](https://deep-paper.org/en/paper/2511.03506/images/cover.png)
We’ve all been there. You’re having a long, detailed conversation with an AI assistant—sharing preferences, life events, and project updates. You feel like it finally gets you. Then, in a later chat, it confidently mentions a “fact” you never told it or forgets something you discussed at length. This isn’t just a glitch; it’s called memory hallucination, and it’s a major obstacle to building trustworthy, long-term AI companions.
For AI to evolve beyond one-shot Q&A and become genuine long-term partners, they need reliable memory systems. These systems allow AI to remember your preferences, track your goals, and maintain consistent understanding across thousands of interactions. But when memory is flawed, the AI invents facts, misremembers details, or fails to update knowledge—leading to confusing and sometimes harmful results.
Until recently, researchers have mostly been testing AI memory like a final exam: ask a question and check if the answer is right or wrong. This “end-to-end” approach reveals that a failure occurred, but not why or where it happened. Did the AI fail to record information, apply an update incorrectly, or retrieve the right memory but still produce an inaccurate response?
A new study—HaluMem: Evaluating Hallucinations in Memory Systems of Agents—introduces a breakthrough method to answer these questions. The authors present HaluMem, the first benchmark that acts like a diagnostic test for AI memory systems. It identifies the exact operational stage where hallucinations originate, letting researchers “look under the hood” of AI memory extraction, updating, and question answering.
Understanding How AI Remembers
Before diving into HaluMem, it’s useful to understand how memory works inside AI systems.
Large Language Models (LLMs) have a built-in, parameterized memory: the knowledge they acquire during training is encoded in their neural weights. This internal memory helps them recall general facts but cannot be easily accessed, updated, or deleted. It’s static—once something is learned, changing it is difficult.
To overcome this, developers created external memory systems. A familiar example is Retrieval-Augmented Generation (RAG), where an AI retrieves relevant documents from an external database before composing an answer. This approach enhances factual grounding and allows updates without retraining the whole model.
Now, more advanced systems like MemO, Supermemory, and Zep have emerged to give AI agents persistent, personalized memory layers—tools that record user details, events, and evolving preferences.

Table 1: Various modern memory systems all aim to provide manageable, long-term memory, though they differ in design and capability.
While these systems are steps toward personalized, lifelong AI, they remain vulnerable to hallucination. Evaluating such hallucinations has been a persistent challenge. Existing tests rely mostly on end-to-end, answer-based assessment—effective for judging outcomes, but poor at locating internal faults.
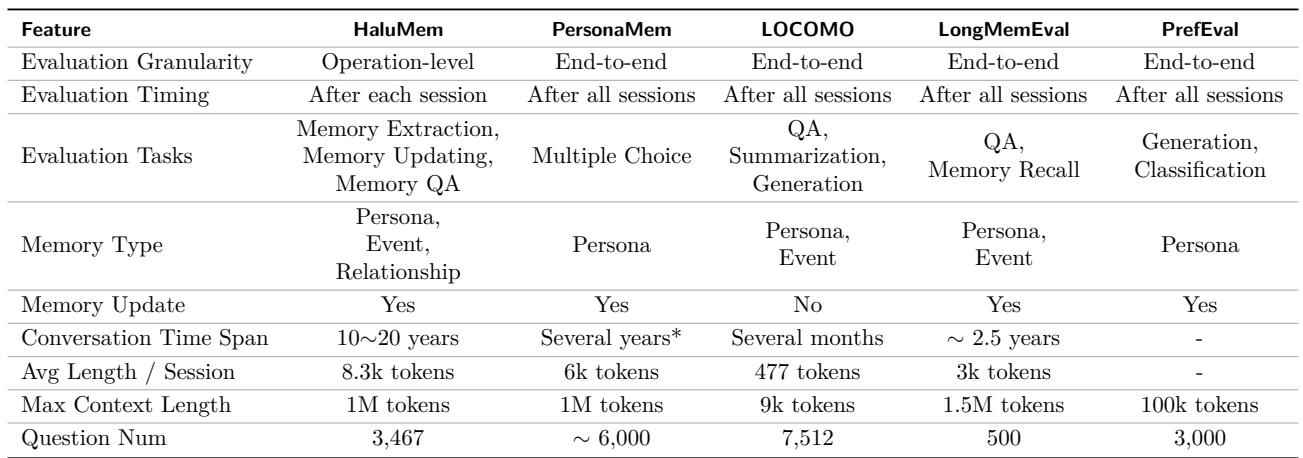
Table 2: HaluMem stands out from previous benchmarks by shifting from end-to-end evaluation to fine-grained, operation-level analysis.
