](https://deep-paper.org/en/paper/2510.00365/images/cover.png)
Imagine teaching a robot a series of home chores. First, it masters making coffee. Next, you show it how to make toast. But after learning to toast, it completely forgets how to make coffee. Worse, as you keep adding new tasks, it becomes “stuck,” unable to absorb fresh knowledge at all.
This is the core challenge of continual learning—a setting where an artificial intelligence system learns from a continuous stream of data without revisiting past examples. It faces two major obstacles: catastrophic forgetting, where it loses previously learned skills, and loss of plasticity, a slow deterioration of its ability to learn anything new.
Traditional approaches have tackled forgetting; however, preserving plasticity remains much more elusive. Interestingly, recent findings show that Transformer architectures, powered by attention mechanisms, handle continual learning remarkably well. But what makes attention so effective?
A new research paper, “Continual Learning with Query-Only Attention”, offers a surprising insight: you can discard the keys and values—the essential components of attention—and keep only the queries. The result? A simpler model that not only performs competitively but also enhances continual learning capabilities. Let’s unpack how this minimalist idea works and why it’s so powerful.
The Twin Challenges of Continual Learning
To appreciate the novelty of Query-Only Attention, we first need to understand the terrain.
In standard training, a model sees the entire dataset multiple times through epochs. In contrast, continual learning feeds data sequentially—each point appears once. The stream may change distributions as new tasks arrive, creating an environment that’s both dynamic and unforgiving.
Two key problems emerge:
- Catastrophic Forgetting: When a model trains on new tasks, updates to its parameters overwrite what it previously learned. Performance on older tasks collapses.
- Loss of Plasticity: Over time, the model’s parameters settle into a narrow region of the loss landscape. Gradients flow weakly, making adaptation to new tasks difficult. Even with fresh data, it struggles to learn.
The authors argue that preserving plasticity is the real linchpin. If a system keeps its learning flexibility intact, reduced forgetting becomes a natural consequence.
The Building Blocks: Attention, Meta-Learning, and kNN
Before plunging into their method, let’s revisit three foundational concepts that the paper cleverly connects.
1. Standard Attention
Attention allows models, such as Transformers, to reason over context. It uses three kinds of vectors: queries (Q), keys (K), and values (V). The query represents the current focus item, keys represent all potential context items, and values carry the associated information.
Each query compares itself to all keys—usually through a dot product—to compute weights determining how much emphasis to place on each value.
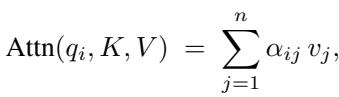
Figure: In full attention, each query interacts with all keys to produce weights applied to the corresponding value vectors.
Weights are obtained via a softmax over query-key similarities.
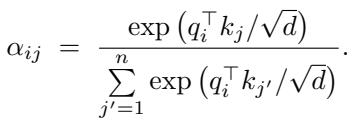
Figure: Attention weights amplify relevant context while diminishing irrelevant information.
This computation scales as \(O(n^2)\) for a sequence of length \(n\). While powerful, the quadratic cost can be prohibitive for continual learning where data arrives rapidly.
2. Model-Agnostic Meta-Learning (MAML)
MAML approaches learning as an optimization problem over tasks. Instead of training for a single task, it seeks an initialization capable of quick adaptation to new ones. It alternates inner-loop updates (task-specific learning) and outer-loop updates (meta-level adjustment), effectively “learning how to learn.”
3. k-Nearest Neighbors (kNN)
A timeless method, kNN makes predictions by averaging the outputs of the closest examples from stored data.
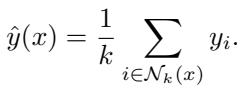
Figure: kNN predicts outcomes based purely on proximity to stored examples.
kNN is immune to catastrophic forgetting—it stores knowledge as raw data, not volatile parameters. However, it lacks generalization across tasks. The paper’s query-only approach bridges this gap by combining data-driven adaptability with learned similarity.
The Core Idea: Query-Only Attention
The proposed Query-Only Attention strips the full attention mechanism down to its most essential piece. By dropping keys and values, it replaces the query-key interaction with a learned function \(Q_\theta\) that measures similarity directly.
Here’s how it works:
- Replay Buffer: Maintain a memory buffer \( \mathcal{B} \) of previously seen samples \((x, y)\).
- Incoming Query: When a new sample \(x_t\) arrives, treat it as the query.
- Sample Support Set: Draw a small support set \(S\) from the buffer to serve as context.
- Compute Similarity Scores: For each element \((x_j, y_j)\) in the support set, compute a score \(d_j = Q_\theta(x_t, x_j, y_j)\) —a learned measure of relevance.
- Generate Output: Predict \(\hat{y}_t = \sum_j d_j y_j\), a weighted average of support labels.
