](https://deep-paper.org/en/paper/2510.27246/images/cover.png)
Beyond a Million Tokens: Building Real Tests — and Real Memory — for Long-Context LLMs
Have you ever chatted with an assistant for a long time and then, a few turns later, had it forget a detail you explicitly told it? As models grow to support enormous context windows — 100K, 1M, even 10M tokens — that failure mode becomes more glaring: bigger context windows don’t automatically translate into better long-term conversational memory.
A recent paper tackles this head-on. The authors make two complementary contributions:
- BEAM: a new benchmark that generates coherent, single-user conversations up to 10M tokens and a rich set of probing questions that test ten distinct memory abilities (not just recall).
- LIGHT: a memory framework inspired by human cognition that equips LLMs with three complementary memory systems — episodic memory (retrieval), working memory (recent turns), and a scratchpad (iteratively summarized salient facts).
This article walks through what the authors built, why existing evaluations fall short, how the BEAM dataset is constructed, how LIGHT works, and what the experiments show about memory in today’s LLMs.
Why this matters (short): if we want assistants that can truly partner with people over long projects or multi-session help, we need realistic evaluation and targeted architecture to make memory useful — not just bigger context windows.
The problem with prior benchmarks
Current long-context benchmarks typically fall into three traps:
- Lack of coherence. Many datasets simulate “long” conversations by concatenating short, unrelated chats. That produces artificial topic jumps and lets models “cheat” by isolating segments rather than reasoning across a narrative that evolves.
- Narrow domains. Benchmarks often focus on personal life scenarios and miss technical or domain-heavy dialogues (coding, finance, health).
- Shallow tasks. Most tests emphasize simple fact recall. They rarely probe abilities like contradiction resolution, instruction following after long gaps, event ordering, or multi-hop inference across dispersed dialogue segments.
The authors’ answer is twofold: generate long, coherent, multi-domain conversations with targeted probes (BEAM), and improve how models access and consolidate memory (LIGHT).
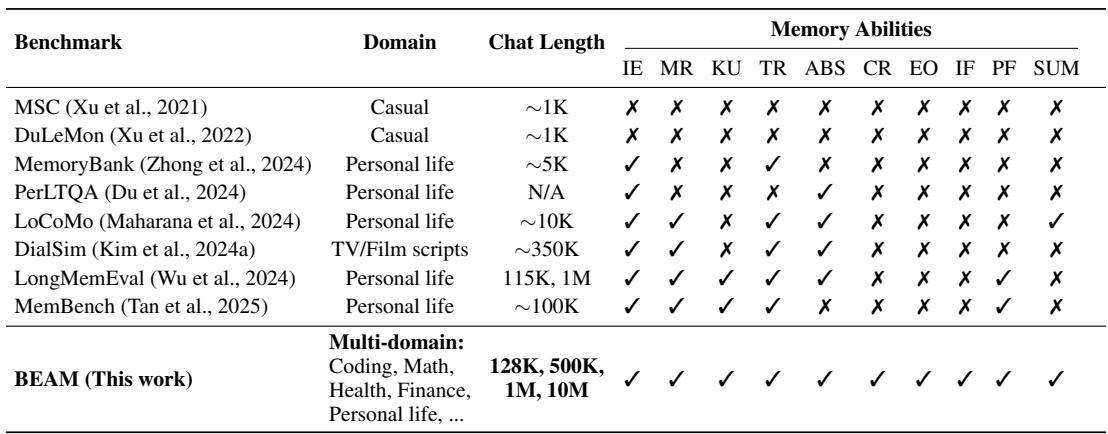
Figure: How BEAM compares to prior benchmarks — BEAM is multi-domain, scales up to 10M tokens, and includes a wider set of memory abilities.
BEAM: generating realistic, extremely long conversations
At the core of BEAM is an automated, multi-stage pipeline that produces long, coherent, and topically diverse conversations and then crafts probing questions that target specific memory capabilities.
Figure 1 below gives a compact view of the pipeline.
