](https://deep-paper.org/en/paper/2510.27656/images/cover.png)
Large Language Models (LLMs) are evolving at a breathtaking pace. We’ve moved from monolithic models to architectures like Mixture-of-Experts (MoE), which scale efficiently to trillions of parameters, and disaggregated inference, where different stages of model execution—prefill and decode—run on distinct, specialized clusters. These new designs are elegant, but they expose a critical weakness in today’s machine learning infrastructure: communication.
For years, distributed training and inference have relied on collective communication libraries—such as NVIDIA’s NCCL or PyTorch Distributed—which excel at synchronized operations like AllReduce and Broadcast. These are ideal for conventional data and tensor parallel workloads where every GPU acts in lockstep. But with emerging workloads like MoE routing and disaggregated inference, this paradigm starts to break down. These tasks are sparse, dynamic, and non-uniform, requiring flexible point-to-point communication instead of rigid, collective synchronization.
Unfortunately, the high-performance tools designed for point-to-point communication—built on Remote Direct Memory Access (RDMA)—are often locked to specific hardware. A solution that shines on NVIDIA’s ConnectX-7 network interface controller (NIC) might degrade or even fail entirely on AWS’s Elastic Fabric Adapter (EFA). This vendor lock-in limits portability and performance across cloud environments.
Researchers at Perplexity AI address this challenge with TransferEngine, a portable RDMA communication library that offers a uniform, high-speed interface across heterogeneous hardware. In this deep dive, we’ll explore how TransferEngine works, the performance breakthroughs it achieves on both NVIDIA and AWS hardware, and how it powers three production-ready systems:
- Disaggregated Inference: Rapid KvCache transfers for elastically scaled clusters.
- Reinforcement Learning (RL): Trillion-parameter model weight updates in under 1.3 seconds.
- Mixture-of-Experts (MoE): State-of-the-art decode latency with ConnectX-7 and the first viable MoE implementation on AWS EFA.
The Communication Divide: Collectives vs. Point-to-Point
RDMA in a Nutshell
At the heart of modern high-performance computing clusters lies Remote Direct Memory Access (RDMA). RDMA enables one server’s NIC to read or write directly to another server’s memory, bypassing kernel intervention and CPU overhead. This kernel bypass delivers sub-microsecond latency and up to 400 Gbps bandwidth, making it indispensable for scaling LLM systems.
RDMA supports two major operation types:
- Two-sided (SEND/RECV): A coordinated handshake where the receiver posts a
RECVbuffer before the sender issues aSEND. - One-sided (WRITE/READ): Direct access without remote involvement—analogous to having a secure key to a friend’s house. A
WRITEIMMextends this by delivering a small 32-bit “immediate” value used for signaling completion.
The Hardware Fragmentation Problem
The key problem arises because not all RDMA implementations behave alike:
- NVIDIA ConnectX: Uses Reliable Connection (RC) transport—order-preserving and connection-oriented.
- AWS EFA: Introduces Scalable Reliable Datagram (SRD)—connectionless and reliable but unordered.
Many RDMA libraries assume RC’s strict in-order delivery. When deployed on AWS EFA, which offers unordered delivery, these systems break or suffer severe performance losses. This incompatibility has led to fragmented solutions like NVSHMEM and DeepEP that are fast but hardware-restricted.
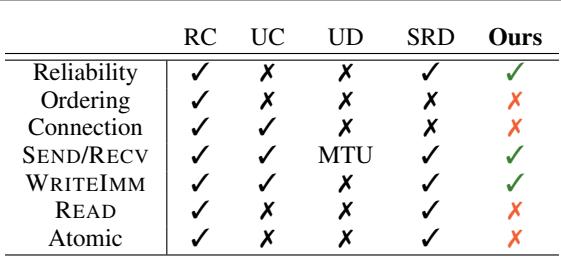
Figure: RDMA transport comparison diagram showing reliable but unordered delivery as the shared foundation across NICs.
The authors’ key insight: both ConnectX and EFA support reliable delivery even if unordered. By building on this common ground, TransferEngine achieves high-performance communication across both ecosystems.
TransferEngine: A Portable RDMA Abstraction
Abstraction Without Compromise
TransferEngine provides a unified interface atop two very different software stacks—libibverbs (ConnectX) and libfabric (EFA). It exposes a clean API for flexible point-to-point data exchange, providing portable SEND/RECV for RPC-style messages and high-bandwidth one-sided WRITEs for bulk transfers.