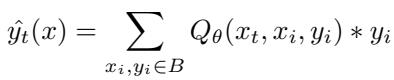
Figure: Query-Only Attention predicts using a learned weighting function between the query and stored examples.
This model scales linearly \(O(n)\) with respect to support size—an enormous efficiency boost compared to full attention’s \(O(n^2)\). It can handle much larger buffers, enabling richer context while remaining computationally light.
A Unified Perspective on Lifelong Learning
The authors provide a conceptual bridge linking Query-Only Attention, meta-learning, and non-parametric models.
Global vs. Local Learning
Traditional neural networks train parameters to fit each task individually—a local solution. Subsequent tasks shift these parameters, causing forgetting.
Query-Only Attention learns a global solution. The network parameters \( \theta \) define a universal similarity function rather than solving specific tasks. Task adaptation occurs dynamically at inference: predictions depend on the contextual support, not on parameter re-optimization. The mechanism becomes in-context, not in-weight.
A Learnable Form of kNN
The structure mirrors weighted kNN, where predictions depend on distance weights:
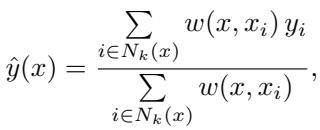
Figure: Weighted kNN computes local predictions using fixed distance-based weights.
Query-Only Attention transforms those fixed weights into learned, dynamic ones via \(Q_\theta(x_t, x_i, y_i)\). This flexibility enables it to infer intricate relationships between data points, offering richer generalization than kNN’s hand-crafted distance metrics.
Implicit Meta-Learning
Remarkably, Query-Only Attention performs an operation akin to MAML—creating temporary task-specific parameters at inference rather than through explicit gradient steps. Predictions can be expressed as:
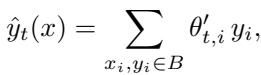
Figure: Each query implicitly generates its own task-specific weights, mirroring meta-learning adaptation.
This means Query-Only Attention practices “meta-learning without inner loops,” adapting seamlessly from experience stored in its buffer.
Experiments and Results
The paper evaluates Query-Only Attention on three continual learning benchmarks, comparing it against Backpropagation (BP), Continuous Backpropagation (CBP), the Full-Attention Transformer, and a MAML-inspired variant.
Performance is assessed via two metrics:
- Forward Performance: Accuracy or loss on new data; degradation signals loss of plasticity.
- Backward Performance: Accuracy on old data; degradation reflects catastrophic forgetting.
Permuted MNIST
Each task permutes MNIST’s pixel positions, forcing the model to adapt to new representations repeatedly.
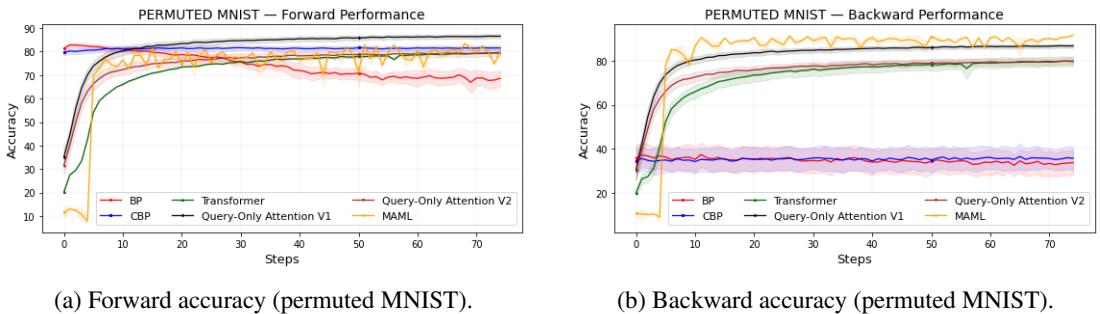
Figure 1: Query-Only Attention maintains strong plasticity and resists forgetting across 7,500 tasks.
Query-Only Attention variants achieve high accuracy comparable to or exceeding full attention, while BP suffers severe degradation. MAML performs well but with higher computational cost.
Split Tiny ImageNet
In this benchmark, each task is a binary classification drawn from Tiny ImageNet’s vast set of classes.
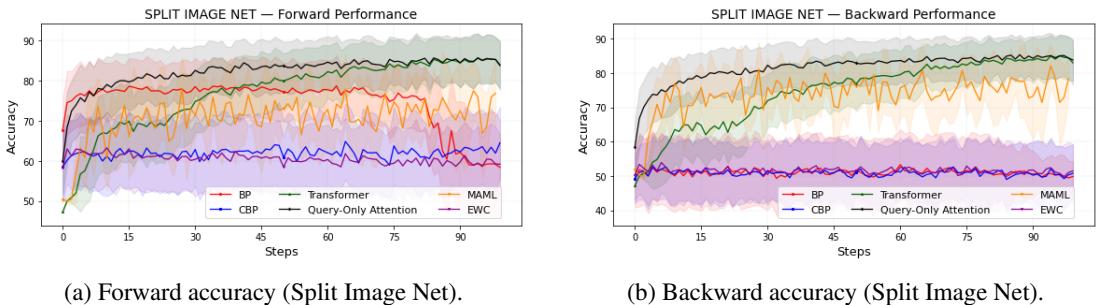
Figure 2: Query-only attention scales efficiently to complex image tasks, preserving both forward and backward accuracy.