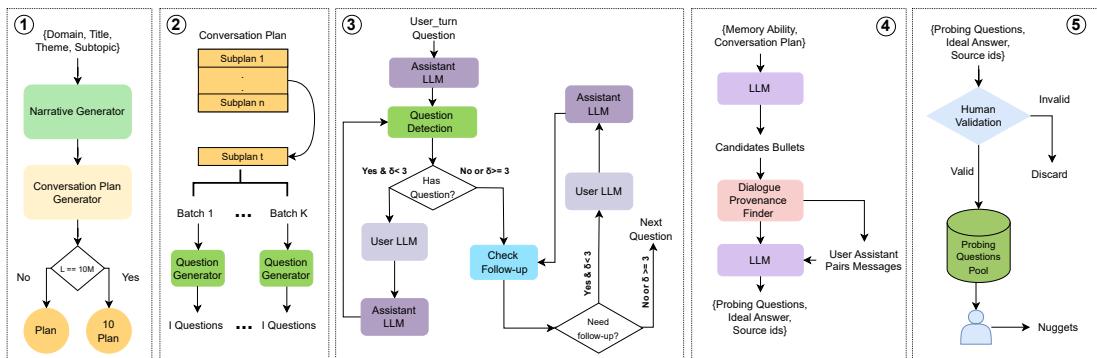
Figure 1: The BEAM data-generation pipeline. It starts with a narrative seed → conversation plan → user and assistant turn generation (with question-detection and follow-up modules) → automated probing-question synthesis → human validation.
Let’s unpack the key stages.
Conversation plan (the scaffold). Each chat begins with a detailed plan generated by an LLM from a seed: domain (e.g., “Coding” or “Health”), title and theme, subtopics, a user profile (name, age, MBTI-like traits), a relationship graph, and an explicit timeline. For very long dialogues (e.g., 10M tokens), the framework composes multiple interlocking plans (e.g., sequential expansion or hierarchical decomposition) so the narrative can evolve naturally over many stages.
User turn generation. Each sub-plan is split into batches to avoid repetitive or unfocused generation. For each batch, an LLM creates user queries that are coherent with the plan, the timeline, prior batches, and the user profile. Batch sizing (how many sub-plans, batches per sub-plan, and questions per batch) is tuned by domain and target conversation length.
Assistant generation (role-playing). Assistant responses are produced in a role-play loop: one LLM plays the assistant, another can play the user. The system uses a question-detection module to catch when the assistant asks follow-ups, and a follow-up-detection module to decide when the user would naturally ask clarifying questions. These modules produce bidirectional, realistic exchanges instead of a flat, scripted Q→A stream.
Probing question synthesis and human validation. Given the generated dialogue and its plan, the system auto-synthesizes candidate probing questions mapped to ten memory abilities (Information Extraction, Multi-hop Reasoning, Information Update, Temporal Reasoning, Abstention, Contradiction Resolution, Event Ordering, Instruction Following, Preference Following, and Summarization). Human annotators validate and refine candidates and produce nugget-based rubrics for evaluation.
Dataset summary: BEAM contains 100 conversations (128K to 10M tokens) and 2,000 validated probing questions. Human judges rated generated chats high on coherence, realism, and complexity.
Why this generation procedure matters: it yields long dialogues that evolve as a single story, include back-and-forth clarifications, and deliberately inject situations that test nuanced memory abilities (e.g., facts that get updated later, contradictions buried far apart, long-spanning preferences/instructions).
LIGHT: three-memory architecture inspired by cognition
BEAM shows us better evaluation targets. LIGHT is the strategy to improve LLM performance on those targets. It mirrors human memory principles:
- Episodic memory (retrieval): an index-like archive of past conversation segments for targeted retrieval.
- Working memory: the most recent turns, kept verbatim for immediate context.
- Scratchpad: an iteratively maintained, higher-level notebook of salient facts, preferences, and normalized timelines; periodically compressed to keep input size manageable.
The high-level flow:
- After each turn, an extractor identifies key–value pairs and a short summary for that exchange; these get embedded and stored in a vector database (episodic index).
- A scratchpad generator reasons over each turn pair to produce salient notes (why it matters, normalized dates, instruction flags, preference cues). When the accumulated scratchpad hits a size threshold, it is compressed into a concise semantic summary.
- At inference, given a question x, the system:
- Retrieves the top-k relevant episodic segments (E) via dense retrieval.
- Provides the last z dialogue pairs as working memory (W).
- Filters scratchpad chunks for relevance to x, producing S_x.
- Feeds x + E + W + S_x to the LLM to answer.