The real innovation lies in how it handles completion notifications in an unordered network world. When large workloads involve hundreds of concurrent transfers, conventional order-dependent tracking fails. TransferEngine solves this with a new primitive: IMMCOUNTER.
The IMMCOUNTER: Completion Without Ordering
Here’s the idea:
- Every RDMA
WRITEIMMcarries an immediate 32-bit value. - The receiver increments an IMMCOUNTER tied to that value upon completion—using atomic updates from the NIC’s completion queue.
- The application just waits for the counter to reach its target (e.g., 100) to confirm all transfers completed.
This mechanism elegantly sidesteps ordering dependencies. It guarantees completeness regardless of arrival sequence, enabling consistent performance across unordered (EFA) and ordered (RC) transports.
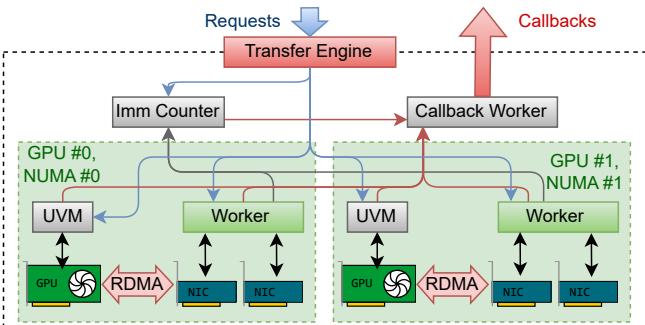
Figure 1. Overview of TransferEngine architecture across NUMA nodes.
TransferEngine creates one worker thread per GPU, pinned to its local CPU core. Each worker coordinates all RDMA NICs attached to that GPU—essential for EFA configurations requiring multi-NIC aggregation. The engine invisibly manages these details, ensuring near-400 Gbps performance even on cloud hardware.
A Look at the API
Here’s a simplified view of the Rust-like API described in the paper:
| |
A particularly powerful concept is the UVM Watcher. It links CPU-side RDMA logic with GPU kernel progress. When a GPU kernel finishes preparing data, it writes to a Unified Virtual Memory address monitored by a low-latency CPU thread via GDRCopy. The change triggers the corresponding RDMA operation—seamlessly aligning GPU compute and network transfer.
Real-World Deployments of TransferEngine
TransferEngine isn’t just theoretical—it’s already powering production systems across various workloads.
1. Disaggregated Inference: KvCache Transfer Between Clusters
During inference, the prefill (processing context) and decode (token generation) phases are separated into dedicated clusters for efficiency. The bottleneck lies in moving the large Key-Value (KV) caches between them.
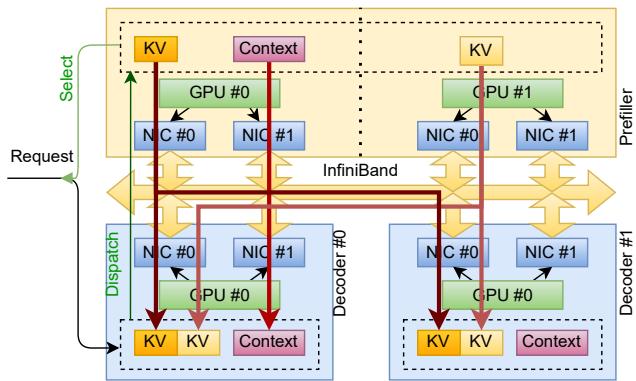
Figure 3. KV cache transfer between prefiller and decoder in disaggregated inference.
Workflow:
- The scheduler assigns a prefiller and decoder node.
- The decoder preallocates memory and sends its RDMA memory map (
MrDesc) to the prefiller. - As each layer’s KV cache finishes on the GPU, a CUDA kernel updates the
UVM Watcher. - TransferEngine detects the update and triggers a paged RDMA WRITE to the decoder.
- The decoder monitors completion via
expect_imm_countand begins generating tokens as soon as the cache is complete.
This approach allows independent scaling of prefill and decode clusters without synchronized reinitialization—something traditional collective-based systems cannot achieve.
