](https://deep-paper.org/en/paper/2509.24527/images/cover.png)
Imagine trying to learn a complex skill—like mastering a new video game or operating a robot—using only recorded videos of other people doing it. You can’t interact with the environment yourself; you can only watch and deduce the rules. How would you discover the right strategy to succeed?
This is one of the great challenges of artificial intelligence: teaching agents to act effectively in complex environments using only offline data, without trial-and-error interaction. This approach is vital for real-world applications such as robotics, where each experiment can be slow, costly, or unsafe.
A powerful solution is the world model—a neural network that learns the rules and physics of an environment directly from video data. Once trained, this model becomes a kind of dream engine, enabling agents to practice inside their own imagination. They can simulate experiences and learn strategies entirely offline.
Until recently, however, building world models that were both accurate and fast enough for imagination training proved difficult. Earlier models either misrepresented object interactions or required massive computing resources for each step of simulation.
In the new paper “Training Agents Inside of Scalable World Models” , researchers from Google DeepMind introduce Dreamer 4, an agent that finally overcomes these hurdles. Dreamer 4 trains entirely inside its own imagined world, learning complex long-horizon behaviors with no direct environment interaction. In the process, it has achieved something unprecedented—it became the first AI to obtain diamonds in Minecraft, one of the game’s hardest goals, purely from offline gameplay data.

Figure 1: Dreamer 4 learns to perform long-horizon tasks in Minecraft by training entirely within its own internal simulation of the game world.
Background: The Building Blocks of Generative Models
Before unpacking how Dreamer 4 works, it helps to understand the foundations it builds upon. Dreamer 4’s world model is a type of diffusion-based generative model, a modern framework for producing complex data like images and videos.
Flow Matching
In a standard diffusion model, noise is gradually added to clean data until the data becomes indistinguishable from random noise. A neural network is trained to reverse that process—to iteratively denoise, step by step.
Flow matching simplifies this procedure. Instead of adding and removing noise over thousands of iterations, the model learns a direct path between pure noise \(x_0\) and clean data \(x_1\). Each intermediate state is defined by the signal level \(\tau \in [0,1]\):
\[ x_{\tau} = (1 - \tau)x_0 + \tau x_1 \]The model \(f_{\theta}\) predicts a velocity vector \(v = x_1 - x_0\), pointing straight from noise to data. It minimizes the squared difference between its prediction and the true velocity:
\[ \mathcal{L}(\theta) = \| f_{\theta}(x_{\tau}, \tau) - (x_1 - x_0) \|^2 \]At inference, starting from noise, the model takes iterative steps along this learned direction to generate realistic outputs.
Shortcut Models: Speeding Up Generation
Traditional diffusion models require hundreds or thousands of tiny steps to generate one image—a huge computational burden. Shortcut Models solve this by teaching the model to leap instead of crawl.
During training, shortcut models learn to take large, accurate jumps by conditioning on the desired step size \(d\). The model is guided by a bootstrap loss that compares the result of a large step with the outcome of two smaller intermediate steps.
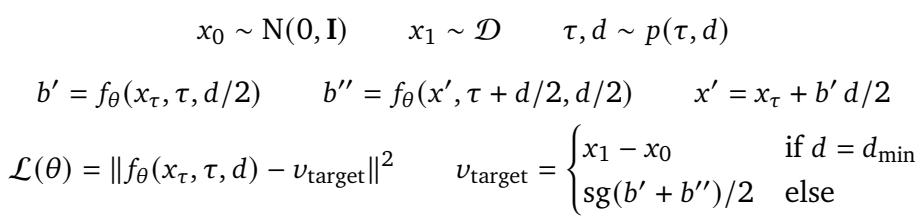
Shortcut training allows models to take larger leaps during inference, reducing hundreds of small steps to just a handful of high-quality ones.
This innovation enables the generation of high-quality samples in as few as 2–4 steps, instead of hundreds—critical for achieving real-time simulation speed in Dreamer 4.