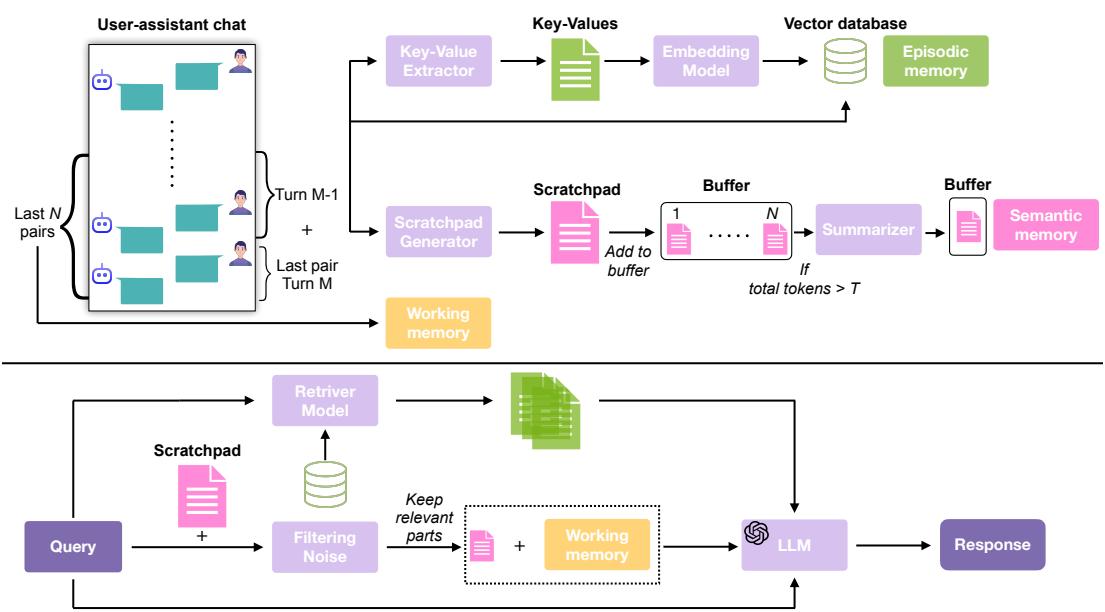
Figure 2: LIGHT overview — three complementary memory stores that the model consults when answering a probing question.
Key design choices and intuitions:
- Episodic retrieval gives precise grounding (like pointing to the paragraph that contains an answer).
- Working memory ensures up-to-the-moment coherence (recent clarifications, immediate conversational state).
- Scratchpad preserves distilled, semantic facts and instructions across long spans (e.g., “always include itemized breakdowns when asked about budget”), overcoming the brittleness of raw transcripts.
Two practical notes:
- Scratchpad is not a retrieval DB — it’s passed directly as context after semantic chunking and relevance filtering.
- When the scratchpad becomes too big, the authors compress it (semantic summarization) to keep the engine efficient and focused.
Experiments: what works — and what still fails
The paper evaluates LIGHT against two baselines:
- Vanilla long-context LLMs (whole-history fed in contexts up to a model’s limit).
- A standard RAG baseline (retrieve top-k segments, pass them with the question).
Models tested included both proprietary models with 1M windows and several open-source LLMs. For RAG and LIGHT the authors used a practical retrieval context size (e.g., 32K) and FAISS for the index.
The headline result: LIGHT consistently outperforms both vanilla and RAG baselines across chat lengths (100K — 10M tokens) and memory abilities.
A few highlights:
- At 1M tokens, LIGHT improved performance by up to ~75.9% over a vanilla baseline for some models.
- At 10M tokens — where no baseline model can natively process the entire history — LIGHT produced dramatic gains (e.g., >100% relative improvements for some backbones).
- Gains are especially large in tasks that require integrating dispersed information: summarization, multi-hop reasoning, and preference following.
