasizes low-level features) can still benefit from pretraining on very large corpora like ImageNet if the task hinges on subtle texture or low-level cues.
- The experiments freeze the ResNet feature extractor in many setups; joint end-to-end training could change dynamics (the authors provide some ablations).
- Curriculum design requires careful metric choices (TL-based vs OT-based), and computational costs for OTDD can be high.
Future directions the authors highlight:
- Tuning the number of images per class optimally for resource-constrained regimes.
- Dynamic curricula that adapt ordering based on run-time performance.
- Extending GEOM beyond non-causal encoders to causal architectures and broader task families.
Bottom line
This paper offers an important and practical counterpoint to the prevailing “scale everything” mentality. By meta-learning an in-context transformer across many curated, domain-specific datasets, GEOM achieves strong out-of-domain generalization, robust sequential learning, and surprisingly strong performance even in unsupervised regimes.
If you’re building few-shot or in-context systems and want better interpretability, modularity, and data governance—or if you simply can’t afford web-scale pretraining—this research suggests a clear alternative: thoughtfully curated diversity trumps raw scale when your goal is adaptable, generalizable in-context learning.
Acknowledgments: The experiments and figures discussed in this article are drawn from “Meta-Learning Transformers to Improve In-Context Generalization” by Braccaioli et al.
Further reading (selected):
- CAMeLU: Unsupervised meta-learning via in-context learning (Vettoruzzo et al., 2025)
- Context-Aware Meta-Learning (CAML, Fifty et al., 2024)
- Optimal Transport Dataset Distance (OTDD) for dataset similarity (Alvarez-Melis & Fusi, 2020)
If you want to reproduce or extend these experiments, the paper’s supplementary materials include code and detailed dataset splits for Meta-Album (Mini/Extended), curriculum orders, and training hyperparameters.