Diffusion Forcing: Generating Video Sequences
Video generation adds a temporal dimension to the challenge. Each frame depends on those before it. Diffusion Forcing assigns a distinct noise level to every frame, allowing each to serve both as a denoising target and as context for subsequent frames. This mechanism helps the model learn coherent temporal dynamics—essential for world models that predict how actions change a scene over time.
The Architecture of Dreamer 4
Dreamer 4 is an integrated agent system centered around its scalable world model. It consists of two main components:
- Causal Tokenizer – compresses visual frames into compact, continuous representations.
- Interactive Dynamics Model – simulates how the world evolves over time in response to actions.
Both components share an efficient transformer architecture designed for high-throughput sequential data.
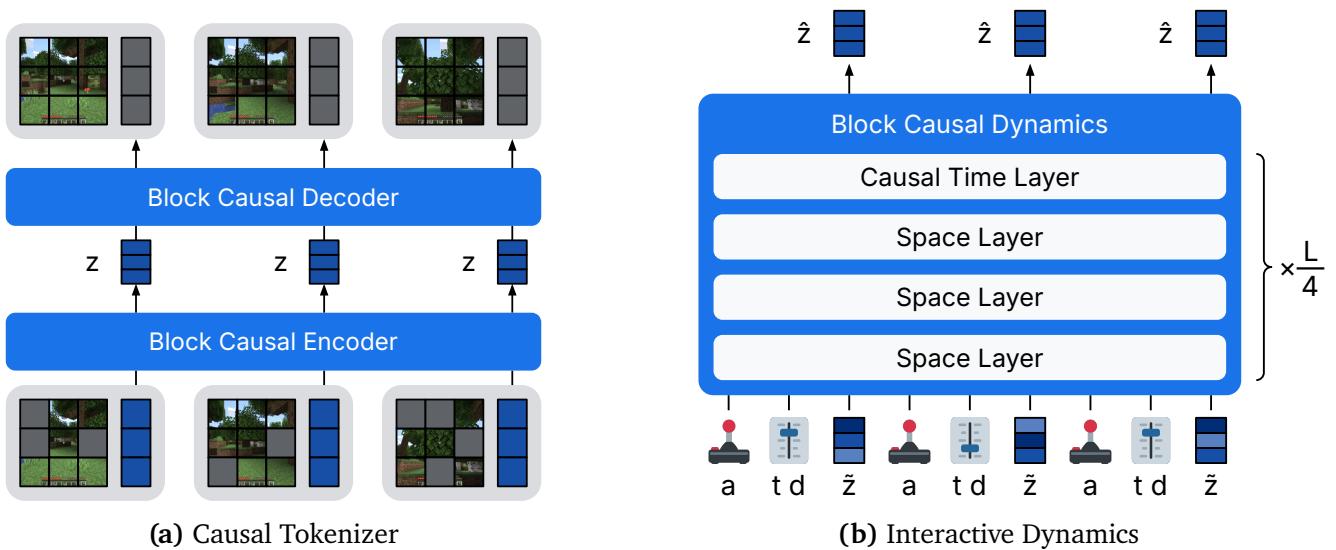
Figure 2: Dreamer 4’s architecture combines a causal tokenizer that encodes video frames with an interactive dynamics model that predicts future frames given actions.
Training proceeds in three distinct phases:
- World Model Pretraining – Learn the physics of the environment from offline videos.
- Agent Finetuning – Add behavior and reward prediction capabilities.
- Imagination Training – Reinforce the policy entirely inside the simulated world.
Causal Tokenizer: Seeing the World Efficiently
Each video frame is too large for direct processing in reinforcement learning. The causal tokenizer converts high-dimensional images into smaller sets of latent “tokens.” It uses an encoder-decoder architecture, where the encoder compresses visuals and the decoder reconstructs them when needed.
To ensure robustness, the tokenizer uses Masked Autoencoding (MAE): during training, random patches of each image are hidden, forcing the model to infer missing details. This encourages a deeper semantic understanding of scenes rather than superficial pixel-matching. The tokenizer operates causally in time, meaning only past frames influence current encoding—vital for streaming, interactive applications.
Interactive Dynamics: The Dream Engine
At the core of Dreamer 4 lies its interactive dynamics model, effectively the “physics simulator” of this learned dream world.