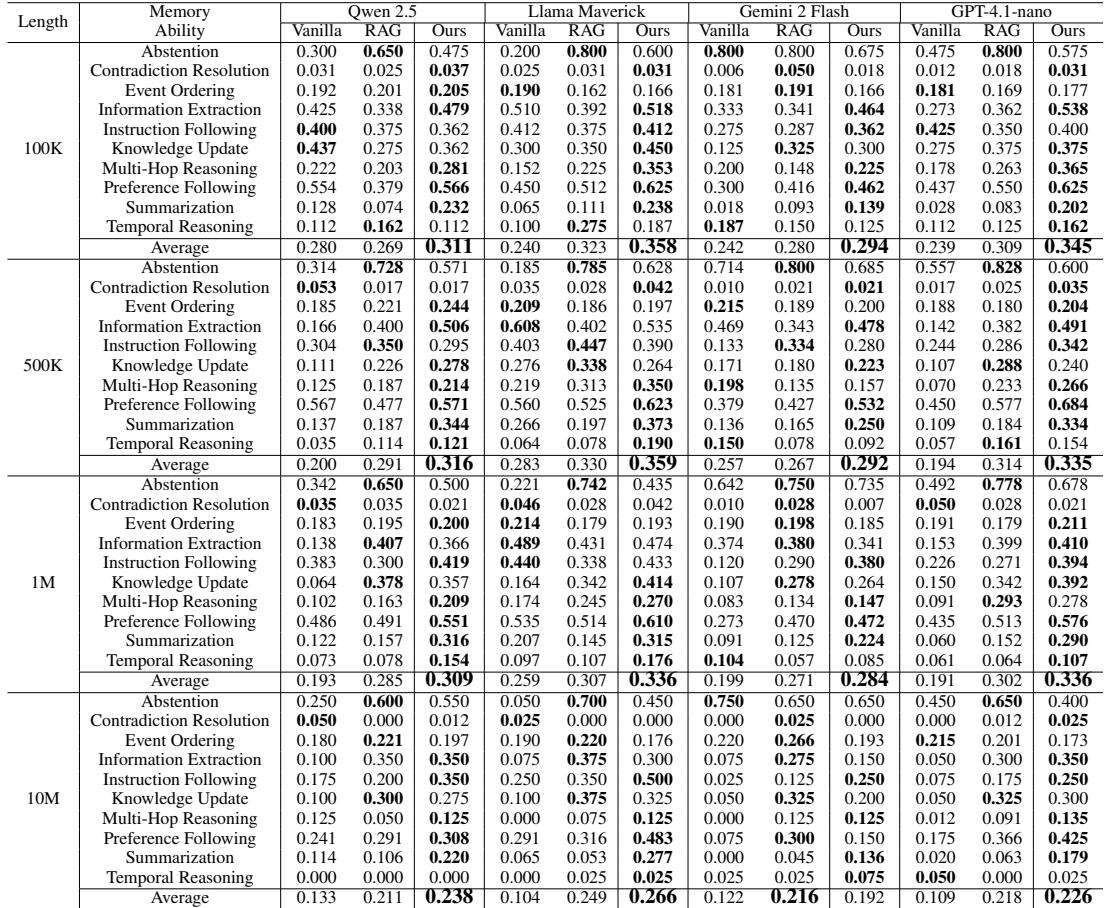
Figure: Overall performance comparison — LIGHT (Ours) outperforms both vanilla long-context and RAG baselines across models and increasingly long contexts.
Ablations and analyses tell an informative story.
- Ablation: removing episodic retrieval, the scratchpad, working memory, or the scratchpad noise filtering each degrades performance — and the harm grows with conversation length. By 10M tokens, removing episodic retrieval or noise filtering produces very large drops.
- Retrieval budget (k): performance generally improved when going from k=5 to k=15 retrieved documents, but degraded when retrieving too many (k=20) — because extra documents often add noise.
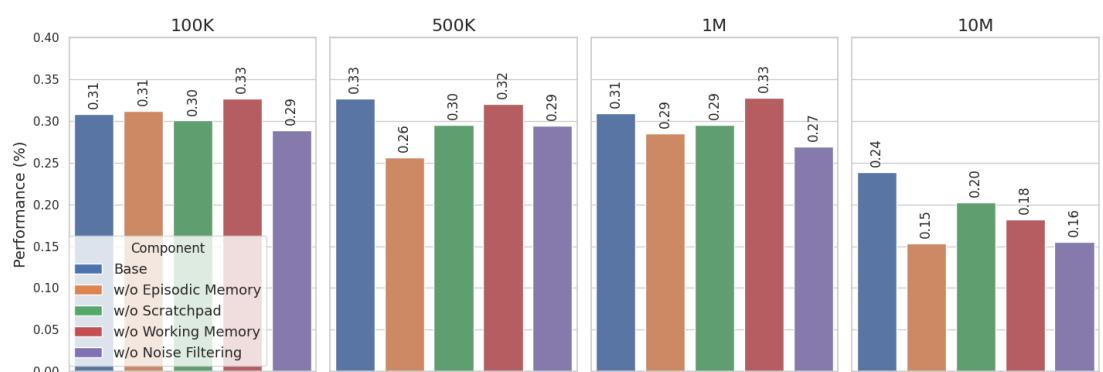
Figure 3: Ablation results. Each component adds value; their importance increases with chat length.