Again, Query-Only performs competitively, outpacing traditional methods and EWC-based baselines that target forgetting explicitly.
Slowly Changing Regression (SCR)
Here, the underlying function drifts gradually—a subtle test of a model’s adaptability.
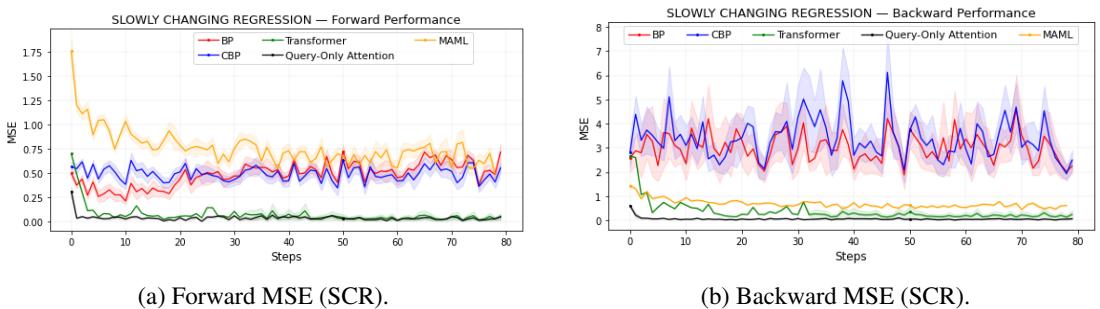
Figure 3: Query-only attention tracks evolving targets, maintaining low error where standard BP loses responsiveness.
Both Query-Only and Transformer models sustain low MSE even as distribution shifts. BP and CBP lose plasticity, while the MAML variant remains stable but less precise.
Digging Deeper: Hessian Rank and Plasticity
To probe the mechanics of learning stability, the authors examine the Hessian matrix of the model’s loss—an analytic tool describing curvature of the optimization landscape. Plastic models exhibit high curvature diversity, allowing flexible direction changes in learning.
The effective rank of the Hessian quantifies this diversity. High effective rank indicates broad learning capacity; a declining rank signals stagnation.
Figure: Effective rank captures curvature richness—the dimensional “spread” of learnable directions.
Empirically, models that preserved plasticity maintained high effective rank.
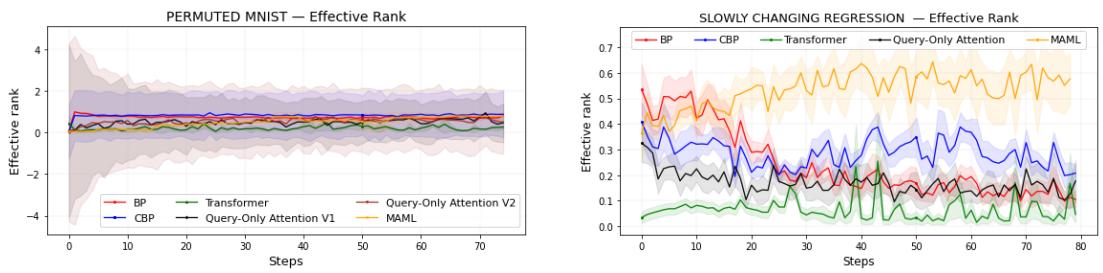
Figure 4: Decline in effective rank aligns with loss of learning flexibility; Query-Only Attention remains robust.
This correlation underscores plasticity’s geometric nature—models must sustain curvature diversity to keep learning across changing tasks.
Key Takeaways and Outlook
The Continual Learning with Query-Only Attention study presents both a theoretical and practical advance:
- Simplicity with Power: Removing keys and values doesn’t hinder learning—it enhances it. Query-only architectures are computationally efficient and plastic.
- Unified Framework: The mechanism connects attention, meta-learning, and memory-based models under one lens, blending the strengths of each.
- Meta-Learning in Context: Adaptation arises naturally during inference, eliminating heavy inner-loop updates.
- Curvature Matters: Empirical Hessian analysis reveals a direct link between effective rank and a model’s ability to stay adaptable.
While reliance on a replay buffer remains a limitation, this work demonstrates that enduring learning need not rely on architectural complexity. In the pursuit of lifelong learning systems—robots, agents, or neural networks that keep evolving—a simple query and a smart similarity function may be all we need.
The future of continual learning might be less about remembering everything—and more about knowing how to ask the right questions.