The dynamics model ingests the encoded image tokens and action sequences (e.g., mouse movements, keyboard presses), predicting how these actions transform the world in subsequent frames. Its efficiency and accuracy stem from a novel Shortcut Forcing training objective.
X-Prediction (Clean Representation Targeting): Instead of predicting velocity differences between states (v-prediction), the model directly predicts the clean latent representation \(z_1\) (x-prediction). This prevents the accumulation of small high-frequency errors typical in long rollouts and stabilizes video generation over thousands of frames.
Bootstrap Loss in X-Space: The shortcut model’s bootstrap training is adapted for direct x-prediction. It ensures that one large simulation step yields the same result as multiple smaller ones, maintaining accuracy while enabling accelerated inference.
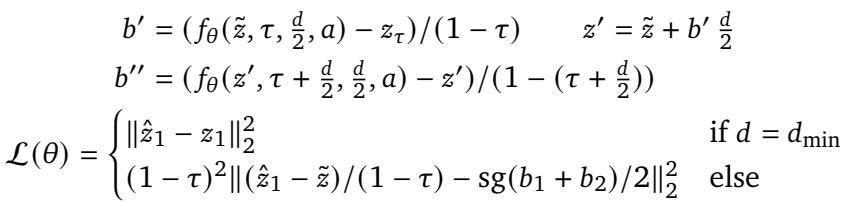
Shortcut Forcing combines flow matching and bootstrap objectives in x-space, allowing Dreamer 4 to simulate sequences quickly while remaining stable.
- Ramp Loss Weight: Since very noisy frames carry little learning signal, Dreamer 4 scales its loss linearly with the signal level \(\tau\):
This focuses model capacity where information is richest.
Together, these innovations make it possible for Dreamer 4’s dynamics model to generate the next frame with just four forward passes, achieving real-time speed on a single GPU.
Imagination Training: Learning to Act in the Dream
After building its internal simulator, Dreamer 4 becomes an agent that learns entirely inside its own imagination.
In the finetuning phase, new heads are added to the transformer: one predicting actions (policy head) and another predicting rewards. These heads are first trained on the offline dataset with behavior cloning, imitating recorded player behavior.
But imitation alone doesn’t create progress. To discover strategies beyond the dataset, Dreamer 4 uses Imagination Training—a reinforcement learning process performed entirely inside its simulated world.
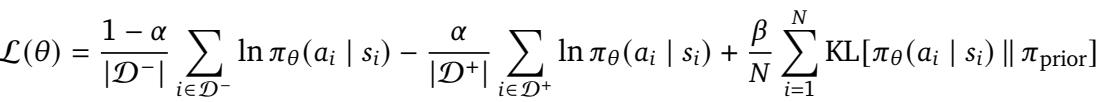
In imagination training, the PMPO objective updates the policy using only simulated trajectories from the world model.
Dreamer 4 rolls out imagined trajectories: actions are sampled from its policy, consequences simulated by the world model, and rewards produced by the learned reward head. A value head predicts cumulative rewards so that the policy can optimize long-term success.
The training objective, called PMPO (Preference Optimization as Probabilistic Inference), updates policies by considering only whether outcomes were better or worse than expected—not by magnitude. This approach prevents instability caused by varying reward scales and ensures balanced learning across tasks.
Experiments: Putting Dreamer 4 to the Test
The researchers evaluated Dreamer 4 extensively in the open-world sandbox of Minecraft, one of the most complex visual control benchmarks available.
The Offline Diamond Challenge
The ultimate test: could Dreamer 4 learn to obtain diamonds? This milestone requires mastering long sequences of actions—chopping wood, crafting tools, mining deep underground—equivalent to roughly 24,000 mouse and keyboard events per episode.
Training used the VPT Contractor Dataset (2,500 hours of recorded human gameplay). Crucially, Dreamer 4 learned purely offline, with no interaction with the live environment.