HaluMem changes the paradigm by giving researchers the ability to dissect each stage of the memory process and identify where errors occur.
Opening the Black Box: From Final Exam to Root-Cause Analysis
An AI memory system performs several key operations during a conversation:
- Memory Extraction (E): Pulling out new, salient facts—called memory points—from dialogue.
- Memory Updating (U): Modifying or deleting previous memories based on new information.
- Memory Retrieval (R): Finding relevant memories when answering a question.
- Memory Question Answering (Q): Generating the final answer using retrieved information.
Traditional evaluation treats this entire chain as a single black box:
\[ \hat{M} = U(E(D)), \quad \hat{R}_j = R(\hat{M}, q_j), \quad \hat{y}_j = A(\hat{R}_j, q_j) \]Here, \(D\) is the conversation, \(q_j\) the question, and \(A\) the AI model producing the answer. We measure correctness via:
\[ \operatorname{Acc}_{e2e} = \frac{1}{J}\sum_{j=1}^{J} \mathbb{I}[\hat{y}_j = y_j^*] \]If an answer is wrong, this tells us something broke—but not whether the fault came from extraction, updating, or reasoning.

Figure 2: HaluMem’s evaluation pipeline (left) inspects individual stages of memory operations, unlike traditional setups that only check final outcomes.
HaluMem introduces stage-specific gold standards—ground-truth datasets for every step. Researchers can now evaluate whether correct memories were extracted \((E)\), appropriately updated \((U)\), and successfully used in answers \((Q)\):
\[ \hat{M}^{\text{ext}} = E(D), \quad \hat{G}^{\text{upd}} = U(\hat{M}^{\text{ext}}, D), \quad \hat{y}_j = A(R(\hat{M}, q_j), q_j) \]This transparency finally allows localization of hallucinations within the memory pipeline.
Engineering HaluMem: Building a World Where AI “Lives” and Learns
Creating a dataset for such detailed analysis isn’t trivial. You need multi-turn conversations with evolving facts, contradictory updates, and nuanced reasoning. The HaluMem team designed a six-stage pipeline to generate this data.
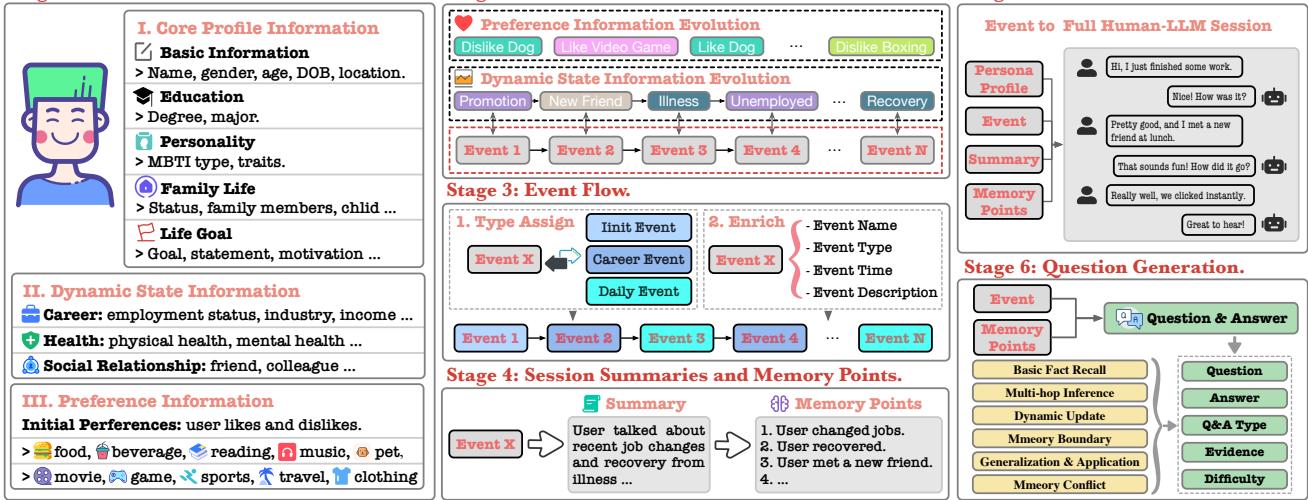
Figure 3: The HaluMem construction pipeline produces realistic, complex user–AI interactions with carefully annotated memory points.
- Stage 1 – Persona Construction: Synthetic personas are built with core profiles (e.g., background, education), dynamic states (career or health), and evolving preferences.