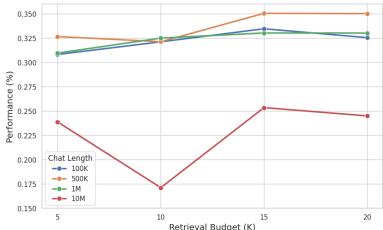
Figure 4: Effect of retrieval budget (K). There is a sweet spot — enough retrieved context to cover distant evidence, but not so much that it overwhelms the model.
A few nuanced points from the experiments:
- At shorter lengths (100K), the scratchpad alone sometimes suffices, and extra retrieval can introduce noise; but as dialogues lengthen, retrieval becomes critical.
- Contradiction resolution remains a challenging ability for all methods — models struggled to detect and reconcile contradictory claims separated by far-apart turns.
- Abstention (saying “I don’t know”) is often handled well; the real weakness is deeper reasoning tasks that require integrating many pieces of evidence.
Case study: why the scratchpad helps
The authors include case studies showing how the scratchpad helps in four abilities:
- Information Extraction: scratchpad aggregates dispersed mentions of tool versions or user attributes, enabling precise recall.
- Instruction Following: the scratchpad can store user meta-instructions (e.g., “always include team counts when discussing mentoring”), so the assistant respects those instructions even many turns later.
- Knowledge Update: when a fact is updated later in the dialogue (e.g., a deadline change), the scratchpad stores the revised value, preventing stale answers.
- Temporal Reasoning: normalized date anchors in the scratchpad make day-difference calculations robust.
These qualitative examples align with the quantitative ablations: the scratchpad materially improves robustness across multiple abilities.
Practical takeaways
- Bigger context windows alone aren’t the solution. Unstructured long context (even if technically feasible) often buries the signal under noise. Structured memory systems that retrieve, summarize, and filter information are necessary to scale reasoning across truly long dialogues.
- Three complementary memory stores — episodic retrieval for precise grounding, working memory for immediate context, and a scratchpad for distilled, high-signal facts and instructions — perform better than any one mechanism alone.
- There is a sweet spot for retrieval depth (k): too few results miss crucial evidence; too many introduce noise. Tuning k matters.
- Some memory tasks remain difficult (notably contradiction resolution). These are promising directions for follow-up research.
Limitations and open questions
The paper advances both evaluation and method, but several limitations remain:
- Human validation is required to ensure high-quality probing questions — building fully automatic, reliably high-quality probes is still an open problem.
- The pipeline generates synthetic dialogues; although human evaluations show high realism, synthetic data always risks artifacts that differ from real-world multi-session human chats.
- Contradiction detection and resolution need more research: models still struggle to reconcile mutually incompatible claims scattered across long histories.
- Computational costs: maintaining and retrieving from massive episodic indices, and maintaining scratchpad compression, require engineering to be efficient in deployed systems.
Final thoughts
BEAM is a strong step toward measuring what truly matters in long conversational memory: coherent narratives, multi-domain complexity, and a broad set of memory abilities beyond rote recall. LIGHT shows a practical path to making long-context LLMs actually use distant information: blend targeted retrieval, short-term context, and an iteratively distilled knowledge store.
If you build or evaluate long-context conversational systems, two lessons are essential:
- Measure the right things. Tests should evaluate a model’s ability to integrate, update, and reason about information that is distributed in time and across topics — not just whether a token is nearby in the context window.
- Architect memory. Use complementary memory mechanisms that can retrieve specific episodes, preserve recent discussion, and maintain a distilled note-like record of important facts and instructions.
These are pragmatic steps toward assistants that can be true multi-session partners: remembering not just what was said, but what changed, what the user prefers, and what the assistant previously advised.