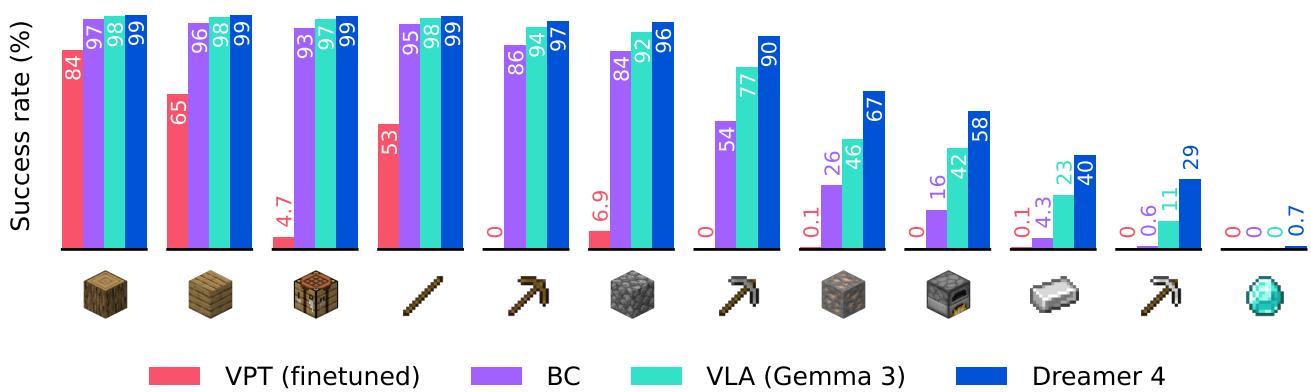
Figure 3: Dreamer 4 dramatically surpasses prior offline agents, becoming the first to collect diamonds purely from recorded data.
The results speak volumes. Dreamer 4 achieved over 90% success on intermediate tasks (crafting stone tools), 29% success on iron pickaxe creation, and successfully obtained diamonds in 0.7% of episodes—a milestone never reached before without online data.
Further ablation studies revealed that imagination training was key:
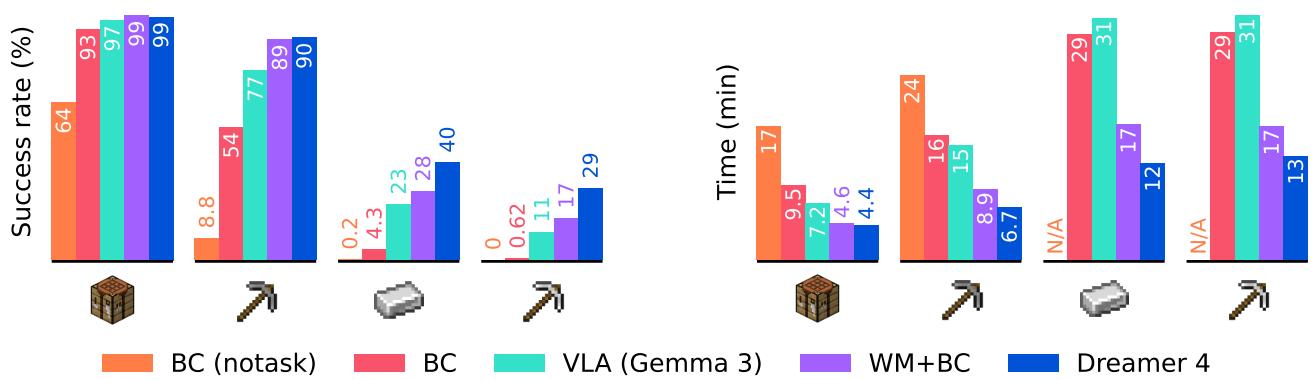
Figure 4: Imagination training improves both success rates and task efficiency compared to pure behavior cloning.
Dreamer 4 significantly reduced the time needed to reach milestones and consistently outperformed all baselines, including OpenAI’s VPT and vision-language models like Gemma 3.
Human Interaction: Playing Inside the Dream
To test the fidelity of the world model’s physics, researchers invited human players to interact inside Dreamer 4’s simulation. Using mouse and keyboard, humans attempted tasks like building a 3×3 wall—comparing Dreamer 4 to prior models such as Oasis and Lucid.