- Stage 2 – Life Skeleton: A timeline of major life events and updates forms the user’s “biography,” ensuring structure for subsequent sessions.
- Stage 3 – Event Flow: These skeletons turn into narrative event chains—promotions, illnesses, friendship updates, or hobbies.
- Stage 4 – Session Summaries and Memory Points: Each event generates a realistic dialogue summary and defines the gold standard memories expected to be extracted or updated.
- Stage 5 – Session Generation: Full dialogues are constructed, complete with distractor memories—false but plausible facts inserted to test hallucination resistance.
- Stage 6 – Question Generation: Over 3,400 questions probe memory performance across fact recall, reasoning, and conflict resolution.
The result is two benchmarks:
- HaluMem‑Medium — realistic medium-length sessions (≈160 k tokens per user).
- HaluMem‑Long — ultra-long contexts (>1 M tokens per user), simulating years of dialogue.
Human annotation verified content quality, achieving 95.7 % correctness—a remarkably high standard for synthetic conversational data.
The HaluMem Evaluation Framework: Measuring Every Cog in the Machine
Once the datasets were prepared, the authors built an evaluation framework that examines hallucination formation at three key stages.
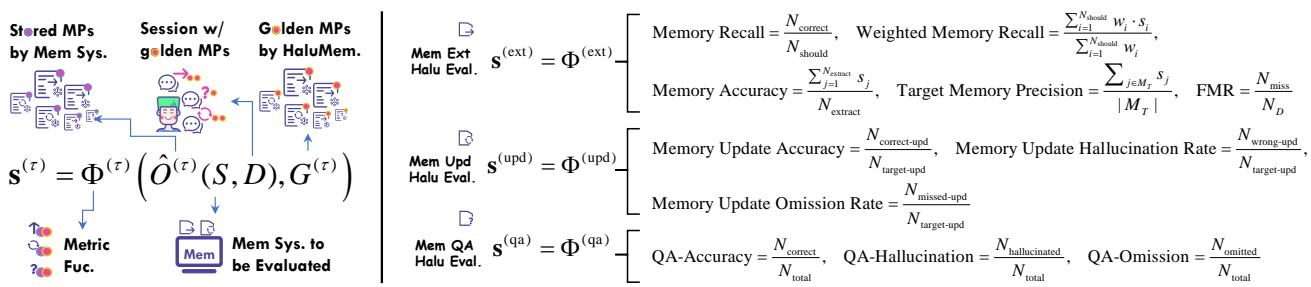
Figure 4: The HaluMem evaluation process, showing how golden memory points support fine-grained measurement across memory extraction, updating, and QA.
1. Memory Extraction Evaluation
Goal: Check if the system correctly captures new facts from conversations.
Memory Integrity (Anti‑Amnesia)
\[ \text{Memory Recall} = \frac{N_{\text{correct}}}{N_{\text{should}}}, \quad \text{Weighted Recall} = \frac{\sum w_i \cdot s_i}{\sum w_i} \]Measures omissions and weighted importance of captured memories.
Memory Accuracy (Anti‑Hallucination)
\[ \text{Memory Accuracy} = \frac{\sum s_j}{N_{\text{extract}}}, \quad \text{Target Precision} = \frac{\sum_{j \in M_T}s_j}{|M_T|} \]Evaluates factual correctness of stored information.
False Memory Resistance (FMR)
\[ FMR = \frac{N_{\text{miss}}}{N_D} \]Tests the system’s ability to ignore misleading “distractor” content.
2. Memory Updating Evaluation
Goal: Assess if systems correctly modify old memories when new data appears.
\[ \begin{array}{r} \text{Update Accuracy} = \frac{N_{\text{correct-upd}}}{N_{\text{target-upd}}}, \\ \text{Hallucination Rate} = \frac{N_{\text{wrong-upd}}}{N_{\text{target-upd}}}, \\ \text{Omission Rate} = \frac{N_{\text{missed-upd}}}{N_{\text{target-upd}}} \end{array} \]High omission rates indicate invisible updates—failing to record changes even when expected.
3. Memory Question Answering Evaluation
Goal: Measure end-to-end reliability after memory operations.
\[ \begin{array}{r} \text{QA‑Accuracy} = \frac{N_{\text{correct}}}{N_{\text{total}}}, \\ \text{QA‑Hallucination} = \frac{N_{\text{hallucinated}}}{N_{\text{total}}}, \\ \text{QA‑Omission} = \frac{N_{\text{omitted}}}{N_{\text{total}}} \end{array} \]Lower accuracy or higher hallucination/omission rates signal problems in upstream memory management.