2. Reinforcement Learning: Trillion-Parameter Model Updates in Seconds
In reinforcement learning fine-tuning, fresh weights from training GPUs must be instantly pushed to inference GPUs. Traditional frameworks funnel data through a single “Rank 0” GPU, bottlenecking NIC bandwidth.
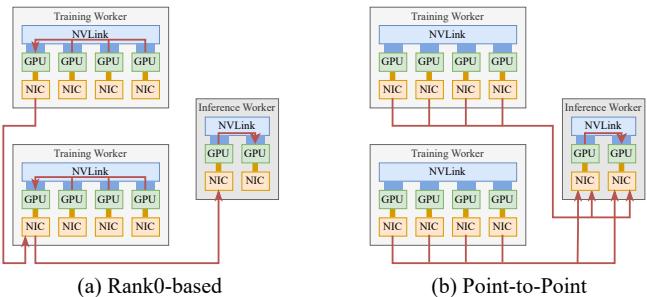
Figure 4. Rank0-based collective vs direct point-to-point transfer.
With TransferEngine, every training GPU writes directly to its target inference GPUs using one-sided RDMA operations, distributing traffic evenly across all NICs.
The team layers this with a multi-stage pipeline to overlap computation and transfer:
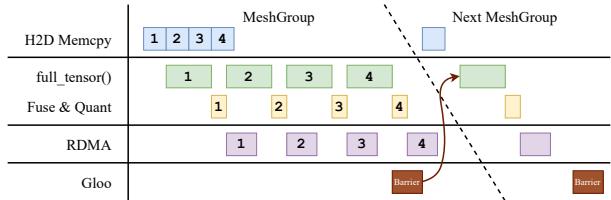
Figure 5. Pipelined weight transfer execution.
The outcomes are stunning — 1.3-second weight updates for trillion-parameter models (like DeepSeek-V3, Qwen3, and Kimi-K2). This represents more than 100× speedup over previous RL infrastructure.
3. Mixture-of-Experts: Portable, Low-Latency Dispatch and Combine
MoE architectures route tokens dynamically across multiple “expert” GPUs. The communication overhead of dispatching and combining tokens is extremely latency-sensitive.

Figure 6. GPU–CPU–NIC coordination for MoE dispatch/combine.
TransferEngine powers proxy-based kernels for dispatch and combine, supporting both ConnectX and AWS EFA—a first for portable expert routing. The proxy thread uses GDRCopy to poll GPU progress and issue RDMA transfers through the IMMCOUNTER interface.
To mitigate latency, the system uses a two-phase dispatch: speculative transfers to small private buffers while routing metadata is exchanged, followed by bulk scatter into contiguous buffers.
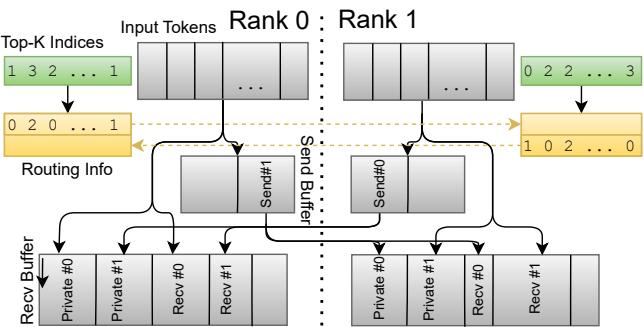
Figure 7. Two-phase dispatch into private and contiguous buffers.
Results show state-of-the-art decode latency on ConnectX and viable MoE deployment on EFA—breaking long-standing hardware restrictions.
Performance Evaluation
Throughput Benchmarks
TransferEngine achieves near-peak hardware performance across both ConnectX and EFA.
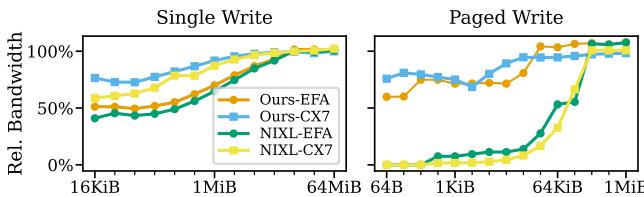
Figure 8. Point-to-point bandwidth comparison.