Figure 5: Dreamer 4’s world model is the first to precisely simulate complex interactions, letting humans play and build structures within the imagined world.
Dreamer 4 accurately predicted the effect of each action, enabling genuine gameplay-like interaction. Competing models often blurred visuals, swapped held items, or hallucinated nonexistent structures.
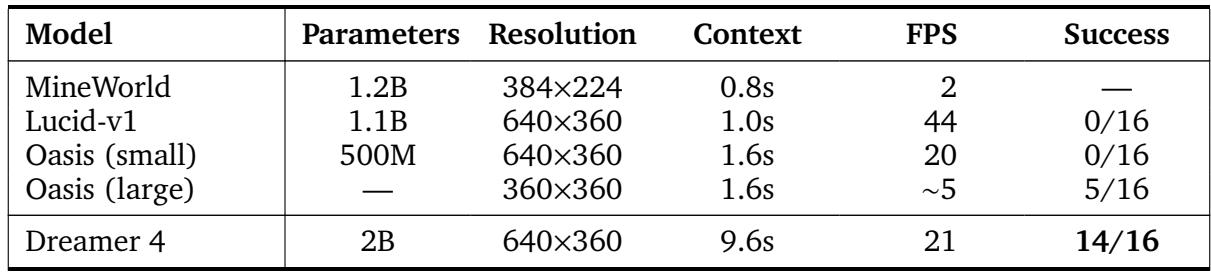
Table 1: Comparison of Minecraft world models. Dreamer 4 achieves the longest temporal context and real-time performance.
Dreamer 4 also mastered robotic simulations when trained on real-world data, learning accurate physics for pick-and-place tasks.

Figure 6: Dreamer 4 applied to robotics. Its world model can simulate realistic physical interactions in real time.
Learning from Unlabeled Videos
A crucial benefit of world models is their ability to learn general structure from video alone. The researchers tested how much labeled action data Dreamer 4 actually needed.
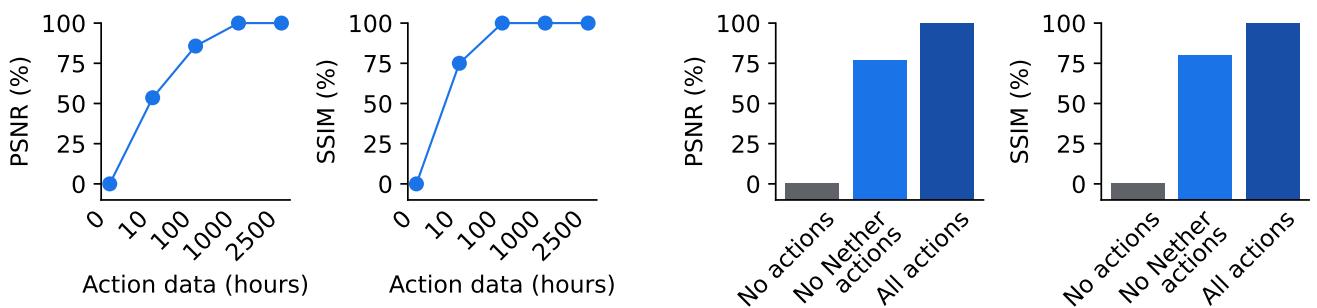
Figure 7: With only 100 hours of action data (≈4% of the total), Dreamer 4 achieves near-perfect action conditioning, even generalizing to unexplored environments like the Nether.
Training on all 2,500 hours of video but only 100 hours of labeled actions, Dreamer 4 reached nearly the same generation quality as full supervised training. Even more remarkably, when trained with actions only from the Minecraft Overworld, it successfully generalized to unseen biomes like the Nether and End—suggesting that action grounding learned from limited data can transfer broadly.
Why It’s Fast and Accurate
The team conducted a thorough breakdown of Dreamer 4’s design, starting from a slow baseline and progressively adding efficiency improvements.