The Verdict: Today’s AI Memory Is Still Leaky
Using this methodology, the researchers evaluated prominent memory systems—Mem0, Memobase, Supermemory, and Zep—on both HaluMem benchmarks.
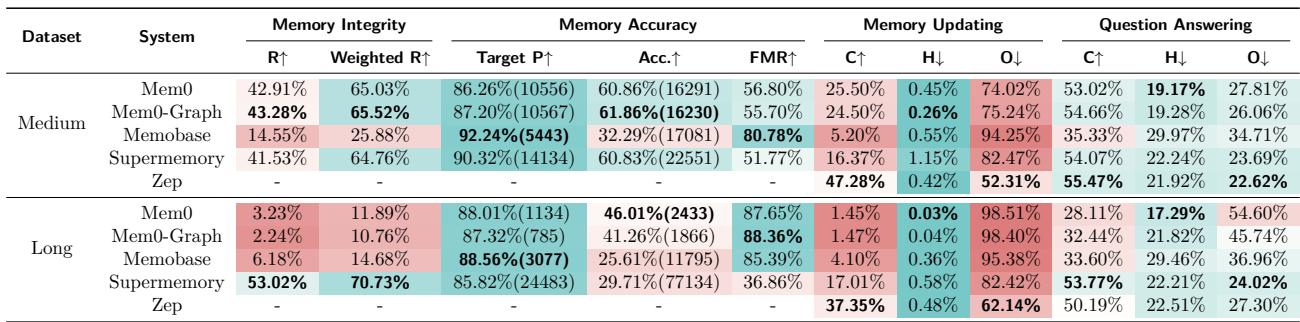
Table 3: Overall results from HaluMem. Green indicates stronger performance; red flags weak results—especially under long‑context scenarios.
Key Insights
Long Conversations Break Memory. Almost every system showed sharp performance drops on HaluMem‑Long. As context length grows, irrelevant details flood the memory, and true facts vanish.
Extraction Is the Weak Link. None achieved recall above 60 %; meaning nearly half of critical information wasn’t stored. Even when extraction occurred, factual accuracy was limited—systems frequently saved wrong or hallucinated entries.
Updating Is Compounded by Extraction Errors. Update accuracy fell below 50 % overall. If a system misses initial facts, it cannot correctly modify them later. Early-stage errors cascade downstream.
Poor Memory Leads to Poor Answers. Question‑answering accuracy strongly correlated with extraction and update quality. Systems that failed earlier stages produced hallucinated or incomplete answers later—a “garbage‑in, garbage‑out” effect.
What Do Systems Forget Most? Persona vs. Experience vs. Relationships
HaluMem’s fine-grained data allowed breakdown by memory type.
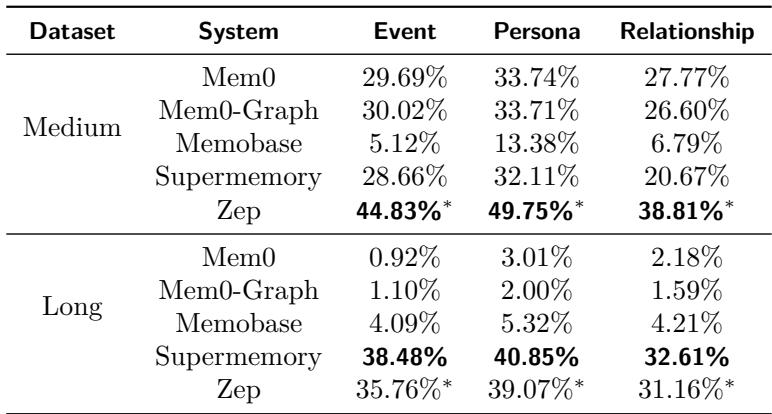
Table 4: Systems generally recall static persona data better than dynamic event or relationship information.
Static “persona” memories—like a user’s hobbies—are easier for AI to maintain, while evolving event or social-relational facts cause confusion. Consistently tracking changes over time remains unsolved.
When Questions Require Real Thinking
Next, the team analyzed performance across question types.