For typical workloads (KV page size 64 KiB and MoE transfer size 256 KiB), TransferEngine saturates the network on both NIC types. At small message sizes, performance differences reflect hardware configuration, not library design.
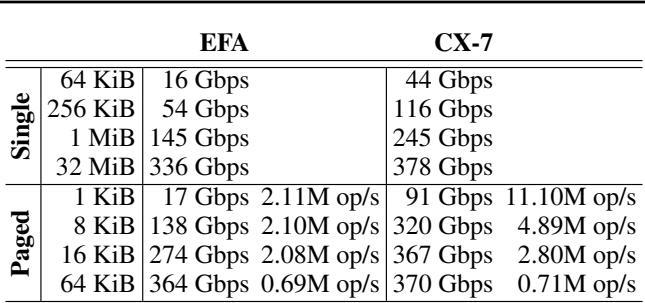
Table 2. EFA vs ConnectX-7 performance comparison.
MoE Decode Latency
The decode phase reveals how efficiently the system handles tightly-coupled inter-node dispatch/combine operations.
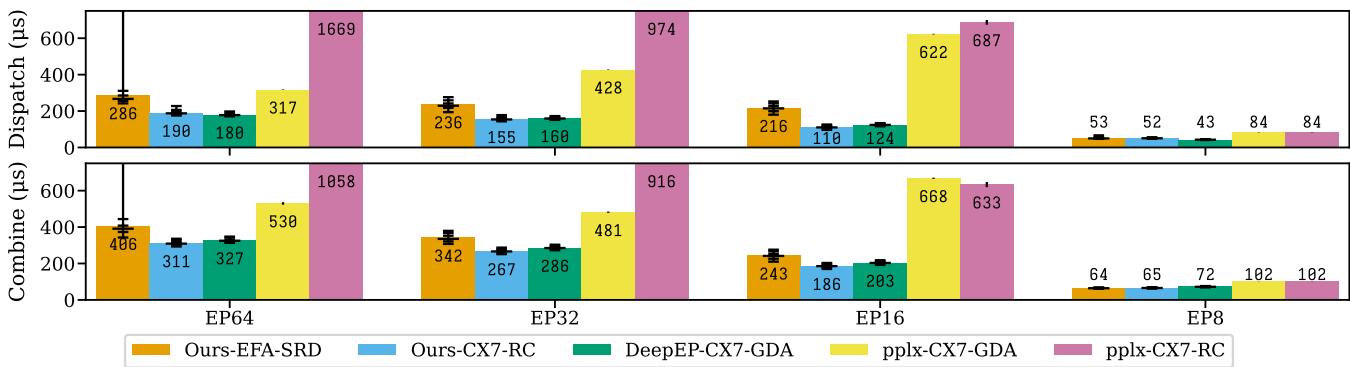
Figure 11. MoE decode latency across ConnectX and EFA deployments.
Highlights:
- On ConnectX-7, TransferEngine surpasses DeepEP’s specialized GPU-initiated design.
- On AWS EFA, it delivers the first practical low-latency MoE routing, only ~30% slower than ConnectX.
This proves portable, host-proxy designs can match or exceed conventional GPU-direct RDMA solutions.
MoE Prefill Performance
Large batch prefill workloads emphasize bandwidth utilization.

Figure 12. Prefill latency comparison.
Here, DeepEP gains an edge with sender-side accumulation, but TransferEngine remains competitive without hardware-specific optimizations—illustrating robustness across differing NIC behaviors.
Conclusion: Portable RDMA for the LLM Era
As LLM architectures grow more dynamic, the limitations of collective-only communication become clear. Future systems require flexible, high-speed point-to-point data movement—independent of vendor hardware.
TransferEngine delivers precisely that. By using reliable but unordered delivery as the shared foundation between ConnectX and EFA, and introducing the novel IMMCOUNTER primitive for portable completion signaling, it removes cloud hardware barriers while maintaining top-tier performance.
Across disaggregated inference, reinforcement learning, and Mixture-of-Experts workloads, TransferEngine enables production-scale systems that combine flexibility and speed, achieving over 400 Gbps throughput and record-setting latency across multiple hardware platforms.
The takeaway is simple: Portable point-to-point communication isn’t just possible—it’s essential. TransferEngine makes it real, ushering in an era of cloud-native LLM infrastructure free from vendor lock-in and ready for boundless scalability.