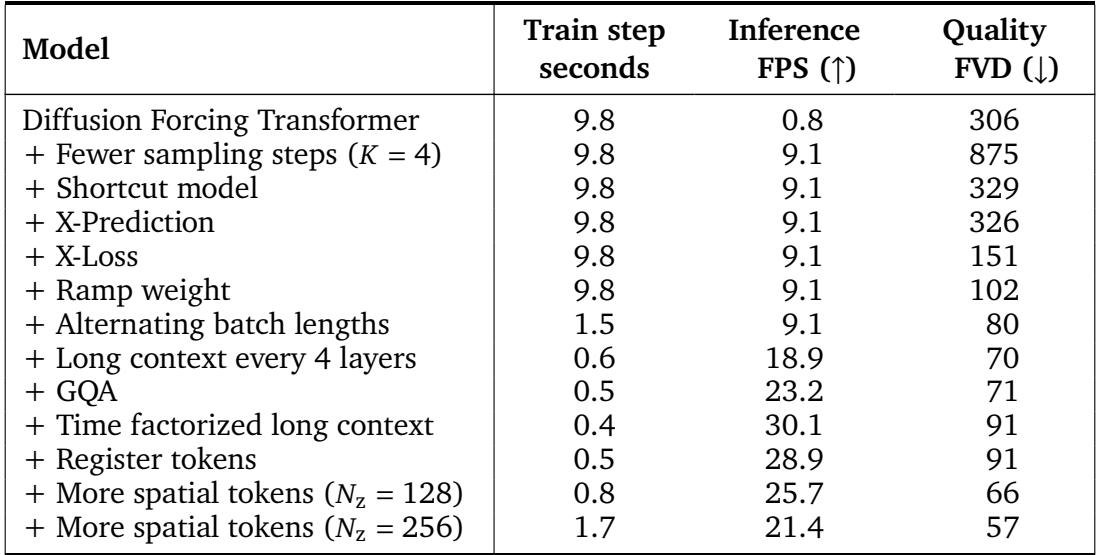
Table 2: Stepwise analysis of Dreamer 4’s architecture. Each design modification improves generation quality (lower FVD) or inference speed (higher FPS).
At first, naive diffusion forcing achieved only 0.8 FPS. Adding shortcut modeling boosted speed to 9.1 FPS while keeping quality steady. Further refinements—x-prediction, x-loss computation, ramp weighting, and architectural optimizations—pushed interactive inference past 20 FPS, matching real-time gameplay.
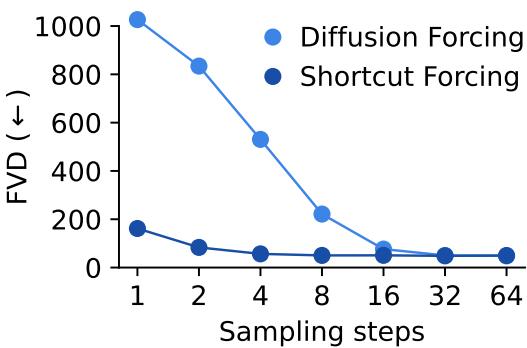
Figure 8: Shortcut Forcing achieves near-equivalent quality to diffusion forcing with only one-sixteenth the sampling steps.
This combination of architectural and training insights produces a world model that is both high-fidelity and real-time capable, a crucial milestone for scalable imagination training.
Conclusion and Future Directions
Dreamer 4 marks a major advance in world modeling and autonomous agent learning. Its innovations—shortcut forcing, causal tokenization, efficient transformer design—collectively enable real-time, scalable imagination-based training.
Key takeaways:
- Imagination training works: Agents can surpass human demonstrations purely by practicing inside learned world models.
- Speed and accuracy in one system: Shortcut forcing and efficient architectures permit real-time, precise simulations from raw pixels.
- Learning from passive video is viable: Only small fractions of labeled actions are needed; the rest can come from observing the world.
These achievements open remarkable horizons: pretraining on diverse web videos, applying world models to robotics, incorporating language understanding, and scaling to agents that reason over indefinite timelines.
Dreamer 4 doesn’t just imagine—it dreams realistically. And in doing so, it demonstrates how intelligent agents may one day learn the complexities of the world not through trial—and error—but through imagination itself.