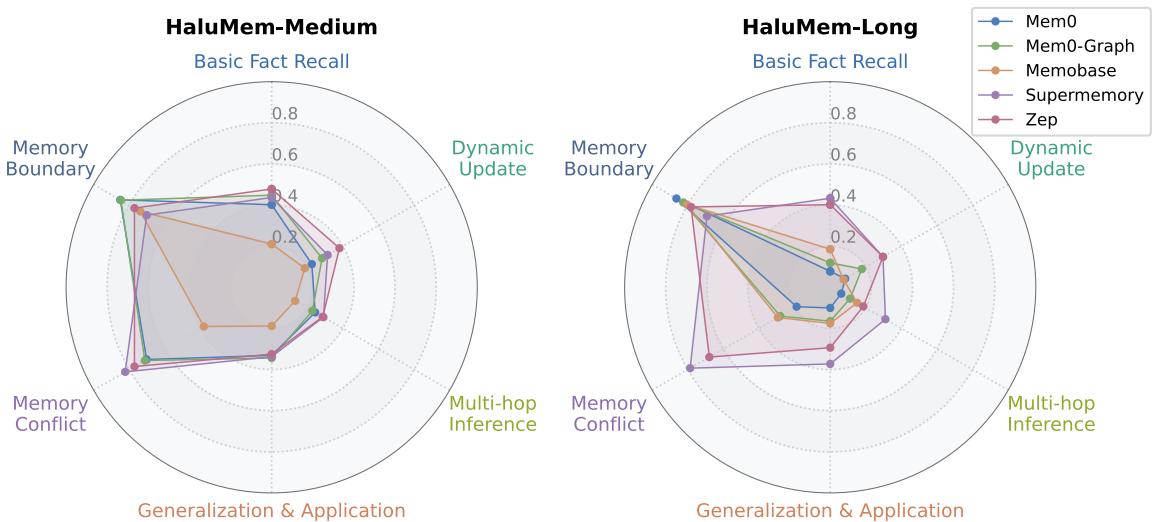
Figure 5: Systems handle direct fact recall better than reasoning-heavy tasks such as multi-hop inference and dynamic updates.
Every system struggled with reasoning-oriented questions—especially multi-hop inference, dynamic updates, and generalization. While most could identify what information they didn’t know (memory boundaries), they faltered at connecting or applying memories across contexts.
Efficiency: Writing Is Harder Than Reading
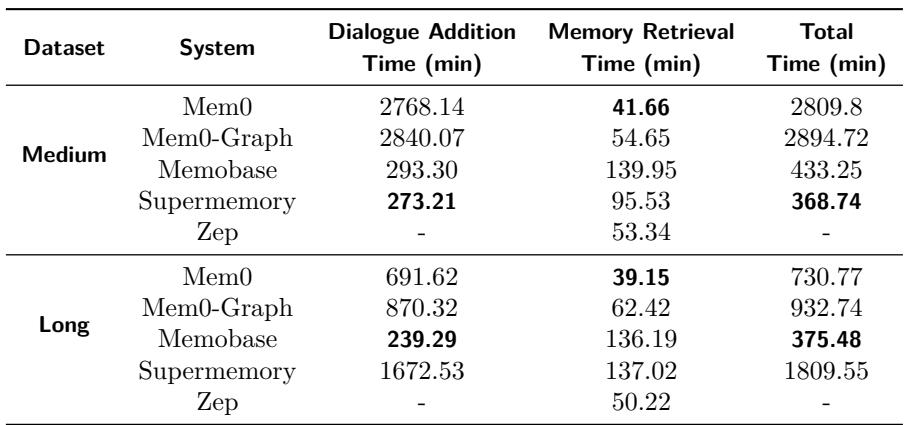
Table 5: Writing (dialogue ingestion and memory extraction) is much slower than reading (retrieval), highlighting key optimization targets.
Across experiments, inserting new memories took vastly longer than retrieving existing ones, suggesting that efficiency bottlenecks lie in extraction and update processes. Improving these steps could notably enhance the responsiveness of memory-enabled AI.
Conclusion: HaluMem Opens a New Era of Transparent Memory Evaluation
Most current benchmarks treat AI memory systems as black boxes, judging them only by final answers. HaluMem introduces the first operation-level perspective—revealing how hallucinations arise during memory extraction and updating, not just whether they appear in final responses.
The results are sobering. Long-term memory systems today are inconsistent, error-prone, and easily derailed by lengthy contexts. They miss key information early, fail to refresh outdated facts, and accumulate hallucinations that propagate through generations of interactions.
But HaluMem offers a path forward. By diagnosing failures at every stage, researchers now have a roadmap for designing more interpretable, stable, and reliable memory architectures—those that not only store information but preserve truth, consistency, and context over time.
In short, the future of AI memory won’t depend solely on training larger models or collecting more data. It will hinge on understanding how memory itself works—and tools like HaluMem are leading the way to make our digital companions truly remember, correctly, and faithfully.